文章目录
- 前言
- LeNet-5部署
- 1.ONNX文件导出
- 2.TensorRT构建阶段(TensorRT模型文件)
- 🧁创建Builder
- 🍧创建Network
- 🍭使用onnxparser构建网络
- 🍬优化网络
- 🍡序列化模型
- 🍩释放资源
- 3.TensorRT运行时阶段(推理)
- 🍄创建Runtime
- 🍅反序列化模型
- 🍒创建ExecutionContext
- 🍓执行推理
- 🍎释放资源
- 4.编译和运行
- 结束语
- 💂 个人主页:风间琉璃
- 🤟 版权: 本文由【风间琉璃】原创、在CSDN首发、需要转载请联系博主
- 💬 如果文章对你有
帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦
前言
提示:这里可以添加本文要记录的大概内容:
本文记录一下TensorRT部署流程,上一篇使用wts文件构造网络结构,这篇会使用ONNX构造网络。关于TensorRT的基础知识,参考前一篇文章:TensorRT部署(wts)
LeNet-5部署
1.ONNX文件导出
关于LeNet-5网络模型的搭建、训练以及保存参考上面的链接文字。这一步导出ONNX文件默认你已经有了LeNet-5的权重文件(pth)。
导出ONNX文件源程序如下:
import torch
from model import LeNet
# s实例化网络
model = LeNet()
# 加载网络模型
model.load_state_dict(torch.load('Lenet.pth'))
model.eval()
input_names = ['input']
output_names = ['output']
# 创建一个示例输入
input_data = torch.randn(1, 1, 28, 28) # 根据您的模型需要调整输入尺寸
# 定义输出路径
onnx_file_path = "LeNet.onnx"
# 转换为 ONNX 模型
torch.onnx.export(model, input_data, onnx_file_path, input_names=input_names, output_names=output_names, verbose=True)
将导出的ONNX文件使用Netron打开,Netron链接:Netron
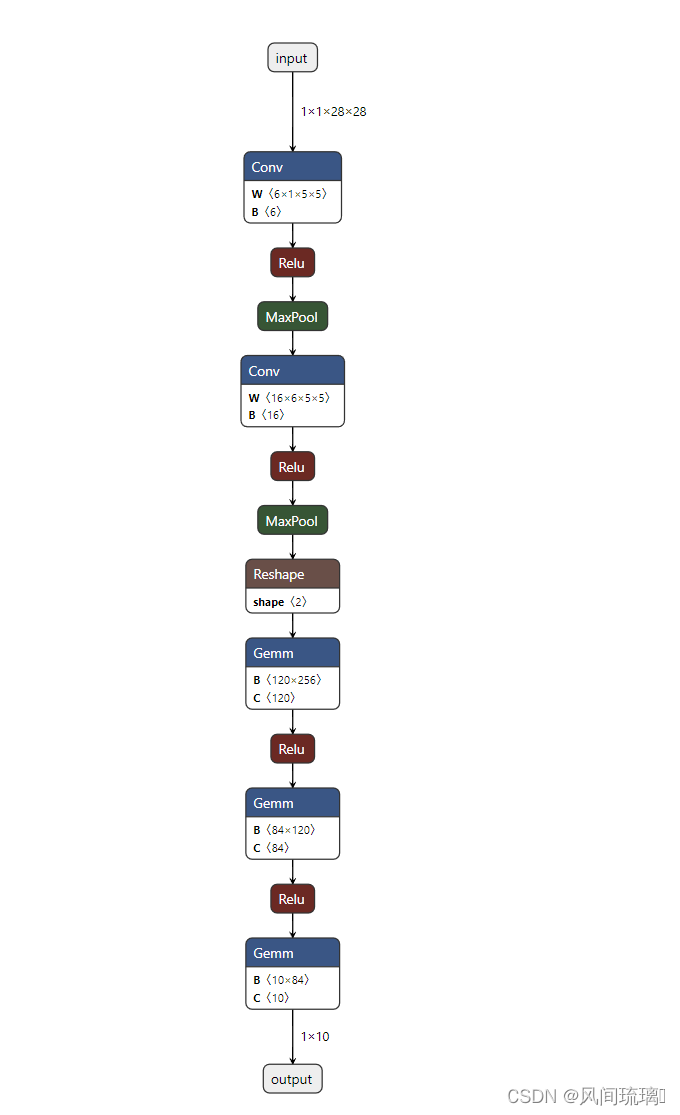
可以看到和我们在model中定义的网络结构是一样的。
2.TensorRT构建阶段(TensorRT模型文件)
🧁创建Builder
// 创建TensorRT的Builder对象
auto builder = std::unique_ptr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(gLogger));
if (!builder)
{
std::cerr << "Failed to create builder" << std::endl;
return -1;
}
使用了TensorRT的createInferBuilder函数创建了一个nvinfer1::IBuilder实例,并将其包装在std::unique_ptr中,这样可以确保在作用域结束时正确释放资源。
std::unique_ptr 的模板参数是 nvinfer1::IBuilder,因此 builder 的类型是 std::unique_ptr< nvinfer1::IBuilder>。这表示 builder 是一个独占所有权的智能指针,管理一个 nvinfer1::IBuilder 类型的对象。在上一节中创建Builder如下
nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(gLogger);
这里 builder 是一个原始指针,你需要手动管理其生命周期和释放内存。这容易导致内存泄漏或悬挂指针问题,因为你需要确保在使用完 builder 后调用 delete 或相应的释放函数。
这里使用了 std::unique_ptr,它是一个 C++ 智能指针,能够自动管理对象的生命周期。当 builder 超出作用域时,std::unique_ptr 会自动释放其拥有的内存。这有助于防止内存泄漏,并提高代码的安全性。
🍧创建Network
在TensorRT中使用builder的成员函数createNetworkV2来构建network。
// 显性batch
const auto explicitBatch = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
// 调用builder的createNetworkV2方法创建network
auto network = std::unique_ptr<nvinfer1::INetworkDefinition>(builder->createNetworkV2(explicitBatch));
if (!network)
{
std::cout << "Failed to create network" << std::endl;
return -1;
}
创建一个 TensorRT 网络,并使用显式批处理标志。显式批处理允许你在运行推理时动态设置批次大小,而不是在构建引擎时固定批次大小。
🍭使用onnxparser构建网络
// 读取ONNX模型文件
char* onnxPath = "/home/mingfei/codeRT/test/lenet_onnx/LeNet.onnx";
std::ifstream onnxFile(onnxPath, std::ios::binary);
if (!onnxFile)
{
