文章目录
- MagicMind 依赖
- 示例
- C++ 编程模型
- sample_ops/sample_add 算子操作
- 混合精度
- 部署
- 多模型部署
- 单模型多实例部署
- 多卡部署
- 最佳实践
- 1、性能指标
- 吞吐率
- 延时
- 工具 mm_run
- 性能优化
- 2内存工具
- Profiler工具
- 3性能和精度差异说明
MagicMind 依赖

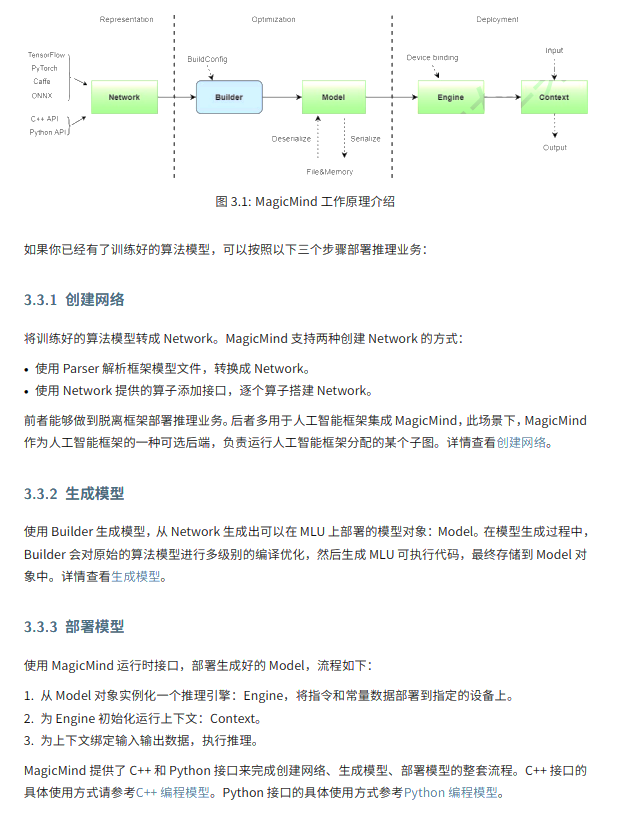
MM 是将训练好的模型转换成统一计算图表示,附带有优化、部署能力。
示例
/usr/local/neuware/samples/magicmind
C++ 编程模型
本示例基于MagicMind C++ API,展示如何构造一个算子,并进行运行部署前的编译工作,包括:
- 创建输入tensors。
- 构建网络。
- 创建模型。
- 序列化模型,生成
[op_name]_model。
sample_ops/sample_add 算子操作
int main(int argc, char **argv) {
// init
auto builder = SUniquePtr<magicmind::IBuilder>(magicmind::CreateIBuilder());
CHECK_VALID(builder);
auto network = SUniquePtr<magicmind::INetwork>(magicmind::CreateINetwork());
CHECK_VALID(network);
// create input tensor
DataType input1_dtype = DataType::FLOAT32;
Dims input1_dims = Dims({-1, -1, -1, -1});
magicmind::ITensor *input1_tensor = network->AddInput(input1_dtype, input1_dims);
CHECK_VALID(input1_tensor);
DataType input2_dtype = DataType::FLOAT32;
Dims input2_dims = Dims({-1, -1, -1, -1});
magicmind::ITensor *input2_tensor = network->AddInput(input2_dtype, input2_dims);
CHECK_VALID(input2_tensor);
// create add node
IElementwiseNode *Add = network->AddIElementwiseNode(input1_tensor,input2_tensor,IElementwise::ADD);
//using Add default paramters, you can set each attribute's value.
//CHECK_STATUS(Add->SetAlpha1([value]));
//CHECK_STATUS(Add->SetAlpha2([value]));
// mark network output
for (auto i = 0; i < Add->GetOutputCount(); i++) {
auto output_tensor = Add->GetOutput(i);
CHECK_STATUS(network->MarkOutput(output_tensor));
}
// create model
auto model = SUniquePtr<magicmind::IModel>(builder->BuildModel("add_model", network.get()));
CHECK_VALID(model);
// save model to file
CHECK_STATUS(model->SerializeToFile("add_model"));
return 0;
}
这段代码是使用C++编写的,它使用了magicmind库(一种深度学习库)来创建一个简单的神经网络模型。以下是代码的逐行解释:
int main(int argc, char **argv) {:这是主函数的开始,所有C++程序的执行都从这里开始。// init:初始化一些变量。auto builder = SUniquePtr<magicmind::IBuilder>(magicmind::CreateIBuilder());:创建一个IBuilder对象,用于构建模型。CHECK_VALID(builder);:检查builder是否有效。auto network = SUniquePtr<magicmind::INetwork>(magicmind::CreateINetwork());:创建一个INetwork对象,它代表了一个神经网络。CHECK_VALID(network);:检查network是否有效。// create input tensor:创建一个输入张量。DataType input1_dtype = DataType::FLOAT32;:定义输入1的数据类型为FLOAT32。Dims input1_dims = Dims({-1, -1, -1, -1});:定义输入1的维度。这里的-1表示该维度可以是任意大小。magicmind::ITensor *input1_tensor = network->AddInput(input1_dtype, input1_dims);:在神经网络中添加一个输入,并获取其对应的ITensor指针。CHECK_VALID(input1_tensor);:检查input1_tensor是否有效。- 以相同的方式为第二个输入创建ITensor。
