题目
- 1 讲一下你门公司的大数据项目架构?
- 2 你在工作中都负责哪一部分
- 3 spark提交一个程序的整体执行流程
- 4 spark常用算子列几个,6到8个吧
- 5 transformation跟action算子的区别
- 6 map和flatmap算子的区别
- 7 自定义udf,udtf,udaf讲一下这几个函数的区别,编写的时候要继承什么类,实现什么方法
- 8 hive创建一个临时表有哪些方法
- 9 讲一下三范式,三范式解决了什么问题,有什么优缺点
- 10 讲一下纬度建模的过程
- 11 纬度表有哪几种
- 12 事实表有几种
- 13 什么是纬度一致性,总线架构,事实一致性
- 15 什么是拉链表,如何实现?
- 16 什么是微型纬度、支架表,什么时候会用到
- 17 讲几个你工作中常用的spark 或者hive 的参数,以及这些参数做什么用的
- 18 工作中遇到数据倾斜处理过吗?是怎么处理的,针对你刚刚提的方案讲一下具体怎么实现。用代码实现,以及用sql实现。
- 19 讲一下kafka对接flume 有几种方式。
- 20 讲一下spark是如何将一个sql翻译成代码执行的,里面的原理介绍一下?
- 21 spark 程序里面的count distinct 具体是如何执行的
- 22 不想用spark的默认分区,怎么办?(自定义Partitioner 实现里面要求的方法 )具体是哪几个方法?
- 23 有这样一个需求,统计一个用户的已经曝光了某一个页面,想追根溯是从哪几个页面过来的,然后求出在这几个来源所占的比例。你要怎么建模处理?
- 23 说一下你对元数据的理解,哪些数据算是元数据
- 24 有过数据治理的经验吗?
- 25 说一下你门公司的数据是怎么分层处理的,每一层都解决了什么问题
- 26 讲一下星型模型和雪花模型的区别,以及应用场景
答案
1 讲一下你门公司的大数据项目架构?
实时流和离线计算两条线
数仓输入(客户端日志,服务端日志,数据库)
传输过程(flume,kafka)
数仓输出(报表,画像,推荐等)
2 你在工作中都负责哪一部分
3 spark提交一个程序的整体执行流程
包括向yarn申请资源、DAG切割、TaskScheduler、执行task等过程
4 spark常用算子列几个,6到8个吧
5 transformation跟action算子的区别
6 map和flatmap算子的区别
7 自定义udf,udtf,udaf讲一下这几个函数的区别,编写的时候要继承什么类,实现什么方法
区别:
- UDF:输入一行,输出一行
UDF:用户定义(普通)函数,只对单行数值产生作用; - UDTF:输入一行,输出多行,类似explode函数
UDTF:User-Defined Table-Generating Functions,用户定义表生成函数,用来解决输入一行输出多行; - UDAF:输入多行,输出一行,类似聚合函数
UDAF:User- Defined Aggregation Funcation;用户定义聚合函数,可对多行数据产生作用;等同与SQL中常用的SUM(),AVG(),也是聚合函数;
Hive实现:
| 类型 | 类 | 方法 |
| UDF | 类: GenericUDF
| initialize:类型检查,返回结果类型 evaluate:功能逻辑实现 入参:DeferredObject[] 出参:Object 出参:String close:关闭函数,释放资源等 出参:void |
| UDTF | 类: 包路径: | initialize:类型检查,返回结果类型 process:功能逻辑实现 入参:Object[] 出参:void 出参:void |
| UDAF | 类: 类:
AbstractAggregationBuffer | -----AbstractGenericUDAFResolver----- getEvaluator:获取计算器 ---------GenericUDAFEvaluator---------- init: getNewAggregationBuffer: 入参:无 出参:AggregationBuffer reset: 入参:AggregationBuffer 出参:void 入参:AggregationBuffer,Object[] 出参:void merge: 入参:AggregationBuffer,Object 出参:void
入参:AggregationBuffer 出参:Object 入参:AggregationBuffer 出参:Object --------AbstractAggregationBuffer------- 入参:无 出参:int |
UDAF说明
- 一个Buffer作为中间处理数据的缓冲:获取getNewAggregationBuffer、重置reset
- 四个阶段(Mode):
- PARTIAL1(Map阶段):
from original data to partial aggregation data:
iterate() and terminatePartial() will be called. - PARTIAL2(Map的Combiner阶段):
from partial aggregation data to partial aggregation data:
merge() and terminatePartial() will be called. - FINAL(Reduce 阶段):
from partial aggregation to full aggregation:
merge() and terminate() will be called. - COMPLETE(Map Only阶段):
from original data directly to full aggregation:
iterate() and terminate() will be called.
- PARTIAL1(Map阶段):
- 五个方法:
- 初始化init
- 遍历iterate:PARTIAL1和COMPLETE阶段
- 合并merge:PARTIAL2和FINAL阶段
- 终止terminatePartial:PARTIAL1和PARTIAL2阶段
- terminate:COMPLETE和FINAL阶段
Spark实现:
参考:Spark - 自定义函数(UDF、UDAF、UDTF) - 知乎
8 hive创建一个临时表有哪些方法
9 讲一下三范式,三范式解决了什么问题,有什么优缺点
10 讲一下纬度建模的过程 (选择业务过程 确定粒度 确定纬度 确定事实表)
11 纬度表有哪几种
12 事实表有几种
13 什么是纬度一致性,总线架构,事实一致性
15 什么是拉链表,如何实现?
