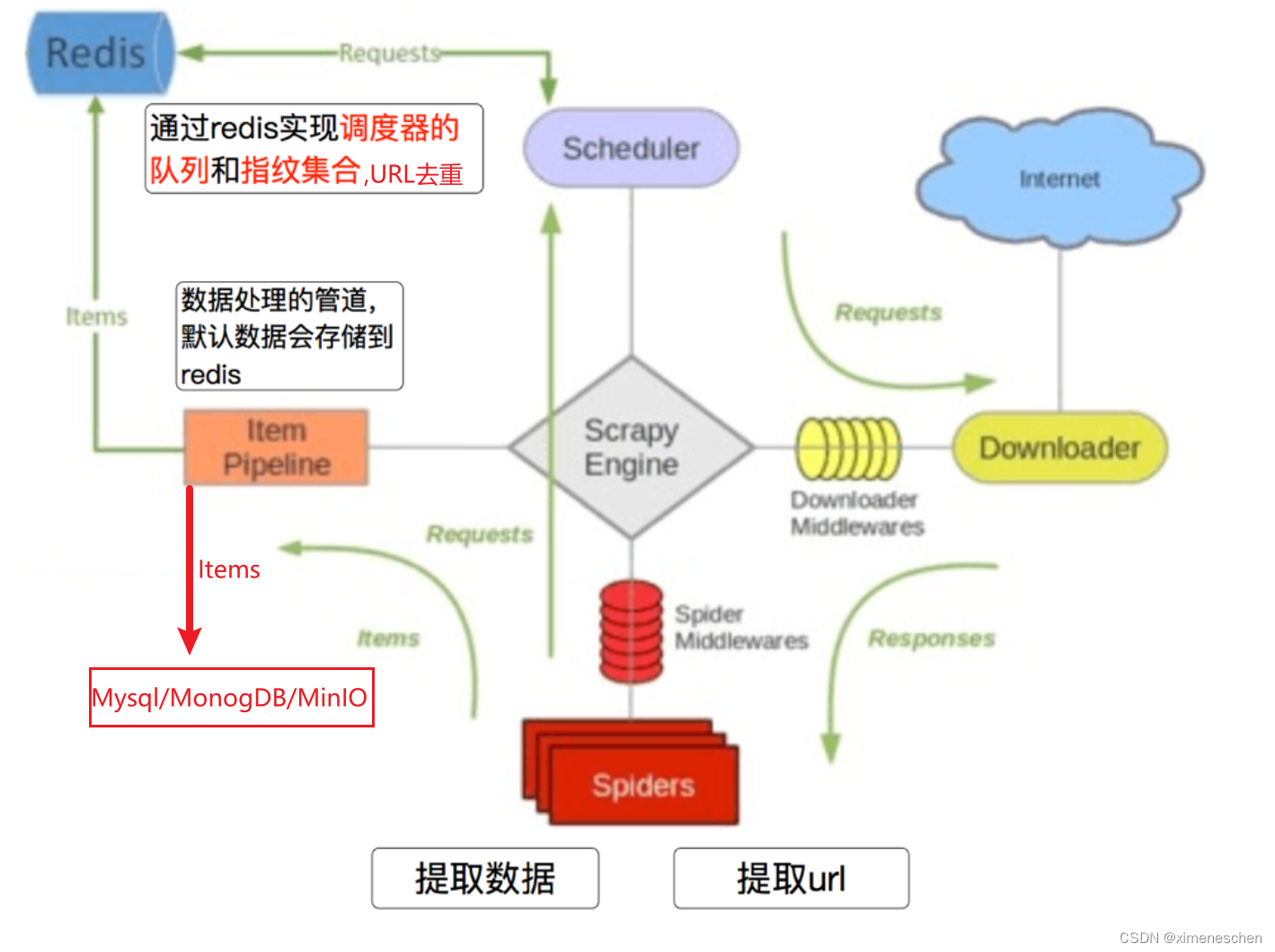
一、什么是scrapy-redis
Scrapy-Redis 是 Scrapy 框架的一个扩展,它提供了对 Redis 数据库的支持,用于实现分布式爬取。通过使用 Scrapy-Redis,你可以将多个 Scrapy 进程连接到同一个 Redis 服务器,共享任务队列和去重集,从而实现爬虫的分布式调度。
- 主要特点和功能包括:
分布式爬取支持: Scrapy-Redis 允许多个 Scrapy进程协同工作,它们可以在不同的机器上运行,共享任务队列和去重集,提高爬取效率。
基于 Redis 的任务调度:
使用 Redis 作为任务队列,爬虫可以从中获取待爬取的URL,实现异步的、分布式的任务调度。基于 Redis 的去重: 利用 Redis 提供的集合数据结构,
Scrapy-Redis 可以在分布式环境中进行URL去重,确保相同的URL在不同的爬虫进程中不会被重复爬取。支持增量爬取: 通过保存爬取状态,Scrapy-Redis 可以支持增量爬取,爬虫可以在上次中断的位置继续执行。
使用简单: Scrapy-Redis 尽量
与原生的 Scrapy保持一致,使用起来相对简单,只需添加一些配置和稍微修改爬虫代码即可实现分布式爬取。
使用 Scrapy-Redis 需要安装对应的扩展,然后在 Scrapy 项目的配置文件中进行相应的设置,如配置 Redis 的地址和端口等。通过合理配置,Scrapy-Redis 可以使你的爬虫更适应大规模和分布式的爬取任务。
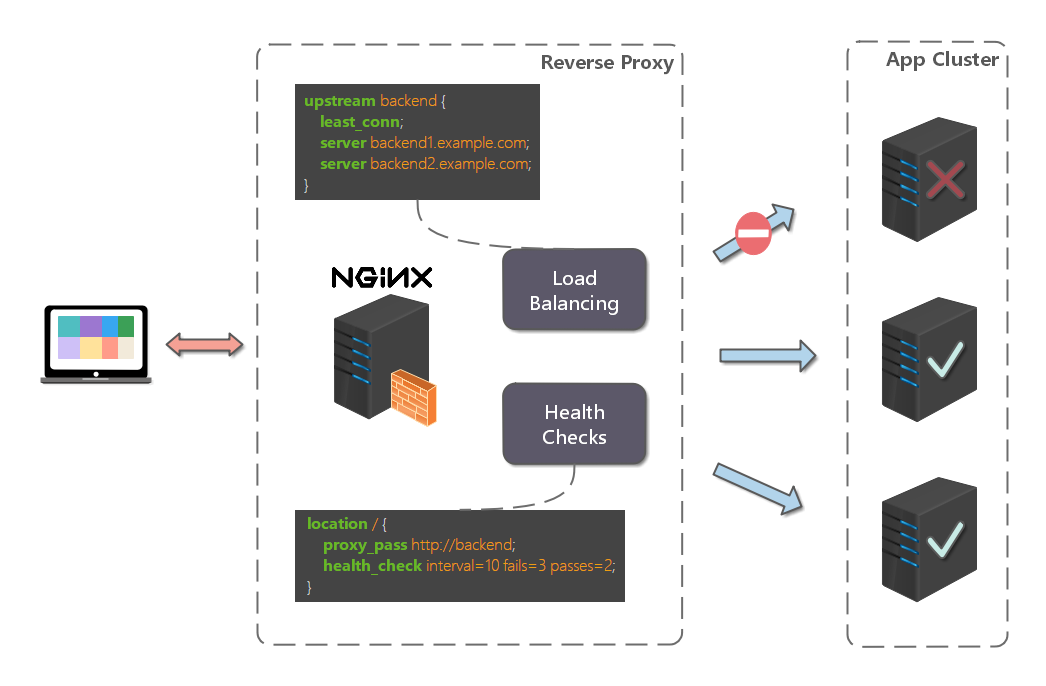
- 示意图:
二、将scrapy项目改造成scrapy-redis项目
- 步骤
- 1.导入scraoy_redis模块中的分布式爬虫类RedisSpider
- 2.继承该爬虫类
- 3.注销start_urls 和allowed_domains
- 4.设置redis_key以获取start_urls
- 5.设置__init__获取允许的域
- 6.编写配置文件
- 例子:
普通爬虫文件:
import scrapy
class BaiduSpider(scrapy.Spider):
name = "baidu"
allowed_domains = ["baidu.com"]
start_urls = ["http://baidu.com/","http://baidu1.com/"]
def parse(self, response):
# 在这里处理初始页面的响应
title = response.css('h1::text').get()
self.log(f'Title on page {response.url}: {title}')
# 提取页面中的链接并继续爬取
links = response.css('a::attr(href)').getall()
for link in links:
yield scrapy.Request(url=link, callback=self.parse_link)
def parse_link(self, response):
# 在这里处理链接页面的响应
title = response.css('h1::text').get()
self.log(f'Title on linked page {response.url}: {title}')
# 提取链接页面中的更多链接并继续爬取
more_links = response.css('a::attr(href)').getall()
for more_link in more_links:
# 使用 yield 关键字将请求对象输出,使其成为一个生成器。
# 这样做的目的是让 Scrapy 异步执行这个请求,允许爬虫同时处理多个请求,提高爬取效率
yield scrapy.Request(url=more_link, callback=self.parse_link)
改造后的文件
#将普通spider文件改为分布式spider的步骤
# 1.导入scraoy_redis中的分布式爬虫类RedisSpider
# 2.继承该爬虫类
# 3.注销start_urls 和allowed_domains
# 4.设置redis_key以获取start_urls
# 5.设置__init__获取允许的域
# 6.编写配置文件
from scrapy_redis.spiders import RedisSpider
class MyRedisSpider(RedisSpider):
name='baidu'
redis_key = 'baidu_spider:start_urls'
def __init__(self,*arge,**kwargs):
# 动态定义允许的domain list(启动时传参数,可传可不传)
# scrapy runspider baidu.py -a domain=example.com,example2.com
# 注意 runspider用于启动一个py文件的爬虫,而crawl则可以启动项目路径下的多个爬虫
domain = kwargs.pop('domain','')
# 如果你不传 'domain' 参数启动爬虫,它仍然可以正常运行
# 只是 self.allowed_domains 将被设置为一个空列表,这意味着爬虫会爬取所有域名
self.allowed_domains=list(filter(None,domain.split(',')))
super(MyRedisSpider,self).__init__(*arge,**kwargs)
def parse(self, response):
title = response.css('h1::text').get()
self.log(f'Title on page {response.url}: {title}')
links = response.css('a::attr(href)').getall()
for link in links:
# 使用 yield self.make_request_from_data(link) 代替 scrapy.Request
yield self.make_request_from_data(link)
def parse_link(self, response):
title = response.css('h1::text').get()
self.log(f'Title on linked page {response.url}: {title}')
more_links = response.css('a::attr(href)').getall()
for more_link in more_links:
# 使用 yield self.make_request_from_data(more_link) 代替 scrapy.Request
yield self.make_request_from_data(more_link)
- 注意 runspider用于启动一个py文件的爬虫,而crawl则可以启动项目路径下的多个爬虫
三、配置文件
#Resis 设置
#使能Redis调度器
SCHEDULER = 'scrapy_redis.scheduler.Scheduler'
