Abstract
利用基于三维点云的技术量化立木和立木参数,可以在林业生态效益评估和立木培育和利用中发挥关键作用。随着光探测与测距(LiDAR)扫描等三维信息获取技术的进步,可以更高效地获取大面积、复杂地形的树木林分信息。然而,由于森林地面的多样性、树木形态的多样性,以及林业经常种植为大规模人工林的事实,有效地分割人工种植的森林点云并提取立木特征参数仍然是一个相当大的问题。挑战。在这项工作中提出了一种基于能量分割和 PointCNN 的有效方法来解决这个问题。该网络通过几何特征平衡模型 (GFBM) 增强了学习点云特征的能力,从而能够从户外环境中地面激光扫描 (TLS) 收集的林业点云数据中有效地分割树木点云。然后利用3D Forest软件得到语义分割后的单木点云,最后利用提取的单木点云利用TreeQSM提取立木特征参数。点云语义分割方法是我们研究中最重要的部分。根据我们的发现,该方法可以分割两个不同人工种植的林地点云的数据集,整体精度为 0.95,树木分割精度为 0.93。与人工测量相比,两个数据集中树高的均方根误差 (RMSE) 分别为 0.30272 和 0.21015 m,胸径的 RMSE 分别为 0.01436 和 0.01222 m。我们的方法是一个基于深度学习的稳健框架,适用于林业,用于提取人工种植树木的特征参数。解决了人工种植树木中树木点云的分割问题,为树木信息提取、树干形状分析等提供了可靠的数据处理方法。
Keywords: 深度学习;语义分割;树木特征信息的提取; TLS激光雷达数据;人工林
1. Introduction
树木的立木特征提供了重要的三维数据[1],可以提取这些数据以获得详细信息,例如树木的位置、高度、木材体积和胸径[2]。虽然关于立地特征的信息对于森林资源管理 [3]、野外清查 [4] 和人工造林很重要,但它也可以协助研究树木动物栖息地及其栖息地结构 [5] 和城市园林景观设计[6]。传统获取树木信息的方法一般需要人工实地测量,而直接测量林业信息的工具和方法很多[7]。然而,这个过程非常耗时,并且可能会对树木造成一些损害。现代遥感技术的发展,特别是基于光探测和测距(LiDAR)传感器的同步定位和建图(SLAM)[8-11],使得对成像的探索逐渐增加[12,13],并使得未经大量培训的技术人员可以轻松收集高质量的林业 3D 信息并重建林业点云图。林业信息采集常用的激光扫描系统根据承载平台可分为以下几类:地面激光扫描(包括地面激光、背包激光和车载激光)、卫星激光雷达扫描和机载激光扫描。其中,地面激光扫描系统以其高度的灵活性和便携性以及良好的点云质量而被广泛应用于森林遥感[14-18]。我们在本文中收集的数据集基于地面激光扫描。虽然林业 3D 信息的提取变得越来越丰富和高质量,但其复杂性给处理带来了挑战。
深度学习是目前机器学习中研究最广泛的领域之一,在对象部分分割、自然语言处理、目标检测、实例分割、语义分割等诸多领域都有应用。二维深度学习算法已被有效地用于图像和视频的自动分类,例如用于精准农业的水果是否腐败的自动识别 [19]、自动驾驶 [20-22] 和城镇调查规划 [23] ].虽然更多的 3D 对象的表示信息反映在点云中,但已经有很多尝试在大型 3D 点云上使用深度学习。例如,SnapNet [24] 将 3D 点云转换为一组虚拟 2D RGBD 快照,然后可以对其进行语义分割并投影到原始点云数据上。 SegCloud [25] 在体素上使用 3D 卷积并应用 3D 全卷积神经网络来生成下采样体素标签。然而,这些方法并没有捕捉到3D点云的内在结构,将点云转换为2D格式也会造成原始信息和空间特征的丢失。还有一些直接处理点云的方法已显示出良好的性能。 Point-Net [26] 是一项开创性的工作,它使用原始点云作为每个体素中的深度学习输入,而 PointNet++ [27] 建立在 PointNet 之上,具有增强的局部结构信息集成能力。这些点云分割方法在林业点云分割中有很多扩展和应用。例如,PointNet 用于树冠的独立分割 [28],PointNet++ 用于林业环境的语义分割 [29]。本文重点关注树木点云(包括茎和叶)的分割,因为我们认为良好的树木点云分割是获得更准确的林分信息的先决条件。
