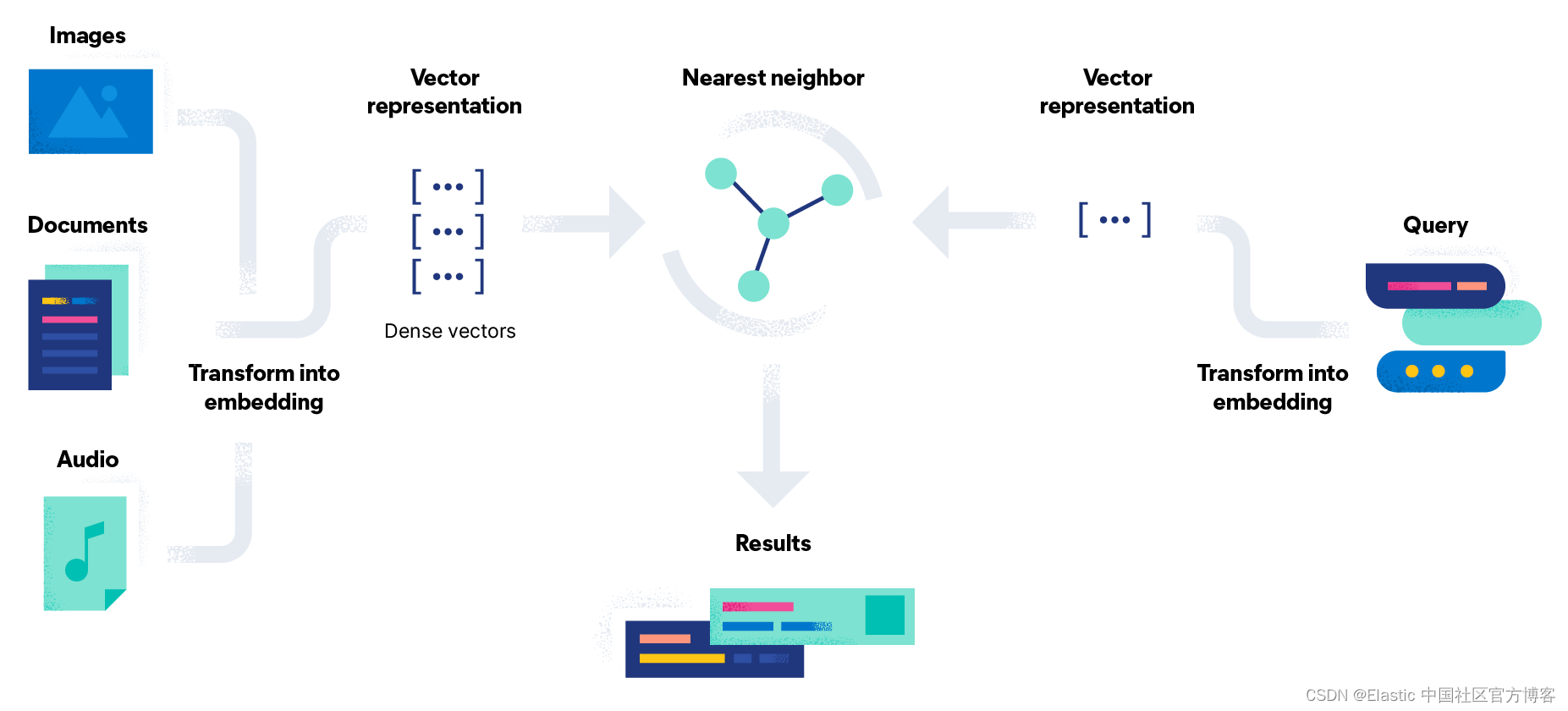
向量嵌入定义
向量嵌入 (vector embeddings) 是一种将单词、句子和其他数据转换为捕获其含义和关系的数字的方法。 它们将不同的数据类型表示为多维空间中的点,其中相似的数据点更紧密地聚集在一起。 这些数字表示可以帮助机器更有效地理解和处理这些数据。
单词和句子嵌入是向量嵌入的两种最常见的子类型,但还有其他子类型。 一些向量嵌入可以表示整个文档,以及旨在匹配视觉内容的图像向量、用于确定用户偏好的用户配置文件向量、帮助识别相似产品的产品向量等等。 向量嵌入可帮助机器学习算法找到数据中的模式并执行情感分析、语言翻译、推荐系统等任务。
向量嵌入的类型
有几种不同类型的向量嵌入常用于各种应用中。 这里有一些例子:
- 词嵌入将单个词表示为向量。 Word2Vec、GloVe 和 FastText 等技术通过从大型文本语料库中捕获语义关系和上下文信息来学习词嵌入。
- 句子嵌入将整个句子表示为向量。 Universal Sentence Encoder (USE) 和 SkipThought 等模型生成的嵌入可以捕获句子的整体含义和上下文。
- 文档嵌入将文档(从报纸文章、学术论文到书籍的任何内容)表示为向量。 它们捕获整个文档的语义信息和上下文。 Doc2Vec 和段落向量等技术旨在学习文档嵌入。
- 图像嵌入通过捕获不同的视觉特征将图像表示为向量。 卷积神经网络 (CNN) 等技术以及 ResNet 和 VGG 等预训练模型可为图像分类、对象检测和图像相似性等任务生成图像嵌入。
- 用户嵌入将系统或平台中的用户表示为向量。 它们捕获用户偏好、行为和特征。 用户嵌入可用于从推荐系统到个性化营销以及用户细分的所有领域。