std::cerr << "无法打开ONNX模型文件: " << onnxPath << std::endl;
return 1;
}
// 创建onnxparser,用于解析onnx文件
auto parser = std::unique_ptr<nvonnxparser::IParser>(nvonnxparser::createParser(*network, gLogger));
// 调用onnxparser的parseFromFile方法解析onnx文件
auto parsed = parser->parseFromFile(onnxPath, static_cast<int>(gLogger.getReportableSeverity()));
if (!parsed)
{
std::cout << "Failed to parse onnx file" << std::endl;
return -1;
}
首先将上面导出的ONNX文件加载进来,然后使用 TensorRT 的 ONNX 解析器进行解析。
createParser函数创建一个 ONNX 解析器对象,这个解析器对象是一个用于解析 ONNX 模型的实例。
inline IParser* createParser(nvinfer1::INetworkDefinition& network, nvinfer1::ILogger& logger)
network:表示 TensorRT 网络的对象。解析器将根据 ONNX 模型的信息构建这个网络。
logger:日志记录器,用于记录解析器操作的日志信息
parseFromFile函数使用解析器解析来自 ONNX 模型文件的模型信息。
virtual bool parseFromFile(const char* onnxModelFile, int verbosity) = 0;
onnxModelFile:ONNX 模型文件的路径,指定要解析的 ONNX 模型文件。
verbosity:解析过程中的详细程度或冗余程度。这通常是一个整数值,用于控制解析器的输出信息的详细级别。
这两个函数的联合使用允许您创建一个 ONNX 解析器对象,然后使用该解析器对象从文件中读取 ONNX 模型并解析出 TensorRT 网络。解析完成后,您就可以使用 TensorRT 的网络进行后续的优化和推理。
🍬优化网络
添加相关Builder 的配置。createBuilderConfig接口被用来指定TensorRT应该如何优化模型。
// 优化网络
auto config = std::unique_ptr<nvinfer1::IBuilderConfig>(builder->createBuilderConfig());
if (!config)
{
std::cout << "Failed to create config" << std::endl;
return -1;
}
// 设置最大batchsize
builder->setMaxBatchSize(1);
// 设置最大工作空间(新版本的TensorRT已经废弃了setWorkspaceSize)
config->setMemoryPoolLimit(nvinfer1::MemoryPoolType::kWORKSPACE, 1 << 30);
// 设置精度,不设置是FP32,设置为FP16,设置为INT8需要额外设置calibrator
config->setFlag(nvinfer1::BuilderFlag::kFP16);
在示例代码中,仅配置workspace(workspace 就是 tensorrt 里面算子可用的内存空间 )大小、运行时batch size和精度。
🍡序列化模型
使用 TensorRT 的 builder 对象根据配置创建一个序列化的引擎,并将其保存到文件中。
// 使用buildSerializedNetwork方法创建engine,可直接返回序列化的engine(原来的buildEngineWithConfig方法已经废弃,需要先创建engine,再序列化)
auto plan = std::unique_ptr<nvinfer1::IHostMemory>(builder->buildSerializedNetwork(*network, *config));
if (!plan)
{
std::cout << "Failed to create engine" << std::endl;
return -1;
}
// 序列化保存engine
std::ofstream engine_file("lenet5.engine", std::ios::binary);
assert(engine_file.is_open() && "Failed to open engine file");
engine_file.write((char *)plan->data(), plan->size());
engine_file.close();
🍩释放资源
因为使用了智能指针,所以不需要手动释放资源。
构建阶段源程序
#include <iostream>
#include <fstream>
#include <cassert>
#include <vector>
#include <NvInfer.h>
#include <NvOnnxParser.h> // onnxparser头文件
#include "logging.h"
using namespace nvinfer1;
static Logger gLogger;
int main()
{
// 读取ONNX模型文件
char* onnxPath = "/home/mingfei/codeRT/test/lenet_onnx/LeNet.onnx";
