A survey of the Vision Transformers and its CNN-Transformer based Variants
- 摘要
- 1、介绍
- 2、vit的基本概念
- 2.1 patch嵌入
- 2.2 位置嵌入
- 2.2.1 绝对位置嵌入(APE)
- 2.2.2 相对位置嵌入(RPE)
- 2.2.3卷积位置嵌入(CPE)
- 2.3 注意力机制
- 2.3.1多头自我注意(MSA)
- 2.4 Transformer层
- 2.4.1 Feed-forward network
- 2.4.2 残差连接
- 2.4.3 归一化层
- 2.5 混合Vision Transformer(CNN-Transformer 架构)
- 3、vit中的架构级修改
- 3.1 基于补丁的方法
- 3.1.1 Tokens-to-Token Vision Transformer (T2T-ViT)
- 3.1.2. Transformer in Transformer (TNT-ViT)
- 3.1.3. Deformable Patch-based Transformer (DPT)
- 3.2. Knowledge transfer-based approaches
- 3.2.1 Data-efficient Image Transformers (DeiT)
- 3.2.2. Target-aware Transformer (TaT)
- 3.2.3 Tiny Vision Transformer (TinyViT)
- 3.3 Shifted window-based approaches
- 3.4. Attention-based approaches
- 3.4.1. Class attention layer (CaiT)
- 3.4.3. Patch-based Separable Transformer (SeT)
- 3.5. Multi-transformer-based approaches
- 3.5.1. Cross Vision Transformer (CrossViT)
- 3.5.2. Dual Vision Transformer (Dual-ViT)
- 3.5.3. Multiscale Multiview Vision Transformer (MMViT)
- 3.5.4. Multi-Path Vision Transformer (MPViT)
- 3.6. Taxonomy of HVTs (CNN-Transformer architectures)
- 3.6.1. Early-layer integration
- 1、Hybrid ViT
- 2、Detection Transformer (DETR)
- 3、LeNet-based Vision Transformer (LeViT)
- 4、Conditional Positional Encodings for Vision Transformers (CPVT)
- 3.6.2. Lateral-layer integration
- 3.6.3. Sequential integration
- 3.6.4. Parallel integration
- 3.6.5. Hierarchical integration
- 3.6.6. Attention-based integration
- 3.6.7. Channel boosting-based integration
- 3.7. Empirical comparison of different methods
- 4、Applications of HVTs
- 4.1. Image/video recognition
- 4.2. Image generation
- 4.3. Image segmentation
- 4.4. Image Restoration
- 4.5. Feature extraction
- 4.6. Medical image analysis
- 4.7. Object Detection
- 4.8. Pose Estimation
- 5. Challenges
- 6. 未来的方向
- 7. Conclusion
摘要
Vision transformers已经成为卷积神经网络(CNNs)的可能替代品,在各种计算机视觉应用中很受欢迎。这些变形金刚能够专注于图像中的全局关系,提供了强大的学习能力。然而,它们可能会受到有限的泛化,因为它们不倾向于在图像中建模局部相关性。最近,在视觉变压器中出现了混合卷积运算和自我注意机制,以利用局部和全局图像表示。这些混合视觉变压器,也称为cnn -Transformer结构,在视觉应用中显示出了显著的效果。鉴于混合视觉变压器数量的迅速增长,对这些混合架构进行分类和解释已成为必要。本文介绍了最近视觉变压器体系结构的分类,更具体地说,是混合视觉变压器的分类。此外,还讨论了这些架构的主要特征,如注意机制、位置嵌入、多尺度处理和卷积。与以往主要关注单个视觉变压器架构或cnn的调查论文相比,本调查独特地强调了混合视觉变压器的新兴趋势。通过展示混合视觉变压器在一系列计算机视觉任务中提供卓越性能的潜力,该调查阐明了这种快速发展的架构的未来方向。
1、介绍
数字图像本质上是复杂的,显示高级信息,如物体、场景和模式(Khan等,2021a)。这些信息可以通过计算机视觉算法进行分析和解释,以提取关于图像内容的有意义的见解,如识别对象、跟踪运动、提取特征等。由于计算机视觉在各个领域的应用,它已经成为一个活跃的研究领域(Bhatt et al. 2021)。然而,由于图像的亮度、位姿、背景杂波等的变化,从图像数据中提取高级信息具有挑战性。
卷积神经网络(cnn)的出现给计算机视觉领域带来了革命性的变革。这些网络已成功应用于各种各样的计算机视觉任务(Liu等人,2018;Khan等人,2020年,2022年,2023年;Zahoor et al. 2022),特别是图像识别(Sohail et al. 2021a;Zhang等(2023a),目标检测(Rauf等,2023),分割(Khan等,2021c)。cnn之所以受欢迎,是因为它们能够自动从原始图像中学习特征和模式(Simonyan和Zisserman 2014;Agbo-Ajala和Viriri 2021年)。一般来说,局部模式,即特征图案,是系统地分布在整个图像中。在卷积层中指定了不同的过滤器来捕获不同的特征基序,而CNNs中的池化层用于降维和合并对变化的鲁棒性。这种局部级的cnn处理可能会导致空间相关性的丢失,这可能会影响它们在处理更大、更复杂的模式时的性能。
最近在计算机视觉领域,在Vaswani等人于2017年首次将变压器引入文本处理应用程序(Vaswani et al. 2017a)之后,出现了一些向变压器的转变。2018年,Parmer等人开发了用于图像识别任务的变压器,并展示了出色的结果(Parmar等人,2018年)。从那时起,人们对将变压器应用于各种与视觉相关的应用产生了越来越大的兴趣(Liu et al. 2021b)。在2020年,Dosovitskiy等人推出了一种变压器架构,视觉Transformer(ViT),专门为图像分析而设计,显示了具有竞争力的结果(Dosovitskiy等人,2020)。ViT模型的工作原理是将一个输入图像分割成一定数量的patch,每个patch随后被平展并反馈给一系列的transformer图层。transformer图层使模型能够了解补丁和它们相应的特征之间的关系,从而能够在图像的全局范围内识别特征基序。与具有局部接受域的CNNs不同,ViTs利用其自我关注模块来建模长期关系,这使它们能够捕捉图像的全局视图(Ye et al. 2019;郭等人,2021)。ViTs的全局接受域有助于它们保持全局关系,从而识别分布在整个图像中的复杂视觉模式(Bi等,2021年;Wu等人。2023b)。在此背景下,Maurício等人报道了vit在各种应用中可能比cnn显示出有前景的结果(Zhang et al. 2021a;Maurício等。2023)。
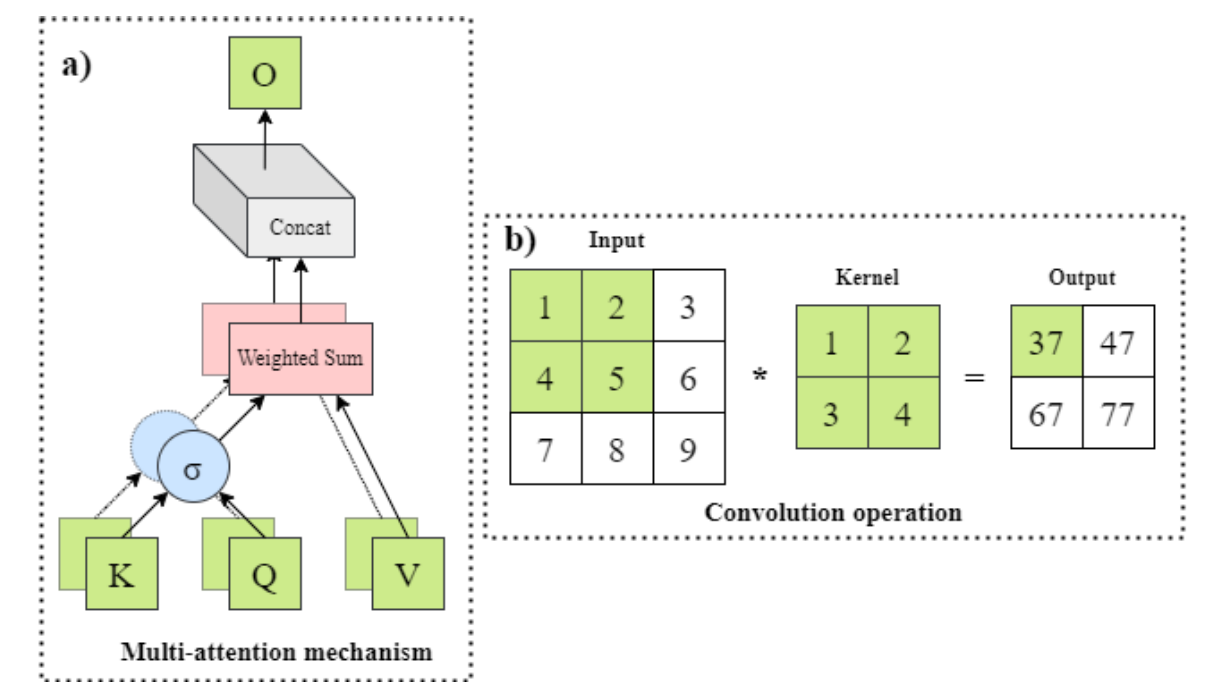
图1:多自我注意(MSA)机制和卷积运算的描述。MSA倾向于捕获全局关系,而卷积操作具有一个局部接受域来对图像中的像素邻域信息建模。
除了它们的设计和捕捉视觉模式的方式不同之外(如图1所示),cnn和vit的归纳偏差也不同。cnn严重依赖于相邻像素之间的相关性,而vit假定最小的先验知识,这使得它们严重依赖于大型数据集(Han et al. 2023)。而ViT模型在目标识别、分类、语义分割等计算机视觉任务中取得了优异的成绩(Kirillov et al. 2023;Dehghani等人,2023年),它们并不是一个放之四海而皆通的解决方案。在训练数据较小的情况下,尽管vit的学习能力较大,但与cnn相比,可能表现出有限的性能(Morra et al. 2020;Jamali等,2023)。此外,它们的大接收域需要更多的计算量。因此,引入混合视觉Transformers(HVT)的概念,即CNN-Transformer,将CNNs和ViTs的功率结合起来(Maaz et al. 2023)。这些混合模型利用了CNNs的卷积层来捕捉局部特征,然后将这些局部特征输入到ViTs中,使用self - attention机制获得全局上下文。HVTs在许多图像识别任务中表现出了更好的性能。