16 什么是微型纬度、支架表,什么时候会用到
17 讲几个你工作中常用的spark 或者hive 的参数,以及这些参数做什么用的
18 工作中遇到数据倾斜处理过吗?是怎么处理的,针对你刚刚提的方案讲一下具体怎么实现。用代码实现,以及用sql实现。
19 讲一下kafka对接flume 有几种方式
三种:source、channel、sink
source和sink对接方式:Flume对接Kafka详细过程_flume kafka_杨哥学编程的博客-CSDN博客
channel对接方式:flume--KafkaChannel的使用_kafka channel为什么没有sink-CSDN博客
20 讲一下spark是如何将一个sql翻译成代码执行的,里面的原理介绍一下?
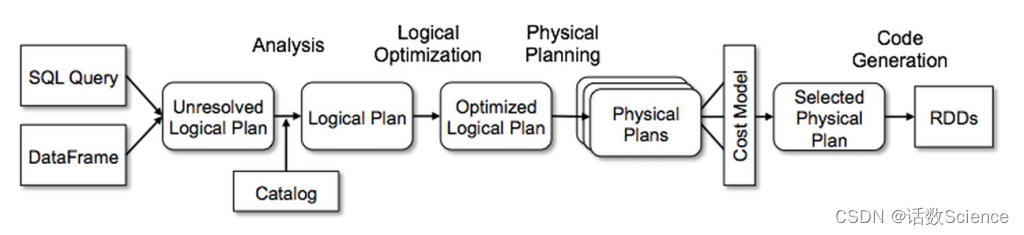
SparkSQL主要是通过Catalyst优化器,将SQL翻译成最终的RDD算子的
| 阶段 | 产物 | 执行主体 |
| 解析 | Unresolved Logical Plan(未解析的逻辑计划) | sqlParser |
| 分析 | Resolved Logical Plan(解析的逻辑计划) | Analyzer |
| 优化 | Optimized Logical Plan(优化后的逻辑计划) | Optimizer |
| 转换 | Physical Plan(物理计划) | Query Planner |
无论是使用 SQL语句还是直接使用 DataFrame 或者 DataSet 算子,都会经过Catalyst一系列的分析和优化,最终转换成高效的RDD的操作,主要流程如下:
1. sqlParser 解析 SQL,生成 Unresolved Logical Plan(未解析的逻辑计划)
2. 由 Analyzer 结合 Catalog 信息生成 Resolved Logical Plan(解析的逻辑计划)
3. Optimizer根据预先定义好的规则(RBO),对 Resolved Logical Plan 进行优化并生成 Optimized Logical Plan(优化后的逻辑计划)
4. Query Planner 将 Optimized Logical Plan 转换成多个 Physical Plan(物理计划)。然后由CBO 根据 Cost Model 算出每个 Physical Plan 的代价并选取代价最小的 Physical Plan 作为最终的 Physical Plan(最终执行的物理计划)
5. Spark运行物理计划,先是对物理计划再进行进一步的优化,最终映射到RDD的操作上,和Spark Core一样,以DAG图的方式执行SQL语句。 在最新的Spark3.0版本中,还增加了Adaptive Query Execution功能,会根据运行时信息动态调整执行计划从而得到更高的执行效率
整体的流程图如下所示:
参考:SparkSQL运行流程浅析_简述spark sql的工作流程-CSDN博客
21 spark 程序里面的count distinct 具体是如何执行的
-
一般对count distinct优化就是先group by然后再count,变成两个mapreduce过程,先去重再count。
-
spark类似,会发生两次shuffle,产生3个stage,经过4个步骤:①先map端去重,②然后再shuffle到reduce端去重,③然后通过map做一次partial_count,④最后shuffle到一个reduce加总。
-
spark中多维count distinct,会发生数据膨胀问题,会把所有需要 count distinct 的N个key组合成List,行数就翻了N倍,这时最好分开来降低单个任务的数据量。
参考:大数据SQL COUNT DISTINCT实现原理 - 知乎
22 不想用spark的默认分区,怎么办?(自定义Partitioner 实现里面要求的方法 )具体是哪几个方法?
abstract class Partitioner extends Serializable {
def numPartitions: Int
def getPartition(key: Any): Int
}
参考:Spark自定义分区器-CSDN博客
23 有这样一个需求,统计一个用户的已经曝光了某一个页面,想追根溯是从哪几个页面过来的,然后求出在这几个来源所占的比例。你要怎么建模处理?(这里回答的不好,挺折磨的。面试官的意思是将所有埋点按时间顺序存在一个List 里,然后可能需要自定义udf函数,更主要的是考虑一些异常情况,比如点击流中间是断开的,或者点击流不全,怎么应对)
23 说一下你对元数据的理解,哪些数据算是元数据
24 有过数据治理的经验吗?
25 说一下你门公司的数据是怎么分层处理的,每一层都解决了什么问题
26 讲一下星型模型和雪花模型的区别,以及应用场景