std::ifstream onnxFile(onnxPath, std::ios::binary);
if (!onnxFile)
{
std::cerr << "无法打开ONNX模型文件: " << onnxPath << std::endl;
return 1;
}
// 创建TensorRT的Builder对象
auto builder = std::unique_ptr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(gLogger));
if (!builder)
{
std::cerr << "Failed to create builder" << std::endl;
return -1;
}
// 显性batch
const auto explicitBatch = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
// 调用builder的createNetworkV2方法创建network
auto network = std::unique_ptr<nvinfer1::INetworkDefinition>(builder->createNetworkV2(explicitBatch));
if (!network)
{
std::cout << "Failed to create network" << std::endl;
return -1;
}
// 创建onnxparser,用于解析onnx文件
auto parser = std::unique_ptr<nvonnxparser::IParser>(nvonnxparser::createParser(*network, gLogger));
// 调用onnxparser的parseFromFile方法解析onnx文件
auto parsed = parser->parseFromFile(onnxPath, static_cast<int>(gLogger.getReportableSeverity()));
if (!parsed)
{
std::cout << "Failed to parse onnx file" << std::endl;
return -1;
}
// 优化网络
auto config = std::unique_ptr<nvinfer1::IBuilderConfig>(builder->createBuilderConfig());
if (!config)
{
std::cout << "Failed to create config" << std::endl;
return -1;
}
// 设置最大batchsize
builder->setMaxBatchSize(1);
// 设置最大工作空间(新版本的TensorRT已经废弃了setWorkspaceSize)
config->setMemoryPoolLimit(nvinfer1::MemoryPoolType::kWORKSPACE, 1 << 30);
// 设置精度,不设置是FP32,设置为FP16,设置为INT8需要额外设置calibrator
config->setFlag(nvinfer1::BuilderFlag::kFP16);
// 使用buildSerializedNetwork方法创建engine,可直接返回序列化的engine(原来的buildEngineWithConfig方法已经废弃,需要先创建engine,再序列化)
auto plan = std::unique_ptr<nvinfer1::IHostMemory>(builder->buildSerializedNetwork(*network, *config));
if (!plan)
{
std::cout << "Failed to create engine" << std::endl;
return -1;
}
// 序列化保存engine
std::ofstream engine_file("lenet5.engine", std::ios::binary);
assert(engine_file.is_open() && "Failed to open engine file");
engine_file.write((char *)plan->data(), plan->size());
engine_file.close();
// 释放资源
// 因为使用了智能指针,所以不需要手动释放资源
std::cout << "Engine build success!" << std::endl;
return 0;
}
3.TensorRT运行时阶段(推理)
在生成Engine文件后,在推理阶段的流程和上一篇的基本是一样的,这里就简单介绍一下,具体的可以参考前面一篇。
🍄创建Runtime
// 创建推理运行时runtime
auto runtime = std::unique_ptr<nvinfer1::IRuntime>(nvinfer1::createInferRuntime(gLogger.getTRTLogger()));
if (!runtime)
{
std::cout << "runtime create failed" << std::endl;
return -1;
}
🍅反序列化模型
// 反序列化生成engine
// 加载模型文件
auto plan = load_engine_file("lenet5.engine");
// 反序列化生成engine
auto mEngine = std::shared_ptr<nvinfer1::ICudaEngine>(runtime->deserializeCudaEngine(plan.data(), plan.size()));