最近,人们进行了不同的调查,讨论了变压器最近的架构和实施进展(Liu et al. 2021b;Du等人,2022年;伊斯兰教2022;Aleissaee等人,2022年;Ulhaq等人,2022年;Shamshad等人,2023)。这些调查文章中的大多数要么关注特定的计算机视觉应用程序,要么深入讨论专门为自然语言处理(NLP)应用程序开发的变压器模型。相反,本调查报告强调了结合了CNNs和变压器概念的HVTs (CNN-Transformer)的最新发展。它提供了一种分类法,并探讨了这些混合模型的各种应用。此外,本文还提出了一般vit的分类,并旨在根据其核心架构设计对新兴的方法进行彻底的分类。
本文首先介绍了ViT网络的基本组件,然后讨论了各种最新的ViT架构。报告的ViT模型根据其独特的特征大致分为六类。此外,还包括了关于hvt的详细讨论,突出了他们对利用卷积操作和多注意力机制的优势的关注。综述了近年来hvt在各种计算机视觉任务中的体系结构和应用。此外,还提出了hvt的分类方法,根据这些体系结构结合卷积操作和自我注意机制的方式对其进行分类。该分类法将hvt分为七大类,每一类都反映了利用卷积和多注意操作的不同方式。表1列出了常用的缩略语。


2、vit的基本概念
图3说明了变压器的基本结构布局。首先,将输入图像进行分割、平化,并转换为低维线性嵌入,即Patch embeddings。然后将位置嵌入和类tokens附加到这些嵌入中,并将它们送入转换器的编码器块中,以生成类标签。该编码块除MSA层外,还包含前馈神经网络(FFN)、归一化层和残留连接。最后,最后一个头(MLP层,或解码器块)预测最终输出。下面的小节将详细讨论这些组件。
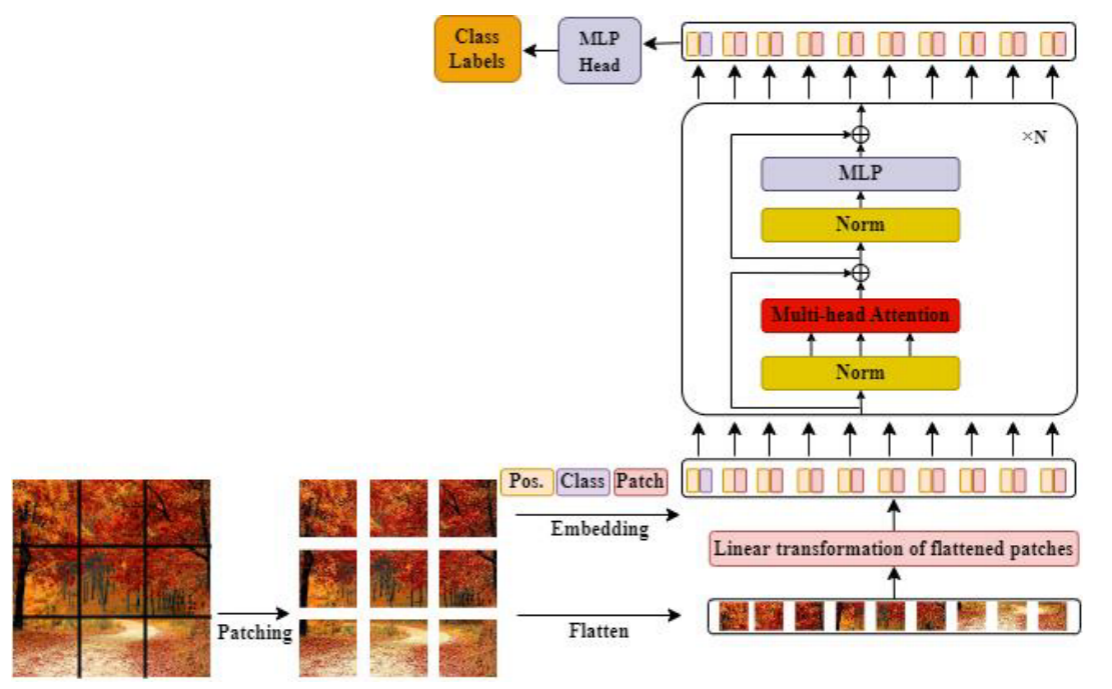
图3:ViT的详细架构。首先将输入图像分割成小块,然后将其线性变换后的嵌入信息与位置信息相结合,并通过多个编码器/解码器块进行下游任务的处理。
2.1 patch嵌入
补丁嵌入是ViT体系结构中的一个重要概念。它涉及到将图像补丁转换为向量表示,这使得ViT能够使用基于转换的方法将图像处理为tokens序列(Dosovitskiy et al. 2020)。将输入图像分割成固定大小的非重叠部分,将其平铺成一维向量,并利用含有嵌入维数的线性层将其投影到高维特征空间(如式1所示)。这使得它能够在涉及图像的任务中获得有希望的结果。

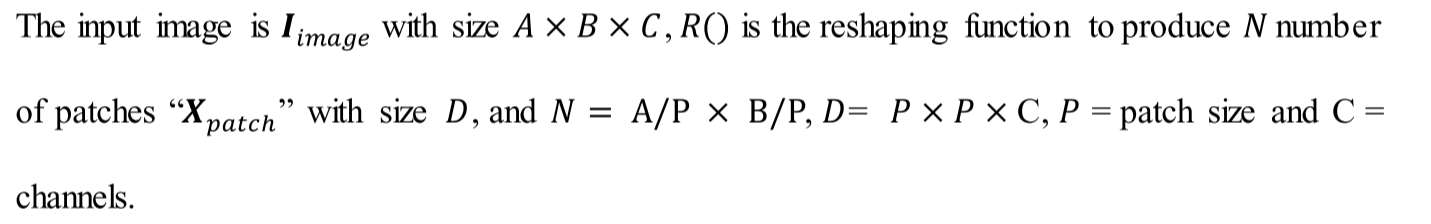
2.2 位置嵌入
vit利用位置编码将位置信息添加到输入序列中,并将其保留在整个网络中。补丁之间的顺序信息是通过位置嵌入捕获的,它被合并到patch嵌入中。自vit发展以来,人们提出了许多用于学习顺序数据的位置嵌入技术(Jiang et al. 2022)。这些技术分为三类:
2.2.1 绝对位置嵌入(APE)
通过在编码器块之前使用APE,将位置嵌入集成到patch嵌入中。

2.2.2 相对位置嵌入(RPE)
相对位置嵌入(RPE)技术主要用于将与相对位置相关的信息纳入注意模块(Wu et al. 2021b)。这种技术基于斑块之间的空间关系比它们的绝对位置更有分量的思想。要计算RPE值,需要使用一个基于可学习参数的查找表。查找过程由补丁之间的相对距离决定。尽管RPE技术可扩展到不同长度的序列,但它可能会增加训练和测试时间(Chu等人,2021b)。
2.2.3卷积位置嵌入(CPE)
卷积位置嵌入(CPE)方法考虑了输入序列的2D特性。二维卷积利用零填充来收集位置信息,以利用二维特性(Islam et al. 2021)。卷积位置嵌入(CPE)可用于整合ViT不同阶段的位置数据。CPE可以专门引入到自我注意模块(Wu et al. 2021a)、前馈网络(FFN) (Li et al. 2021c;Wang等人2021b),或者在两个编码器层之间(Chu等人2021a)。
2.3 注意力机制
ViT体系结构的核心组件是自注意机制,它在显式表示序列中实体之间的关系方面起着至关重要的作用。它通过表示每个实体的全局上下文信息并捕捉它们之间的交互来计算一个项目对其他项目的重要性(Vaswani et al. 2017b)。自注意模块将输入序列转换为三个不同的嵌入空间,即查询、键和值。具有查询向量的键值对集被作为输入。输出向量是通过对这些值进行加权和,然后使用softmax运算符来计算的,其中加权由一个评分函数来计算(公式3)。
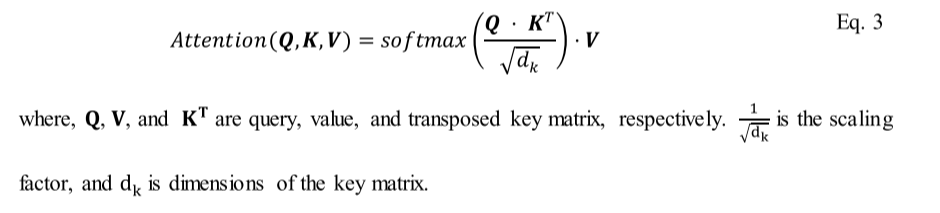
2.3.1多头自我注意(MSA)
单头自我注意模块的能力有限,往往导致它只关注少数几个位置,可能会忽略其他重要的位置。为了解决这个限制,使用了MSA。MSA利用自注意块的平行叠加来增加自注意层的有效性(Vaswani et al. 2017b)。它通过向注意层分配各种表示子空间(查询、键和值)来捕获序列元素之间各种复杂的交互。MSA构成多个自我注意块。每一个都配备了用于查询、键和值子空间的可学习权矩阵。然后,这些块的输出被连接起来,并使用可学习参数𝑊𝑂投射到输出空间。这使得MSA能够关注多个部分,并有效地捕获所有领域中的关系。注意过程的数学表示如下:
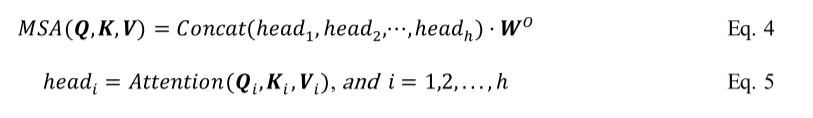
与卷积处理相比,自注意力为每个输入序列动态计算过滤器的能力是一个显著的优势。与通常是静态的卷积滤波器不同,自我注意可以根据输入数据的特定上下文进行调整。自注意力对输入点的数量或它们的排列变化也很敏感,这使它成为处理不规则输入的良好选择。另一方面,传统的卷积过程不太适合处理具有可变对象的输入,并且需要像2D图像那样的网格结构。自注意力是对顺序数据建模的强大工具,在包括NLP在内的各种任务中都很有效(Khan等,2021b)。
2.4 Transformer层
一个ViT编码器由几个层来处理输入序列。这些层包括MSA机制、前馈神经网络(FFN)、剩余连接和归一化层。这些层被安排来创建一个统一的块,该块被重复多次以学习输入序列的复杂表示。
2.4.1 Feed-forward network
为了从输入数据中获得更复杂的属性,模型中采用了变压器专用前馈网络(FFN)。它包含多个全连接层和一个非线性激活函数,如层之间的GELU(公式6)。FFN的隐藏层通常有一个2048的维度。这些FFNs或MLP层是局部的,在翻译上相当于全局的自我关注层(Dosovitskiy et al. 2020)。
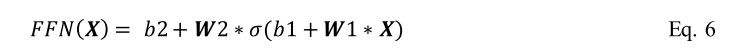
在式7中,非线性激活函数GELU用σ表示。网络的权值表示为W1、W2,而b1、b2对应的是分层偏差
2.4.2 残差连接
编码/解码器中的子层(MSA和FFN)利用剩余链路来提高性能和加强信息流。将原始的输入位置嵌入作为附加信息加入到MSA的输出向量中。然后对剩余的连接进行层归一化操作(式7)。

2.4.3 归一化层
层归一化的方法有多种,例如经常使用的层前归一化(Pre-LN)(Kim et al. 2023)。归一化层放置在 MSA 或 FFN 之前并位于残差连接内部。人们建议使用其他标准化程序(包括批量标准化)来增强变压器模型的训练,但是,由于特征值的变化,它们可能不会那么有效(Jiang et al. 2022)。
2.5 混合Vision Transformer(CNN-Transformer 架构)
在计算机视觉任务领域,vit越来越受欢迎,但与cnn相比,它们仍然缺乏特定于图像的归纳偏见,通常被称为先验知识(Seydi和Sadegh 2023)。这种归纳偏差包括平移和尺度不变性等特征,这是由于不同空间位置的权重共享所致(Moutik等人,2023)。在cnn中,局部性、平移等方差和二维邻域结构在整个模型的每一层中都根深蒂固。此外,kernel利用相邻像素之间的相关性,便于快速提取好的特征(Woo et al. 2023)。另一方面,在ViT中,图像被分割成线性补丁(tokens),这些补丁通过线性层被送入编码器块,以在图像中建模全局关系。然而,线性层在提取局部相关方面缺乏有效性(Woo et al. 2023)。
许多HVT设计都关注于卷积在捕获图像中的局部特征方面的效率,特别是在图像处理工作流程的初始阶段(用于修补和标记化)(Guo等,2023)。例如卷积视觉Transformer(Convolutional Vision Transformer, CvT)就是利用卷积投影来学习图像patch中的空间和低层信息。它还利用token数量逐渐减少和token宽度增加的分层布局来模拟CNNs中的空间下采样效应(Wu et al. 2021a)。类似地,卷积增强图像Transformers(CeiT)利用卷积操作通过图像到令牌模块提取低级别特征(Yuan等,2021a)。紧凑卷积Transformer(CCT)提出了一种新的序列池化技术,该技术还集成了对流池整形块来进行标记化(Hassani et al. 2021)。在从头开始训练时,它在CIFAR10等较小的数据集上也显示了约95%的准确性,这通常是其他传统vit难以实现的。
