SFD
Sparse Fuse Dense: Towards High Quality 3D Detection with Depth Completion
论文网址:SFD
论文代码:SFD
论文简读
本文主要关注如何利用深度完成技术提高三维目标检测的质量。论文提出了一种名为 SFD(Sparse Fuse Dense)的新型多模态框架,以提高基于激光雷达(LiDAR)的三维目标检测性能。SFD 框架主要包括三个部分:激光雷达数据流、伪数据流和稀疏密集融合头。
- 激光雷达数据流:该部分仅使用原始激光雷达点云数据进行三维区域提议(RoI)生成,为后续的伪点云数据流提供 RoI。
- 伪数据流:这部分利用原始激光雷达点云和对应的图像生成伪点云。通过对伪点云进行上色,得到彩色伪点云。然后,使用提出的 CPConv(Color Point Convolution)对伪点云进行特征提取。最后,对 RoI 中的伪点云进行体素化,并应用稀疏卷积进行特征提取。
- 稀疏密集融合头:这部分提出了一种新的 RoI 特征融合策略 3D-GAF(3D Grid-wise Attentive Fusion),以更细粒度的方式融合原始点云和伪点云的 RoI 特征。此外,还提出了 SynAugment(同步增强)方法,使多模态框架能够充分利用针对激光雷达数据的特定数据增强方法。
论文的主要贡献包括:
- 提出了一种新的 RoI 特征融合策略 3D-GAF,以更细粒度的方式融合原始点云和伪点云的 RoI 特征。
- 提出了 SynAugment 方法,解决了多模态方法中数据增强不足的问题。
- 定制了一种有效且高效的特征提取器 CPConv,用于伪点云。它可以同时提取伪点云的 2D 图像特征和 3D 几何特征。
- 在 KITTI 汽车三维目标检测排行榜上取得了最高成绩,证明了 SFD 方法的有效性。
这篇论文提出了一种新颖的多模态三维目标检测框架 SFD,通过深度完成技术生成伪点云,结合稀疏激光雷达点云数据,实现了高质量的三维目标检测。实验结果表明,SFD 在 KITTI 数据集上的性能优于其他先进方法。
摘要
当前仅使用 LiDAR 的 3D 检测方法不可避免地会受到点云稀疏性的影响。人们提出了许多多模态方法来缓解这个问题,而图像和点云的不同表示使得它们难以融合,从而导致性能不佳。本文提出了一种新颖的多模态框架SFD(稀疏融合密集),它利用深度补全生成的伪点云来解决上述问题。与之前的工作不同,本文提出了一种新的 RoI 融合策略 3D-GAF(3D Grid-wise Attentive Fusion),以更充分地利用来自不同类型点云的信息。具体来说,3D-GAF以网格方式融合来自点云对的3D RoI特征,粒度更细、更精确。此外,本文提出了 SynAugment(同步增强),使本文的多模式框架能够利用专为仅 LiDAR 方法量身定制的所有数据增强方法。最后,本文为伪点云定制了一个有效且高效的特征提取器CPConv(Color Point Convolution)。它可以同时探索伪点云的2D图像特征和3D几何特征。本文的方法在 KITTI 汽车 3D 目标检测排行榜上名列前茅,证明了 SFD 的有效性。
引言
近年来,深度学习和自动驾驶的兴起带动了3D检测的快速发展。目前的3D检测方法主要基于LiDAR点云,而点云的稀疏性极大地限制了其性能。稀疏的 LiDAR 点云在远处和遮挡区域提供的信息很差,因此很难生成精确的 3D 边界框。许多多模态方法被提出来解决这个问题。 MV3D 引入了RoI融合策略来融合第二阶段图像和点云的特征。 AVOD 建议融合图像特征图和 BEV 特征图的全分辨率特征裁剪,以实现高召回率。 MMF 利用 2D 检测、地面估计和深度补全来辅助 3D 检测。在MMF中,伪点云用于主干特征融合,深度补全特征图用于RoI特征融合。尽管他们取得了巨大的成功,但他们有两个缺点。