虽然上述所有方法在林业点云语义分割中都表现良好,但是人工林业场景下树木点云的语义分割仍然面临着诸多挑战,其中之一就是场景中点云几何特征的不匹配。在树干主要具有线性和垂直性特征,树冠主要具有线性和散布特征,地面主要具有平面性特征,各几何特征的点云数量与场景不匹配的人工林环境中,使网络无法更好地学习每个标签的特征。例如,分支的平面度和垂直特征点云数量不同会影响网络对茎标签的学习。网络对其余几何特征的了解不够,当一个几何特征的点云过多时会影响分割。同时,由于林业点云具有规模大、无序的特点,一些在室内环境下效果较好的卷积方法很难在林业点云上达到相同的效果。然而,[30,31] 提出的能量分区可以将大规模林业点云无监督地划分为几何分区,然后采用我们提出的几何特征平衡模型(GFBM)来平衡整体几何特征,最后嵌入 PointCNN [32] 用于特征学习。 PointCNN由于X-Conv的引入可以保留点云的空间位置信息,一定程度上解决了林业点云的无序问题。
在以往研究的背景下,直接使用商业软件提取树木参数是可能的,但不排除环境中其余的点云 [17]。Fully Convolutional Neural Network (FCN) 系列网络也可用于对叶子和茎点云进行分类,但结果一般[33]。我们的论文提出了一种基于深度学习的方法,用于从人工种植的森林中提取树木特征参数。它通过语义分割去除环境中的干扰点,具有良好的分割精度。重点关注以下几个要点:(1)能量分割将原始点云划分为几何分区; (2) 几何特征匹配平衡了整个场景的几何特征; (3) 将几何平衡的点云嵌入到PointCNN网络中进行学习; (4) 利用软件3D Forest[34]和TreeQSM[35-38]建立定量结构模型(QSM),获取立木特征,如树高、胸径等。
2. Materials
2.1. Methodology Overview
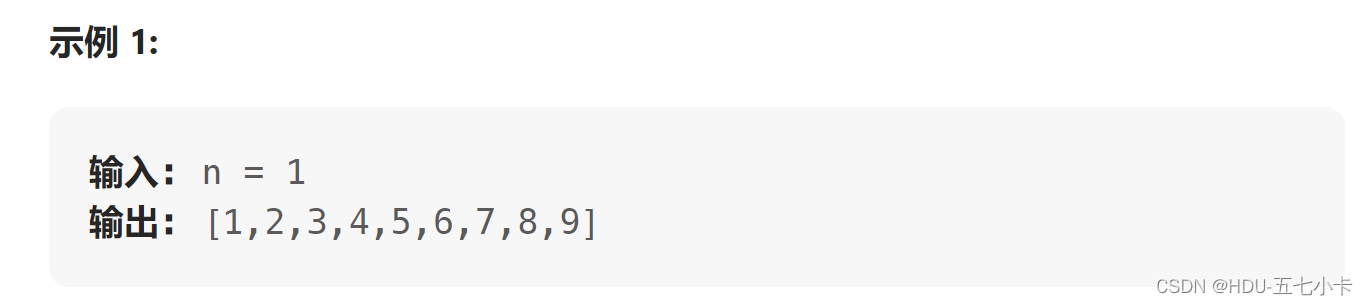
这项工作的动机是提供一种方法,可以使用 TLS 点云在人工种植的森林环境中提取立木特征参数。语义分割方法是该过程中的重要步骤,适用于不同点云数据集中的树木。在这里,我们描述了数据集的构建方式、深度学习的模型框架和训练方法、QSM 模型的构建方法以及这些模型和方法的验证方式。图 1 显示了本文方法如何处理原始点云的示意图。该示意图显示了一种工具,该工具可在不同的复杂场景中从人工种植的森林的点云中提取立木特征参数。该工具适用于森林点云(高分辨率)的TLS采集。我们将点云数据分为四个标签:叶子、茎、地面和其他点(包括灌木、草和一些人物)。几何特征平衡模型在深度学习网络训练期间参与处理数据,但在分割测试点云时不参与。
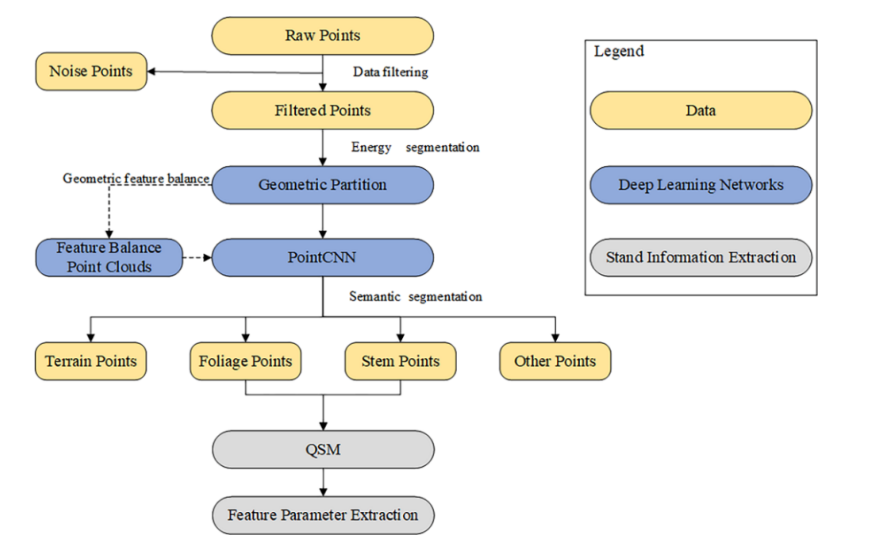
图1 基于深度学习的人工林特征参数提取的主要步骤
2.2. Class Selection Approach
语义分割的类别是根据省略颜色信息的点云的视觉检查来选择的。尽管一些框架 [39-41] 可以使用颜色和反射来分割点云,但我们的模型旨在单独处理空间(X,Y,Z)坐标,以便它可以处理由不同设备收集的更多人工森林点云。选定的林业点云受某些条件的限制。由于我们语义分割的目的是从收集的林业环境点云中提取特征信息,因此需要从收集的点云中构建 QSM 模型。因此,采集的点云在拼接成林业点云图时必须相对完整,点云要求有一定的覆盖范围和精度。例如,树木的胸径和树高至少可以直接从树点云中测量出来,大多数LiDAR设备都可以采集到这样的点云。虽然点云图中的一些茎或树枝在重建时效果不佳,但我们保留了它们,因为它们对于树干形状分析或分析茎的生长趋势仍然很重要。点云的人工标注需要高度的专注力和判断力,为保证本文数据的一致性,文中所有数据集均由一位作者人工分割。在标注叶和茎时,如果两者的交界处有一部分隐隐约约类似于叶的点,则标注为叶。在标记地面点和茎时,如果某个部分看起来像地面上的一个点,则将其归类为地面。除树木外,地面上方或下方的对象点不是我们的主要分割目标,而是被分组到其他点中。
2.3. Study Area