最近的一些研究研究了增强vit局部特征建模能力的方法。LocalViT采用深度卷积来提高建模局部特征的能力(Li et al. 2021c)。LeViT在ViT架构的开始使用一个四层CNN块,在推理时逐渐增加通道并提高效率(Graham et al. 2021)。然而ResT也使用了类似的方法来管理图像大小的波动、深度卷积和自适应位置编码(Zhang和Yang 2021)。
在没有额外数据的情况下,CoAtNets独特的深度卷积和相对自注意架构实现了出色的ImageNet顶级精度(Dai等人,2021年)。为了创建更强的跨补丁连接,Shuffle Transformer提供了一个Shuffle操作(Huang et al. 2021b),而CoaT是一种混合方法,它结合了深度卷积和交叉注意来对不同尺度的tokens之间的关系进行编码(Xu et al. 2021a)。另一种方法“twin”建立在PVT的基础上,结合了可分离深度卷积和相对条件位置嵌入(Chu等人2021a)。最近,混合架构MaxVit引入了多轴注意力的概念。他们的混合块由基于mbconvbased的卷积、随后的块自注意和网格自注意组成,当重复多次时,该块创建一个分层表示,并能够完成图像生成和分割等任务(Tu et al. 2022b)。块智能注意层和网格智能注意层能够分别提取局部和全局特征。在这些混合设计中,卷积和变压器模型的强度是要结合起来的。
3、vit中的架构级修改
近年来,ViT架构进行了不同的修改(Zhou et al. 2021)。这些修改可以根据它们的注意机制、位置编码、预训练策略、架构更改、可伸缩性等进行分类。基于架构修改的类型,ViT架构可以大致分为五大类,分别是(i)基于补丁的方法、(ii)基于知识转移的方法、(iii)基于移位窗口的方法、(iv)基于注意力的方法和(v)基于多重转换的方法。然而,可以观察到,随着CNN对vit的归纳偏见的引入,其性能得到了提升。在这方面,我们还根据结构设计将hvt分为七类。ViT体系结构的分类如图4所示。
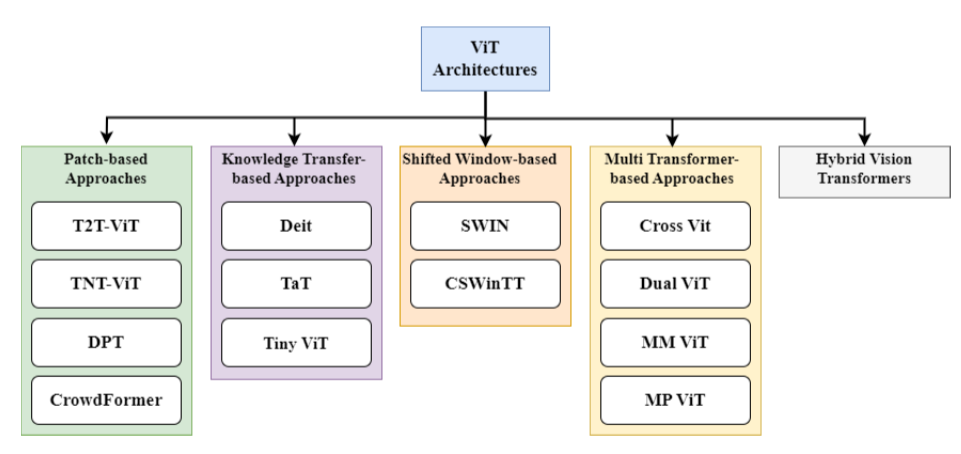
图4:视觉ViT架构的分类。
3.1 基于补丁的方法
在ViT中,首先将图像划分为补丁网格,然后将其压平以生成线性嵌入,并将其作为tokens序列处理(Dosovitskiy et al. 2020)。将Positiona l嵌入和类tokens添加到这些嵌入中,然后将它们提供给编码器以进行特性学习。一些研究利用不同的patch提取机制来提高ViTs的性能。这些机制包括固定大小的补丁(Wang et al. 2021c)、动态补丁(Ren et al. 2022;Zhang等人2022c),以及重叠补丁(Wang等人2021b)。在这方面,我们讨论了几种架构及其补丁标准。
3.1.1 Tokens-to-Token Vision Transformer (T2T-ViT)
令牌到令牌视觉Transformer(T2T-ViT)利用固定大小和迭代方法生成补丁(Yuan等,2021b)。它利用提出的令牌到令牌模块迭代地从图像中生成补丁。生成的补丁然后被反馈到T2T-ViT网络以获得最终的预测。
3.1.2. Transformer in Transformer (TNT-ViT)
Transformer ViT (TNT-ViT) 中的 Transformer 提出了一种多级修补机制,用于学习不同大小和位置的对象的表示(Han et al. 2021)。它首先将输入图像划分为补丁,然后每个补丁进一步划分为子补丁。随后,该架构利用不同的转换器块来对补丁和子补丁之间的关系进行建模。大量实验证明了 TNT-ViT 在 ImageNet 数据集上的图像分类方面的效率。
3.1.3. Deformable Patch-based Transformer (DPT)
基于可变形补丁的 Transformer (DPT) 提出了一种名为 DePatch 的自适应补丁嵌入模块(Chen 等人,2021e)。变压器中的固定大小修补会导致语义信息丢失,从而影响系统性能。在这方面,DPT中提出的DePatch模块以自适应方式分割图像,以获得具有可变大小和强语义信息的补丁。
###3.1.4. CrowdFormer
Yang 和合著者开发了一种 ViT 架构 CrowdFormer,用于人群计数(Yang 等人,2022b)。所提出的架构利用其重叠修补变压器块来捕获人群的全局上下文信息。为了以自上而下的方式考虑不同尺度的图像,利用了重叠修补层,其中使用滑动窗口代替固定大小的修补程序来提取重叠修补程序。这些重叠的斑块往往会保留相关的上下文信息,以进行有效的人群计数。
3.2. Knowledge transfer-based approaches
此类别涵盖了那些利用知识转移(知识蒸馏)方法的 ViT 架构。它涉及将知识从较大的网络传输到较小的网络,就像老师向学生传授知识一样(Kanwal et al. 2023;Habib et al. 2023)。教师模型通常是一个具有丰富学习能力的复杂模型,而学生模型则比较简单。知识蒸馏背后的基本思想是促进学生模型获取和融合教师模型的独特特征。这对于计算资源有限的任务特别有用,因为较小的 ViT 模型比较大的模型可以更有效地部署。
3.2.1 Data-efficient Image Transformers (DeiT)
Deit 是 ViT 的更小、更高效的版本,它在各种任务上都表现出了有竞争力的性能(Touvron et al. 2020)。它为教师使用预先训练的 ViT 模型,为学生使用较小的版本。通常,监督学习和无监督学习结合使用,教师网络监督学生网络以产生类似的结果。除了 DeiT 的推理时间快和计算资源有限之外,它还具有改进的泛化性能,因为学生模型已经学会捕获数据中最重要的特征和模式,而不仅仅是记住训练数据。
3.2.2. Target-aware Transformer (TaT)
目标感知变压器(TaT)(Lin et al. 2022)利用一对多关系将信息从教师网络交换到学生网络。特征图首先被划分为多个块,然后对于每个块,所有教师的特征都转移到所有学生的特征,而不是采用所有空间区域之间的相关性。然后将补丁内的所有特征平均化为单个向量,以使知识转移计算高效。
3.2.3 Tiny Vision Transformer (TinyViT)
吴等人。提出了一种快速蒸馏方法以及一种称为 TinyViT 的新颖架构(Wu 等人,2022a)。他们的主要概念是在预训练期间将大型预训练模型的学习特征传达给小型模型(图 5)。除了预先在光盘上进行编码数据增强之外,还减少并存储了指导模型的输出逻辑,以节省内存和计算资源。然后,学生模型采用解码器来重新构建保存的数据增强,并通过输出 logits 传输知识,两个模型都独立训练。结果证明了 TinyViT 在大规模测试集上的有效性。
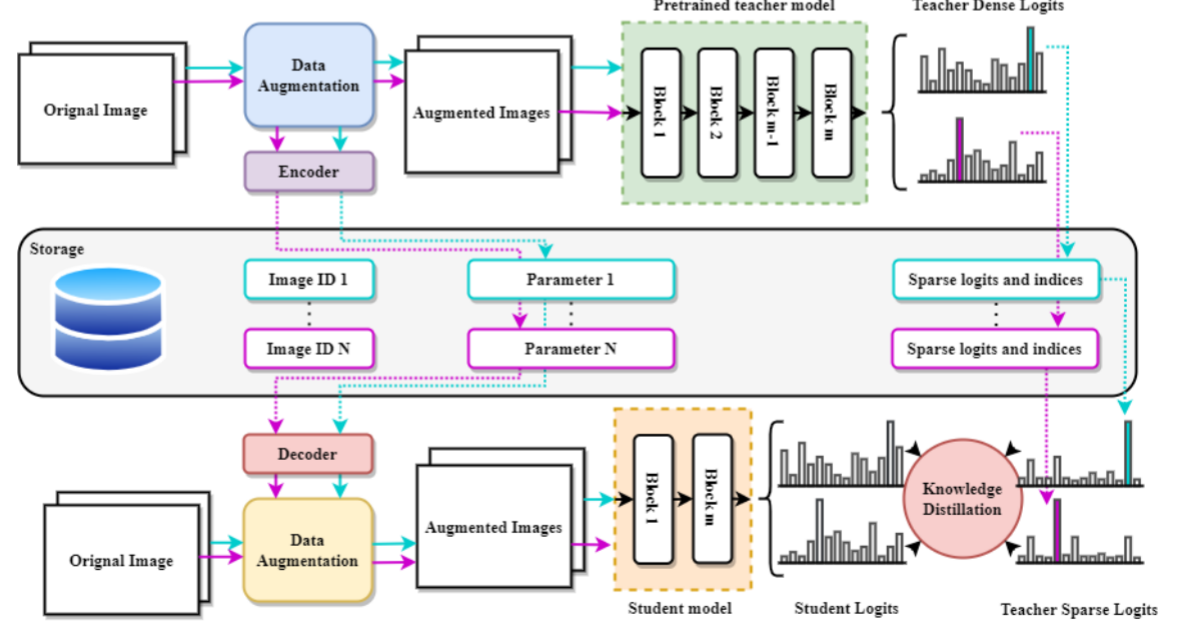
图 5:基于知识转移的方法 (TinyViT) 的详细工作流程。
3.3 Shifted window-based approaches
一些 ViT 架构采用了基于移位窗口的方法来增强其性能。这种方法首先由 Liu 等人提出。在他们的 Swin Transformer 中(Liu et al. 2021c)。 Swin Transformer 具有与 ViT 类似的架构,但采用了移位窗口方案,如图 6 所示。它通过在每个不重叠的本地窗口内计算自注意力计算来控制自注意力计算,同时仍然提供跨窗口连接以改进的功效。这是通过将基于移位窗口的自注意力实现为两个连续的 Swin Transformer 块来实现的。第一个块使用常规的基于窗口的自注意力,第二个块移动这些窗口并再次应用常规的基于窗口的自注意力。移动窗口背后的想法是实现跨窗口连接,这可以帮助网络提高其对全局关系进行建模的能力。
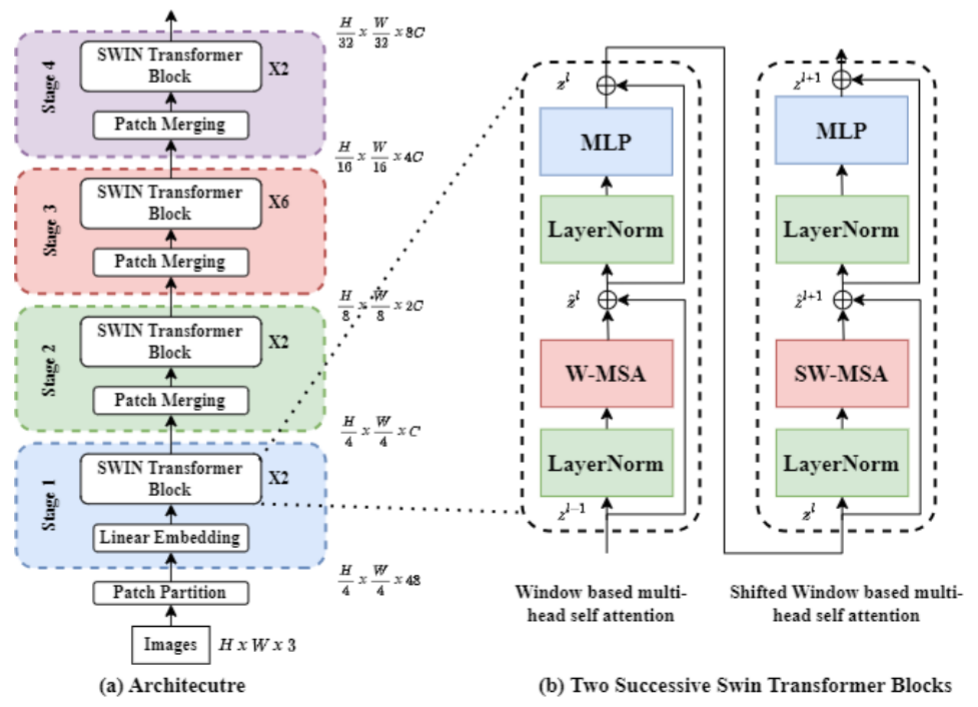
图 6:Swin Transformer 的架构图(基于移位窗口的方法)。
宋等人。提出了一种用于视觉对象跟踪的新颖 ViT 架构,名为 CSWinTT,它在多尺度上利用基于循环移位窗口的注意力(Song 等人,2022b)。这种方法将像素注意力增强到窗口注意力,并实现跨窗口多尺度注意力以聚合不同尺度的注意力。这确保了跟踪对象的完整性,并为目标对象生成最佳的精细匹配。此外,循环移位技术利用位置信息扩展了窗口样本,从而提高了准确性和计算效率。通过将位置信息纳入注意机制,模型能够更好地处理对象位置随时间的变化,并且可以更有效地跟踪对象。总体而言,所提出的架构在提高使用基于 ViT 的模型的视觉对象跟踪的准确性和效率方面显示出了有希望的结果。
3.4. Attention-based approaches
人们提出了许多 ViT 架构来修改自注意力模块以提高其性能。其中一些模型利用密集的全局注意力机制(Vaswani et al. 2017a;Dosovitskiy et al. 2020),而其他模型则利用稀疏注意力机制(Jiang et al. 2021;Liu et al. 2021c;Dai et al. 2021)来捕获图像中的全局级依赖性,没有空间相关性。众所周知,这些类型的注意力机制的计算成本很高。为了在性能和计算复杂性方面改进注意力模块,人们已经做了许多工作(Tu et al. 2022b)。
