陶博士月线反转6.4 python 化代码
量化系统有好几个月没有进度了,之前一直纠结策略问题,无从下手。最近和量化的同学聊了下,还得先把自动交易流程先跑起来后面再慢慢优化策略。
所以先拿陶博士的月线反转6.4 python 化,作为试水的策略把整个流程跑起来。后面开始研究怎么自动化交易。
聊回正题,陶博士月线反转策略(该策略来自陶博士):
条件
-
RPS50大于87 -
RPS120大于90 -
当天RPS50或RPS120大于90 -
创70日最高收盘价 -
创70日新高,且当天RPS50或RPS120大于90。 -
50日内最低价大于200日内最低价 -
30日内最低价大于120日内最低价 -
20日内最低价大于50日内最低价 -
满足条件6,7,8 作为结构紧凑的重要条件 -
10天内曾创80日新高 -
当天创50日最高收盘价或50日最高价,且RPS50或RPS120大于90 -
当天收盘价必须站上20天线和200天线 -
当天收盘价大于200天线 -
当天收盘价大于250天线 -
45天内,收盘价站上200天线的天数大于等于2,小于45 -
45天内,至少有一天的最低价低于200天线;且至少站上200天线3天以上 -
45天内,至少有一天的最低价低于250天线;且至少站上250天线3天以上 -
120天线或200天线呈上升趋势 -
120天线或200天线呈上升趋势 -
120天线和200天线线呈上升趋势 -
120天线和200天线线呈上升趋势 -
120日线、200日线呈多头排列 -
30天内最高价与120日内最低价之比小于1.50,且120天线或200天线呈上升趋势 -
30天内最高价与120日内最低价之比小于1.55,且120天线和200天线线呈上升趋势 -
30天内最高价与120日内最低价之比小于1.65,且长期均线呈多头排列 -
5天内最高价距离120日内的最高价不到15% -
5天内最高价距离120日内的最高价不到20% -
当天收盘价距离10日内的最高价不到10%
python代码
陶博士 6.4 的公式对应 is_mouth_line_reversal 函数,其他方法是选股方法,采用了多进程,速度还行,全 A 选股一次 26 s左右(本机本系统的测试)。
import multiprocessing
import os
import time
import pandas as pd
import database.stockdatabasev2 as sdb
from config.stockconfigv2 import StockConfigV2
def is_mouth_line_reversal(df: pd.DataFrame) -> list:
"""
陶博士月线反转 6.4
该方法默认本地已经计算好了 rps50、rps120、rps250
df: 列 ['open', 'high', 'low', 'close', 'rps50', 'rps120', 'rps250']