// create add node:创建一个add节点,该节点将两个输入相加。IElementwiseNode *Add = network->AddIElementwiseNode(input1_tensor,input2_tensor,IElementwise::ADD);:在神经网络中添加一个元素级加法节点,将两个输入相加。//using Add default paramters, you can set each attribute's value.:这行代码注释掉了对Add节点的一些属性的设置。你可以根据需要设置这些属性值。// CHECK_STATUS(Add->SetAlpha1([value]));:这行代码注释掉了对Add节点Alpha1属性的设置。你可以用实际的值替换[value],或者完全移除这行代码。// CHECK_STATUS(Add->SetAlpha2([value]));:这行代码注释掉了对Add节点Alpha2属性的设置。你可以用实际的值替换[value],或者完全移除这行代码。// mark network output:标记网络输出。for (auto i = 0; i < Add->GetOutputCount(); i++) {:遍历所有Add节点的输出。auto output_tensor = Add->GetOutput(i);:获取当前输出。CHECK_STATUS(network->MarkOutput(output_tensor));:将此输出标记为网络的输出。}:结束for循环。// create model:创建模型。auto model = SUniquePtr<magicmind::IModel>(builder->BuildModel("add_model", network.get()));:使用builder和network对象创建一个新的模型,并将其命名为"add_model"。CHECK_VALID(model);:检查model是否有效。// save model to file:将模型保存到文件。CHECK_STATUS(model->SerializeToFile("add_model"));:将模型序列化并保存为"add_model"文件。return 0;:程序成功执行完毕,返回0。
混合精度
见:【寒武纪(6)】MLU推理加速引擎MagicMind,最佳实践(二)
部署
真实的业务场景中,多模型、多线程、多卡部署业务的需求。本次介绍在满足这些应用场景下的模型部署需求。
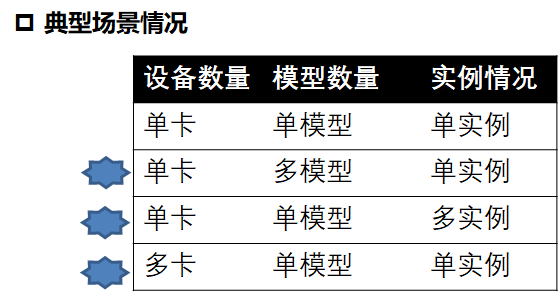
多模型部署
一种典型的业务场景为在同一个MLU设备上同时部署多个模型。在MM 上,用户通过创建多个模型对象来完成多模型部署。首先创建IEngine将指令和常量数据部署Device。可以创建多个Engine,部署到同一个设备或多个设备。基于IContext 执行环境,绑定Context输入和输出地址,最后使用Enqueue执行。
例如我们部署Resnet50和Efficientnet两个模型。
IMode *modelA = CreateModel();
modelA ->DeserializeFromFile(resnet_model_file);
IEngine *engineA = modelA ->CreateIEngine();
…
IMode *modelB = CreateModel();
modelB ->DeserializeFromFile(effi_model_file);
IEngine *engineA = modelB ->CreateIEngine();
…
对于多线程部署多模型, CreateIEngine后不允许使用fork创建信息的子进程。因为主进程运行时有部分全局资源,fork的子进程为无效拷贝,导致无法运行。需要使用spawn创建新进程。
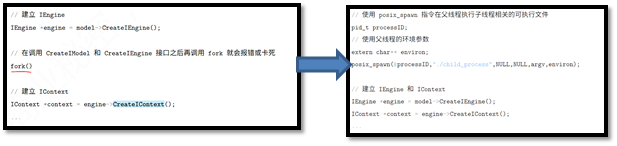
单模型多实例部署
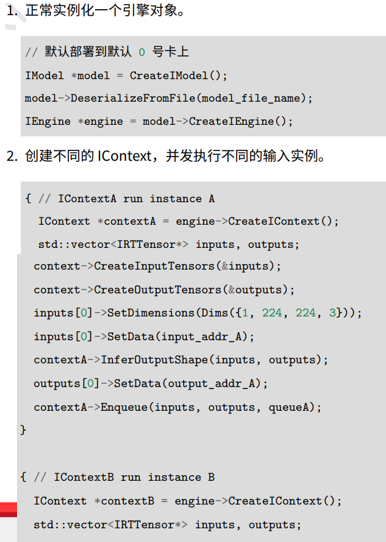
另一种典型的业务,同一个MLU设备上同时单个模型并发地处理不同地输入实例,不同实例共享该设备地指令和常量数据。通过一个Engine创建多个Context。并发执行不同实例。
1、实例A和实例B运行在不同Context上面。
2、实例A和实例B使用不同队列,可以在MLU并行执行(如果物理资源足够地情况下)
3、为了进一步加速上面地代码,主机端可以启多个线程并发执行两个不同地实例。
4、 Context是互斥资源。多线程使用Enqueue异步调用Context是不允许。
多卡部署
一种典型的业务场景为,单个模型部署到多个MLU设备,实现数据并行。
通过同一个模型,创建不同Engine,部署到多个设备上。
1、引擎A和引擎B运行在不同MLU上面。
2、共享主机端指令、模型数据,主机内存不会随着引擎数增加而明显增长。