3.4.1. Class attention layer (CaiT)
图夫龙等人。引入了一种提高深度变压器性能的新方法(Touvron et al. 2021)。他们的架构名为 CaiT,包含一个自注意力模块和一个类注意力模块。自注意力模块就像普通的 ViT 架构一样,但在初始层中没有添加类标记(类信息)。类嵌入被添加到类注意力模块中,稍后在架构中。他们的方法通过一些参数显示出良好的结果。
###3.4.2. Deformable attention transformer (DAT)
Xia 和合著者提出了一种依赖于数据的注意力机制,以关注更可靠的区域(Xia 等人,2022)。他们的架构采用模块化设计,每个阶段都有一个局部注意力层,然后每个阶段都有一个可变形注意力层。所提出的 DAT 架构在基准数据集上展示了出色的性能。
3.4.3. Patch-based Separable Transformer (SeT)
孙等人。在其 ViT 架构中使用了两个不同的注意力模块来完全捕获图像中的全局关系(Sun et al. 2022)(图 7)。他们提出了一个像素级注意模块来学习初始层中的局部交互。后来他们利用补丁式注意力模块来提取全局级别的信息。 SeT 在多个数据集(包括 ImageNet 和 MS COCO 数据集)上显示出优于其他方法的结果。
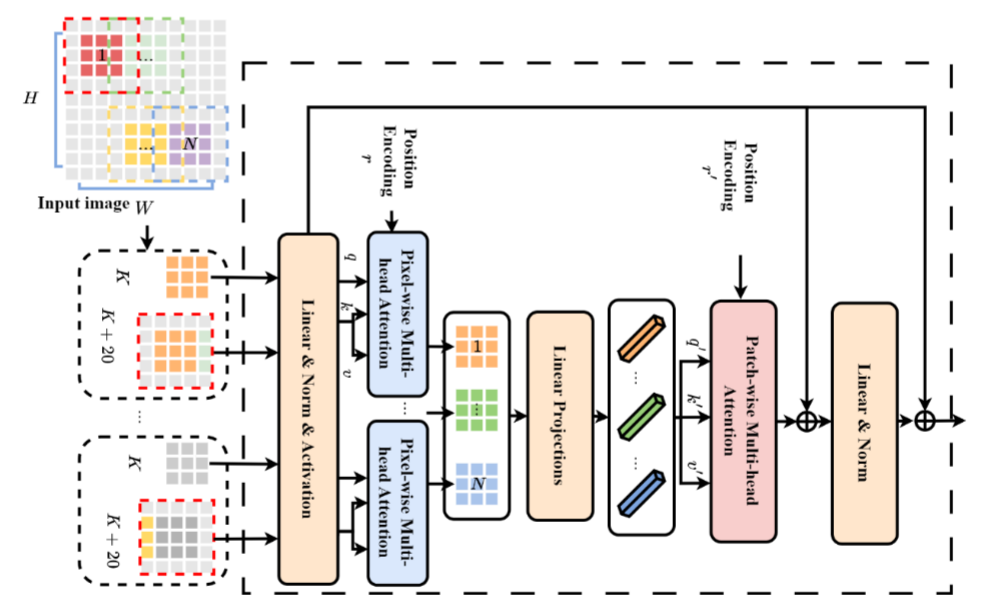
图 7:基于补丁的可分离变压器 (SeT) 的架构,它通过引入两个不同的注意力块来修改其 MSA 层。
3.5. Multi-transformer-based approaches
许多方法在其架构中利用多个 ViT 来提高需要多尺度功能的各种任务的性能。本节讨论此类基于多变压器的 ViT 架构。
3.5.1. Cross Vision Transformer (CrossViT)
Chen 和合著者提出了一种具有双分支的 ViT 架构,他们将其命名为 CrossViT(Chen 等人,2021a)。该模型的关键创新在于不同大小的图像块的组合,这使得 CrossViT 能够生成与领域高度相关的特征。较小和较大的补丁令牌使用具有不同计算复杂性的两个单独的分支进行处理。使用高效的交叉注意模块将两个分支多次融合在一起。该模块通过创建非补丁令牌来实现分支之间的知识传输。通过这个过程,注意力图的生成是线性地而不是二次地实现的。这使得 CrossViT 比使用二次注意力的其他模型更具计算效率。
3.5.2. Dual Vision Transformer (Dual-ViT)
双视觉变压器(Dual-ViT)是一种新的 ViT 架构,可以降低自注意力机制的计算成本(Yao 等人)。该架构利用两个单独的路径来捕获全局和本地级别的信息。语义分支学习粗略的细节,而像素路径捕获图像中更精细的细节。这两个分支是并行整合和培训的。与其他现有模型相比,所提出的 DualViT 在 ImageNet 数据集上以更少的参数显示出良好的结果。
3.5.3. Multiscale Multiview Vision Transformer (MMViT)
多尺度多视图视觉变换器 (MMViT) 将多尺度特征图和多视图编码合并到变换器模型中。 MMViT 模型利用多个特征提取阶段来并行处理各种分辨率的输入的多个视图。在每个规模阶段,都会利用交叉注意力块来合并不同视角的数据。这种方法使 MMViT 模型能够以多种分辨率获取输入的高维表示,从而产生复杂且鲁棒的特征表示。
3.5.4. Multi-Path Vision Transformer (MPViT)
MPViT 利用多尺度修补技术和基于多路径的 ViT 架构来学习不同尺度的特征表示(Lee 等人,2021b)。他们提出的多尺度修补技术利用 CNN 创建不同尺度的特征图(图 8)。后来他们利用多个转换器编码器来处理多尺度补丁嵌入。最后,它们聚合每个编码器的输出以生成聚合输出。与 ImageNet 数据集上的现有方法相比,所提出的 MPViT 表现出了更好的结果。
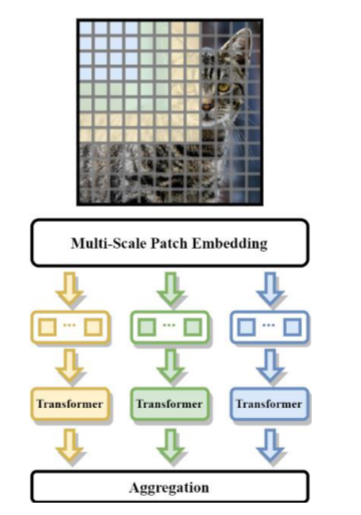
图 8:基于多变压器的 MPViT 架构,其架构中使用了多个变压器。
3.6. Taxonomy of HVTs (CNN-Transformer architectures)
尽管 ViT 具有成功的性能,但仍面临三个主要问题,a)无法通过考虑局部邻域的相关性来捕获低级特征,b)由于其 MSA 机制而导致计算和内存消耗昂贵,c)和固定大小输入标记,嵌入。为了克服这些问题,2021 年之后出现了 CNN 和 ViT 混合的热潮。HVT 结合了 CNN 和 Transformer 架构的优势,创建了用于捕获图像中的局部模式和全局上下文的模型(Yuan 等人,2023b)。由于在多项图像相关任务中取得了有希望的成果,他们在研究界获得了宝贵的关注(Li et al. 2022)。研究人员通过利用不同的方法来合并 CNN 和 Transformer,提出了该领域的各种架构(Heo 等人,2021 年;Si 等人,2022 年)。这些方法包括但不限于在 Transformer 块内添加一些 CNN 层(Liu et al. 2021a;He et al. 2023;Wei et al. 2023),在 CNN 中引入多注意力机制(Zhang et al. 2023) . 2021b; Ma et al. 2023b),或使用 CNN 提取局部特征和转换器来捕获远程依赖性(Yuan et al. 2021a、2023a;Zhang et al. 2023c)。在这方面,我们根据卷积运算与 ViT 架构的集成模式定义了一些子类别。这些包括(1)早期层集成,(2)横向层集成,(3)顺序集成,(4)并行集成,(5)块集成,(6)分层集成,(7)基于注意力的集成,以及( 8) 通道增强积分,如图 9 所示。
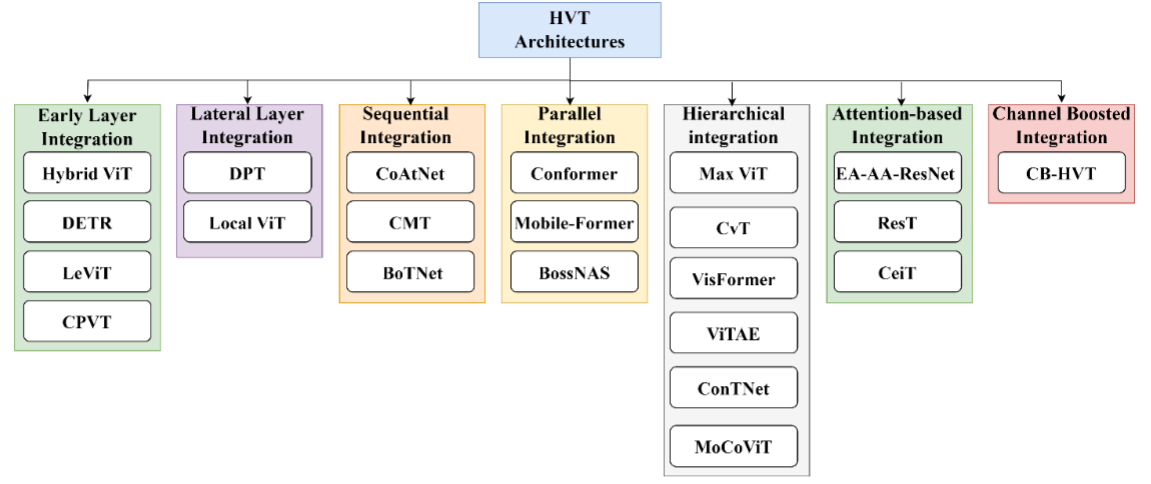
图 9:混合 ViT 的分类。
3.6.1. Early-layer integration
ViT 很好地捕获了图像中的长程依赖性,但由于不存在归纳偏差,因此训练它们需要大量数据。另一方面,CNN 固有的与图像相关的归纳偏差并捕获本地图像中存在的高级相关性。因此,研究人员正在专注于设计 HVT,以融合 CNN 和 Transformer 的优点(Pan et al. 2022)。为了找出在 Transformer 架构中融合卷积和注意力的最佳方法,我们做了很多工作。 CNN 可以在不同级别上使用,以将局部性纳入架构中。各种研究表明,首先捕获局部模式,然后学习远程依赖性,以获得更优化的图像局部和全局视角是有益的(Peng et al. 2023)。
1、Hybrid ViT
第一个 ViT 架构是由 Dosovitskiy 等人提出的。 2020 年(Dosovitskiy 等人,2020)。在他们的工作中,他们提出了将图像块视为标记序列并将其输入基于变压器的网络以执行图像识别任务的想法。在他们的论文中,他们通过提出混合版本的 ViT 为 HVT 奠定了基础。在混合架构中,输入序列是从 CNN 特征图而不是原始图像块中获得的(LeCun 等人,1989)。输入序列是通过在空间上展平特征图来创建的,并且使用 1x1 滤波器生成补丁。他们利用 ResNet50 架构来获取特征图作为 ViT 的输入(Wu et al. 2019)。此外,他们还进行了广泛的实验来确定用于特征图提取的最佳中间块。
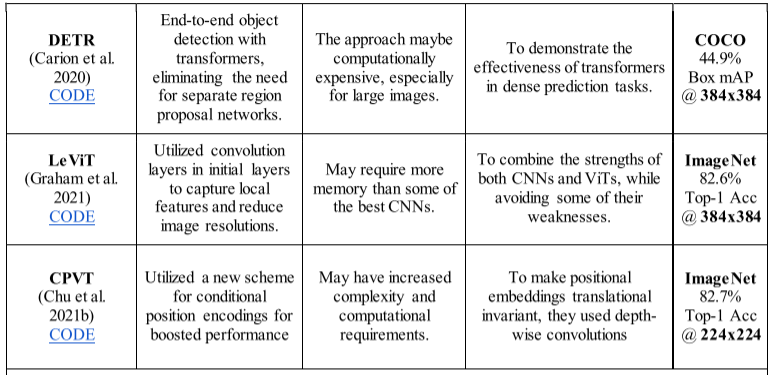
2、Detection Transformer (DETR)
卡里昂等人。 2020 年提出了一种用于在自然图像中执行对象检测的检测变压器(DETR)(Carion et al. 2020)。在他们提出的端到端方法中,他们最初使用 CNN 来处理输入,然后将其馈送到 ViT 架构。来自 CNN 主干的特征图与固定大小的位置嵌入相结合,为 ViT 编码器创建输入。 ViT 解码器的输出随后被馈送到前馈网络以做出最终预测。与 Faster R-CNN 等其他革命性检测模型相比,DETR 显示出更好的性能。他们的详细想法如图 10 所示。
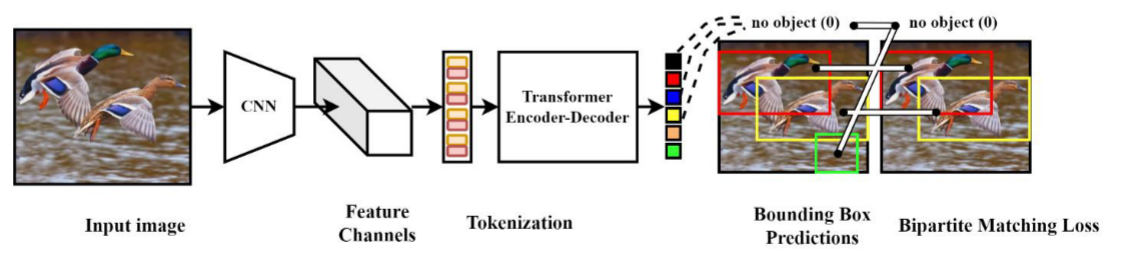
图 10:DETR 的架构,其中 CNN 集成作为初始主干块。
3、LeNet-based Vision Transformer (LeViT)
格雷厄姆等人。于 2021 年提出了混合 ViT“LeViT”(Graham et al. 2021)。在他们的模型中,他们最初利用卷积层来处理输入。所提出的架构将 CNN 与 ViT 架构的 MSA 相结合,从输入图像中提取局部和全局特征。 LeViT架构首先利用四层CNN模型来降低图像分辨率并获得局部特征表示。然后将这些表示馈送到具有 MLP 和注意力层的 ViT 启发的多级架构中以生成输出。