index: 日期
只是翻译陶博士月线反转6.4 的公式,可以优化均值计算,从本地数据库读取数据,为了通用性,这里就没有优化
"""
last_time = time.time()
# {RPS50大于87}
# FYX11赋值:如果RPS50>=87,返回1,否则返回0
FYX11 = df['rps50'].apply(lambda x: True if x >= 87 else False)
# {RPS120大于90}
# FYX12赋值:如果RPS120>=90,返回1,否则返回0
FYX12 = df['rps120'].apply(lambda x: True if x >= 90 else False)
# {当天RPS50或RPS120大于90,在后面被FYX32引用}
# FYX130赋值:RPS50>=90 OR RPS120>=90
c1 = df['rps50'].apply(lambda x: True if x >= 90 else False)
c2 = df['rps120'].apply(lambda x: True if x >= 90 else False)
FYX130 = c1 | c2
# {创70日最高收盘价}
# FYX131赋值:收盘价>=70日内收盘价的最高值
FYX131 = df['close'] >= df['close'].rolling(70).max()
# {创70日新高,且当天RPS50或RPS120大于90。在后面被FYX21、FYX22、FYX63、FYX72等引用}
# FYX13赋值:FYX130 AND FYX131
FYX13 = FYX130 & FYX131
# FYX1赋值:FYX11 OR FYX12
FYX1 = FYX11 | FYX12
# {50日内最低价大于200日内最低价}
# FYX21赋值:50日内最低价的最低值>200日内最低价的最低值 AND FYX13
c1 = df['low'].rolling(50).min() > df['low'].rolling(200).min()
FYX21 = c1 & FYX13
# {30 日内最低价大于120日内最低价,且FYX13}
# FYX22赋值:30日内最低价的最低值>120日内最低价的最低值 AND FYX13
c1 = df['low'].rolling(30).min() > df['low'].rolling(120).min()
FYX22 = c1 & FYX13
# {20日内最低价大于50日内最低价,顺鑫农业2018年4月2日的月线反转信号}
# FYX23赋值:20日内最低价的最低值>50日内最低价的最低值
FYX23 = df['low'].rolling(20).min() > df['low'].rolling(50).min()
# {结构紧凑的重要条件}
# FYX2赋值:FYX21 OR FYX22 OR FYX23
FYX2 = FYX21 | FYX22 | FYX23