#所有spider通过redis使用同一个去重过滤器
DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'
#不清除Redis队列、这样可以暂停/恢复 爬取
#SCHEDULER_PERSIST = True
#SCHEDULER_QUEUE_CLASS ='scrapy_redis.queue.PriorityQueue' #默认队列,优先级队列
#备用队列。
#SCHEDULER_QUEUE_CLASS ='scrapy_redis.queue.FifoQueue' #先进先出队列
#SCHEDULER_QUEUE_CLASS ='scrapy_redis.queue.LifoQueue' #后进先出队列
#最大空闲时间防止分布式爬虫因为等待而关闭
#SCHEDULER_IDLE_BEFORE_CLOSE = 10
#将抓取的item存储在Redis中以进行后续处理。
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline':300,
}
# The item pipeline serializes and stores the items in this redis key.
#item pipeline 将items 序列化 并用如下key名储存在redis中
#REDIS_ITEMS_KEY = '%(spider)s:items'
#默认的item序列化方法是ScrapyJSONEncoder,你也可以使用自定义的序列化方式
#REDIS_ITEMS_SERIALIZER = 'json.dumps'
#设置redis地址 端口 密码
REDIS_HOST = 'localhost'
REDIS_HOST = 6379
#也可以通过下面这种方法设置redis地址 端口和密码,一旦设置了这个,则会覆盖上面所设置的REDIS_HOST和REDIS_HOST
REDIS_URL = 'redis://root:redis_pass@xxx.xx.xx.xx:6379'
#root用户名,redis_pass:你设置的redis验证密码,xxxx:你的主机ip
#你设置的redis其他参数 Custom redis client parameters (i.e.: socket timeout, etc.)
REDIS_PARAMS = {}
#自定义的redis客户端类
#REDIS_PARAMS['redis_cls'] = 'myproject.RedisClient'
# If True, it uses redis ``zrevrange`` and ``zremrangebyrank`` operation. You have to use the ``zadd``
# command to add URLS and Scores to redis queue. This could be useful if you
# want to use priority and avoid duplicates in your start urls list.
#REDIS_START_URLS_AS_SET = False
# 默认的RedisSpider 或 RedisCrawlSpider start urls key
#REDIS_START_URLS_KEY = '%(name)s:start_urls'
#redis的默认encoding是utf-8,如果你想用其他编码可以进行如下设置:
#REDIS_ENCODING = 'latin1'