4、Conditional Positional Encodings for Vision Transformers (CPVT)
CPVT是由Chu等人提出的。 2023 年(Chu 等人,2021b)。在他们的工作中,他们设计了一种新的条件位置嵌入方案来提高 ViT 的性能(图 11)。在这方面,他们提出了位置编码生成器(PEG),它利用深度卷积使位置嵌入更加局部和平移等效。他们还基于所提出的方案开发了 ViT,利用 PEG 将更多位置信息纳入其架构中,并显示出良好的结果。此外,他们还表明,最终 MLP 层之上的全局平均池化层(而不是类标记)带来了性能提升。肖等人。他们的研究估计,在 ViT 的早期层使用 CNN 层可以提高其性能(Xiao 等人,2021)。为了进行比较,他们用卷积干代替了传统的 ViT 修补,并报告了更通用和增强的性能。
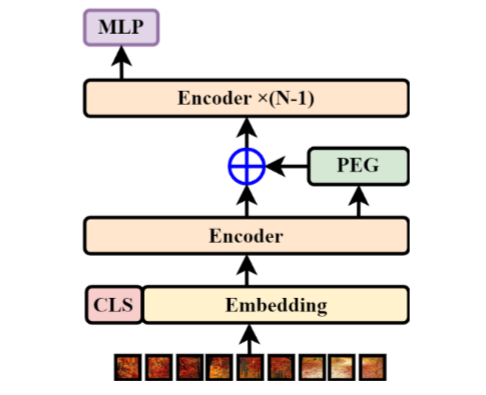
图 11:CPVT 的架构,将 CNN 纳入其 PEG 模块中。
3.6.2. Lateral-layer integration
在 Transformer 网络末端使用 CNN 层或块(例如代替最后一个线性层)或作为后处理层的模型就属于此类。
- Dense Prediction Transformer (DPT)
兰福特等人。提出了一种用于自然图像分割的密集预测变换器“DPT”。 DPT 采用基于编码器-解码器的设计,ViT 作为编码器,CNN 作为解码器。它通过主干架构捕获了全局视角和远程依赖关系。然后将学习到的全局表示解码为利用 CNN 获取的基于图像的嵌入。基于 ViT 的编码器的输出在不同级别进行解码,以进行密集预测(Ranftl 等人,2021)。 - Local Vision Transformer (LocalViT)
Li等人在他们的研究中还将局部性纳入ViT架构中以进行图像分类。 LocalViT的架构就像传统的ViT一样,其MSA模块专门用于捕获图像的全局级特征。 ViT 编码器中的前馈网络通过从注意力模块学习的编码中获取输入来执行最终预测。 LocalVit 修改其 FFN,通过采用深度卷积将局部信息纳入其架构中(Li et al. 2021c)。
3.6.3. Sequential integration
此类别描述了一些流行的混合 ViT,它们通过遵循一些顺序集成,在其 ViT 架构中利用 CNN 的优势(Wang 等人,2023c)。
- Convolution and Attention Networks (CoAtNet)
戴等人。进行了广泛的研究,以找出在单一架构中合并卷积和注意力机制的最佳和有效的方法,以提高其泛化性和容量(Dai et al. 2021)。在这方面,他们通过垂直堆叠几个卷积和变压器块引入了 CoAtNet。对于卷积块,他们采用了基于深度卷积的 MBConv 块。他们的研究结果表明,依次堆叠两个卷积块和两个变压器块可以显示出有效的结果。 - CNNs Meet Transformers (CMT)
尽管 ViT 具有成功的性能,但仍面临三个主要问题,a)无法通过考虑局部邻域的相关性来捕获低级特征,b)由于其 MSA 机制而导致计算和内存消耗昂贵,c)和固定大小的输入令牌、嵌入。为了克服这些问题,2021 年之后出现了 CNN 和 ViT 混合的热潮。 2021 年还提出了一种混合 ViT,名为 CMT(CNNs Meet Transformers)(Guo et al. 2021)。受 CNN(Tan 和 Le 2019)的启发,CMT 还包含一个初始主干块,然后是 CNN 层和 CMT 块的顺序堆叠。设计的 CMT 模块受到 ViT 架构的启发,因此包含一个轻量级 MSA 模块来代替传统的 MSA,并且 MLP 层被替换为反向残差前馈网络(IRFFN)。此外,在CMT块中添加本地感知单元(LPU)以增加网络的表示能力。其架构如图 12 所示。
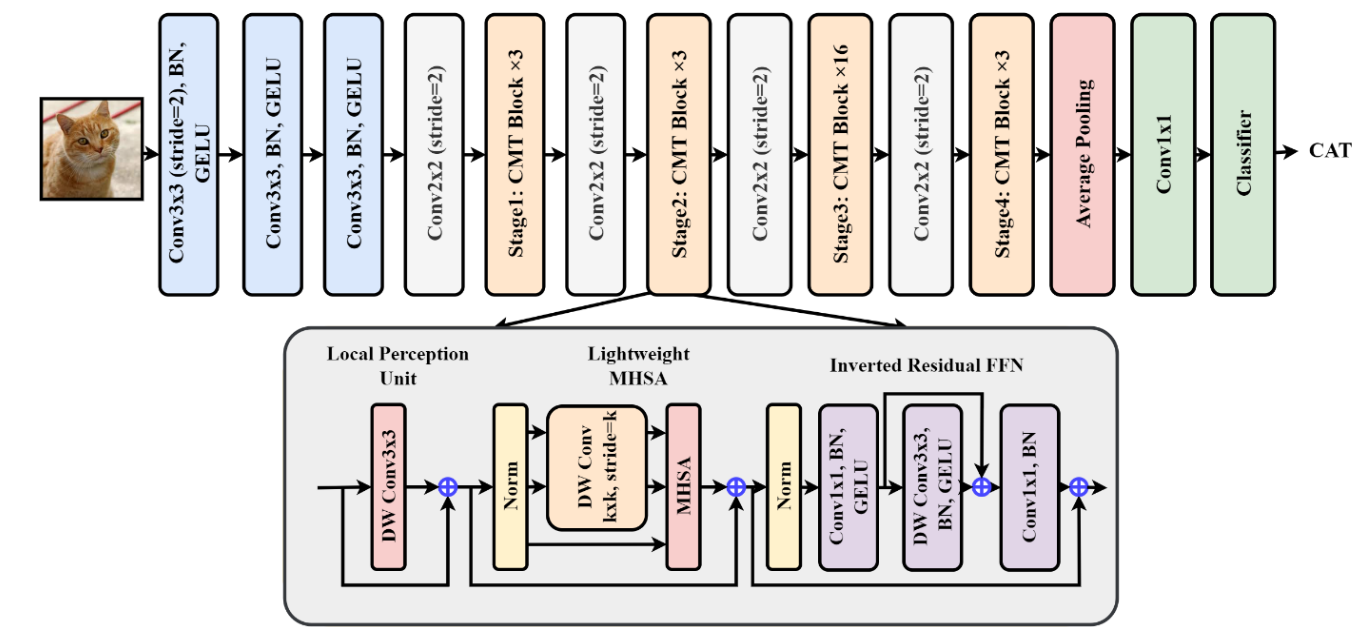
图 12:CMT 架构,按顺序集成 CNN - Bottleneck Transformers (BoTNet)
由于卷积层捕获的是图像中许多结构元素的主要构建块的低级特征,Srinivas 等人引入了混合 ViT、BoTNet(视觉识别瓶颈变换器),以从 CNN 和 ViT 中受益(Srinivas等人,2021)。 BoTNet 的架构只是 ResNet 块的顺序组合,其中注意力机制被合并在最后三个块中。 ResNet 块包含两个 1x1 卷积和一个 3x3 卷积。添加 MSA 来代替 3x3 卷积,以捕获除局部特征之外的长期依赖性。
3.6.4. Parallel integration
此类别包括并行使用 CNN 和 Transformer 架构的 HVT 架构,然后最终组合它们的预测(Wang 等人,2021a)。
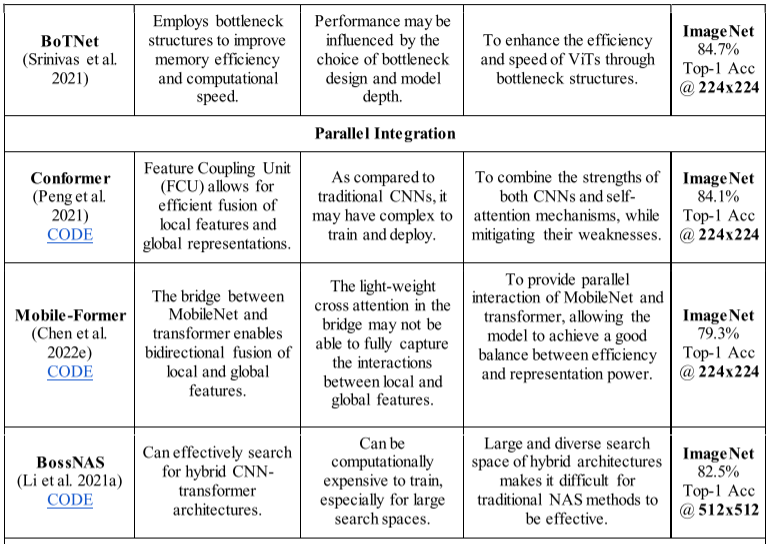
- Convolution-augmented Transformer (Conformer)
2021 年,Peng 等人。进行了一项在自然图像中进行视觉识别的研究。对此,他们提出了一种名为 Conformer 的架构(Peng et al. 2021)。由于 ViT 的流行,Conformer 的架构也是基于 ViT 的。为了提高网络的感知能力,他们整合了 CNN 的优点和多头自注意力机制。 Conformer 是一种混合 ViT,包含两个独立的分支,一个用于捕获局部感知的 CNN 分支和一个用于捕获全局级特征的 Transformer 分支。随后建立了从 CNN 分支到 Transformer 分支的连接,以使每个分支具有本地全局上下文感知能力。最终预测是通过 CNN 分类器和 Transformer 分类器获得的。使用交叉熵损失函数来训练每个分类器。 Conformer 表现出比其他表现优异的 ViT 架构(例如 DeiT 和 VIT)更好的性能。 - MobileNet-based Transformer (Mobile-Former)
陈等人。提出了一种并发混合 ViT 架构,具有 CNN 和 Transformer 的两种不同路径(Chen 等人,2022e)。与其他混合 ViT 一样,Mobile-Former 采用 CNN 模型来学习空间相关性,并使用转换器来捕获图像中的长期依赖性,从而融合局部相关性和全局表示。 CNN 架构基于 MobileNet,它使用参数数量减少的反向残差块。两个分支之间的信息通过连接进行同步,这使得 CNN 路径能够了解全局信息,而 Transformer 能够了解本地信息。然后将两个分支的连接输出和池化层一起馈送到双层分类器以进行最终预测。图 13 显示了它们的详细架构。
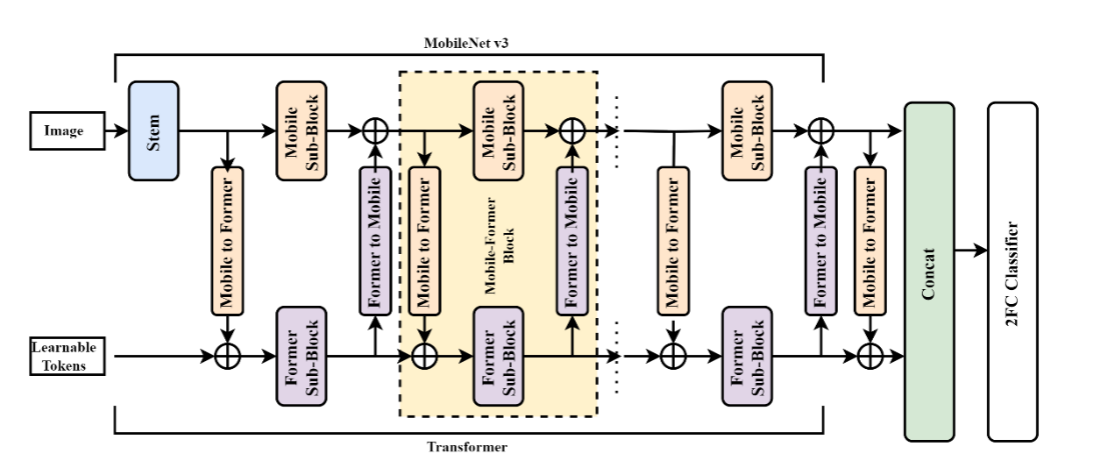
图 13:Mobile-former 的架构(CNN 和 Transformer 并行集成) - Block-wisely Self-supervised Neural Architecture Search (BossNAS)
李等人。开发了一个搜索空间(HyTra)来评估混合架构,并建议每个块应该单独训练(Li et al. 2021a)。在 HyTra 搜索空间的每一层中,他们都以并行和可自由选择的形式使用具有各种分辨率的 CNN 和 Transformer 块。这个广泛的搜索领域包括空间尺度逐渐变小的传统 CNN 和具有固定内容长度的纯 Transformer。
3.6.5. Hierarchical integration
那些采用分层设计的 HVT 架构(类似于 CNN)就属于这一类。其中许多模型都设计了一个统一的模块来集成 CNN 和 ViT,然后在整个架构中重复使用(Tu et al. 2022b)。
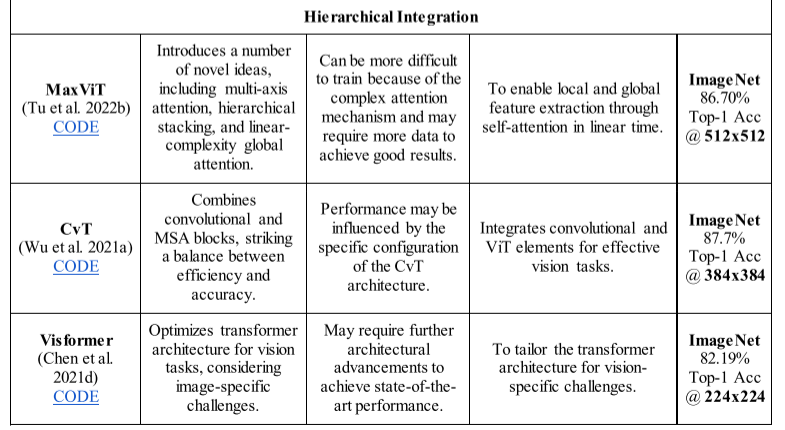
- Multi-Axis Attention-based Vision Transformer (MaxViT)
MaxViT 是 ViT 架构的一个变体,由 Tu 等人在其论文“Mult iAxis Attention Based Vision Transformer”(Tu 等人,2022b)中介绍。它引入了由阻塞局部注意力和扩展全局注意力组成的多轴注意力机制。与以前的架构相比,它被证明是一种高效且可扩展的注意力机制。引入了一个新的混合块作为基本元素,它由基于 MBConv 的卷积和基于多轴的注意力组成。基本混合块在多个阶段重复,以获得分层主干,类似于可用于分类、对象检测、分割和生成建模的基于 CNN 的主干。 MaxViT 可以看到整个网络的本地和全局情况,包括早期阶段。 - Convolutional Vision Transformer (CvT)
CvT 由 Wu 等人提出。 2021 年(Wu 等人,2021a)。 CvT 的架构包含几个像 CNN 一样的阶段,构成了一个分层框架。他们以两种方式在架构中添加了卷积。首先,他们使用卷积令牌嵌入来提取令牌序列,这不仅结合了网络中的局部性,而且逐渐缩短了序列长度。其次,他们提出了一种卷积投影,使用深度可分离卷积来代替编码器块中每个自注意力块之前的线性投影。 CvT 的性能优于其他图像识别方法。 - Vision-Friendly Transformer (Visformer)