# NH80赋值:如果最高价>80日内最高价的最高值,赋值 0,否则赋值1
c1 = df['high'] > df['high'].rolling(80).max()
NH80 = c1.apply(lambda x: 0 if x else 1)
# {10天内曾创80日新高}
# FYX31赋值:统计NH8010日中满足True的天数
FYX31 = NH80.rolling(10).sum() > 0
# {当天创50日最高收盘价或50日最高价,且RPS50或RPS120大于90}
# FYX32赋值:(收盘价>=50日内收盘价的最高值 OR 最高价>=50日内最高价的最高值) AND FYX130
c1 = df['close'] >= df['close'].rolling(50).max()
c2 = df['high'] >= df['high'].rolling(50).max()
FYX32 = (c1 | c2) & FYX130
# FYX3赋值:FYX31 OR FYX32
FYX3 = FYX31 | FYX32
# {当天收盘价必须站上20天线和200天线}
# FYX4赋值:收盘价>收盘价的20日简单移动平均 AND 收盘价>收盘价的200日简单移动平均 AND 收盘价的120日简单移动平均/收盘价的200日简单移动平均>0.9
c1 = df['close'] > df['close'].rolling(20).mean()
c2 = df['close'] > df['close'].rolling(200).mean()
c3 = df['close'].rolling(120).mean() / df['close'].rolling(200).mean() > 0.9
FYX4 = c1 & c2 & c3
# {当天收盘价大于200天线}
# NN200赋值:如果收盘价>收盘价的200日简单移动平均,返回1,否则返回0
c1 = df['close'] > df['close'].rolling(200).mean()
NN200 = c1.apply(lambda x: 1 if x else 0)
# AA200赋值:统计45日中满足NN200的天数
AA200 = NN200.rolling(45).sum()
# {当天收盘价大于250天线}
# NN250赋值:如果收盘价>收盘价的250日简单移动平均,返回1,否则返回0
c1 = df['close'] > df['close'].rolling(250).mean()
NN250 = c1.apply(lambda x: 1 if x else 0)
# AA250赋值:统计45日中满足NN250的天数
AA250 = NN250.rolling(45).sum()