最佳实践
1、性能指标

吞吐率
单位时间可以完成多少推理请求。为了实现高吞吐率,业务层需要实现三级流水,让不同请求之间的计算和内存拷贝并行起来。
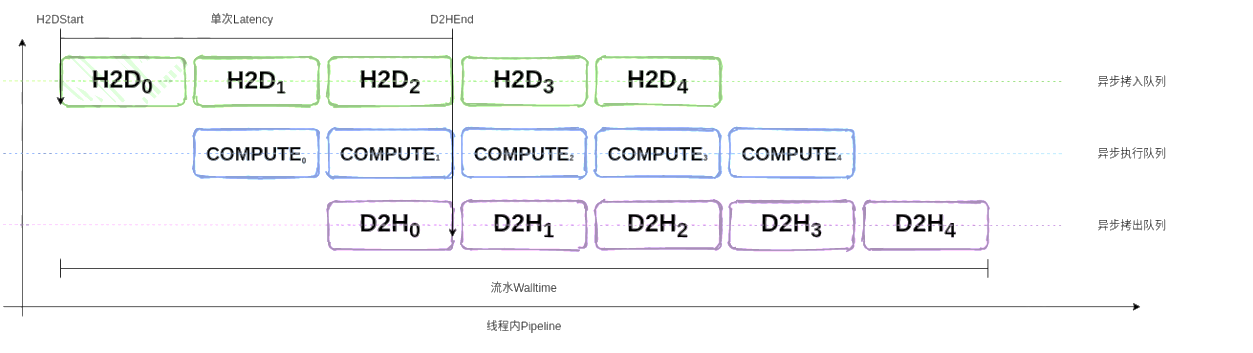

延时
每次推理请求的总响应时间,

工具 mm_run


1、c 编程使用clock_gettime() 函数。
2、CNRT 提供的Notifier 接口统计异步队列执行时间。具体看手册说明《Cambricon-MagicMind-Best-Practices-Guide-CN-v1.5.0.pdf》