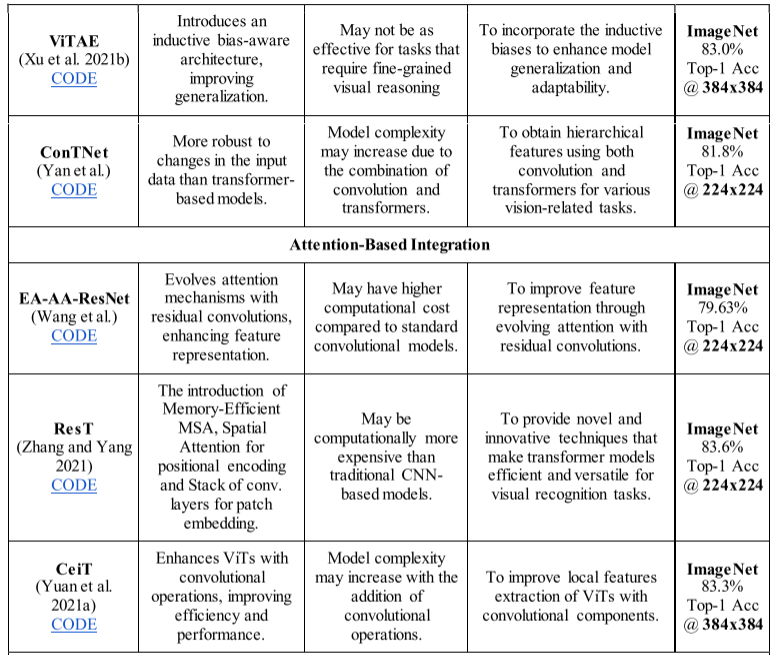
Visformer 于 2020 年作为视觉友好型变压器推出(Chen 等人,2021d),呈现出实现高效性能的模块化设计。该架构对传统 ViT 网络进行了多项修改。在 Visformer 中,采用全局平均池化代替分类标记,并将层归一化替换为批量归一化。此外,他们在每个阶段利用受 ResNeXt(Xie 等人)启发的卷积块代替自注意力来有效捕获空间和局部特征。然而,为了对全局依赖关系进行建模,他们在最后两个阶段采用了自我关注。 Visformer 架构的另一个显着修改是在 MLP 块中添加了 3x3 卷积。 - Vision Transformer Advanced by Exploring intrinsic Inductive Bias (ViTAE)
作者提出了一种称为 ViTAE 的新型 ViT 架构,它结合了两种不同的基本细胞类型(如图 14 所示):还原细胞 (RC) 和正常细胞 (NC) (Xu et al. 2021b)。 RC 用于缩小输入图像并将其嵌入到丰富的多尺度上下文令牌中,而 NC 用于在令牌序列内同时对本地和长期依赖关系进行建模。这两类单元的底层结构也相似,由并行注意力模块、卷积层和 FFN 组成。 RC 通过在金字塔缩减模块中利用多个具有不同膨胀率的卷积,将上下文信息包含在标记中。作者还提出了一个更优化的版本 ViTAEv2,它显示出比早期方法更好的性能(Zhang 等人,2022d)。
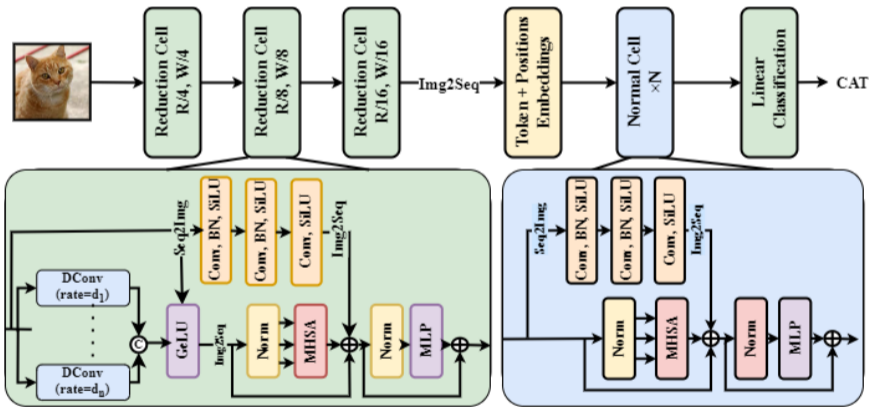
Figure 14: Architectural diagram of ViTaE - Convolution-Transformer Network (ConTNet)
为计算机视觉任务提出了一种新颖的卷积变换网络(ConTNet),以解决该领域面临的挑战。 ConTNet是通过堆叠多个ConT块来实现的(Yan等人)(如图15所示)。 ConT 块将标准变换器编码器 (STE) 视为类似于卷积层的独立组件。具体来说,特征图被分成几个大小相等的块,每个块被展平为一个(超)像素序列,然后输入到 STE。重塑补丁嵌入后,生成的特征图将传递到下一个卷积层或 STE 模块。
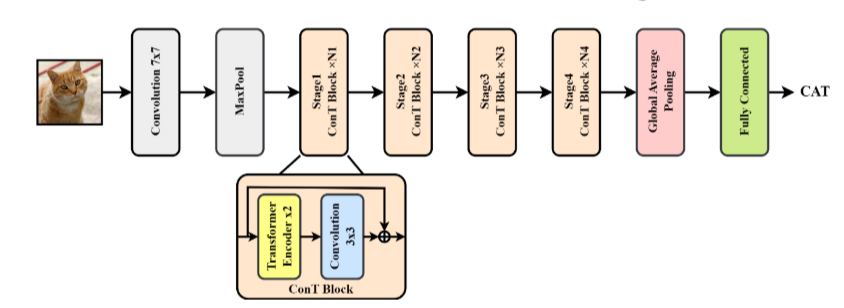
图 15:ConTNet 的架构,它将 CNN 和 ViT 集成在其 ConT 块中,形成分层架构。
3.6.6. Attention-based integration
本节讨论那些 HVT 架构,它们在注意力机制中利用 CNN 来合并局部性。
- Evolving Attention with Residual Convolutions (EA-AA-ResNet)
由于独立自注意力层在捕获令牌之间的底层依赖关系方面的通用性有限,Wang 等人。通过添加卷积模块扩展了注意力机制(Wang 等人)。具体来说,他们采用了带有残差连接的卷积单元,通过利用从先前层继承的知识来概括每一层中的注意力图,称为进化注意力(EA)。所提出的 EA-AA-ResNet 架构通过桥接不同层的注意力图并使用卷积模块学习一般的注意力模式来扩展注意力机制。 - ResNet Transformer (ResT)
一种混合架构,将卷积运算集成到其注意力机制中,使其能够有效捕获全局和局部特征(Zhang 和 Yang 2021)。作者在其架构中使用了一种新的高效变压器模块,用其高效变体取代了传统的 MSA 模块。在所提出的高效多头自注意力中,他们在计算注意力函数之前采用深度卷积来减少输入标记图的空间维度。 - Convolution-Enhanced Image Transformer (CeiT)
CeiT是由Yuan等人提出的。 2021 年,他们的论文“将卷积设计融入视觉转换器”(Yuan 等人,2021a)。所提出的 CeiT 结合了 CNN 和 ViT 在提取低级特征、捕获局部性和学习远程依赖性方面的优点。在他们的 CeiT 中,他们在传统 ViT 架构中取得了三项主要进展。他们修改了补丁提取方案、MLP 层,并在 ViT 架构之上添加了最后一层。对于补丁提取,他们提出了图像到令牌 (I2T) 模块,其中利用基于 CNN 的块来处理输入。他们没有利用原始输入图像,而是使用从初始卷积块中学到的低级特征来提取补丁。 I2T 在其架构中包含卷积层、最大池化层和批量归一化层,以充分利用 ViT 中 CNN 的优势。他们利用局部增强前馈 (LeFF) 层代替 ViT 编码器中的传统 MLP 层,其中利用深度卷积来捕获更多空间相关性。此外,还设计了最后一类令牌注意(LCA)层来系统地组合 ViT 不同层的输出。 CeiT 不仅在多个图像和场景识别数据集(包括 ImageNet、CIFAR 和 Oxford-102)上显示出有希望的结果,而且与 ViT 相比,计算效率也很高。
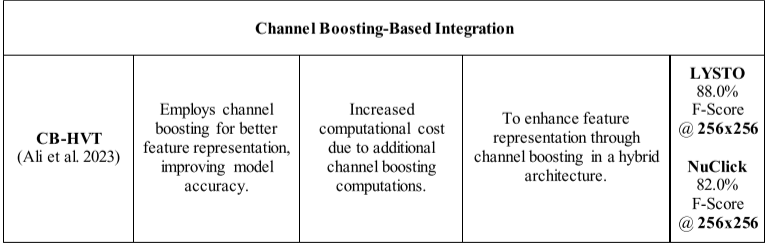
3.6.7. Channel boosting-based integration
通道增强(CB)是深度学习中用于提高 CNN 模型的表示学习能力的一个想法。在 CB 中,除了原始通道之外,还使用基于迁移学习的辅助学习器生成增强通道,以从图像中捕获多样化且复杂的模式。基于 CB 的 CNN(CB-CNN)在各种视觉相关任务中表现出了出色的性能。在 Ali 等人的一项研究中,他们提出了一种基于 CB 的 HVT 架构(Ali 等人,2023)。在 CB-HVT 中,他们利用 CNN 和基于 ViT 的辅助学习器来生成增强通道。基于 CNN 的通道捕获图像模式中局部级别的多样性,而基于 Pyramid Vision Transformer (PVT) 的通道则学习全局级别的上下文信息。作者在淋巴细胞评估数据集上评估了 CBHVT,显示出合理的性能。其架构概述如图 16 所示。
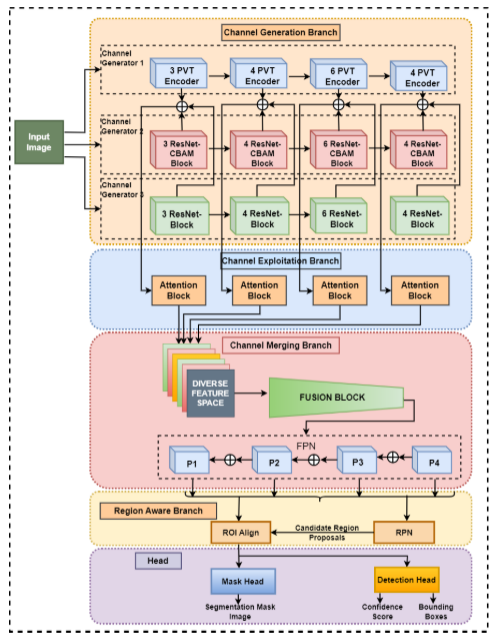
图 16:CB-HVT 概述,其中 PVT(VIT)使用通道增强结合在 CNN 架构中。
3.7. Empirical comparison of different methods
在本节中,我们对几种 ViT 和 HVT 架构进行了简短而全面的实证比较,这些架构在各种计算机视觉任务中表现出了卓越的性能。为了深入了解它们的优点和缺点,我们在表 3 和表 4 中提供了详细的概述。此外,我们还根据其分类强调了每个模型中所做的主要修改以及基本原理。
表 3:根据各种 ViT 架构的优点、缺点、基本原理和基准数据集上的性能对各种 ViT 架构进行实证比较(为了进行比较,我们报告了上述架构的最佳性能变体的结果)。
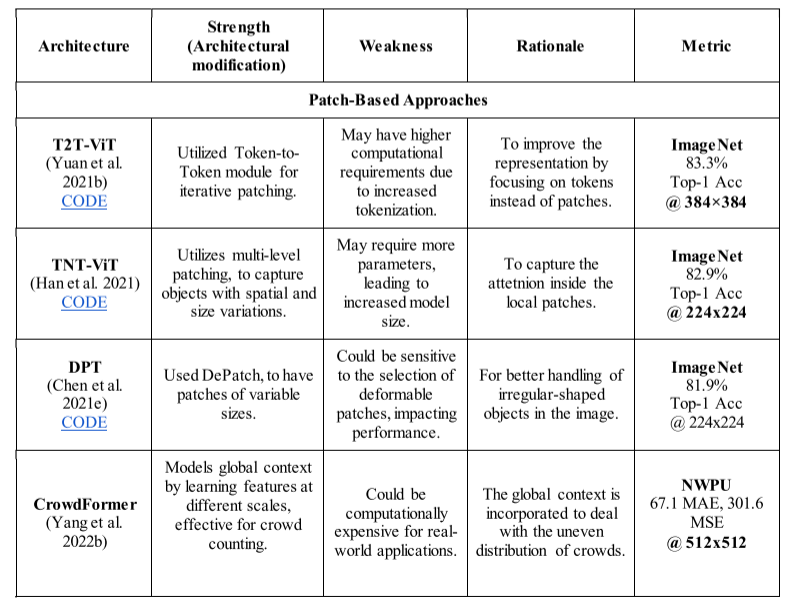
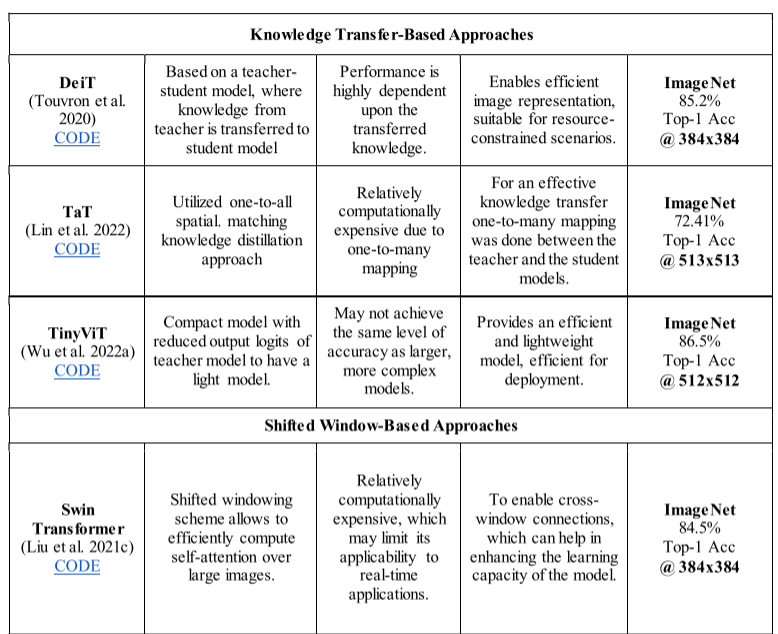
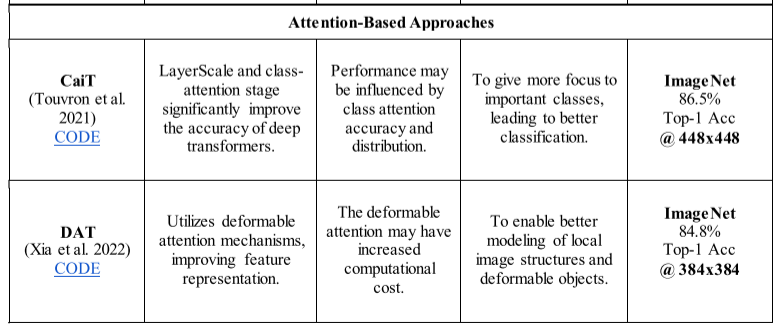
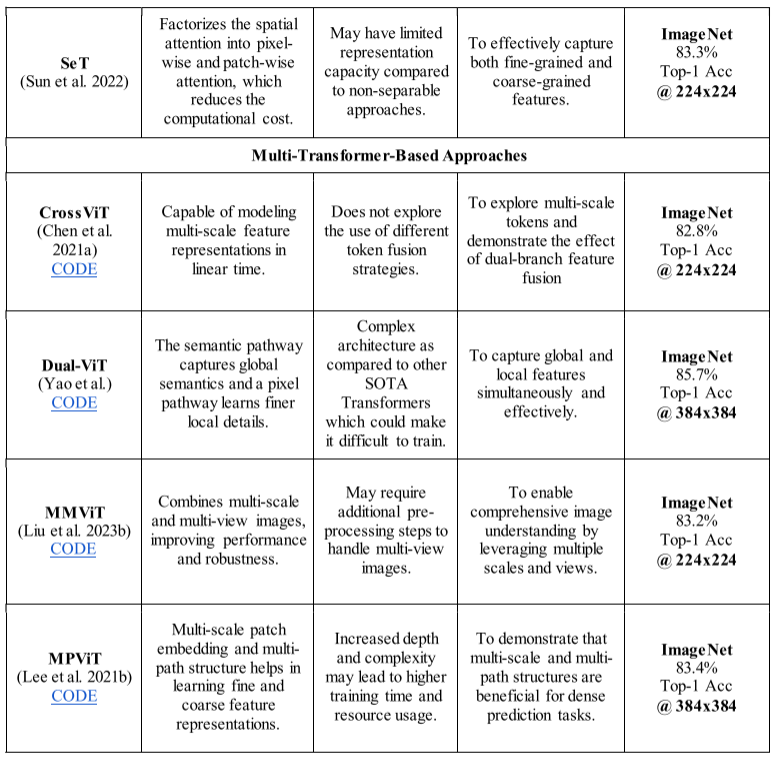
表 4:几种 HVT 架构的实证比较,基于其优点、缺点、基本原理和基准数据集上的性能(为了进行比较,我们报告了上述架构的最佳性能变体的结果)


4、Applications of HVTs
近年来,HVT 在一系列基于视觉的应用中变得越来越普遍(Deng et al. 2023;Xue and Ma 2023;Yan et al. 2023;Cheng et al. 2023;Lian et al. 2023;Chen et al. al. 2023d;Liu et al. 2023a;Ye et al. 2023a),包括图像和视频识别(Zhang 和Zhang 2022;Chen et al. 2023a;Xia et al. 2023;Mogan et al. 2023;Liang et al. . 2023),目标检测(Dehghani-Dehcheshmeh et al. 2023;Huang et al. 2023a;Yu and Zhou 2023),分割(Chen et al. 2021b;Li et al. 2023e;Quan et al. 2023),图像恢复(Zhou et al. 2023a)和医学图像分析(Gao et al. 2021;An et al. 2022;Chen et al. 2022a;Song et al. 2022a;Zhang et al. 2022b;Yang and Yang 2023;Nafisah et al.) al. 2023;Wu 等人,2023c)。 CNN 和基于 Transformer 的模块相结合创建了 HVT,这是一种可以解释复杂视觉模式的有效方法(Li et al. 2023a)。下面讨论 HVT 的一些值得注意的应用。
4.1. Image/video recognition