# {45天内,收盘价站上200天线的天数大于等于2,小于45}
# FYX51赋值:AA200>=2 AND AA200<45
FYX51 = (AA200 >= 2) & (AA200 < 45)
# LNN200赋值:如果最低价<收盘价的200日简单移动平均,返回1,否则返回0
c1 = df['low'] < df['close'].rolling(200).mean()
LNN200 = c1.apply(lambda x: 1 if x else 0)
# LAA200赋值:统计45日中满足LNN200的天数
LAA200 = LNN200.rolling(45).sum()
# {45天内,至少有一天的最低价低于200天线;且至少站上200天线3天以上}
# FYX52赋值:LAA200>0 AND AA200>2
FYX52 = (LAA200 > 0) & (AA200 > 2)
# LNN250赋值:如果最低价<收盘价的250日简单移动平均,返回1,否则返回0
c1 = df['low'] < df['close'].rolling(250).mean()
LNN250 = c1.apply(lambda x: 1 if x else 0)
# LAA250赋值:统计45日中满足LNN250的天数
LAA250 = LNN250.rolling(45).sum()
# {45天内,至少有一天的最低价低于250天线;且至少站上250天线3天以上}
# FYX53赋值:LAA250>0 AND AA250>2
FYX53 = (LAA250 > 0) & (AA250 > 2)
# FYX5赋值:FYX51 OR FYX52 OR FYX53
FYX5 = FYX51 | FYX52 | FYX53
# {120天线或200天线呈上升趋势}
# FYX6011赋值:收盘价的120日简单移动平均>=10日前的收盘价的120日简单移动平均 OR 收盘价的200日简单移动平均>=10日前的收盘价的200日简单移动平均
c1 = df['close'].rolling(120).mean() >= df['close'].shift(10).rolling(120).mean()
c2 = df['close'].rolling(200).mean() >= df['close'].shift(10).rolling(200).mean()
FYX6011 = c1 | c2
# {120天线或200天线呈上升趋势}
# FYX6012赋值:收盘价的120日简单移动平均>=15日前的收盘价的120日简单移动平均 OR 收盘价的200日简单移动平均>=15日前的收盘价的200日简单移动平均
c1 = df['close'].rolling(120).mean() >= df['close'].shift(15).rolling(120).mean()
c2 = df['close'].rolling(200).mean() >= df['close'].shift(15).rolling(200).mean()