Coarse RoI Fusion Strategy. 在融合RoI特征时,如图2(a)所示,以前的RoI融合方法将从BEV LiDAR特征图裁剪的2D LiDAR RoI特征和从FOV图像特征图裁剪的2D图像RoI特征连接起来。本文注意到这种 RoI 融合策略是粗糙的。首先,2D 图像 RoI 特征通常与其他物体或背景的特征混合,这会混淆模型。其次,RoI 融合策略忽略了 2D 图像和 3D 点云中的对象部分对应关系。本文提出了一种更细粒度的RoI融合策略3D-GAF(3D Grid-wise Attentive Fusion),它融合3D RoI特征而不是2D RoI特征,如图2(b)所示。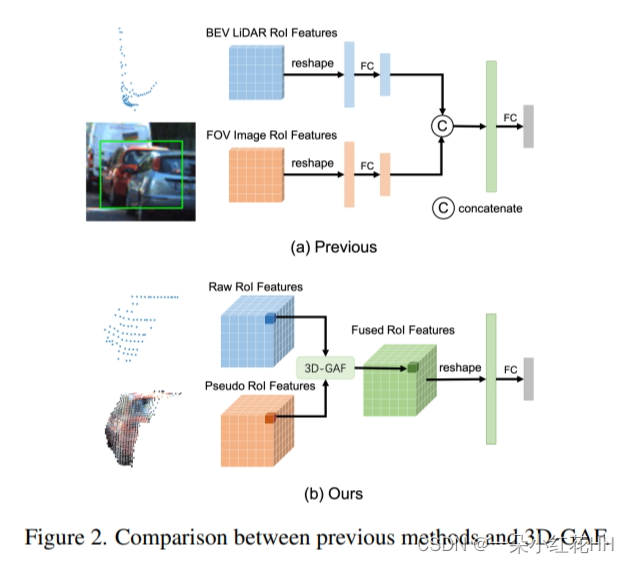
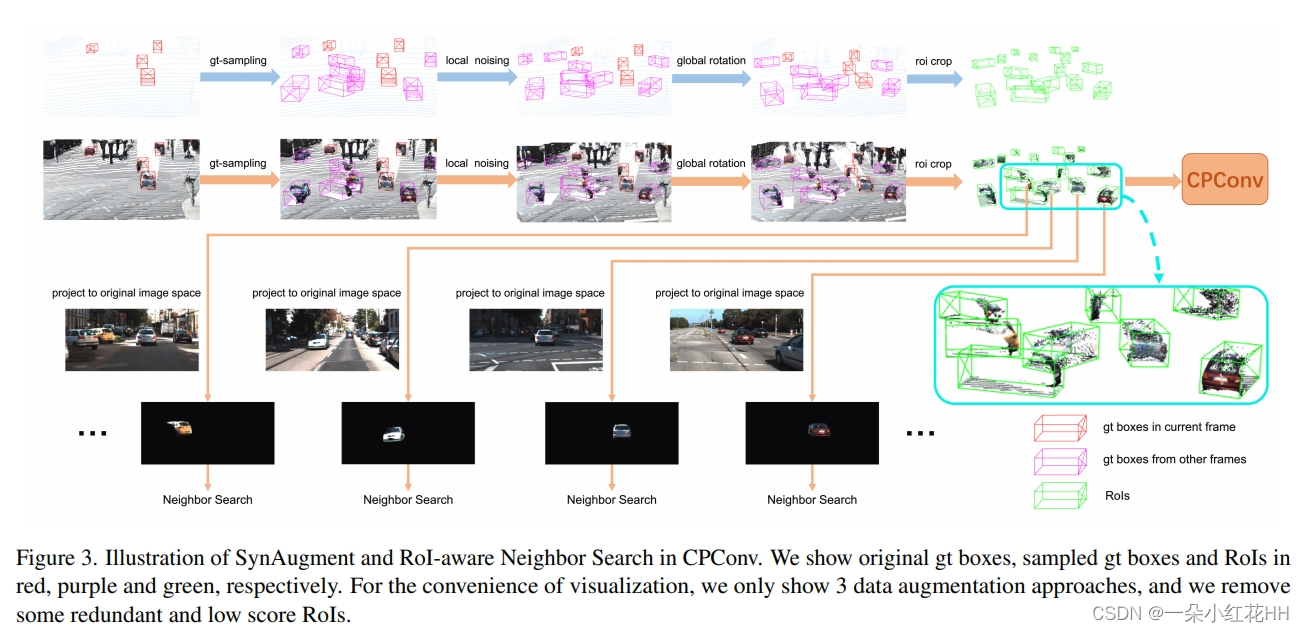
Insufficient Data Augmentation. 大多数多模态方法都存在这个缺点。由于 2D 图像数据无法像 3D LiDAR 数据一样进行操作,因此许多数据增强方法很难在多模态方法中部署。这是多模态方法通常不如单模态方法的一个关键原因。为此,本文引入了SynAugment(同步增强)。本文观察到,将 2D 图像转换为 3D 伪点云后,图像和原始点云的表示是统一的,这表明本文可以像操作原始点云一样操作图像。然而,这还不够。一些复杂的数据增强方法,例如 gt 采样 和局部旋转 可能会导致 FOV(前视)遮挡。这是一个不可忽视的问题,因为需要在 FOV 上提取图像特征。现在,是时候跳出思维定势了。将2D图像转换为3D伪点云后,为什么不直接提取3D空间中的图像特征呢?这样,就不再需要考虑FOV遮挡问题了。
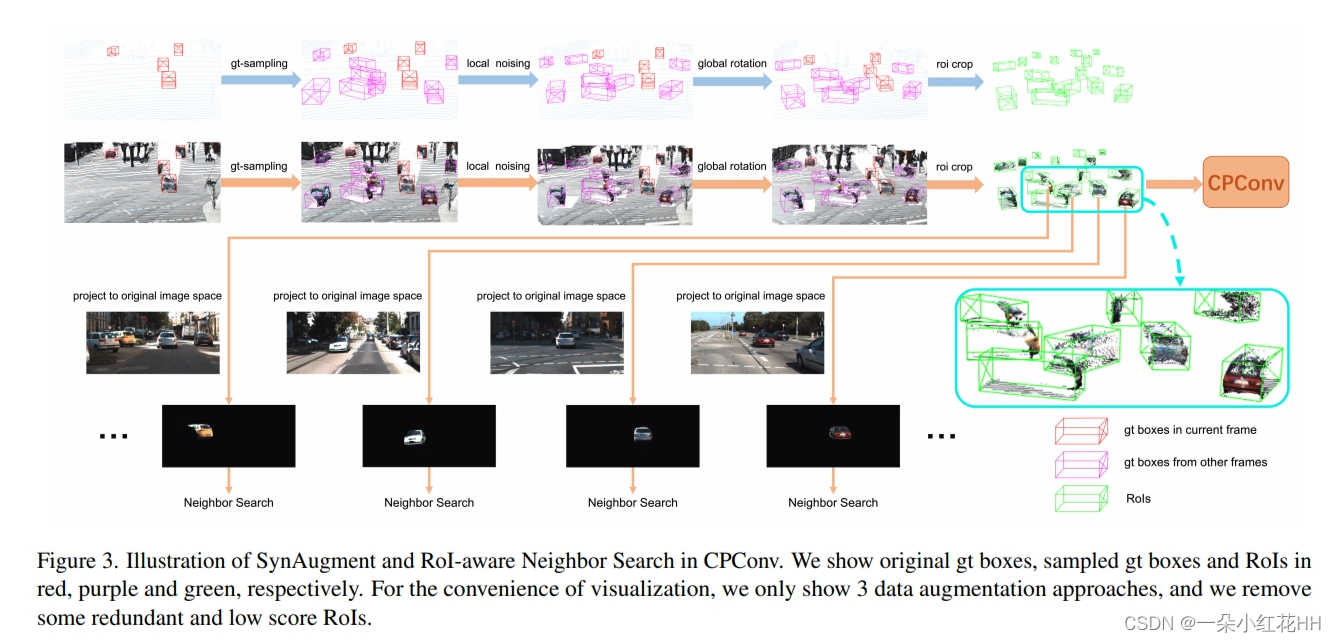
然而,在 3D 空间中提取伪点云特征并非易事。因此,本文提出了 CPConv(Color Point Convolution),它在图像域上搜索伪点的邻居。它使我们能够有效地提取伪点云的图像特征和几何特征。考虑到FOV遮挡问题,不能将所有伪点投影到当前帧的图像空间进行邻居搜索。在这里,本文提出了一种 RoI 感知邻居搜索,它将每个 3D RoI 中的伪点投影到其原始图像空间,如图 3 所示。因此,在执行邻居搜索时,FOV 上相互遮挡的伪点不会成为邻居。换句话说,它们的功能不会互相干扰。
总而言之,本文的贡献如下:
- 本文提出了一种新的 RoI 特征融合策略 3D-GAF,以更细粒度的方式融合原始点云和伪点云的 RoI 特征。
- 本文提出了一种数据增强方法 SynAugment 来解决多模态方法所面临的数据增强不足的问题。
- 本文为伪点云定制了一个有效且高效的特征提取器CPConv。它既可以提取2D图像特征,也可以提取3D几何特征。
- 本文通过大量实验证明了方法的有效性。特别是,在 KITTI 汽车 3D 物体检测排行榜上排名第一。
相关工作