我们的数据是使用地面激光扫描自动收集的。提取的地面激光扫描数据是使用RIEGL VZ-2000i扫描仪获得的,该扫描仪具有高达1.2 MHz的高激光脉冲重复率,垂直扫描的视野为40°至+60°,水平扫描的视野为360°,最大扫描范围为2500 m,能够在0至40°c的环境中工作。这两个数据集由RIEGL的RISCAN PRO软件拼接而成,位于两个不同的坐标系中,扫描仪的位置为RIEGL独特的激光雷达技术基于波形数字化、在线波形处理和多回波周期处理,能够在能见度差的条件下进行高速、长距离、高精度测量,如灰尘、雾霾、雨水和高植被覆盖。该设备用于在八甲公园种植数据集试验期间在试验地点收集77次点云,在高唐种植试验期间在试验地点收集98次点云。最终的点云以LAS 1.4格式存储。
2.3.1. Beijing’s Dongsheng Bajia Park Dataset
北京东升八甲公园位于中国北京市海淀区东升乡双清路号(N:40♀0104.7800 E:116♀20040.6300)。东升八甲公园是北京最大的郊野公园,处于温带季风区,年平均降雨量688.26毫米,年平均气温13.1♀c,占地面积约1521.75亩,植物种类丰富,树木21700余株,绿化覆盖率达90%以上。本文研究的人工林面积约20亩,种植的树种主要包括椿和杨树。如图2所示,树木(主要是椿)被用作研究对象,以验证我们的方法。该场景主要由树木(包括树叶和树干)、地面和一些被认为会分散注意力的对象组成,包括人类阴影和发光体。
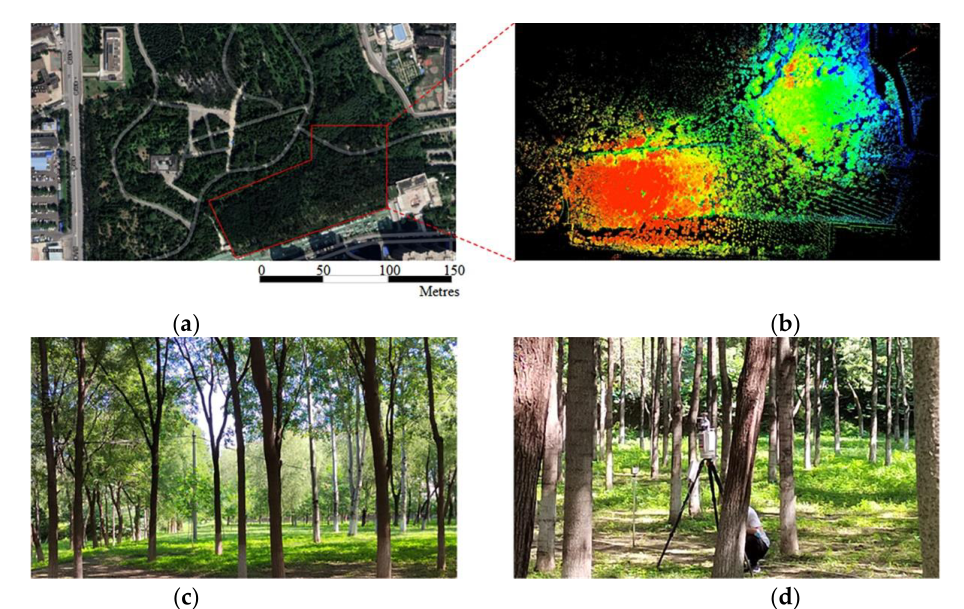
图 2. 中国北京东胜八家公园研究区:(a) 八家公园 RGB 鸟瞰图; (b) 样地点云图鸟瞰图; © 图中白色样地的RGB图像,清楚地显示了树种分布的关系; (d) 我们使用 TLS 收集数据。
2.3.2. Gaotang Triploid Populus Tometosa Dataset
三倍体毛白杨人工林位于中国山东省聊城市高唐县清平镇国家生态公园(北纬36♀48046.3300东经116♀05023.0000)。清平镇国家生态公园是山东省最大的平原森林公园,处于温带季风区,年平均降雨量589.3毫米,年平均气温13.0♀c,占地面积约5万亩,森林覆盖率达80%以上,动植物资源丰富。这些树是在2015年春天种植的,使用三倍体无性杨B301((毛白杨×新疆杨)×毛白杨),平均胸径为2厘米,高3米。这些树在生长季节用常规肥料施肥(每年每株170克尿素,分4次施用),采用完全随机分组设计,有三个处理:完全灌溉(FI)、控制灌溉(CI)和不灌溉(CK)。如图3所示,选择了20亩杨树来验证我们的方法。整个场景由树木(包括树叶和树干)、地面、一些被认为是人为干扰的人类阴影、矮灌木和地面上的草组成。

图 3、毛白杨研究区的状况:(a)毛白杨的RGB鸟瞰图;(b)毛白杨采样点云图鸟瞰图;©毛白杨采样点的RGB图像,清楚地显示了株间间距和行间关系;(d)我们使用TLS收集数据。
2.4. Data Pre-Processing
2.4.1. Training and Validation Data
训练的第一步是获得足够和高质量的训练、验证和测试数据。由于手动标记点云数据既费时又单调,尤其是树干和树叶标记需要熟练和耐心的操作员,因此通过随机旋转 X 和 Y 轴以及将轴乘以随机比例变化来扩展数据训练集样本的 0.6-1.4 倍。大量样本有助于避免过度拟合,让网络能够使用尽可能多的数据进行训练。然后我们将训练和验证集中的点云转换为 HDF5 [42] 格式进行训练和验证。