- 产品嵌入将电子商务或推荐系统中的产品表示为向量。 它们捕获产品的属性、功能和任何其他可用的语义信息。 然后,算法可以使用这些嵌入根据产品的向量表示来比较、推荐和分析产品。
嵌入和向量是同一回事吗?
在向量嵌入的背景下,是的,嵌入和向量是同一件事。 两者都指的是数据的数字表示,其中每个数据点都由高维空间中的向量表示。
术语 “向量” 仅指具有特定维度的数字数组。 在向量嵌入的情况下,这些向量表示连续空间中上述的任何数据点。 相反,“嵌入” 特指将数据表示为向量的技术,以捕获有意义的信息、语义关系或上下文特征。 嵌入旨在捕获数据的底层结构或属性,通常通过训练算法或模型来学习。
虽然嵌入和向量可以在向量嵌入的上下文中互换使用,但 “嵌入” 强调以有意义和结构化的方式表示数据的概念,而 “向量” 指的是数字表示本身。
向量嵌入是如何创建的?
向量嵌入是通过机器学习过程创建的,其中训练模型将上面列出的任何数据(以及其他数据)转换为数值向量。 以下是其工作原理的快速概述:
- 首先,收集一个大型数据集,该数据集表示你要为其创建嵌入的数据类型,例如文本或图像。
- 接下来,你将对数据进行预处理。 这需要根据你正在使用的数据类型,通过消除噪声、规范化文本、调整图像大小或执行各种其他任务来清理和准备数据。
- 你将选择一个最适合你的数据目标的神经网络模型,并将预处理的数据输入到模型中。
- 该模型通过在训练期间调整其内部参数来学习数据中的模式和关系。 例如,它学习将经常一起出现的单词关联起来或识别图像中的视觉特征。
- 当模型学习时,它会生成表示数据含义或特征的数值向量(或嵌入)。 每个数据点(例如单词或图像)都由唯一的向量表示。
- 此时,你可以通过测量嵌入在特定任务上的性能或使用人工来评估给定结果的相似程度来评估嵌入的质量和有效性。
- 一旦您判断嵌入运行良好,你就可以将它们用于分析和处理你的数据集。
向量嵌入是什么样的?