CNN 因其能够从视觉数据中自动提取复杂信息而被广泛用于图像和视频处理(Fan et al. 2016; Fang et al. 2018; Yao et al. 2019; Kaur et al. 2022; Rafiq et al. .2023)。尽管如此,ViT 在图像和视频识别等各种具有挑战性的任务上取得了出色的性能,彻底改变了计算机视觉领域(Chen 和 Ho 2022;Jing 和 Wang 2022;Chen 等人 2022b;Wensel 等人 2022;Ulhaq 等人) . 2022;Chen 等人,2022c)。 ViT 的成功可以归因于它们的自我关注机制,这使它们能够捕获图像中的远程依赖性(Ji et al. 2023)。近年来,HVT 越来越受欢迎,因为它们结合了 CNN 和 Transformer 的功能(Zhang 等人,2022a;Li 等人,2023g;Ma 等人,2023a)。人们基于 HVT 提出了各种用于图像和视频识别的方法 (Jiang et al. 2019; Li et al. 2021b; Huang et al. 2021a; GE et al. 2021; Yang et al. 2022a; Leong et al. 2021)。 2022;Zhao 等人,2022a;Raghavendra 等人,2023;Zhu 等人,2023b)。熊等人。提出了一种基于 ViT 和 CNN 的混合多模态方法来增强细粒度 3D 对象识别(Xiong 和 Kasaei 2022)。他们的方法使用 ViT 网络对对象的全局信息进行编码,并使用 CNN 网络通过对象的 RGB 和深度视图对对象的局部表示进行编码。他们的技术优于仅 CNN 和仅 ViT 的基线。在另一种技术中,Tiong 等人。提出了一种新型混合注意力视觉变换器(HA-ViT)来进行面部眼周交叉识别(Tiong et al. 2023)。 HA-ViT 在其混合注意力模块中并行利用深度卷积和基于卷积的 MSA 来集成局部和全局特征。所提出的方法在人脸眼周交叉识别(FPCI)准确性方面优于三个基准数据集。王等人。提出了一种使用基于 HVT 的架构进行视觉位置识别的新颖方法(Wang 等人,2022d)。他们的方法旨在通过结合 CNN 和 ViT 来捕获局部细节、空间上下文和高级语义信息,从而提高视觉位置识别系统的鲁棒性。识别车辆 Shi 等人。开发了一种融合网络,该网络使用 SE-CNN 架构进行特征提取,然后使用 ViT 架构捕获全局上下文信息(Shi et al. 2023)。他们提出的方法证明了道路识别任务的良好准确性。
4.2. Image generation
图像生成是计算机视觉中一项有趣的任务,可以作为许多下游任务的基线(Frolov 等人,2021)。生成对抗网络(GAN)广泛用于各个领域的图像生成(Arjovsky 等人,2017 年;Karras 等人,2019 年)。此外,基于 Transformer 的 GAN 在这项任务中表现出了良好的性能(Lee 等人,2021a;Naveen 等人,2021;Rao 等人,2022;Gao 等人,2022b)。最近,研究人员还利用了基于 HVT 的 GAN,并在各种基准数据集上展示了出色的性能(Tu et al. 2022a;Lyu et al. 2023)。托尔布诺夫等人。报道了 UVCGAN,一种用于图像生成的混合 GAN 模型(Torbunov 等人,2022)。 UVCGAN 模型的架构基于原始 CycleGAN 模型(Zhu et al. 2017)并进行了一些修改。UVCGAN 的生成器是基于 UNet(Weng 和 Zhu,2015)和 ViT 瓶颈(Devlin 等人,2018)的混合架构。实验结果表明,与早期性能最佳的模型相比,其性能优越,同时保留了原始图像和生成图像之间的强相关性。在另一项工作中,Zhao 等人引入了 SwingGAN 用于 MRI 重建(Zhao et al. 2023)。他们利用了基于 Swin Transformer U-Net 的生成器网络和基于 CNN 的判别器网络。 SwingGAN 生成的 MRI 图像由于能够捕获更有效的信息而显示出良好的重建质量。图等人。在他们提出的 SWCGAN 中结合了 Swin Transformer 和 CNN 层(Tu et al. 2022a)。在他们的架构中,他们最初利用 CNN 层来捕获局部级特征,然后在后续层中利用残差密集 Swin 变压器块“RDST”来捕获全局级特征。与现有的遥感图像方法相比,所开发的方法显示出良好的重建性能。最近,鲍等人。提出了一种空间注意力引导的 CNN-Transformer 聚合网络(SCTANet)来重建面部图像(Bao 等人,2023b)。他们在混合注意力聚合 (HAA) 模块中同时使用 CNN 和 Transformer 来进行深度特征提取。他们的实验结果表明比其他技术有更好的性能。郑等人。在他们的方法中提出了一种基于 HVT 的 GAN 网络,用于医学图像生成(Zheng et al. 2023)。在他们的名为 L-former 的方法中,他们在浅层使用 Transformer,在深层使用 CNN。与传统的 GAN 架构相比,他们的方法表现出了优异的性能。
4.3. Image segmentation
尽管 CNN 和基于 ViT 的方法在图像分割等复杂的图像相关任务中表现出了卓越的性能,但目前的重点是结合这两种方法的优势来实现性能的提升(Dolz 等人,2019 年;Wang 等人,2020 年) ,2022c,b;Jing 等人,2023;Shafri 等人,2023;Yang 等人,2023b)。对此,王等人。提出了一种新的语义分割方法,称为 DualSeg,用于葡萄分割(Wang et al. 2023a)。他们的方法结合了 Swin Transformer 和 CNN,利用了全局和局部特征的优势。在另一项工作中,Zhou 和合著者提出了一种名为 SCDeepLab 的混合方法来分割隧道裂缝(Zhou 等人,2023b)。他们的方法在隧道衬砌裂缝分割方面优于其他仅基于 CNN 和仅基于 Transformer 的模型。冯等人。在金属耦合器中进行分割识别以检测断裂表面(Feng et al. 2023)。为此,他们提出了一种基于端到端 HVT 的方法,利用 CNN 进行自动特征提取,并使用混合卷积和变换器 (HCT) 模块进行特征融合和全局建模。最近,Xia 和 Kim 开发了 Mask2Former,一种 HVT 方法,以解决基于 ViT 或 CNN 的系统的局限性(Xia 和 Kim 2023)。与 ADE20K 和 Cityscapes 数据集上的其他技术相比,所开发的方法取得了更好的结果。李等人。提出了一种基于 HVT 的方法,称为 MCAFNet,用于遥感图像的语义分割(Li et al. 2023d)。
4.4. Image Restoration
计算机视觉中的一项关键任务是图像恢复,它往往会从损坏的版本中恢复原始图像。基于图像恢复的系统已从使用 CNN 转向使用 ViT 模型(Song 等人,2023),最近又转向使用结合了 CNN 和 Transformer 优势的 HVT(Gao 等人,2022a;Wu 等人,2023c) 。易等人。提出了一种基于自动编码器的混合方法来进行单红外图像盲去模糊(Yi et al. 2023)。他们的方法利用混合卷积变换器块来提取对象与其背景之间的上下文相关信息。为了加速训练过程的收敛并实现卓越的图像去模糊结果,该研究还采用了多阶段训练技术和混合误差函数。在另一种技术中,陈等人。开发了一种称为 Dual-former 的高效图像恢复架构,它结合了卷积的局部建模能力和自注意力模块的全局建模能力(Chen 等人,2022d)。所提出的架构在多个图像恢复任务上实现了卓越的性能,同时比以前提出的方法消耗的 GFLOP 显着减少。为了解决高计算复杂度的问题 Fang 等人。利用混合网络 HNCT 来实现轻量级图像超分辨率(Fang 等人,2022)。HNCT 利用 CNN 和 ViT 的优点,提取考虑局部和非局部先验的特征,从而产生轻量级但有效的超分辨率模型。实验结果表明,与参数较少的现有方法相比,HNCT 的结果有所改善。赵等人。开发了一种混合去噪模型,称为变压器编码器和卷积解码器网络(TECDNet),用于高效且有效的真实图像去噪(Zhao et al. 2022b)。 TECDNet 取得了出色的去噪效果,同时保持了相对较低的计算成本。最近,陈等人。提出了一种用于红外和可见光图像融合的基于端到端 HVT 的图像融合方法(Chen 等人,2023b)。该技术由一个具有两个分支的 CNN 模块组成,用于提取粗略特征,以及一个 ViT 模块,用于获取图像中的全局和空间关系。他们的方法能够关注全局信息并克服基于 CNN 的方法的缺陷。此外,为了保留纹理和空间信息,设计了专门的损失函数。
4.5. Feature extraction