使用单模态数据进行 3D 检测. 目前的3D检测方法主要基于LiDAR数据。 SECOND 提出了一种稀疏卷积运算来加速 3D 卷积。 SA-SSD 利用辅助网络来引导特征。 PV-RCNN 利用基于体素的方法和基于点的方法的优点来获得更具辨别力的特征。 Voxel-RCNN 指出原始点的精确定位是不必要的。 SE-SSD通过自组装获得了优异的性能。 CenterPoint 为 3D 检测提供了一个简单但有效的无锚框架。 LiDAR RCNN给出了解决尺度模糊问题的有效解决方案。 SPG 生成语义点来恢复前景对象的缺失部分。 VoTr 提出了一种基于Transformer的架构来有效地捕获大量上下文信息。 Pyramid R-CNN 设计了一个金字塔 RoI 头来自适应地从稀疏兴趣点学习特征。 CT3D 设计了一个channel Transformer来捕获点之间丰富的上下文依赖关系。然而,激光雷达数据通常稀疏,对这些方法提出了挑战。
使用多模态数据进行 3D 检测. 由于点云的稀疏性,研究人员寻求利用图像和点云的多模态方法的帮助。一些方法使用级联方法来利用多模态数据。然而,它们的性能受到 2D 探测器的限制。 MV3D 通过使用图像进行 RoI 细化的 RoI 特征融合策略实现了两阶段多模态框架。 ContFuse 提出了一个连续融合层来融合 BEV 特征图和图像特征图。 MMF 受益于多任务学习和多传感器融合。 VMVS 为伪点云中每个检测到的行人生成一组虚拟视图。然后使用不同的视图来产生准确的方向估计。 3D-CVF 融合了多视图图像的特征。 CLOC PVCas 以可学习的方式完善了 3D 候选者与 2D 候选者的置信度。一些工作通过建立图像和点云之间的对应关系,然后通过点云索引图像特征来实现细粒度的融合。然而,由于图像和点云之间的稀疏对应关系,它们索引的图像信息是有限的。值得注意的是,虽然MMF也采用了深度补全,但它并没有解决第1节中提到的两个问题。本文充分利用伪点云并给出了有效的解决方案。
深度补全. 深度补全旨在在彩色图像的指导下从稀疏深度图预测密集深度图。最近,提出了许多有效的深度补全方法。 [Penet]利用两分支骨干网络实现精确高效的深度补全网络。 [Depth completion with twin surface extrapolation at occlusion boundaries]提出了一种多假设深度表示,可以清晰前景和背景之间的深度边界。虽然深度补全任务的主要目的是服务下游任务,但在 3D 检测中使用深度补全的方法很少。在基于图像的 3D 物体检测中,有一些工作使用深度估计来生成伪点云。然而,由于缺乏准确或足够的原始激光雷达点云,它们的性能受到很大限制。
Sparse Fuse Dense
准备工作
为了简单起见,本文将LiDAR生成的原始LiDAR点云和深度补全生成的伪点云分别命名为原始云和伪点云。给定一帧原始云 R,可以将其转换为具有已知投影 T(LiDAR→image)的稀疏深度图 S。让I表示对应于R的图像。将I和S输入深度补全网络,可以得到密集的深度图D。利用已知的投影T(image→LiDAR),可以得到一帧伪云P。
方法概述
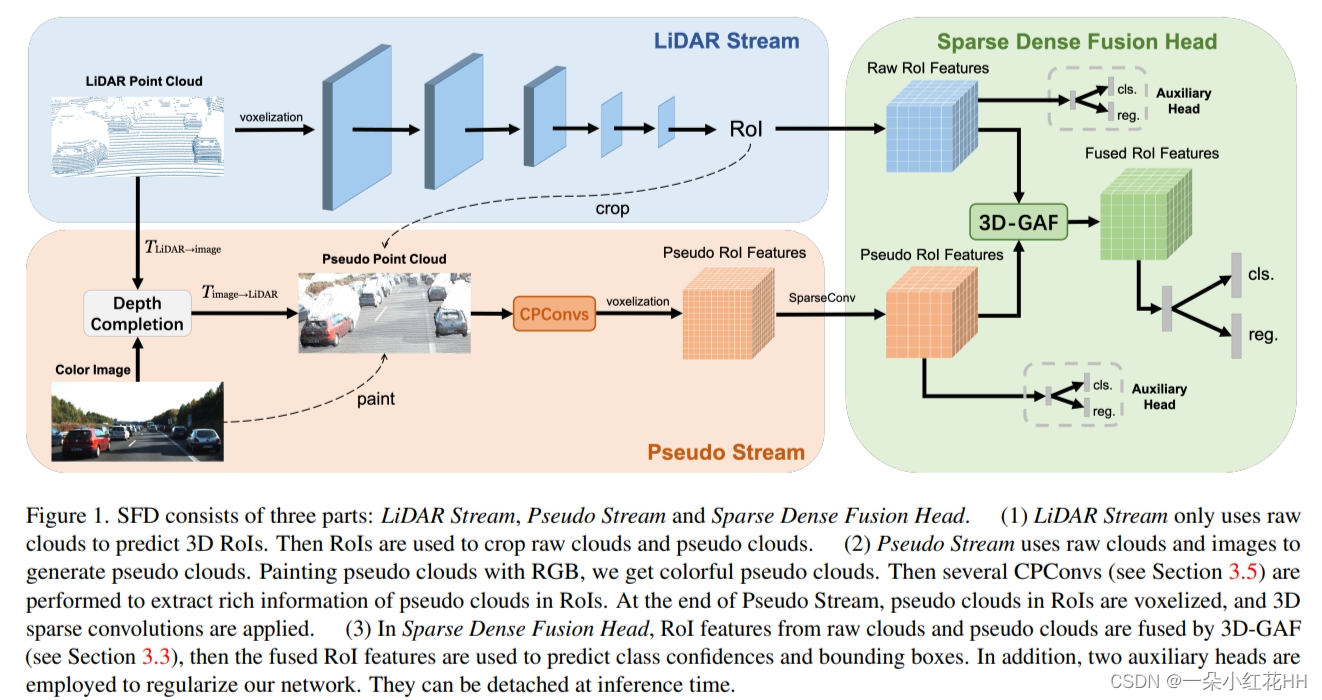
图 1 中展示了本文的框架,包括:(1) 仅使用原始点云并充当 RPN 来生成 3D RoIs 的 LiDAR 流; (2) 一个伪流,用提出的 CPConv 提取点特征,并用稀疏卷积提取体素特征; (3) 稀疏密集融合头,以网格方式关注的方式融合原始云和伪云的 3D RoI 特征,并产生最终预测。
3D Grid-wise Attentive Fusion