性能优化
1、使用混合精度。追求性能,使用qint8_mixed)float16进行推理。具体设置为在build_config 配置精度percision_config。
2、BatchSize 调优
单个推理示例IContext 独占 MLU 时,增大 batch size 提升吞吐率。原因是:
- 小batch size 无法充分利用MLU 核,增大batchsize可以提升利用率
- 一些公共的开销,如从DDR 加载常量数据,能通过增大数据并行度(batch size)被更好的利用。
如果业务对延时要求不那么严格,可尝试等待一段时间,将T时间内的积攒一起提交给IContext 处理,提升吞吐率。
2、batch size 对齐
这个和硬件有关,将 batch size 设置为硬件cluster 的整数倍能提升吞吐率。设备支持的最大cluster 可以通过cndrv的cnDeviceGetAttribute 获得。
3、多实例并发
多个 IContext 并发提升吞吐率。用一个IEngine 创建多个推理实例,多个实例可以绑定不同的cnrtQuene,并发地执行在同一个设备。
有如下风险需要注意:
- 占用更多地cpu和mlu资源
- 不同实例之间会争抢cluster 资源,导致每个实例地推理延时存在波动,某些情况下回导致整体地吞吐率还不如使用单个实例增大batchsize。
对于多实例并大地资源冲突地手段是为每个推理实例划分独立的计算资源,当前寒武纪的驱动API 已经提供轻量级的计算资源隔离机制,visible cluster。可以绑定当前线程所使用的物理cluster,做到资源独占
4、模型输入的形状
设置固定形状时,网络输入维度是固定的,传入的Dims 是固定的,magicmind 会专门做统一计算图编译优化。在buildConfig 中的graph_shape_mutable 设置为false。
如果设置为可变,可以设置维度最大值和最小值,有助于优化。

5、使用偏好的物理布局
大部分硬件在架构设计上会有偏好布局,在软件层面合理安排数据的物理布局可以极大的提升系统性能,降低系统功耗 。例如选择NHWC 和NCHW布局。(对这个不懂的可以看我之前的文章《OpenCV读取图像时按照BGR的顺序HWC排列,PyTorch按照RGB的顺序CHW排列》),
推荐如下:
1、杜宇物理布局敏感的算子,尽可能选择channel last物理布局,NHWC
2、整个网络的输入和输出,尽可能选择channel last 布局,NHWC

输入输出,pytorch 导入的模型,默认布局是NCHW,在预处理允许输出布局为NHWC数据的情况下,我们可将推理部分的输入和输出的物理布局调整为NHWC,从而提升推理性能。



6、优化预处理
将部分预处理操作合并到推理模型,尝试使用算子融合,提升推理加速。目前支持的预处理为:减均值除方差(标准化)
(1)如果对输出结果范围有要求,用归一化。 (2)如果数据较为稳定,不存在极端的最大最小值,用归一化。
(3)如果数据存在异常值和较多噪音,用标准化,可以间接通过中心化避免异常值和极端值的影响。
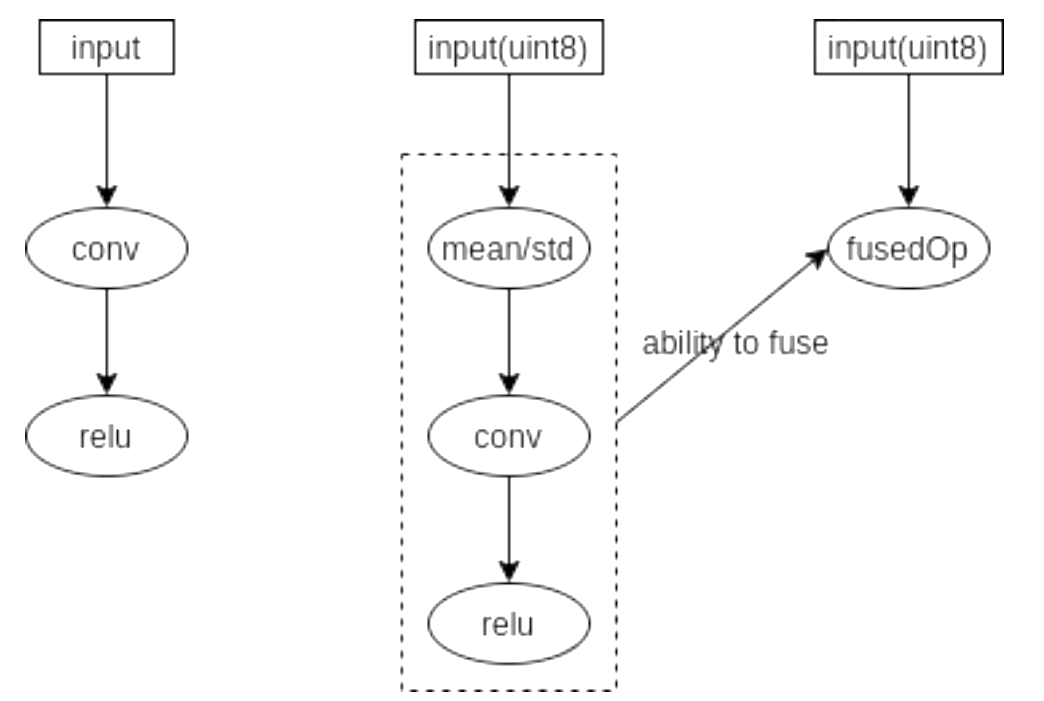
可在BuildConfig 中设置insert_bn_before_firstnode 配置来使用该功能,下面展示一下通过一个json文件实现:

7、提供运行时资源提升算子融合性能,BuildConfig 中配置archs 或produce_names 进一步提升网络运行时性能。


8、图优化
图优化策略可提升整体推理性能,但是部分图优化策略可能会改变计算顺序,影响数据分布。某些看似等价的数学变换,在使用低精度推理的情况下,存在精度溢出的可能性,影响网络最终精度。因此MagicMind会将某些会影响精度的图优化策略默认设置为关闭,并提供使能配置,允许用户权衡精度和性能。
9、特定网络优化
对Transformer 和BERT ,模型的输入序列长度不超过128,支持官方的Transformer-Base 和oytorch官方的Bert-base/large ,会特定的统合优化Pass 会被使能,模型的网络片段替换为高度优化的底层算子。

10、自定义算子
用户通过BANG C 语言实现高性能MLU算子,实现定制化的性能优化
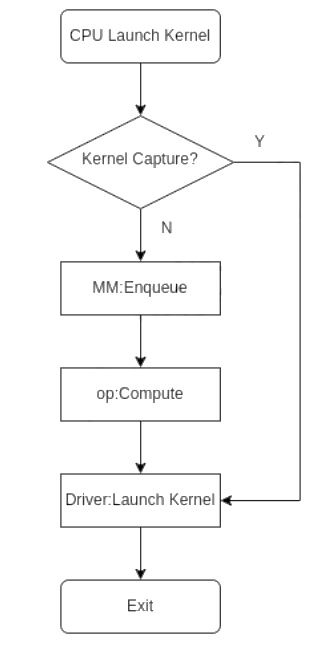
11、使能 Kernel capture
存在某些场景,主机下发任务的速度比MLU执行任务的速度慢,从而导致MLU空闲,整体性能不理想。使用kernel capture 功能,可以在首先场景下环节主机端下发任务慢的问题。原理如下:在模型的kernel 执行顺序和kernel参数固定的情况下,提前执行模型中可以被捕获的kernel 并缓存对应的执行参数,在后续推理迭代中一致复用捕获的kernel以及执行参数,洁身主机端下发任务的时间。