FYX6012 = c1 | c2
# FYX601赋值:FYX6011 OR FYX6012
FYX601 = FYX6011 | FYX6012
# {120天线和200天线线呈上升趋势}
# FYX6021赋值:收盘价的120日简单移动平均>=10日前的收盘价的120日简单移动平均 AND 收盘价的200日简单移动平均>=10日前的收盘价的200日简单移动平均
c1 = df['close'].rolling(120).mean() >= df['close'].shift(10).rolling(120).mean()
c2 = df['close'].rolling(200).mean() >= df['close'].shift(10).rolling(200).mean()
FYX6021 = c1 & c2
# {120天线和200天线线呈上升趋势}
# FYX6022赋值:收盘价的120日简单移动平均>=15日前的收盘价的120日简单移动平均 AND 收盘价的200日简单移动平均>=15日前的收盘价的200日简单移动平均
c1 = df['close'].rolling(120).mean() >= df['close'].shift(15).rolling(120).mean()
c2 = df['close'].rolling(200).mean() >= df['close'].shift(15).rolling(200).mean()
FYX6022 = c1 & c2
# FYX602赋值:FYX6021 OR FYX6022
FYX602 = FYX6021 | FYX6022
# {120日线、200日线呈多头排列}
# FYX603赋值:收盘价的120日简单移动平均>收盘价的200日简单移动平均 AND FYX601
FYX603 = (df['close'].rolling(120).mean() > df['close'].rolling(200).mean()) & FYX601
# {30天内最高价与120日内最低价之比小于1.50,且120天线或200天线呈上升趋势,石英股份2022年的平台在120天左右}
# FYX61赋值:30日内最高价的最高值/120日内最低价的最低值<1.50 AND FYX601
c1 = df['high'].rolling(30).max() / df['low'].rolling(120).min() < 1.50
FYX61 = c1 & FYX601
# {30天内最高价与120日内最低价之比小于1.55,且120天线和200天线线呈上升趋势}
# FYX62赋值:30日内最高价的最高值/120日内最低价的最低值<1.55 AND FYX602
c1 = df['high'].rolling(30).max() / df['low'].rolling(120).min() < 1.55