由于图像和点云之间的维度差距,之前的工作直接连接从BEV LiDAR特征图裁剪的2D LiDAR RoI特征和从FOV图像特征图裁剪的2D图像RoI特征,这是一种粗略的RoI融合战略。在本文的方法中,通过将 2D 图像转换为 3D 伪云,可以以更细粒度的方式融合图像和点云的 RoI 特征,如图 2 所示。 3D-GAF 由 3D Fusion、Grid-wise Fusion 和细心融合。
-
3D融合
本文使用3D RoI来裁剪3D原始云和3D伪云,其中仅包括3D RoI中的LiDAR特征和图像特征,如图2(b)所示。以前的方法使用 2D RoI 来裁剪图像特征,这将涉及其他对象或背景的特征。它会造成很多干扰,尤其是对于被遮挡的物体,如图 2(a) 所示。 -
网格融合
在以前的RoI融合方法中,图像RoI网格和LiDAR RoI网格之间没有对应关系,因此它们直接连接图像RoI特征和LiDAR RoI特征。在本文的方法中,由于原始 RoI 特征和伪 RoI 特征具有相同的表示,可以分别融合每对网格特征。这样能够使用相应的伪网格特征准确地增强对象的每个部分。 -
Attentive fusion
为了自适应地融合原始 RoI 和伪 RoI 中的每对网格特征,本文利用了一个简单的注意力模块。一般来说,为每对网格预测一对权重,并用权重对这对网格特征进行加权以获得融合的网格特征。
class Attention(nn.Module):
def __init__(self, channels):
super(Attention, self).__init__()
self.pseudo_in, self.valid_in = channels
middle = self.valid_in // 4
self.fc1 = nn.Linear(self.pseudo_in, middle)
self.fc2 = nn.Linear(self.valid_in, middle)
self.fc3 = nn.Linear(2*middle, 2)
self.conv1 = nn.Sequential(nn.Conv1d(self.pseudo_in, self.valid_in, 1),
nn.BatchNorm1d(self.valid_in),
nn.ReLU())
self.conv2 = nn.Sequential(nn.Conv1d(self.valid_in, self.valid_in, 1),
nn.BatchNorm1d(self.valid_in),
nn.ReLU())
def forward(self, pseudo_feas, valid_feas):
batch = pseudo_feas.size(0)
pseudo_feas_f = pseudo_feas.transpose(1,2).contiguous().view(-1, self.pseudo_in)
valid_feas_f = valid_feas.transpose(1,2).contiguous().view(-1, self.valid_in)
pseudo_feas_f_ = self.fc1(pseudo_feas_f)
valid_feas_f_ = self.fc2(valid_feas_f)
pseudo_valid_feas_f = torch.cat([pseudo_feas_f_, valid_feas_f_],dim=-1)
weight = torch.sigmoid(self.fc3(pseudo_valid_feas_f))
pseudo_weight = weight[:,0].squeeze()