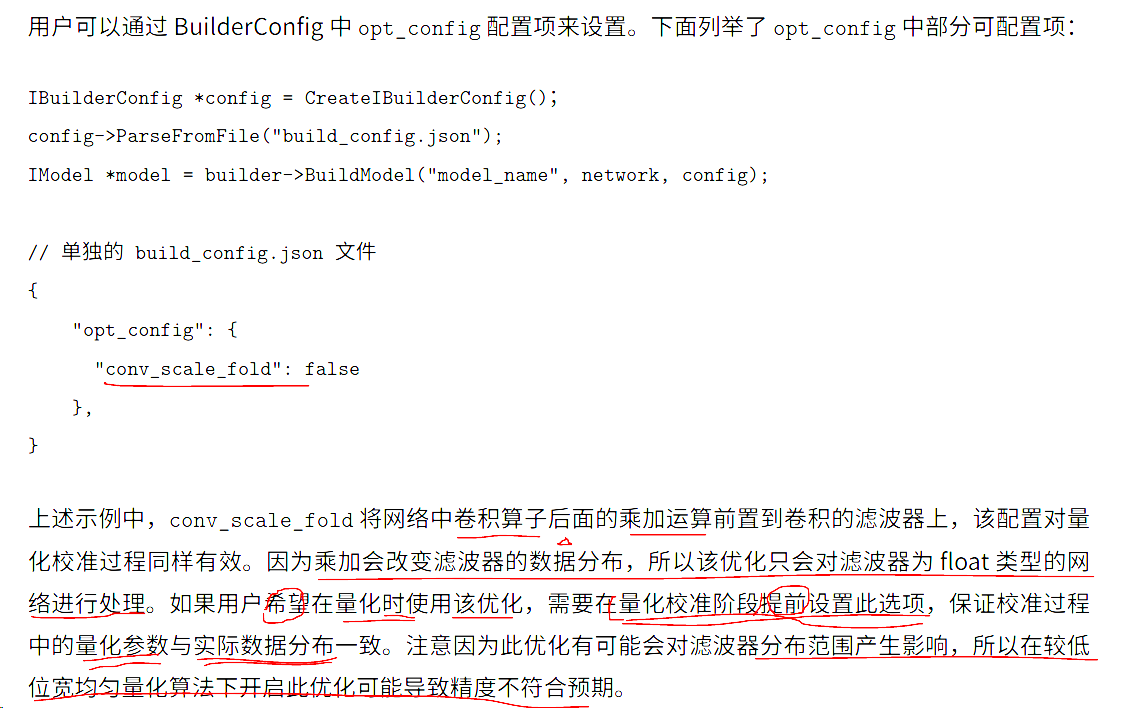
12、 使用 conv scale fusion
在某些场景,例如分通道量化网络中,会在每个卷积算子后面添加一个乘法加法孙子,此时由于卷积算子无法直接融合乘法加法算子,性能较融合差,才外还会阻塞器后算子向前融合,例如导致后续出现Relu/ReluN 算子也无法融合进卷积算子,性能较差,此时可以尝试 convs cale fusion。
该算子会改变内部运算顺序,可能影响精度结果。
图优化策略可提升整体推理性能,但是部分图优化策略可能会改变计算顺序,影响数据分布。某些看似等价的数学变换,在使用低精度推理的情况下,存在精度溢出的可能性,影响网络最终精度。因此MagicMind会将某些会影响精度的图优化策略默认设置为关闭,并提供使能配置,允许用户权衡精度和性能。
13、conv qcast fusion
在量化网络中,将卷积算子的scale 参数与量化转数的scale 参数进行折叠,折叠过程中将转数算子的scale参数作用于卷积算子大的bias 数据上,使卷积和量化转数算子融合。会影响精度。支持持普通Relu。

14、设置计算偏好模式
有 自动,fast 和高精度三种模式。
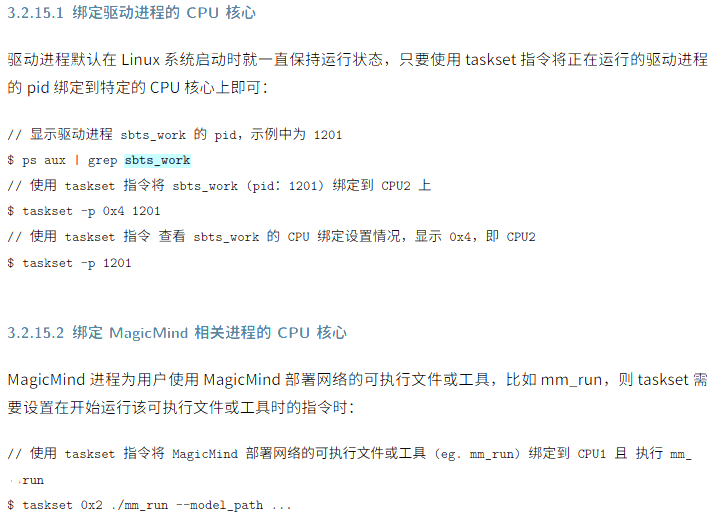
15、绑定CPU 核心
减少CPU 上下文切换。使用 Linux 的 taskset 命令将不同进程设置成亲和到不同CPU 上运行,目前已知的会争抢CPU 资源的两个进程是 MagicMind 部署接口业务进程和寒武纪驱动进程 sbts_work。绑定到CPU 如下:
16、AutoTuning 优化
该功能是在模型编译阶段,通过在MLU 板卡上抓取融合算子的运行时间,为后续算子融合的评估流程提供真实的算子运行时间数据,使得系统在算子融合是选择运行最快的算子融合方案,最终提升模型性能。
实验证明,大幅度提升性能
包含depthwise convoution的模型,例如 inception -V4
包含多分枝结构的模型,看i如SENet50