FYX62 = c1 & FYX602
# {30天内最高价与120日内最低价之比小于1.65,且长期均线呈多头排列,且满足FYX13}
# FYX63赋值:30日内最高价的最高值/120日内最低价的最低值<1.65 AND FYX603 AND FYX13
c1 = df['high'].rolling(30).max() / df['low'].rolling(120).min() < 1.65
FYX63 = c1 & FYX603 & FYX13
# FYX6赋值:FYX61 OR FYX62 OR FYX63
FYX6 = FYX61 | FYX62 | FYX63
# {5天内最高价距离120日内的最高价不到15 %}
# FYX71赋值:5日内最高价的最高值/120日内最高价的最高值>0.85
c1 = df['high'].rolling(5).max() / df['high'].rolling(120).max() > 0.85
FYX71 = c1
# {5天内最高价距离120日内的最高价不到20 %,且满足FYX13}
# FYX72赋值:5日内最高价的最高值/120日内最高价的最高值>0.8 AND FYX13
c1 = df['high'].rolling(5).max() / df['high'].rolling(120).max() > 0.8
FYX72 = c1 & FYX13
# {当天收盘价距离10日内的最高价不到10 %}
# FYX73赋值:收盘价/10日内最高价的最高值>0.9
c1 = df['close'] / df['high'].rolling(10).max() > 0.9
FYX73 = c1
# FYX7赋值:(FYX71 OR FYX72) AND FYX73
FYX7 = (FYX71 | FYX72) & FYX73
# YXFZ赋值:FYX1 AND FYX2 AND FYX3 AND FYX4 AND FYX5 AND FYX6 AND FYX7
YXFZ = FYX1 & FYX2 & FYX3 & FYX4 & FYX5 & FYX6 & FYX7
# OUT赋值:当满足条件在15周期内首次YXFZ距今天数=0时
OUT = YXFZ.apply(lambda x: 1 if x else 0).rolling(15).sum().apply(lambda x: 1 if x > 0 else 0).diff(1)
# 找出出大于等于1 的日期,并格式化%Y-%m-%d
OUT = OUT[OUT >= 1]
BUY_DATE = OUT.index.strftime('%Y-%m-%d').tolist()
# print(f'耗时:{time.time() - last_time}', '月线反转:', BUY_DATE)
return BUY_DATE
def _mouth_stock_picking_task(