if (!mEngine)
{
return -1;
}
🍒创建ExecutionContext
// 创建执行上下文context
auto context = std::unique_ptr<nvinfer1::IExecutionContext>(mEngine->createExecutionContext());
if (!context)
{
std::cout << "context create failed" << std::endl;
return -1;
}
🍓执行推理
在进行推理之前需要对输入的图片的图片的进行预处理,预处理的操作需要保持在网络训练的时候的操作一样的,如归一化,减均值等。
cv::Mat preprocess(cv::Mat &image)
{
// 获取图像的形状(高度、宽度和通道数)
int height = image.rows;
int width = image.cols;
int channels = image.channels();
// 打印图像的形状
std::cout << "Image Shape: Height = " << height << ", Width = " << width << ", Channels = " << channels << std::endl;
// 使用blobFromImage函数创建blob
cv::Mat blob;
cv::dnn::blobFromImage(image, blob, 1.0 / 255.0, cv::Size(28, 28), cv::Scalar(0.5));
// 获取图像的形状(高度、宽度和通道数)
height = blob.rows;
width = blob.cols;
channels = blob.channels();
// 打印图像的形状
std::cout << "Blob Shape: Height = " << height << ", Width = " << width << ", Channels = " << channels << std::endl;
return blob;
}
然后将处理后的图片数据转成float的指针类型,为后面的推理做准备。
// 获取blob的数据指针
uchar* ucharData = blob.ptr<uchar>(); // 使用uchar*类型的指针
// 获取图像数据指针
float* data = reinterpret_cast<float*>(ucharData);
然后需要将CPU的数据传输到GPU上进行计算,计算结束后需要将结果传回CPU。
// 执行推理
float prob[OUTPUT_SIZE];
inference(*context, data, prob, 1);
// 执行推理
void inference(nvinfer1::IExecutionContext& context, float* input, float* output, int batchSize)
{
// 获取与上下文相关的引擎
const nvinfer1::ICudaEngine& engine = context.getEngine();
// 为输入和输出设备缓冲区创建指针以传递给引擎
assert(engine.getNbBindings() == 2);
void* buffers[2];
// 为了绑定缓冲区,需要知道输入和输出张量的名称
const int inputIndex = engine.getBindingIndex(INPUT_BLOB_NAME);
const int outputIndex = engine.getBindingIndex(OUTPUT_BLOB_NAME);
// 在设备上创建输入和输出缓冲区
CHECK(cudaMalloc(&buffers[inputIndex], batchSize * 1 * INPUT_H * INPUT_W * sizeof(float)));
CHECK(cudaMalloc(&buffers[outputIndex], batchSize * OUTPUT_SIZE * sizeof(float)));
// 创建流
cudaStream_t stream;
CHECK(cudaStreamCreate(&stream));
// 将输入批量数据异步 DMA 到设备,异步对批量进行推理,然后异步 DMA 输出回主机
CHECK(cudaMemcpyAsync(buffers[inputIndex], input, batchSize * 1 * INPUT_H * INPUT_W * sizeof(float), cudaMemcpyHostToDevice, stream));
//context.enqueue(batchSize, buffers, stream, nullptr); // 新版本中是enqueueV2
context.enqueueV2(buffers, stream, nullptr); // 新版本中是enqueueV2
// 将推理结果从设备拷贝到主机上:output
CHECK(cudaMemcpyAsync(output, buffers[outputIndex], batchSize * OUTPUT_SIZE * sizeof(float), cudaMemcpyDeviceToHost, stream));
cudaStreamSynchronize(stream);
// 释放流和缓冲区
cudaStreamDestroy(stream);
CHECK(cudaFree(buffers[inputIndex]));
CHECK(cudaFree(buffers[outputIndex]));
}