2内存工具

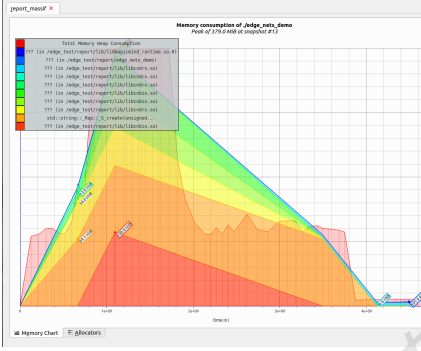
1、测量CPU 内存占用
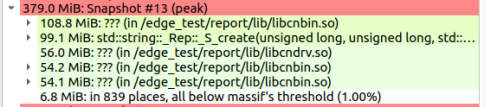
使用valgrind Massif 堆栈分析器测量程序堆栈大小,使用Massif-Visualizer 浏览数据图表
 以下是运行 ResNet50设置混合精度的CPU内存峰值379M:
以下是运行 ResNet50设置混合精度的CPU内存峰值379M:
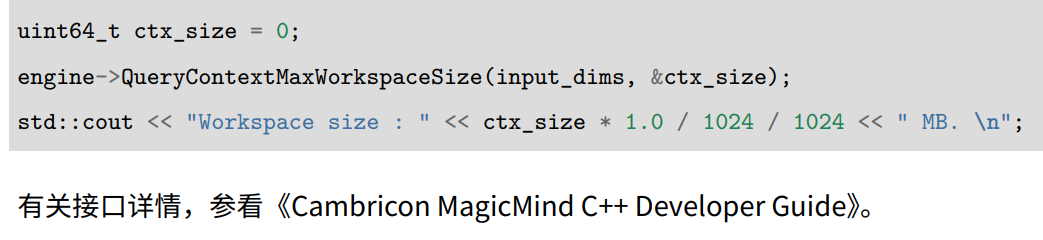
2、测量 MLU 内存占用
使用QueryConstDataSize 接口