task_index,
part_codes,
start_time,
end_time
):
"""
月线反转选股任务,由于封装好的数据库可以一次性查多个股数据,所以一次性查回来即可
选出来的时最后一个交易日的股票代码,如果需要一段时间的,修改日期判断范围即可
@param part_codes: 任务需要处理的股票代码集合
@param start_time: 开始时间 注意,开始时间必须比结束时间早一年多,否则影响计算结果
@param end_time: 结束时间 注意,结束时间必须是最近一个交易日,否则影响计算结果
"""
last_time = time.time()
# 本地数据库方法,一次性查回所有股票数据股票集合时part_codes
all_stocks_df = sdb.stock_daily(part_codes, start_time, end_time)
picking_list = []
for code in part_codes:
stock_df = all_stocks_df[all_stocks_df['code'] == code]
stock_df.sort_index(inplace=True)
buy_date = is_mouth_line_reversal(stock_df)
# 如果买点日期包含end_time,说明是最近一个交易日的买点
if len(buy_date) > 0 and end_time in buy_date:
picking_list.append(code)
#
# if len(buy_date) > 0:
# picking_list.append(code)
print(f'任务{task_index}耗时:{time.time() - last_time}', '月线反转:', picking_list)
return picking_list
def mouth_line_reversal_stock_picking():
"""
月线反转选股,多进程提速
"""
config = StockConfigV2()
# 本地配置,全 A 的股票代码
stock_codes = config.get_stock_codes()
start_time = '2022-06-01' # 距离最后一个交易日提前一年半
end_time = '2023-12-02' # 最近一个交易日
end_time = config.legal_trade_date(end_time)
last_time = time.time()
picking_list = []
# 根据 cpu 个数拆分股票任务数
cpu_count = os.cpu_count()
item_count = int(len(stock_codes) / cpu_count)
with multiprocessing.Pool(processes=cpu_count) as pool:
futures = []
for sumLen in range(cpu_count):
start_index = sumLen * item_count
end_index = start_index + item_count
# 如果是最后一个任务,索引到最后
if sumLen == cpu_count - 1:
end_index = len(stock_codes)
# 切片,分任务
part_codes = stock_codes[start_index: end_index]
print(f'任务{sumLen} 开始位置:{start_index} 结束位置:{end_index}')
# 异步启动任务
future = pool.apply_async(_mouth_stock_picking_task,
args=(sumLen,
part_codes,
start_time,
end_time)
)
futures.append(future)
# 等待所有任务完毕
pool.close()
pool.join()
# 获取所有任务的返回值
for future in futures:
picking_list += future.get()
print(f'总耗时:{time.time() - last_time}', '月线反转财富代码:', picking_list)
if __name__ == '__main__':
# start_time = '2022-01-01'
# end_time = '2023-12-02'
# stocks_df = sdb.stock_daily('000429', start_time, end_time)
# is_mouth_line_reversal(stocks_df)
mouth_line_reversal_stock_picking()
pass
跑代码日志: 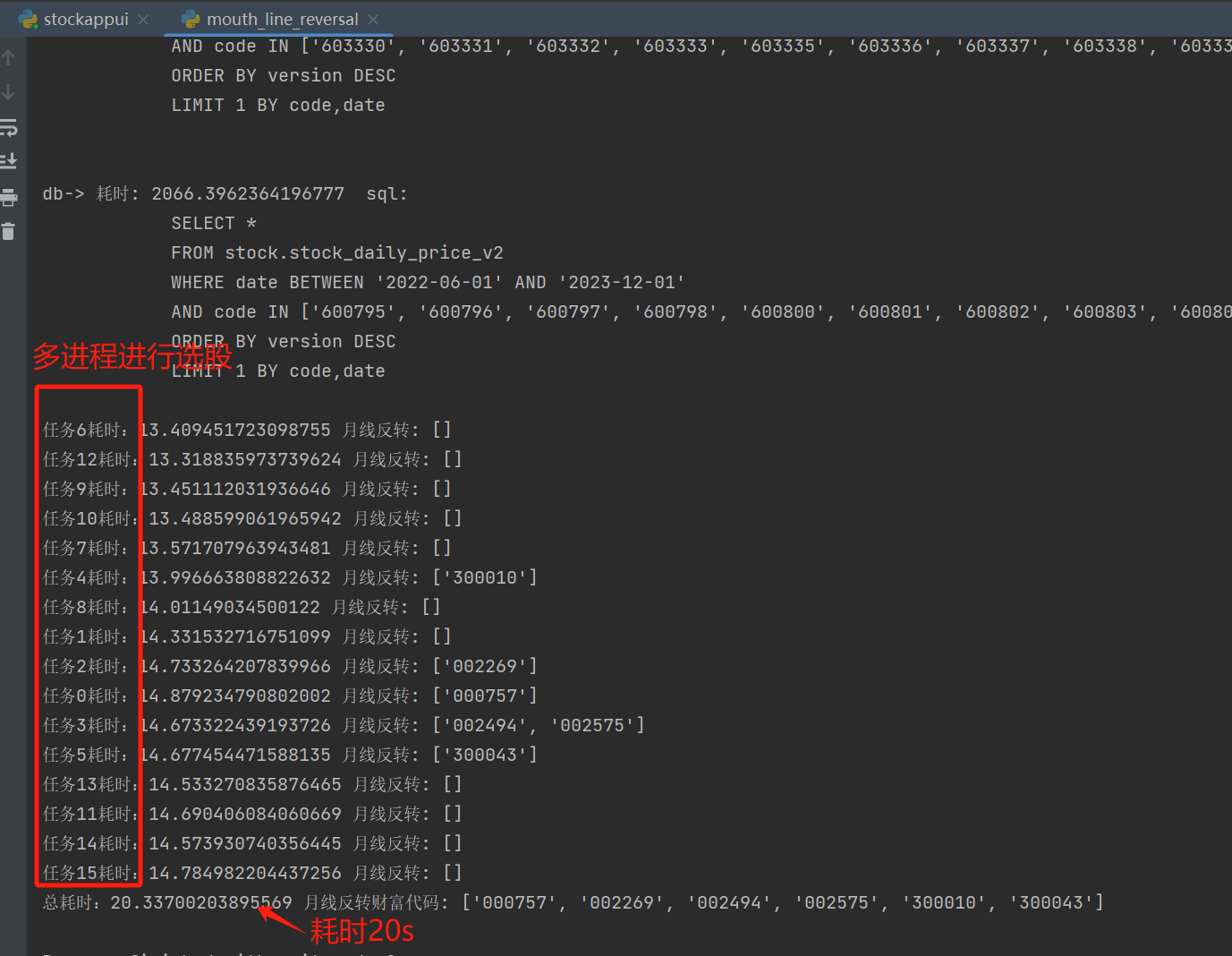
验证
这 python 化的代码到底准不准?我们验证一下出现买点的时间是否和通达信一直即可。由于我的量化系统已经实现了买点标注的功能,验证相对简单。我对比了很多个票,买点位置都是可以对得上的,所以上面的代码是问题不大的。
代码002575
通达信: 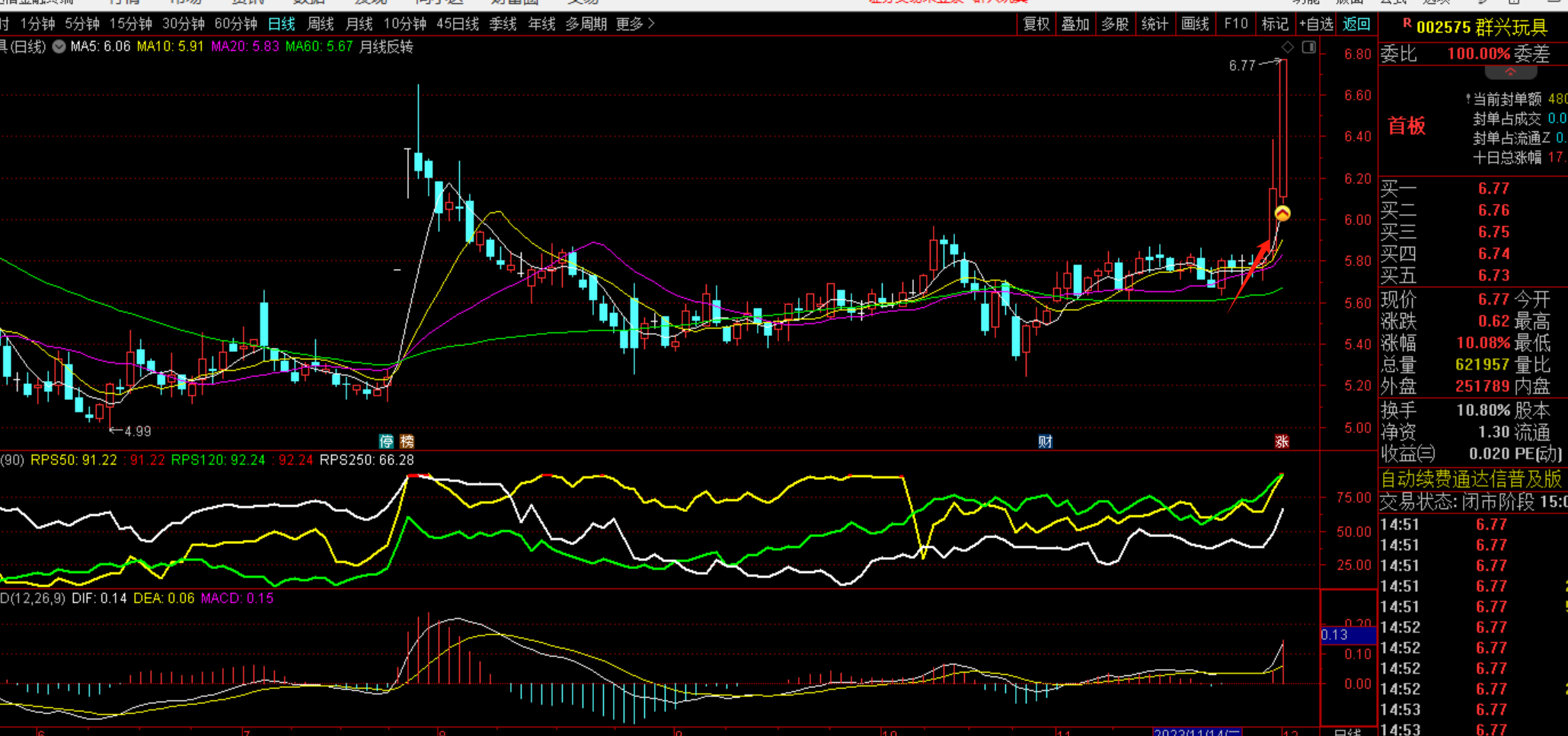 我自己的系统标注:
我自己的系统标注: 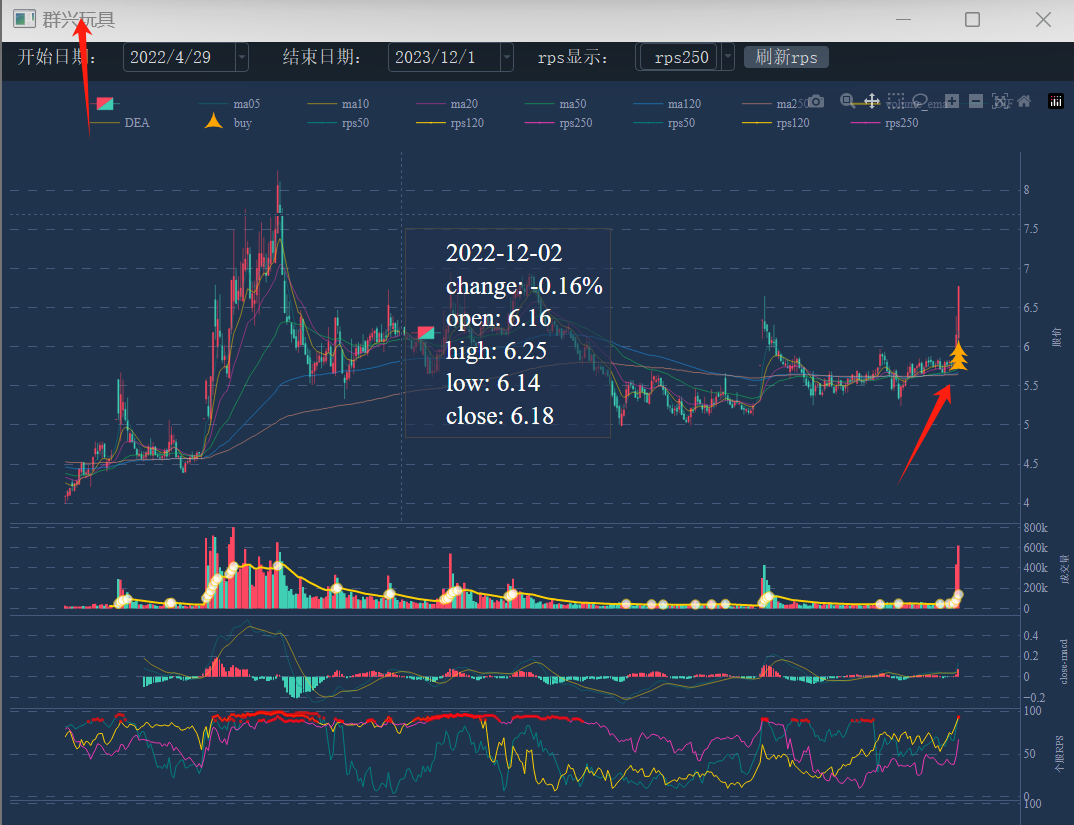
代码300058
通达信: 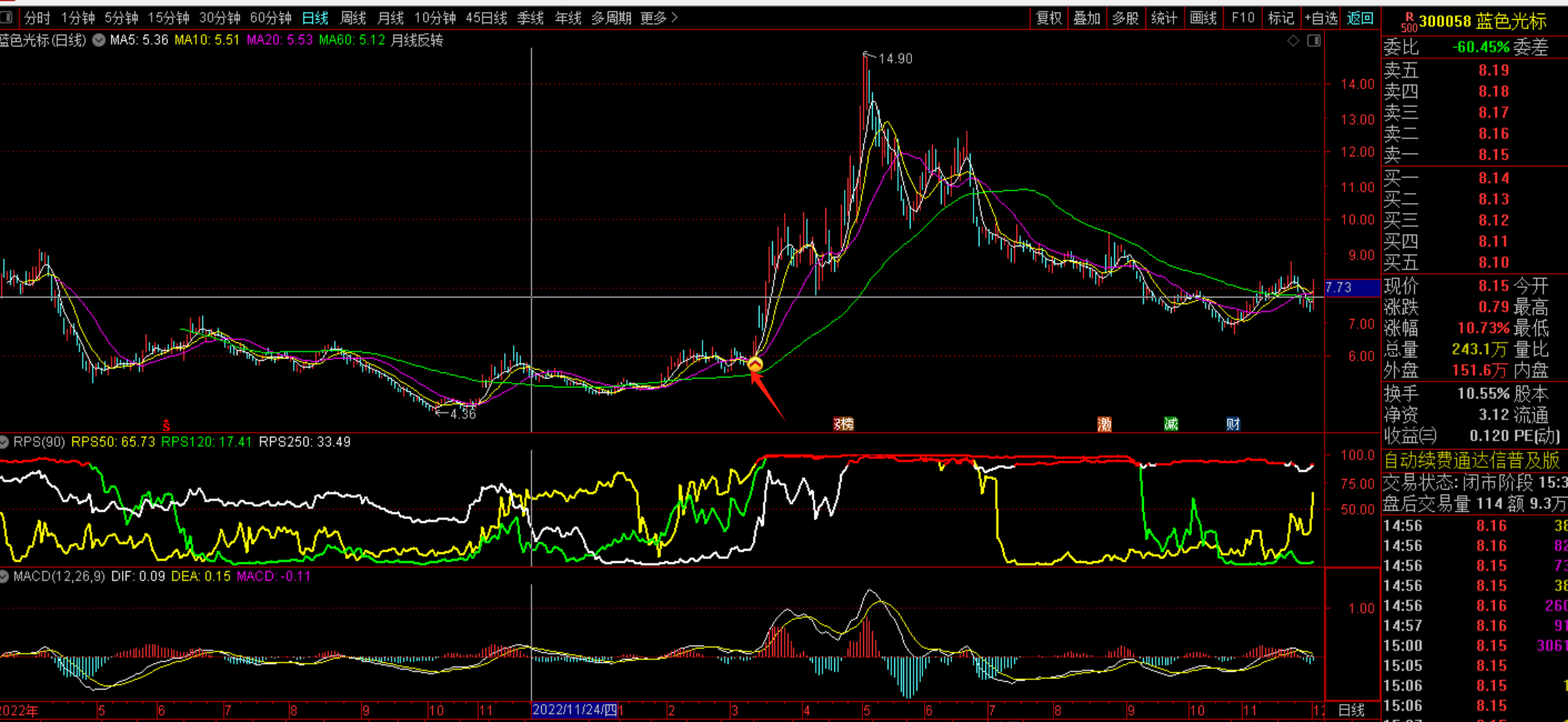 我自己的系统标注:
我自己的系统标注: 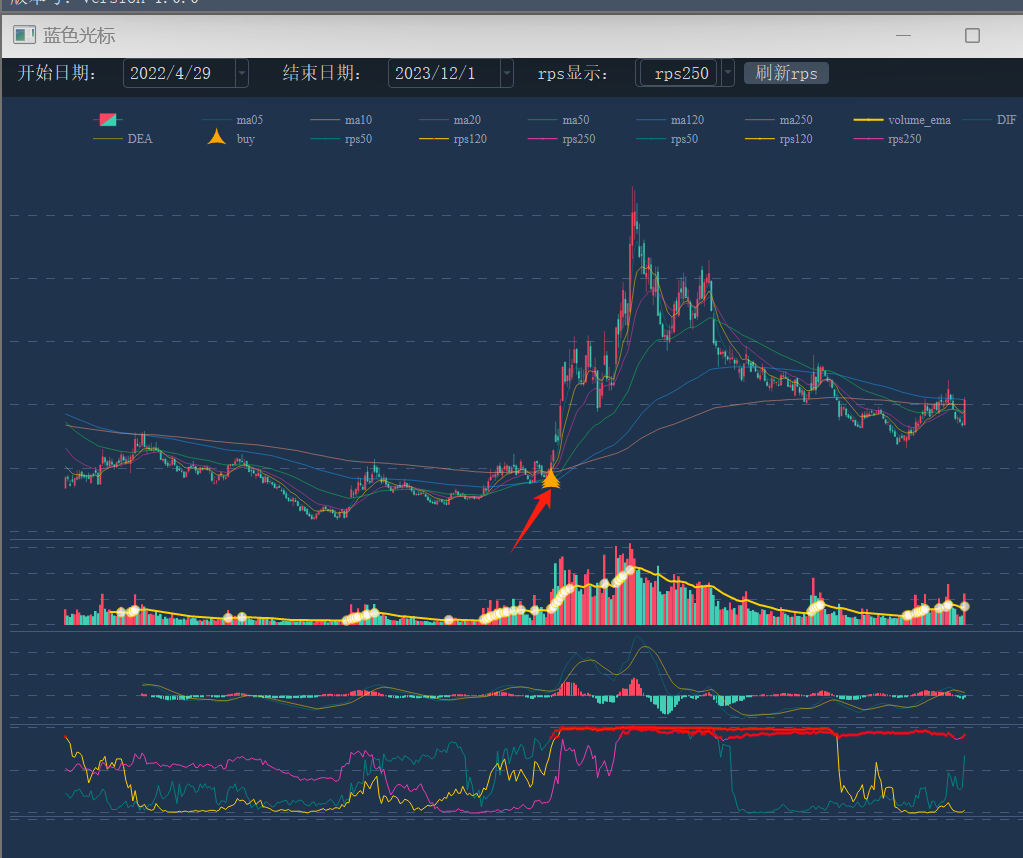
写于 2023 年 12 月 03 日 17:16
本文由 mdnice 多平台发布