pseudo_weight = pseudo_weight.view(batch, 1, -1)
valid_weight = weight[:,1].squeeze()
valid_weight = valid_weight.view(batch, 1, -1)
pseudo_features_att = self.conv1(pseudo_feas) * pseudo_weight
valid_features_att = self.conv2(valid_feas) * valid_weight
return pseudo_features_att, valid_features_att
本文提供 3D-GAF 的详细描述。让 b 表示单个 3D RoI。将 Fraw ∈ Rn×C 和 Fpse ∈ Rn×C 分别表示为 b 中的原始云 RoI 特征和伪云 RoI 特征。这里 n(默认为 6 × 6 × 6,遵循基线 Voxel-RCNN )是 3D RoI 中的网格总数,C 是网格特征通道。 Fraw 和 Fpse 的第 i 个 RoI 网格特征分别表示为 Fraw i 和 Fpse i 。给定一对 RoI 网格特征(Fraw i 、 Fpse i ),将 Fraw i 和 Fpse i 连接起来。然后将结果输入到全连接层和 sigmoid 层,为一对网格特征生成一对权重 (wraw i , wpse i ),其中 wraw i 和 wpse i 都是标量。最后,用(wraw i,wpse i)对(Fraw i,Fpse i)进行加权以获得融合网格特征Fi。形式上,Fi 的获得如下:
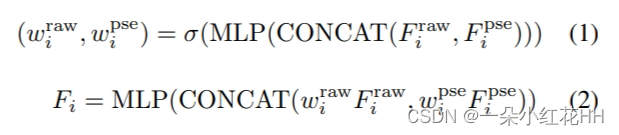
实际上,批量中的所有 RoI 网格特征对都可以并行处理,因此本文的 3D-GAF 非常高效。
同步增强
由于图像和点云的表示不同,多模态方法很难利用许多数据增强方法,例如gt采样和局部噪声。数据增强不足极大地限制了许多多模态方法的性能。因此,本文提出了一种多模态数据增强方法 SynAugment,使 SFD 能够使用专为仅 LiDAR 方法量身定制的所有数据增强方法。具体来说,SynAugment 包含两部分:像点云一样操作图像和提取 3D 空间中的图像特征。
Manipulate Images like Point Clouds(像点云一样操作图像): 多模态数据增强的最大挑战是如何像点云一样操作图像。深度补全给出了答案。通过深度补全,2D 图像可以转换为 3D 伪云。用RGB绘制伪云,伪云承载了图像的所有信息。然后只需要像原始云一样对伪云进行数据增强,如图3顶部所示。
Extract Image Features in 3D Space(提取 3D 空间中的图像特征): 对于多模态数据增强来说,像点云一样操作图像是不够的。目前,大多数多模态方法需要在FOV图像上提取图像特征。然而,这将限制模型使用可能导致 FOV 遮挡问题的数据增强方法(例如 gt 采样和局部旋转)。为了解决这个问题,本文建议将 2D 图像转换为 3D 伪云来提取 3D 空间中的图像特征。这样,就不需要考虑遮挡问题,因为不再在FOV图像上提取图像特征。为了提取 3D 空间中的特征,可以使用 3D 稀疏卷积。然而,还有一种更有效的方法。
值得注意的是,[Pointaugmenting]可以通过对图像进行额外的遮挡检测来实现多模态gt-sampling,但它们不适合更复杂的数据增强,这些数据增强不能简单地通过遮挡检测来解决,例如局部噪声和SA-DA 。一些将图像分割分数投影到原始点云的研究也可以使用多模态数据增强,但由于图像和点云之间的稀疏对应关系,原始点云携带的图像信息是稀疏的。在本文的方法中,每个gt采样器的图像信息是密集的,因为可以在伪云中裁剪采样器的完整图像信息。
