一、简介
1、什么是数据库
数据仓库,用来存储数据。访问必须用SQL语句来访问
2、数据库的类型
1、关系型数据库:Oracle、DB2、Microsoft SQL Server、Microsoft Access、MySQL等 可以用SQL语句方便的在一个表以及多个表之间做非常复杂的数据查询;事务支持良好,使得对于安全性能很高的数据访问要求得以实现
2、非关系型数据库:redis,MongoDb等 性能高,不需要经过SQL层的解析
3、常见的数据库类型
Oracle 大型数据库,收费
Mysql 小型数据库,开源,
SQL Server 微软数据库
DB2 IBM公司产品,大型数据库,收费
二、数据库增删改查的操作
前置:安装mysql,教程点击此处
1、增
| 语法 | 含义 | 模板 |
| CREATE DATABASE | 创建新数据库 | CREATE DATABASE dbname; |
| CREATE TABLE | 创建新表 | CREATE TABLE table_name ( column_name1 data_type(size), column_name2 data_type(size), column_name3 data_type(size), .... ); |
| INSERT INTO | 向数据库中插入新数据 | 两种编写形式 1、第一种形式无需指定要插入数据的列名,只需提供被插入的值即可 INSERT INTO table_name VALUES (value1,value2,value3,... 2、第二种形式需要指定列名及被插入的值 INSERT INTO table_name (column1,column2,column3,...) VALUES (value1,value2,value3,...); |
2、删
| 语法 | 含义 | 模板 | 实例 | 备注 |
| DELETE | 从数据库中删除数据 | DELETE FROM table_name WHERE some_column=some_value; | DELETE FROM Websites WHERE name='Facebook' AND country='USA'; | WHERE 子句规定哪条记录或者哪些记录需要删除。如果省略了 WHERE 子句,所有的记录都将被删除 |
| drop | 从数据库中删除数据 | drop table 表名; | 把表和表中数据直接删除 | |
| truncate | 从数据库中删除数据 | truncate table 表名; | truncate 直接把表删除 会按照之前的表在创建一个新的 |
删除速度 drop>truncate>delete
3、改
| 语法 | 含义 | 模板 | 备注 |
| UPDATE | 更新数据库中的数据 | UPDATE table_name SET column1=value1,column2=value2,... WHERE some_column=some_value; | 执行没有 WHERE 子句的 UPDATE 要慎重,再慎重。 在 MySQL 中可以通过设置 sql_safe_updates 这个自带的参数来解决,当该参数开启的情况下,你必须在update 语句后携带 where 条件,否则就会报错。 set sql_safe_updates=1; 表示开启该参数 |
4、查
1、select语句
| 语法 | 含义 | 模板 | 备注 |
| DISTINCT | 用于返回唯一不同的值 | SELECT DISTINCT column_name,column_name FROM table_name; | |
| WHERE (②、③) | 用于提取那些满足指定条件的记录 | SELECT column_name,column_name FROM table_name WHERE column_name operator value; | 1、文字用单引号,数字不用引号; 2、后面不能跟聚合函数 |
| AND & OR | 如果第一个条件和第二个条件都成立,则 AND 运算符显示一条记录。 如果第一个条件和第二个条件中只要有一个成立,则 OR 运算符显示一条记录 | 1、SELECT * FROM Websites WHERE country='CN' AND alexa > 50; 2、SELECT * FROM Websites WHERE country='USA' OR country='CN'; | |
| ORDER BY (④、⑤) | 关键字用于对结果集按照一个列或者多个列进行排序 | SELECT column_name,column_name FROM table_name ORDER BY column_name,column_name ASC|DESC; | 关键字默认按照升序对记录进行排序。如果需要按照降序对记录进行排序,可以使用 DESC 关键字 |
| like¬ like (⑥) | 用于在 WHERE 子句中搜索列中的指定模式 | SELECT column_name(s) FROM table_name WHERE column_name LIKE pattern; | |
| in | 在 WHERE 子句中规定多个值 | SELECT column_name(s) FROM table_name WHERE column_name IN (value1,value2,...); | 转换 1、select * from Websites where name in ('Google','菜鸟教程'); 2、select * from Websites where name='Google' or name='菜鸟教程'; |