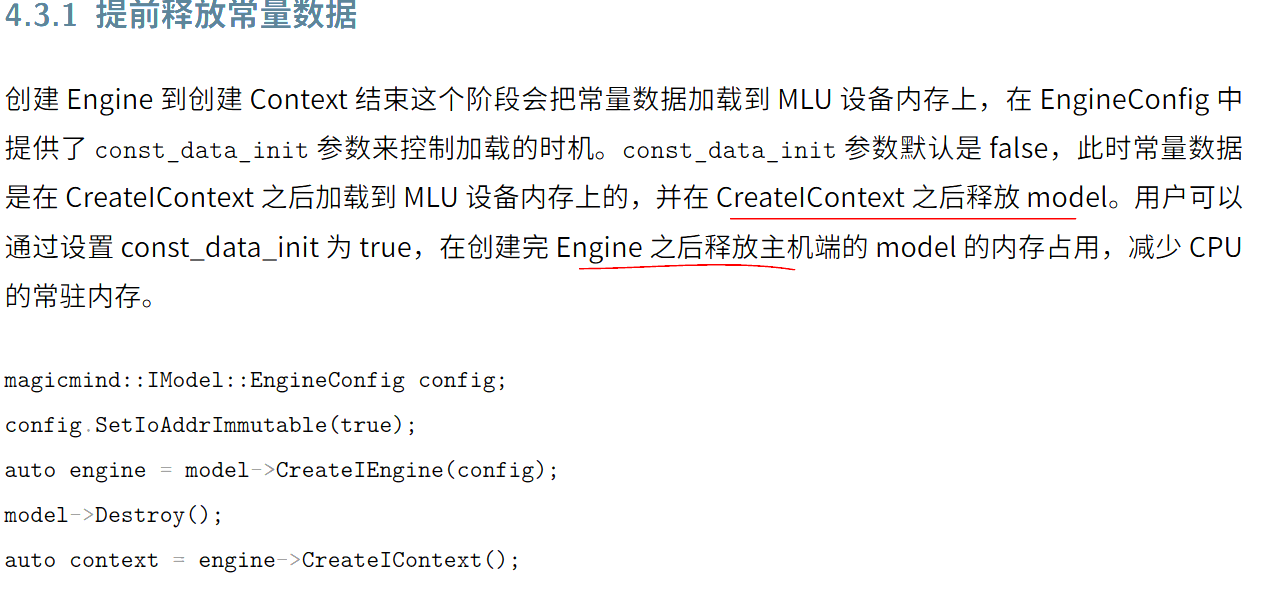
3、优化内存占用
- 提前释放常量数据
- 算子库裁剪


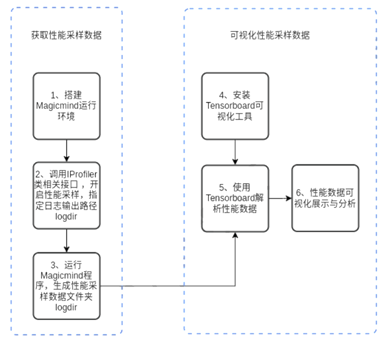
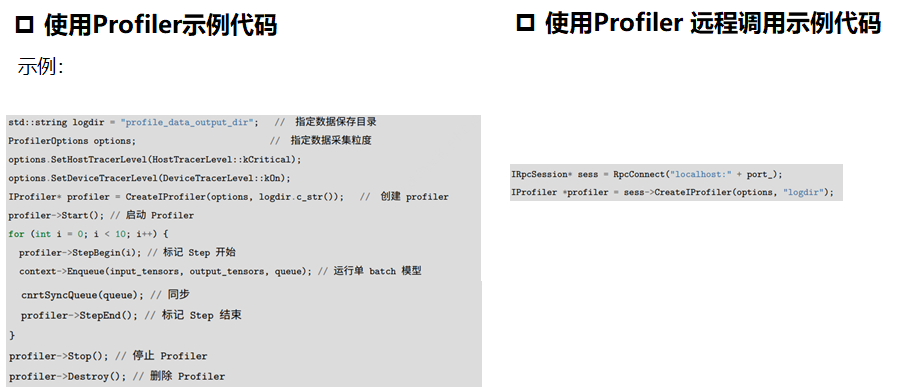
Profiler工具
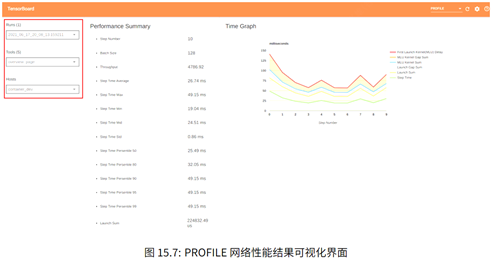
定位是主机侧问题、或者Device侧问题,或者定位内存占用问题。使用Profiler工具,用于并行度调优、性能分析和图形化性能展示。

3性能和精度差异说明
当用户通过不同的 解析Parse—> 校准(Calibrate)---->构图(Build)---->运行(Run),多相同模型会产生不同差距。可以从三个阶段分别说明原因。
1、解析
解析颗粒度可能存在差异。
-
用户原生矿机和MagicMind 的解析和各自的图优化差异,例如MM使用公共子表达式CSE消除优化,消除冗余表达,原生框架不一致时,会产生差异,导致网络性能差异,
-
原生框架对MM API的映射和MM解析原生框架API存在差异
2、校准
量化参数产生过程前的优化差异可能通过改变算网络结构影响设计量化算子(Conv,MatMul)的输入数据的分布,从而导致量化统计和参数的差异。
针对QAT/用户量化校准/MMjiaozhun 等情况,可能存在以下原因:
- Conv-BatchNorm/Scale 结构的执行顺序变更,将乘加挪移至滤波器/bias 后,该优化在量化统计前发生将影响统计结果。
- Concat算子链接多个Conv-MatMul乘加激活分支,将Contact挪至滤波器,该优化在量化参数统计前发生将影响统计结果。
上述或类似于统计前可完成的优化,无法在量化统计后的量化网络完成,否者会带来精度的较大损失。
3、构图
构图姐u但根据用户的配置项对网络进行修改从而导致性能/精度差异,如果两种构图方式性能/精度存在差异,需要核对以下方面是否对齐
-
模型输入形状是否固定。
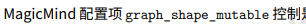
-
图像预处理存在差异。是否使能图像预处理(输入数据归一化)功能,会导致图结构差异。
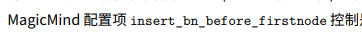
-
输入输出及算子物理布局差异。是否构图阶段对网络的输入和输出的Layout进行转换会影响图结构从而影响性能。
-
构图计算精度差异。例如,MM使用half精度推理模型,会将可常量折叠的分支使用高精度float计算,而此时用户构图使用half计算可常量折叠的分支,会带来两者的精度差异。