向量的长度或维数取决于你使用的特定嵌入技术以及你希望如何表示数据。 例如,如果你正在创建词嵌入,它们的尺寸通常从几百到几千不等 —— 这对于人类来说太复杂了,无法直观地绘制图表。 句子或文档嵌入可能具有更高的维度,因为它们捕获更复杂的语义信息。
向量嵌入本身通常表示为数字序列,例如 [0.2, 0.8, -0.4, 0.6, ...]。 序列中的每个数字对应于特定的特征或维度,并有助于数据点的整体表示。 也就是说,向量中的实际数字本身没有意义。 数字之间的相对值和关系捕获语义信息并允许算法有效地处理和分析数据。
向量嵌入的应用
向量嵌入在各个领域都有广泛的应用。 以下是你可能会遇到的一些常见问题:
- 自然语言处理 (NLP) 广泛使用向量嵌入来执行情感分析、命名实体识别、文本分类、机器翻译、问答和文档相似性等任务。 通过使用嵌入,算法可以更有效地理解和处理文本相关数据。
- 搜索引擎使用向量嵌入来检索信息并帮助识别语义关系。 向量嵌入帮助搜索引擎接受用户查询并返回相关的主题网页、推荐文章、更正查询中拼写错误的单词以及建议用户可能认为有帮助的类似相关查询。 该应用程序通常用于支持语义搜索。
- 个性化推荐系统利用向量嵌入来捕获用户偏好和项目特征。 它们根据用户与向量中的项目之间的密切匹配,帮助将用户个人资料与用户可能喜欢的项目(例如产品、电影、歌曲或新闻文章)进行匹配。 一个熟悉的例子是 Netflix 的推荐系统。 有没有想过它是如何选择符合你口味的电影的? 它通过使用项目相似性度量来建议与用户通常观看的内容相似的内容。
- 视觉内容也可以通过向量嵌入进行分析。 在此类向量嵌入上训练的算法可以对图像进行分类、识别对象并在其他图像中检测它们、搜索相似图像以及将所有类型的图像(以及视频)分类为不同的类别。 Google Lens 使用的图像识别技术是一种常用的图像分析工具。
- 异常检测算法使用向量嵌入来识别各种数据类型中的异常模式或异常值。 该算法对代表正常行为的嵌入进行训练,以便它可以学习发现与规范的偏差,这些偏差可以根据嵌入之间的距离或相异性度量来检测。 这在网络安全应用程序中特别方便。
- 图分析使用图嵌入,其中图是由线(称为边)连接的点(称为节点)的集合。 每个节点代表一个实体,例如人、网页或产品,每条边代表这些实体之间的关系或连接。 这些向量嵌入可以做很多事情,从在社交网络中推荐朋友到检测网络安全异常(如上所述)。
- 音频和音乐也可以被处理和嵌入。 向量嵌入捕获音频特征,使算法能够有效地分析音频数据。 这可用于各种应用,例如音乐推荐、流派分类、音频相似性搜索、语音识别和说话人验证。
开始使用 Elasticsearch 进行向量嵌入
Elasticsearch 平台本身将强大的机器学习和人工智能集成到解决方案中,帮助你构建有利于用户并更快完成工作的应用程序。 Elasticsearch 是 Elastic Stack 的核心组件,Elastic Stack 是一组用于数据摄取、丰富、存储、分析和可视化的免费开放工具。
Elasticsearch 可以帮助你:
- 改善用户体验并提高转化率
- 实现新的见解、自动化、分析和报告
- 提高员工在内部文档和应用程序中的工作效率
了解有关 Elasticsearch 向量数据库的更多信息
向量嵌入资源
- 什么是向量搜索? 使用 ML 进行更好的搜索
- 什么是自然语言处理(NLP)?
- 什么是词嵌入?
- 如何部署 NLP:文本嵌入和向量搜索
- 向量搜索的优势 — 以及 IT 领导者需要它来改善搜索体验的 5 个原因