Color Point Convolution
定义:对于一帧伪云 P,将图像中每个像素的 RGB (r, g, b) 和坐标 (u, v) 连接到其对应的伪点。因此,第i个伪点pi可以表示为(xi,yi,zi,ri,gi,bi,ui,vi)。
提取伪云特征的一种简单方法是直接对伪云进行体素化并执行3D稀疏卷积,但实际上并没有充分挖掘伪云中丰富的语义和结构信息。 PointNet++是提取点特征的一个很好的例子,但它不适合伪云。首先,PointNet++中的球查询操作由于伪点数量庞大,会带来海量的计算量。其次,PointNet++无法提取2D特征,因为球查询操作没有考虑2D邻域关系。鉴于此,需要一个能够有效提取 2D 语义特征和 3D 结构特征的特征提取器。
RoI-aware Neighbor Search on the Image Domain(图像域上的 RoI 感知邻居搜索): 基于上述分析,本文受到体素查询和网格搜索的启发,提出了一种CPConv(Color Point Convolution),它在图像域上搜索邻居。这样就可以克服PointNet++的缺点。首先,伪点可以在恒定时间内搜索其邻居,这使得它比球查询快得多。其次,图像域上的邻域关系使得提取二维语义特征成为可能。
不幸的是,本文无法将所有伪点投影到当前帧图像空间进行邻居搜索,因为使用 gt 采样,来自其他帧的伪点可能会导致 FOV 遮挡。为此,提出了 RoI 感知的邻居搜索。具体来说,根据伪点所携带的(u,v)属性将每个3D RoI中的伪点分别投影到其原始图像空间,如图3底部所示。这样,相互遮挡的伪点将不会成为邻居,因此即使在 FOV 上它们之间存在严重遮挡,它们的特征也不会相互干扰。
Pseudo Point Features(伪点特征): 对于第 i 个伪点 pi,将 pi 的特征表示为 fi = (xi, yi, zi, ri, gi, bi),它由 3D 几何特征 (xi, yi, zi) 和 2D 语义特征 (ri, gi、bi)。本文在执行邻居搜索之前在伪点特征上应用全连接层以降低复杂性。经过全连接层后,特征通道提升至C3,如图4所示。
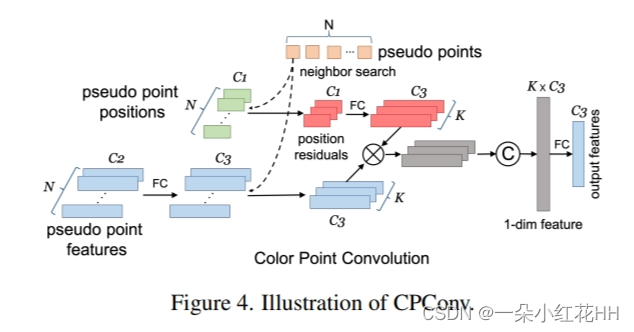
Position Residuals(位置残差): 本文利用 pi 到其邻居的 3D 和 2D 位置残差,使 pi 的特征了解 3D 和 2D 空间中的局部关系,这对于提取 pi 的 3D 结构特征和 2D 语义特征尤其重要。对于 pi 的第 k 个邻居 pi k,pi 和 pi k 之间的位置残差表示为 hi k = (xi− xi k, yi−yi k, zi−zi k, ui−ui k, vi−vi k, ||pi −pi k||)。
Feature Aggregation(特征聚合): 对于 pi 的 K 个邻居,本文收集它们的位置并计算位置残差。然后在位置残差上应用一个全连接层,将它们的通道提升到 C3 以与伪点特征对齐。给定一组邻居特征 Fi = {fk i ∈ RC3 , k ∈ 1, · · · ,K} 和一组邻居位置残差 Hi = {hk i ∈ RC3 , k ∈ 1, · · · ,K},用相应的 hi k 对每个 fi k 进行加权。加权邻居特征被串联起来[5],而不是最大池化[4],以获得最大的信息保真度。最后,应用全连接层将聚合特征通道映射回 C3。