同时,由于两个数据集的不同特征,我们还为它们生成了不同的训练和验证数据集。对于八家公园数据集,在语义标注过程中人工生成了四种类型的数据集,包括(1)完整和部分残缺的单树茎; (2) 树冠和树叶; (3) 完整的地面; (4) 场景中的其他点云,如人体影子(操作员)和实验设备(太阳辐射计)。除了树木本身的性状特征与八家数据集不同外,高唐杨树数据集在点云图中地面上的植物也多于八家数据集。由于我们在本文中只关注树木的林分信息,因此这些植物在该数据集中被分为其他类别。八家数据集中的树木总数约为230棵完整的树木点云和一些碎片化的树木点云,而高唐数据集中的树木总数约为215棵。两个数据集根据数据分为训练集和验证集holdout 方法的比例为 7 比 3,因此八家数据集包含 158 棵用于训练的树和 72 棵用于验证的树,而高唐数据集包含 154 棵用于训练的树和 61 棵用于验证的树。图 4 显示了数据集的单树标记细节,它说明了两个数据集中杨树和椿树的性状差异。在这项工作的标记过程中,所有数据集都根据此标准进行了注释。如图 5 所示,我们的训练和验证数据集由每个点云中的 3 到 20 棵树组成;其中一部分显示在这里。

图 4、八家和高唐数据集单树标注示意图:(a,d)标注后的整棵树; (b,e) 一棵树的叶子和树干的标签细节; (c,f) 标记后清除单棵树的茎。
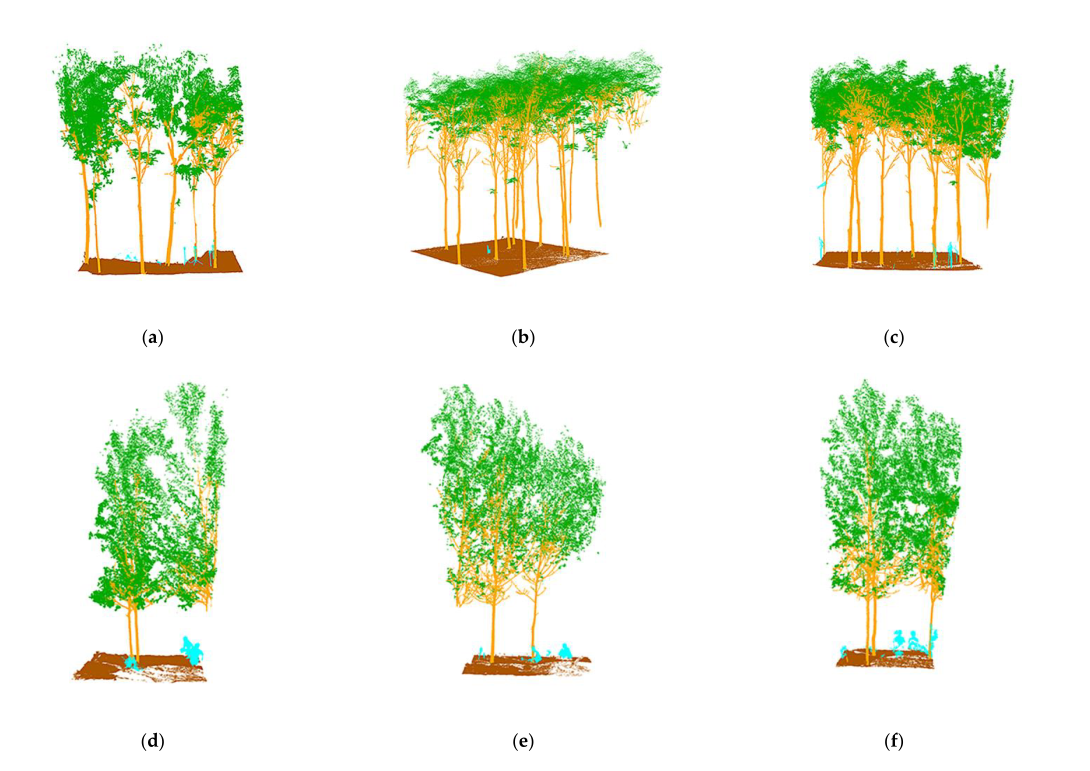
图 5. 数据集标注数据示意图:(a–c) 东升八甲数据集部分标注; (d–f) 部分高唐三倍体 Populus tometosa 数据集的标记。
2.4.2. Testing Data
我们的语义分割方法的准确性和鲁棒性通过从八家公园和高塘杨树数据中提取的样本数据块进行了测试。测试集的详细参数如表1所示。
表 1. 我们两个自建数据集的测试集的详细参数。

NT:树的数量; NP:扫描点数; RTP:树点云与扫描点的比率。
3. Methods
我们在这项工作中使用的深度学习框架基于能量分割、我们提出的几何特征平衡模型 (GFBM) 和 PointCNN,如图 6 所示。能量分割函数用作点云的预分割框架,允许基于对象几何将点云有效地分割成更小的几何分区而不丢失主要的精细细节,这里主要列出其形成几何分区的能量分割方法。每个几何分区与进入GFBM后的几何特征相匹配,使整个场景的几何特征均衡。基于 TensorFlow [43] 的 PointCNN 被嵌入到随后的语义分割中,使用卷积网络学习输入点云特征。
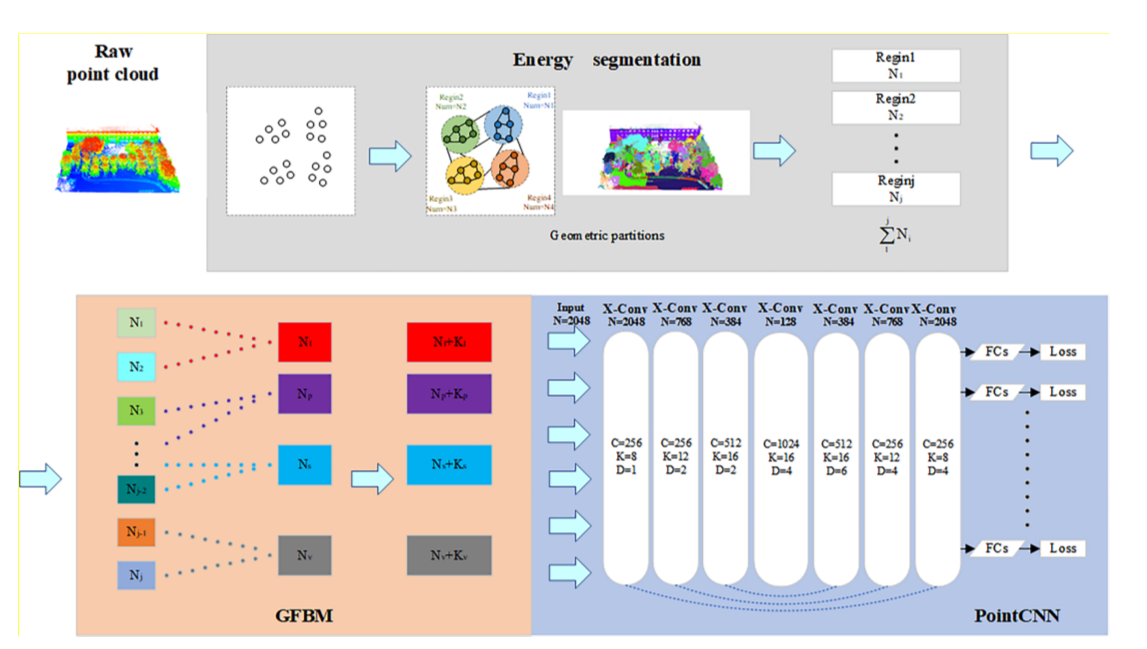
图 6. 本文中的深度学习网络结构,其中 N 1 − N j \mathrm{N}_1-\mathrm{N}_{\mathrm{j}} N1−Nj代表每个几何分区; Nl、Np、Ns、Nv分别表示以线性、平面性、散射、垂直为主要特征的点云; K l , K p , K s \mathrm{K}_{\mathrm{l}}, \mathrm{K}_{\mathrm{p}}, \mathrm{K}_{\mathrm{s}} Kl,Kp,Ks, K v \mathrm{K}_{\mathrm{v}} Kv表示几何特征平衡后加入的各个特征的点云。在PointCNN中,在每一次X-Conv操作中,N代表下一层的点数,C代表特征维度,K代表最近邻的数量,D代表扩张率。
3.1. Energy Segmentation Network
我们在本节中描述了能量分割网络的过程,其中输入原始点云被计算能量分割,允许将数百万点的原始输入点云数据转换为数百个几何分区,其中点的局部几何形状每个分区内都是相似的。
对于输入点云P,根据其三维几何特征计算几何划分。根据以上四个特征对点云进行几何分割:线性度、平面度、散射度和垂直度。每个点将只属于一个几何分区。
根据 [44],这些特征由点云中每个点的局部域定义。每个点的特征值 λ 1 ≥ λ 2 ≥ λ 3 \lambda_1 \geq \lambda_2 \geq \lambda_3 λ1≥λ2≥λ3是根据相邻点位置的协方差矩阵计算的。选择邻域大小,使其最小化向量的特征熵 E(λ1/Λ、λ2/Λ、λ3/Λ),其中 E 表示点云邻接关系。根据Weinmann等[44]提出的最佳邻居原则,Λ = ∑3 i=1 λi,符合最优邻接关系:
根据[44],这些特征由点云中每个点的局部区域定义。每个点 λ 1 ≥ λ 2 ≥ λ 3 \lambda_1 \geq \lambda_2 \geq \lambda_3 λ1≥λ2≥λ3的特征值由相邻点位置的协方差矩阵计算得出。选择邻域大小,使其最小化向量的特征E ( λ 1 / Λ , λ 2 / Λ , λ 3 / Λ ) \left(\lambda_1 / \Lambda, \lambda_2 / \Lambda, \lambda_3 / \Lambda\right) (λ1/Λ,λ2/Λ,λ3/Λ),其中E表示点云邻接关系。根据Weinmann等人[44]提出的最佳邻居原则, Λ = ∑ i = 1 3 λ i \Lambda=\sum_{i=1}^3 \lambda_i Λ=∑i=13λi,符合最佳邻接关系:
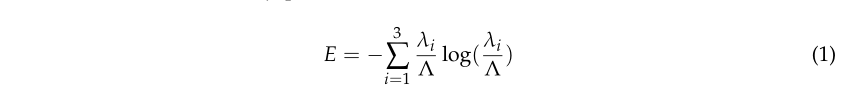
根据 [45] 的发现,可以根据这些特征值给出局部邻域的线性度、平面度和散射的公式。
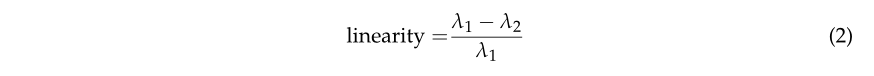
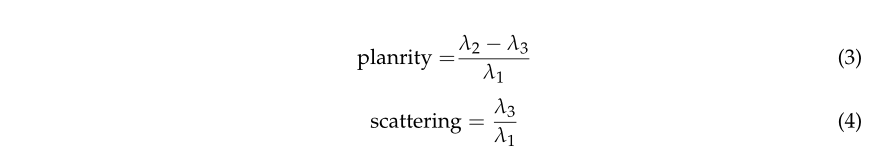
线性度描述邻域的拉长程度,平面度描述它与平面的拟合程度,高散射值对应于各向同性和球形邻域。这三个特征结合起来形成维度。垂直度也可以从特征向量的定义和上面定义的值中获得。令 μ 1 \mu_1 μ1、 μ 2 \mu_2 μ2、 μ 3 \mu_3 μ3分别为与 、 λ 1 , λ 2 , λ 3 \lambda_1, \lambda_2, \lambda_3 λ1,λ2,λ3相关联的三个特征向量。然后,我们将 R 3 \mathrm{R}^3 R3中主方向的一元向量定义为特征向量坐标的绝对值之和,这些向量由特征值加权。
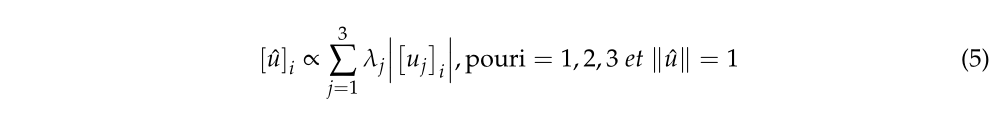
我们认为该向量的垂直部分表征了点场的垂直性。
本文参照全局属性的划分问题,对广义最小划分问题进行了研究。对于每个点 i,我们计算一个几何特征向量并将其相关联的局部几何特征向量 f i ∈ R 4 \mathrm{f}_{\mathrm{i}} \in \mathrm{R}^4 fi∈R4(维数和垂直度)计算分段常数近似 g ∗ \mathrm{g}^* g∗,其中 g ∗ \mathrm{g}^* g∗ 定义为 R 4 × P \mathrm{R}^{4 \times \mathrm{P}} R4×P 的向量,最小化以下项波茨分割能量。我们通过解决这个优化问题得到了点云几何分区。
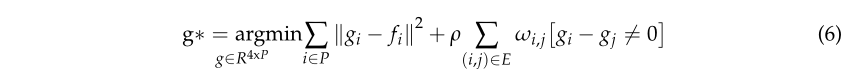
上式中,[ ]为艾弗森括号;对于属于 P 的任何点 i,ρ 是正则化因子并影响分区的粗糙度; ωi,j 是边缘权重,在 0 处等于 0,在其他任何地方都等于 1。对于分区,l0-cut pursuit [46]被用来解决这个能量分区问题。这种方法的优点是不需要定义点云的大小,计算后快速得到整个场景的不同能量分区。
3.2. Geometric Feature Balance Model
该模块的主要功能是平衡输入到网络的点云的几何特征。例如,对于点云中的树木,大部分树枝以散射几何特征为主,但也有一些树枝具有更多的垂直或平面性几何特征,增加训练集中这些树枝的数量有利于增强网络对词干标签细节的学习。在本文中,平衡整个场景的几何特征而不是特定的标签,这有利于全局特征并且计算量较小。整体流程如图7所示。
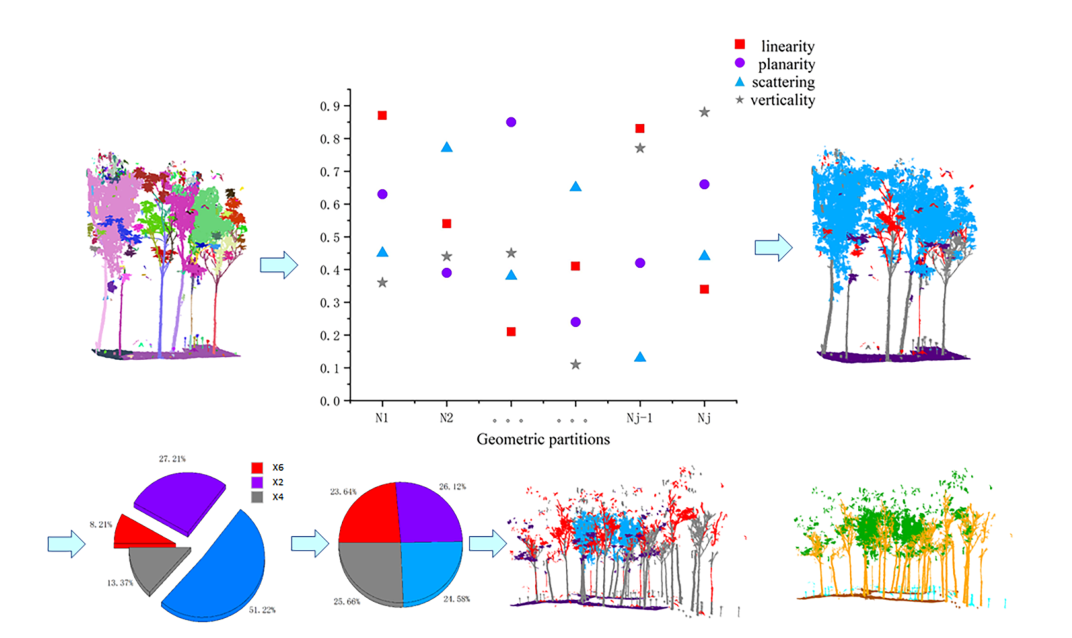
图 7. 以图 5a 为例,可视化为每个几何分区选择的主要几何特征。
计算局部邻域的四种几何特征的公式如前面3.1节所示。对于每个几何分区,分别计算其四个几何特征的平均值,然后选取每个几何分区中最具代表性的特征作为该分区的几何特征,使得以四个特征为主的点云数量可以分别得到整个场景的特征。
经过上述操作,我们得到了以线性度、平面度、散射度和垂直度为主要特征的四种点云,分别为 , Pl, Pp, Ps, Pv。几何特征平衡策略是以四点云特征集中数量最多的点云作为量化基准,其余几何特征集按数量级顺序按此基准对齐,如方程式( 7)–(9) 下面。通过复制和平移点云来平衡几何特征,在平移中添加随机旋转角度以增加网络的通用性。同时,为确保场景的整体几何特征不会因旋转操作而发生变化,旋转是使用与 Z 配对的参考轴进行的。