然后就是对结果进行处理,如softmax,这里由于的做的是分类模型,所以需要找到置信度最大的概率和标签。
// softmax
std::vector<float> result = softmax(prob);
// 找到最大值和索引
auto maxElement = std::max_element(result.begin(), result.end());
float maxValue = *maxElement;
int maxIndex = std::distance(result.begin(), maxElement);
// 打印结果
std::cout << "probability: " << maxValue << std::endl;
std::cout << "Number is : " << maxIndex << std::endl;
// 显示
std::ostringstream text;
text << "Predict: " << maxIndex;
cv::resize(image,image,cv::Size(400,400));
cv::putText(image, text.str(), cv::Point(10, 50), cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(0, 255, 0), 1, cv::LINE_AA);
// 保存图像到当前路径
cv::imwrite("output_image.jpg", image);
🍎释放资源
因为使用了unique_ptr,所以不需要手动释放
运行时阶段源程序
#include <iostream>
#include <fstream>
#include <cassert>
#include <vector>
#include <algorithm>
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
#include <NvInfer.h>
#include <NvOnnxParser.h> // onnxparser头文件
#include "logging.h"
static Logger gLogger;
static const int INPUT_H = 28;
static const int INPUT_W = 28;
static const int OUTPUT_SIZE = 10;
const char* INPUT_BLOB_NAME = "input";
const char* OUTPUT_BLOB_NAME = "output";
#define CHECK(status) \
do\
{\
auto ret = (status);\
if (ret != 0)\
{\
std::cerr << "Cuda failure: " << ret << std::endl;\
abort();\
}\
} while (0)
// 加载模型文件
std::vector<unsigned char> load_engine_file(const std::string &file_name)
{
std::vector<unsigned char> engine_data;
// 打开二进制文件流
std::ifstream engine_file(file_name, std::ios::binary);
// 检查文件是否成功打开
assert(engine_file.is_open() && "Unable to load engine file.");
// 定位到文件末尾以获取文件长度
engine_file.seekg(0, engine_file.end);
int length = engine_file.tellg();
// 调整容器大小以存储整个文件的数据
engine_data.resize(length);
// 重新定位到文件开头
engine_file.seekg(0, engine_file.beg);
// 读取文件数据到容器中
engine_file.read(reinterpret_cast<char *>(engine_data.data()), length);
return engine_data;
}
cv::Mat preprocess(cv::Mat &image)
{
// 获取图像的形状(高度、宽度和通道数)
int height = image.rows;
int width = image.cols;
int channels = image.channels();
// 打印图像的形状
std::cout << "Image Shape: Height = " << height << ", Width = " << width << ", Channels = " << channels << std::endl;
// 使用blobFromImage函数创建blob
cv::Mat blob;
cv::dnn::blobFromImage(image, blob, 1.0 / 255.0, cv::Size(28, 28), cv::Scalar(0.5));
// 获取图像的形状(高度、宽度和通道数)
height = blob.rows;
width = blob.cols;
channels = blob.channels();
// 打印图像的形状
std::cout << "Blob Shape: Height = " << height << ", Width = " << width << ", Channels = " << channels << std::endl;
return blob;
}