| between& not between | 选取介于两个值之间的数据范围内的值 | SELECT column_name(s) FROM table_name WHERE column_name BETWEEN value1 AND value2; | 带有 IN 的 BETWEEN 操作符实例 SELECT * FROM Websites WHERE (alexa BETWEEN 1 AND 20) AND country NOT IN ('USA', 'IND'); |
5、多表连接
| 语法 | 含义 | 模板 | 备注 |
| INNER JOIN&JOIN | 关键字在表中存在至少一个匹配时返回行 | 1、SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name=table2.column_name; 2、SELECT column_name(s) FROM table1 JOIN table2 ON table1.column_name=table2.column_name; | |
| LEFT JOIN | 关键字从左表(table1)返回所有的行,即使右表(table2)中没有匹配。如果右表中没有匹配,则结果为 NULL 左为主 把左边的表中的不符合规则的数据显示出来 | SELECT column_name(s) FROM table1 LEFT JOIN table2 ON table1.column_name=table2.column_name; | 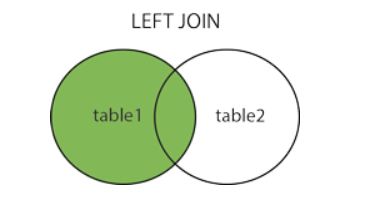 |
| RIGHT JOIN | 关键字从右表(table2)返回所有的行,即使左表(table1)中没有匹配。如果左表中没有匹配,则结果为 NULL 右连接 右为主 把右边的表中的不符合规则的数据显示出来 | SELECT column_name(s) FROM table1 RIGHT JOIN table2 ON table1.column_name=table2.column_name; | 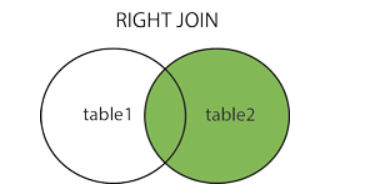 |
6、函数
| 语法 | 含义 | 模板 | 备注 |
| AVG() | 返回平均值 | SELECT AVG(column_name) FROM table_name | 聚合函数 |
| COUNT() | COUNT(column_name) 函数返回指定列的值的数目(NULL 不计入) COUNT(*) 返回表中的记录数 COUNT(DISTINCT column_name) 返回指定列的不同值的数目 | 同左 | 聚合函数 |
| MAX() | 返回最大值 | SELECT MAX(column_name) FROM table_name; | 聚合函数 |
| MIN() | 返回最小值 | SELECT MIN(column_name) FROM table_name; | 聚合函数 |
| SUM() | 返回总和 | SELECT SUM(column_name) FROM table_name; | 聚合函数 |
| GROUP BY | 用于结合聚合函数,根据一个或多个列对结果集进行分组。 | SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name; | |
| HAVING (⑦) | 筛选分组后的各组数据,解决WHERE 关键字无法与聚合函数一起使用 | SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name HAVING aggregate_function(column_name) operator value; |
②、WHERE 子句中的运算符
| 运算符 | 描述 | 示例 |
| = | 等于 | |
| <> | 不等于。注释:在 SQL 的一些版本中,该操作符可被写成 != | |
| > | 大于 | |
| < | 小于 | |
| >= | 大于等于 | |
| <= | 小于等于 |
③、WHERE 子句并不一定带比较运算符,当不带运算符时,会执行一个隐式转换。当 0 时转化为 false,1 转化为 true。
例如:
SELECT studentNO FROM student WHERE 0
则会返回一个空集,因为每一行记录 WHERE 都返回 false。
SELECT studentNO FROM student WHERE 1
返回 student 表所有行中 studentNO 列的值。因为每一行记录 WHERE 都返回 true。
④、ORDER BY 多列的顺序
先按照第一个column name排序,在按照第二个column name排序
1)、先将country值这一列排序,同为CN的排前面,同属USA的排后面;
2)、然后在同属CN的这些多行数据中,再根据alexa值的大小排列。
3)、ORDER BY 排列时,不写明ASC DESC的时候,默认是ASC。
⑤、ORDER BY 多列的升降序
order by A,B 这个时候都是默认按升序排列
order by A desc,B 这个时候 A 降序,B 升序排列
order by A ,B desc 这个时候 A 升序,B 降序排列
即 desc 或者 asc 只对它紧跟着的第一个列名有效,其他不受影响,仍然是默认的升序。
⑥、
| %a | 以a结尾的数据 |
| a% | 以a开头的数据 |
| %a% | 含有a的数据 |
| _a_ | 三位且中间字母是a的 |
| _a | 两位且结尾字母是a的 |
| a_ | 两位且开头字母是a的 |
⑦、分组查询的筛选条件
| 数据源 | 位置 | 关键字 | |
| 分组前筛选 | 原始表 | group by子句的前面 | where |
| 分组后筛选 | 分组后的结果集 | group by子句的后面 | having |