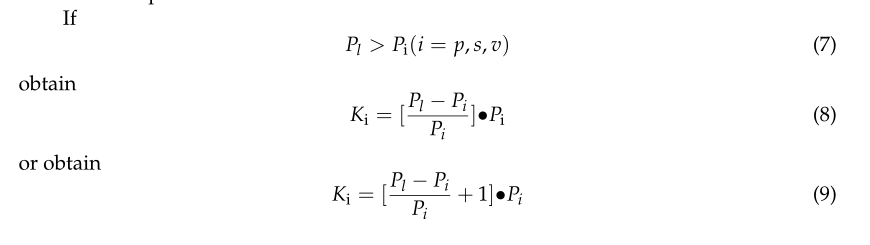
3.3. PointCNN Deep Learning Network
PointCNN 通过使用转置矩阵来解决点云无序问题。与使用对称函数处理点云无序的PointNet相比,PointCNN可以减少特征损失。在 PointCNN 中,我们使用了编码器-解码器范式,称为 X-conv,其中编码器减少了点数,同时增加了通道数。然后,网络的解码器部分增加点数,通道数逐渐减少。该网络还使用与 U-Net [47] 相同的“跳过连接”架构。 X-conv最重要的特点是既能对输入的特征进行加权又能保证不变性,然后对特征进行传统的卷积,是PointCNN的基本块。
PointCNN 在两个主要方面不同于传统的基于网格的 CNN。首先,局部区域提取的方法不同。 CNN是直接通过K×K块来提取局部特征,而PointCNN是通过在一个点上表示K个相邻点来提取局部特征,然后通过加权求和来融合K个邻域内的特征,使其达到与卷积算子融合相同的效果常规数据中的域特征。其次,局部区域信息学习的方法也不同。 CNN通常通过Conv提取图像特征然后池化下采样,而PointCNN使用X-Conv提取特征,将它们聚合成更少的点以增加通道递归学习与周围点的相关性。两种方法的比较如图 8 所示。
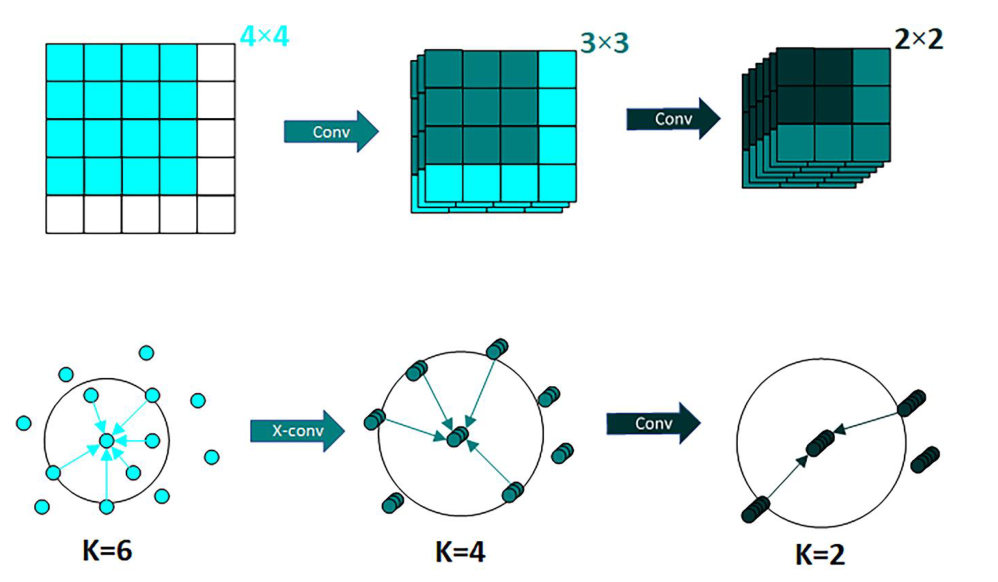
图 8. CNN 和 PointCNN 特征融合的不同过程
3.4. Training Details and Performance Measures
我们在本节中提供了有关培训的更多详细信息。所有训练和测试均在个人计算机上进行,在训练过程中使用 Nvidia 3060 GPU 进行 CUDA 加速计算。在Ubuntu 18.04上搭建了Python 3.6和TensorFlow GPU 2.4.1的开发环境,基本学习率为0.0002,batch study size为8。网络训练了150多轮,全部使用随机dropout方法训练,它在最后一个完全连接的层之前应用,以减少过度拟合。该方法可以有效提高训练过程的泛化能力,使算法在稀疏点云上表现良好。
将人工测量的真实值与QSM测量值进行比较,作为立木特征信息提取有效性的参考。 Softmax交叉熵函数被用作深度学习网络的损失函数。为了评估语义分割模型的性能,Python 包 Numpy 和 Seaborn 用于评估我们的结果并生成混淆矩阵。 IoU是每个类别的评价指标,OA是数据集的整体精度评价指标。 Precision表示实际阳性与预测阳性的比例,Recall表示正确预测的实际阳性的比例。
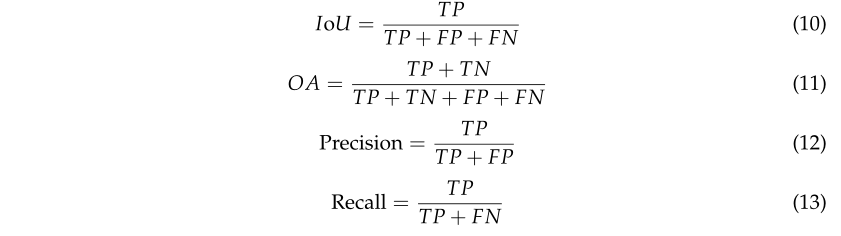
其中 TP 是真阳性,TN 是真阴性,FP 是假阳性,FN 是假阴性。
3.5. QSM Formation and Feature Parameter Extraction
树的 QSM 是树的结构模型,描述了它的基本分支结构以及几何和体积特性。这些属性还包括树的分支总数和分支的父子关系,单个分支的长度、体积和角度,以及分支大小分布。从 QSM 可以轻松计算出其他属性和分布。 QSM 由构造块组成,通常具有一些几何形状,例如圆柱体和圆锥体。此处使用圆柱体是因为它是最可靠的,并且在大多数情况下可以高度准确地估算直径、长度、方向、角度和体积。由圆柱体组成的 QSM 提供了树的下采样表示,并且可以存储有关树的大量信息,如前所述
在实际案例中,使用语义分割后的树木点云再进行QSM和立木特征信息提取,可以减少环境中其余点云对树木信息准确性的干扰,也证明了我们方法的必要性和准确性。点云分割方法。
本文采用3D Forest软件对语义分割后的树木点云进行实例分割,然后使用TreeQSM通过拟合列从分割后的点云中提取立木特征信息,将点云转化为QSM模型,可以表示我们超过 99% 的分割树干点云的精度超过亚毫米。 TreeQSM 提取树参数有两个关键步骤;第一步是分支结构的拓扑重建,即将点云分割成茎和单个分支。第二步是分支面的几何重构,通过拟合圆柱体实现。有关原始 TreeQSM 方法的更多详细信息,请参阅原始文章 [35-38]。