Multi-Level Feature Fusion(多层次特征融合): 本文堆叠三个 CPConv 来提取伪云的更深层次特征。考虑到高级特征提供更大的感受野和更丰富的语义信息,而低级特征可以提供更精细的结构信息,将每个 CPConv 的输出连接起来,以获得更全面和更有辨别力的伪云表示。
class CPConvs(nn.Module):
def __init__(self):
super(CPConvs, self).__init__()
self.pointnet1_fea = PointNet( 6,12)
self.pointnet1_wgt = PointNet( 6,12)
self.pointnet1_fus = PointNet(108,12)
self.pointnet2_fea = PointNet( 12,24)
self.pointnet2_wgt = PointNet( 6,24)
self.pointnet2_fus = PointNet(216,24)
self.pointnet3_fea = PointNet( 24,48)
self.pointnet3_wgt = PointNet( 6,48)
self.pointnet3_fus = PointNet(432,48)
def forward(self, points_features, points_neighbor):
if points_features.shape[0] == 0:
return points_features
N, F = points_features.shape
N, M = points_neighbor.shape
point_empty = (points_neighbor == 0).nonzero()
points_neighbor[point_empty[:,0], point_empty[:,1]] = point_empty[:,0]
pointnet_in_xiyiziuiviri = torch.index_select(points_features[:,[0,1,2,6,7,8]],0,points_neighbor.view(-1)).view(N,M,-1)
pointnet_in_x0y0z0u0v0r0 = points_features[:,[0,1,2,6,7,8]].unsqueeze(dim=1).repeat([1,M,1])
pointnet_in_xyzuvr = pointnet_in_xiyiziuiviri - pointnet_in_x0y0z0u0v0r0
points_features[:, 3:6] /= 255.0
pointnet1_in_fea = points_features[:,:6].view(N,1,-1)
pointnet1_out_fea = self.pointnet1_fea(pointnet1_in_fea).view(N,-1)
pointnet1_out_fea = torch.index_select(pointnet1_out_fea,0,points_neighbor.view(-1)).view(N,M,-1)
pointnet1_out_wgt = self.pointnet1_wgt(pointnet_in_xyzuvr)
pointnet1_feas = pointnet1_out_fea * pointnet1_out_wgt