std::vector<float> softmax(const float input[10])
{
std::vector<float> result(10);
float sum = 0.0;
// Calculate e^x for each element in the input array
for (int i = 0; i < 10; ++i) {
result[i] = std::exp(input[i]);
sum += result[i];
}
// Normalize the values by dividing each element by the sum
for (float& value : result) {
value /= sum;
}
return result;
}
// 执行推理
void inference(nvinfer1::IExecutionContext& context, float* input, float* output, int batchSize)
{
// 获取与上下文相关的引擎
const nvinfer1::ICudaEngine& engine = context.getEngine();
// 为输入和输出设备缓冲区创建指针以传递给引擎
assert(engine.getNbBindings() == 2);
void* buffers[2];
// 为了绑定缓冲区,需要知道输入和输出张量的名称
const int inputIndex = engine.getBindingIndex(INPUT_BLOB_NAME);
const int outputIndex = engine.getBindingIndex(OUTPUT_BLOB_NAME);
// 在设备上创建输入和输出缓冲区
CHECK(cudaMalloc(&buffers[inputIndex], batchSize * 1 * INPUT_H * INPUT_W * sizeof(float)));
CHECK(cudaMalloc(&buffers[outputIndex], batchSize * OUTPUT_SIZE * sizeof(float)));
// 创建流
cudaStream_t stream;
CHECK(cudaStreamCreate(&stream));
// 将输入批量数据异步 DMA 到设备,异步对批量进行推理,然后异步 DMA 输出回主机
CHECK(cudaMemcpyAsync(buffers[inputIndex], input, batchSize * 1 * INPUT_H * INPUT_W * sizeof(float), cudaMemcpyHostToDevice, stream));
//context.enqueue(batchSize, buffers, stream, nullptr); // 新版本中是enqueueV2
context.enqueueV2(buffers, stream, nullptr); // 新版本中是enqueueV2
// 将推理结果从设备拷贝到主机上:output
CHECK(cudaMemcpyAsync(output, buffers[outputIndex], batchSize * OUTPUT_SIZE * sizeof(float), cudaMemcpyDeviceToHost, stream));
cudaStreamSynchronize(stream);
// 释放流和缓冲区
cudaStreamDestroy(stream);
CHECK(cudaFree(buffers[inputIndex]));
CHECK(cudaFree(buffers[outputIndex]));
}
int main()
{
// 读取图像
cv::Mat image = cv::imread("/home/mingfei/codeRT/test/lenet_onnx/8.jpg");
// 检查图像是否成功加载
if (image.empty()) {
std::cerr << "Error: Unable to read the image." << std::endl;
return -1;
}
// 创建推理运行时runtime
auto runtime = std::unique_ptr<nvinfer1::IRuntime>(nvinfer1::createInferRuntime(gLogger.getTRTLogger()));
if (!runtime)
{
std::cout << "runtime create failed" << std::endl;
return -1;
}
// 反序列化生成engine
// 加载模型文件
auto plan = load_engine_file("lenet5.engine");
// 反序列化生成engine
auto mEngine = std::shared_ptr<nvinfer1::ICudaEngine>(runtime->deserializeCudaEngine(plan.data(), plan.size()));
if (!mEngine)
{
return -1;
}
// 创建执行上下文context
auto context = std::unique_ptr<nvinfer1::IExecutionContext>(mEngine->createExecutionContext());
if (!context)
{
std::cout << "context create failed" << std::endl;
return -1;
}
// 图像预处理
cv::Mat blob = preprocess(image);