5. Discussion
5.1. Evaluation of Our Approach
通过激光雷达扫描技术提取林业环境中立木特征的信息对于林业自动化具有重要意义。分析树木的物理参数对于研究直立冠层与树液流、光、土壤等之间的关系非常有帮助。我们的方法提供了一种从人工种植木材的 TLS 点云中可靠地提取树木特征信息的新方法。从激光扫描数据中自动提取树木点云是林地特征信息提取、树木表型和生物物理参数估计的重要前提。本文中的语义分割方法为从激光雷达扫描的林业点云中提取树木点云提供了一种新的可靠方法。这种语义分割方法通过平衡场景中的几何特征来增强网络对人工种植林地对象特征的学习,点云由PointCNN分割。两种林业场景的语义分割均获得了较好的分割结果,该方法具有较高的鲁棒性。
但是,这项工作仍然存在一些局限性。例如,点云的手动标记仍然非常主观。虽然地面和其他点通常被正确标记,但在标记树干和树叶时,虽然大多数点都被准确标记,但由于可用时间有限以及一些模糊的事实,少数点不可避免地被错误标记人工点很难区分。在 2.4.1 节中,我们还展示了我们标记点云类别的规模,其中模糊的茎状点云被标记为树叶状,以便网络可以最大程度地学习完整茎状点云的特征从整体点云中扩展并更好地分割主干点云。我们相信,获得的树点云整体分割精度为 0.9 达到了我们预期的目标。根据我们对两个数据集的分割研究,八家数据集的树木分割准确率比高唐数据集高 4%。造成这种现象的主要原因可能是八家数据集中的椿树的物理参数与高唐数据集中的三倍体白杨的物理参数完全不同。椿树树冠扁圆,分枝多,叶片较大,而三倍体毛杨的长枝叶呈阔卵形或三角卵形叶状,叶片较小。
其他结果也很重要。例如,在八家数据集中,点云边缘上边界上的一些树点云被误分类为地面类,尽管误分类的数量很少,这可能是由于点云边界特征与地面特征。在高唐数据集中,树枝上的叶子被错误分类为茎,这可能是由于缺乏详细的标签或网络特征学习不好。但是,这并不会对立木信息的提取产生负面影响。
总体而言,本文探索的人工种植林信息提取方法有效地提取了立木特征信息,语义分割方法最大限度地保留了点云的空间特征,在最终测试中取得了良好的性能。网络在训练过程中通过迭代获得最优权重,使得模型在识别构成树干和树叶结构的点云方面具有鲁棒性。
5.2. Comparison with Similar Methods
我们还将我们的实验结果与其他论文的结果进行了比较。值得注意的是,由于采用了不同的数据和数据标注方法,这些数值并不一定能表征算法的绝对性能,但仍为我们的研究提供了一定的参考。
我们的研究与其他论文的比较见表 3,每篇论文对类的定义不同,但基本上都包含两个类:叶子和树干。在上述研究中,在计算的四个类别中,[29] 在整体精度方面表现最好,它采用了基于 PointNet++ 的方法。相比之下,我们的方法在地面和其他点类中表现更好,在树叶类中的精度相似,而在茎类中的精度较低。相比之下,[48] 比较了多种方法,在体素和 PointNet 上应用 3D 卷积神经网络来分割数据集,还分别比较了具有强度和没有强度的数据。在 [49] 中获得了 0.925 的总体精度,它使用了一种基于无监督学习的方法。
虽然我们在这里的比较有很多限制,但我们的方法获得了更准确的结果。这种比较清楚地了解了方法之间的差异,这将为我们未来的研究工作提供参考。
我们还使用三种算法在八家和高唐数据集上比较了不同的语义分割方法,包括 MVF CNN [50](也使用 CNN)、基于点的方法 PointNet 和原始的未改变的 PointCNN 网络。
MVF CNN 是一种基于深度学习的多尺度体素和特征融合算法,用于大规模点云分类。首先,点云被转换成两个不同大小的体素。然后将体素输入三维卷积神经网络 (3D CNN) 以提取特征。接下来,输出的特征被送入一个推荐的全局和局部特征融合分类网络(GLNet),最后融合主分支的多尺度特征得到它们的分类结果。
PointNet利用原始点云的输入最大化点云的空间特征,将输入分割成大小均匀的体素。网络的输入是包含n个体素和一个体素内1024个点的三维点云的三维坐标(n×1024×3)。然后将其输入网络进行训练。