pointnet1_feas = self.pointnet1_fus(pointnet1_feas.reshape(N,1,-1)).view(N,-1)
pointnet2_in_fea = pointnet1_feas.view(N,1,-1)
pointnet2_out_fea = self.pointnet2_fea(pointnet2_in_fea).view(N,-1)
pointnet2_out_fea = torch.index_select(pointnet2_out_fea,0,points_neighbor.view(-1)).view(N,M,-1)
pointnet2_out_wgt = self.pointnet2_wgt(pointnet_in_xyzuvr)
pointnet2_feas = pointnet2_out_fea * pointnet2_out_wgt
pointnet2_feas = self.pointnet2_fus(pointnet2_feas.reshape(N,1,-1)).view(N,-1)
pointnet3_in_fea = pointnet2_feas.view(N,1,-1)
pointnet3_out_fea = self.pointnet3_fea(pointnet3_in_fea).view(N,-1)
pointnet3_out_fea = torch.index_select(pointnet3_out_fea,0,points_neighbor.view(-1)).view(N,M,-1)
pointnet3_out_wgt = self.pointnet3_wgt(pointnet_in_xyzuvr)
pointnet3_feas = pointnet3_out_fea * pointnet3_out_wgt
pointnet3_feas = self.pointnet3_fus(pointnet3_feas.reshape(N,1,-1)).view(N,-1)
pointnet_feas = torch.cat([pointnet3_feas, pointnet2_feas, pointnet1_feas, points_features[:,:6]], dim=-1)
return pointnet_feas
Loss Function
本文遵循 VoxelRCNN 的 RPN 损失和 RoI 头损失,分别表示为 Lrpn 和 Lroi。为了防止梯度被特定流主导,在 LiDAR Stream 和 Pseudo Stream 上添加辅助 RoI 水头损失,分别表示为 Laux1 和 Laux2 。 Laux1和Laux2与Lroi一致,包括类别置信度损失和回归损失。深度补全网络损失L深度遵循[12]的定义。那么总损失为:
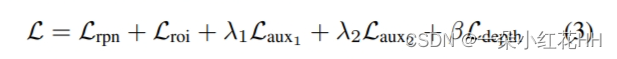
其中λ1、λ2和β是Laux1、Laux2和L深度的权重(默认情况下λ1 = 0.5,λ2 = 0.5,β = 1)。
结论
本文提出了一种用于高质量 3D 检测的新型多模态框架 SFD。设计了一种新的RoI融合策略3D-GAF,以更细粒度的方式融合原始云和伪云。通过提出的 SynAugment,SFD 可以使用针对仅 LiDAR 方法量身定制的数据增强方法。此外,设计了一个 CPConv 来有效且高效地提取伪云的特征。实验结果表明本文的方法可以显着提高检测精度。