// 获取blob的数据指针
uchar* ucharData = blob.ptr<uchar>(); // 使用uchar*类型的指针
// 获取图像数据指针
float* data = reinterpret_cast<float*>(ucharData);
// 执行推理
float prob[OUTPUT_SIZE];
inference(*context, data, prob, 1);
// softmax
std::vector<float> result = softmax(prob);
// 找到最大值和索引
auto maxElement = std::max_element(result.begin(), result.end());
float maxValue = *maxElement;
int maxIndex = std::distance(result.begin(), maxElement);
// 打印结果
std::cout << "probability: " << maxValue << std::endl;
std::cout << "Number is : " << maxIndex << std::endl;
// 显示
std::ostringstream text;
text << "Predict: " << maxIndex;
cv::resize(image,image,cv::Size(400,400));
cv::putText(image, text.str(), cv::Point(10, 50), cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(0, 255, 0), 1, cv::LINE_AA);
// 保存图像到当前路径
cv::imwrite("output_image.jpg", image);
// 释放资源
// 因为使用了unique_ptr,所以不需要手动释放
return 0;
}
4.编译和运行
整个工程如下所示:
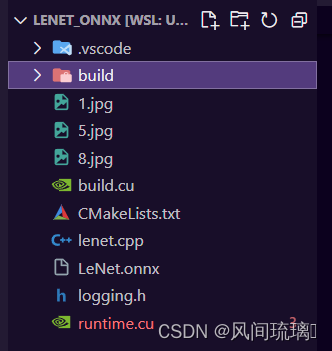
使用CMakeLists.txt来构建整个工程,lenet.cpp相当于集成了build.cu和runtime.cu,然后将生成的文件保存在build目录下。
- 生成可执行程序:
cmake -S . -B build (–> Makefile)
cmake --build build (–>可执行程序) - 运行可执行程序:
./build/build
./build/runtime
CMakeLists.txt如下,相较于上一个wts工程,需要添加nvonnxparser库的链接,其他基本是一样的。
cmake_minimum_required(VERSION 3.10)
# 支持c++和cuda编译(nvcc)
project(lenet5 LANGUAGES CXX CUDA)
add_definitions(-std=c++11)
option(CUDA_USE_STATIC_CUDA_RUNTIME OFF)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_BUILD_TYPE Debug)
include_directories(${PROJECT_SOURCE_DIR}/include)
# include and link dirs of cuda and tensorrt, you need adapt them if yours are different
# cuda
include_directories(/usr/local/cuda/include)
link_directories(/usr/local/cuda/lib64)
# tensorrt
include_directories(/usr/include/x86_64-linux-gnu/)
link_directories(/usr/lib/x86_64-linux-gnu/)
# opencv
find_package(OpenCV REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS})
# 生成engine
add_executable(build_engine ${PROJECT_SOURCE_DIR}/build.cu)
target_link_libraries(build_engine nvinfer)
target_link_libraries(build_engine cudart)
target_link_libraries(build_engine nvonnxparser)
target_link_libraries(build_engine ${OpenCV_LIBS})
# predict
add_executable(runtime ${PROJECT_SOURCE_DIR}/runtime.cu)
target_link_libraries(runtime nvinfer)
target_link_libraries(runtime cudart)
target_link_libraries(runtime nvonnxparser)
target_link_libraries(runtime ${OpenCV_LIBS})
add_definitions(-O2 -pthread)
运行结果如下:


结束语
感谢阅读吾之文章,今已至此次旅程之终站 🛬。
吾望斯文献能供尔以宝贵之信息与知识也 🎉。
学习者之途,若藏于天际之星辰🍥,吾等皆当努力熠熠生辉,持续前行。
然而,如若斯文献有益于尔,何不以三连为礼?点赞、留言、收藏 - 此等皆以证尔对作者之支持与鼓励也 💞。