表 3. 分割结果与类似研究的比较。粗体数字表示每个指标的最高分。
* 包括茎类和叶类; ** 包括我们所有的类(地面、树叶、茎等)。 *** 我们与 [29] 中的 TLS_1 和 TLS_2 数据集进行了比较;数据集包含叶子和茎。
PointCNN沿用了原论文的结构,并没有改变它,将输入点云分割成大小均匀的体素,馈入网络进行测试集的训练和预测。
在这项工作中,训练了网络,划分了测试集,maximumepoch 设置为 200。batch size 使用了 8 个样本,学习率为 0.0002。分割结果如图 13 所示,定量评价了结果在表 4 中提供。
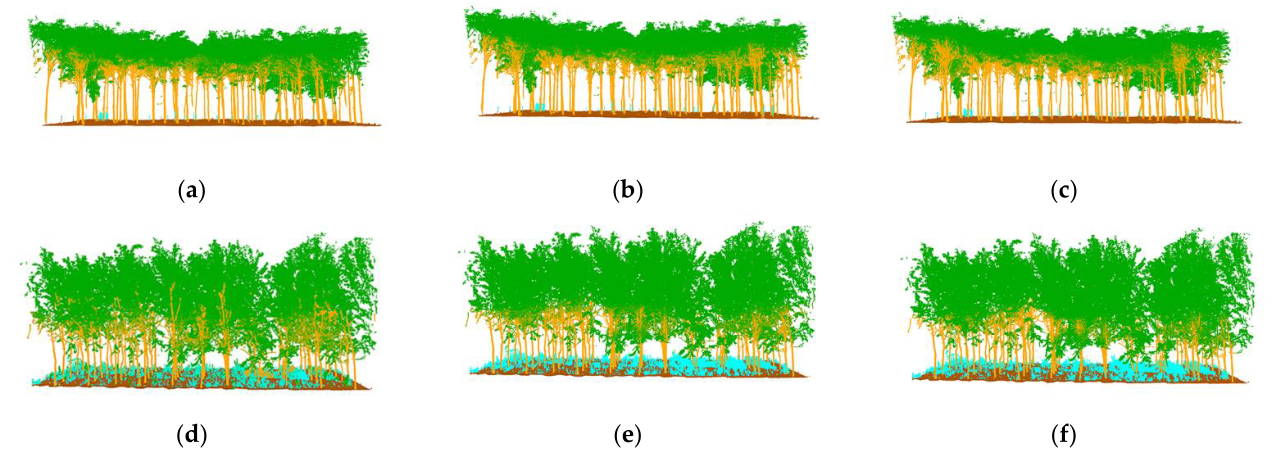
图 13. (a,d) MVF CNN 分割; (b,e) PointNet 分割; (c,f) PointCNN 分割。
表 4. 每种方法的精度比较。

其中,MVF CNN 和 PointNet 表现出相似的精度 0.85,这两种方法在树干和树叶类上都有很好的精度。原始PointCNN相对于前两种方法具有0.91的更高精度,其stem精度是四种方法中最好的。这三种方法的整体准确性不如我们的方法。这表明我们的深度学习框架在处理 TLS 捕获的人工种植树木的点云时,在提取树木的空间特征方面表现更好。
5.3. Future Research Directions
在这个项目的未来工作中,我们的重点将放在提高网络分割的准确性上。在实践中,语义分割的准确率越高,需要的人工校正就越少,这将大大减少人工工作量,有利于森林点云的全自动分割。我们打算增加训练集的数据量,将分割后人工修正的测试集加入到训练集中,再次迭代训练模型,以增强网络的识别能力。我们还将探索我们的方法在不同采集技术中的适用性,例如背包雷达和航空雷达。这将使我们能够确定其在更多设备收集的点云上的适用性,测试其在不同林业环境(例如原始森林或城市绿地)中的有效性,并探索其在更大环境中的分割有效性。树枝间的阴影问题会影响人工标注的准确性和树木的分类结果,正如阴影也会对叶面积计算产生影响一样[51]。在未来的工作中,我们还将考虑如何解决这个问题,例如,考虑使用航空雷达数据 [52] 是否会减少这种影响,或者考虑一些基于图的深度学习网络 [53]。
在未来的工作中,我们还将探索不同神经网络对人工种植树木点云分割的有效性。本文两个数据集的不同结果表明,当使用相同的树木特征信息提取方法时,不同的树种在同一网络上可能表现不同,从而表明不同的神经网络是否适用于不同的树种点云数据。探索神经网络的选择与森林环境中树木点云的分割能力之间是否存在关系,对于建立林分信息的全自动提取方法具有重要意义。
6. Conclusions
这项工作旨在获得完整的人工种植树木地基雷达点云树木信息提取方法,以帮助我们更好地研究树木的三维物理信息、树木生长和树木栽培实践之间的关系。我们将工作分为林业点云地图构建、基于深度学习的语义分割和基于 QSM 的树木特征信息提取。
林业地图是使用RIEGL设备构建的,本文重点介绍了我们提出的基于深度学习的语义分割方法,因为LiDAR收集的林业点云有噪声,其他对象的点云不相关。语义分割是排除其他点云对树点云影响的一个极其重要的组成部分。虽然在一些实际应用中需要提取树木点云也可以通过直接人工分割来解决,但由于人力有限,林业环境数据量巨大,基于深度学习的语义分割无疑是最好的方法。然后使用现有的 QSM 方法对点云进行处理,以有效地获取目标立木特征的信息。
我们的方法在数据集上显示出良好的分割结果,树高的 RMSE 分别为 0.30272 和 0.21015 m,胸高直径的 RMSE 分别为 0.01436 和 0.01222 m,语义分割的整体精度为 0.95,树木的整体精度为 0.93 .与点云的手动分割相比,我们的方法作为从TLS收集的人工林地点云中提取特征信息的自动化过程具有相当大的优势,为创建从人工林地点云中提取信息的全自动和高精度方法提供了坚实的基础林地站立。
论文链接:https://www.mdpi.com/2072-4292/14/15/3842/pdf?version=1660102616