特征提取在计算机视觉中对于从图像中识别和提取相关视觉信息至关重要。最初 CNN 用于此目的,但现在 Transformer 因其在图像分类以及姿势估计和人脸识别等其他应用中令人印象深刻的结果而受到关注(Wang 等人,2023d;Zhu 等人,2023a;Su 等人) .2023)。 Li 和 Li 在他们的工作中提出了一种混合方法 ConVit,该方法融合了 CNN 和 Transformer 的优势,可有效提取特征来识别农作物病害(Li 和 Li 2022)。所开发方法的实验结果在植物病害识别任务中表现出良好的性能。 Li等人提出了一种级联方法。用于重新捕获的场景图像识别(Li et al. 2023b)。在他们的方法中,他们最初使用 CNN 层来提取局部特征,后来在更深的层中,他们使用 Transformer 块来学习全局级图像表示。他们提出的方法的高精度证明了其在识别重新捕获的图像方面的有效性。 Li 和合著者开发了 HVT 架构来检测带钢表面的缺陷。他们的方法利用了 CNN 模块,然后是补丁嵌入块和两个转换器块来提取高域相关特征。与现有方法相比,他们的实验显示出良好的分类性能。最近,拉贾尼等人。在他们的方法中,提出了一种编码器-解码器方法来对不同海底类型进行分类。他们开发的方法是基于 ViT 的架构,其 MLP 块被基于 CNN 的特征提取模块取代。修改后的架构在满足实时计算要求的同时取得了出色的结果。
4.6. Medical image analysis
基于 CNN 的方法由于能够捕获多样化且复杂的模式而经常用于分析医学图像(Zafar 等人,2021 年;Sohail 等人,2021b;Rauf 等人,2023 年)。然而,由于需要对全局级图像表示进行建模,研究人员受到启发,在医学图像分析领域使用 Transformer(Obeid 等人,2022;Cao 等人,2023;Zou 和 Wu,2023;Li 等人,2023c; Zidan 等人,2023;Xiao 等人,2023)。最近,一些研究提出集成 CNN 和 Transformer 以捕获医学图像中的局部和全局图像特征,从而进行更全面的分析(Tragakis 等人;Springenberg 等人 2022;Wu 等人 2022c;Jiang 和 Li 2022; Bao 等人,2023a;Dhamija 等人,2023;Huang 等人,2023b;Wu 等人,2023a;Ke 等人,2023;Yuan 等人,2023a)。这些混合架构(CNN-transformer)在许多医学图像相关应用中表现出了巨大的性能(Zhang et al. 2021c;Shen et al. 2022;Rehman and Khan 2023;Li et al. 2023f;Wang et al. 2023b) 。特拉加基斯等人。提出了一种新颖的全卷积变换器(FCT)方法来分割医学图像(Tragakis 等人)。 FCT 在其架构中采用了 ViT 和 CNN,将 CNN 学习有效图像表示的能力与 Transformer 捕获长期依赖关系的能力结合起来。与其他现有架构相比,开发的方法在各种医疗挑战数据集上表现出了出色的性能。在另一部作品中,Heidari 等人。提出了 HiFormer,这是一种利用 Swin Transformer 模块和基于 CNN 的编码器捕获多尺度特征表示的 HVT(Heidari 等人,2022)。实验结果证明了 HiFormer 在各种基准数据集中分割医学图像的有效性。在他们的论文中,Yang 和同事提出了一种名为 TSEDeepLab 的新型混合方法,它将卷积运算与转换器块相结合来分析医学图像(Yang 等人,2023a)。具体来说,该方法在早期阶段利用卷积层来学习局部特征,然后由转换器块处理以提取全局模式。他们的方法在多个医学图像分割数据集上展示了卓越的分割精度和强大的泛化性能。
4.7. Object Detection
目标检测是一项至关重要的计算机视觉任务,具有广泛的现实应用,例如监控、机器人、人群计数和自动驾驶(Liu et al. 2023a)。多年来,深度学习的进步极大地促进了物体检测的进步(Er et al. 2023)。 ViT 在对象检测方面也表现出了令人印象深刻的性能,因为它的自注意力机制使它们能够捕获图像像素之间的远程依赖关系并识别整个图像中的复杂对象模式(Carion 等人,2020 年;Chen 等人,2021c;Wang 和Tien 2023;Heo 等人 2023)。最近,人们对将 CNN 与自注意力机制相结合以提高目标检测性能的 HVT 产生了很大的兴趣(Jin 等人,2021;Maaz 等人,2022;Mathian 等人,2022;Ye 等人,2023b;Zhang等人,2023b;Lu 等人,2023a;Ullah 等人,2023)。比尔等人。提出了一种名为 ViT-FRCNN 的 HVT 方法,用于自然图像中的目标检测。在他们的方法中,他们利用基于 ViT 的骨干网来实现 Faster RCNN 目标检测器。 ViT-FRCNN 显示出改进的检测结果和更好的泛化能力(Beal et al. 2020)。陈等人。推出了用于遥感图像检测的单级混合探测器。他们提出的方法 MDCT 在其架构中利用了 CNN 和 Transformer,并且与其他单级检测器相比表现出了更好的性能(Chen 等人,2023c)。卢等人。开发了一种基于 HVT 的方法,用于无人机 (UAV) 图像中的目标检测(Lu 等人,2023b)。所提出的方法利用基于 Transformer 的主干来提取具有全局级别信息的特征,然后将其馈送到 FPN 进行多尺度特征学习。与早期的方法相比,所提出的方法表现出良好的性能。 Yao 和他的同事提出了一种融合网络,利用单独的 Transformer 和基于 CNN 的分支来学习全局和局部级别的特征(Yao et al. 2023)。实验结果表明,与其他方法相比,所开发的方法具有令人满意的性能。
4.8. Pose Estimation
人体姿态估计倾向于识别各种场景中的重要点。 CNN 和 Transformer 在姿态估计任务中都表现出了出色的性能(Sun et al. 2019;Huang et al. 2019;Cao et al. 2022)。目前,研究人员致力于将 CNN 和 Transformer 结合到一个统一的方法中,以合并局部和全局级别的信息,以实现准确的姿态估计(Stoffl et al. 2021;Mao et al. 2021;Li et al. 2021d;Wu et al. 2022b) 。赵等人。提出了一种用于人体姿态估计的新型双管道集成变压器“DPIT”(Zhao 等人,2022c)。在Zhao的方法中,最初采用两个基于CNN的分支来提取局部特征,然后使用变压器编码器块来捕获图像中的长距离依赖性(Wang等人,2022a)。在另一种技术中,Wang 和合著者使用 CNN 和 Transformer 分支来学习局部和全局图像表示,然后将其集成以生成最终输出。与其他现有方法相比,他们的方法显示出显着的改进。 Hampali 和合著者开发了一种混合姿态估计方法,称为 Keypoint Transformer(Hampali 等人,2021)。在所提出的方法中,他们利用 CNN 和基于 Transformer 的模块来有效地将人体关节估计为 2D 关键点。实验结果显示了该方法在包括 InterHand2.6M 在内的数据集上的示范性结果。
5. Challenges
HVT 不仅在计算机视觉领域而且在其他各个领域都表现出了卓越的性能。尽管如此,将卷积运算有效地集成到变压器架构中给 HVT 带来了一些挑战。其中一些挑战包括:
- Transformer 中的 MSA 机制和 CNN 中的卷积运算都依赖于密集矩阵乘法来捕获数据依赖性。然而,HVT 架构(CNN-Transformers)可能面临高计算复杂度和内存开销。因此,他们在尝试对体积分析和分割等密集应用程序进行建模时可能会遇到挑战。
- 由于计算复杂性,训练 HVT 需要 GPU 等强大的硬件资源。由于硬件限制和相关成本,这可能会限制它们在现实应用程序中的部署,尤其是在边缘设备上。
- HVT 架构面临的主要挑战是有效合并来自转换器层和卷积层的学习特征。变换器层学习与空间位置无关的全局特征,而卷积层学习空间相关的局部特征。从架构角度来看,MSA 和 CNN 层的有效统一可能会提高各种视觉任务的性能。
- HVT 因其高学习能力而能够准确处理复杂的图像数据。然而,这也意味着它们需要大量的训练数据集来有效地学习和概括数据。这带来了挑战,特别是在医学图像领域,获取大量带注释的数据通常是困难且耗时的。获取大量标记数据的需求可能是一个重大障碍,消耗宝贵的资源和时间,并阻碍 HVT 在医学成像中的开发和应用。
6. 未来的方向
HVT 是具有数十亿参数的大型模型,因此需要轻量级架构。它们的高复杂性可能会导致推理延迟和显着的能耗开销。需要探索新的创新设计原理,以实现具有显着推理率的高效 HVT,以使其能够在现实应用、边缘设备和计算有限的系统(例如卫星)中实际部署。通过将知识从大容量模型转移到更简单的模型,知识蒸馏成为生成数据高效且紧凑的模型的一种有前途的方法。
HVT 结合了 CNN 和 Transformer 的优势,在图像分析和计算机视觉方面取得了重大进步。然而,为了充分利用它们的潜力,重要的是探索将卷积和自注意力机制集成到特定视觉应用的合适方法。这涉及到基于集成方法对各种环境的适用性进行深入分析,例如早期层集成、横向层集成、顺序集成、并行集成、分层集成、基于注意力的集成和基于注意力的集成。
HVT 的本地和全局处理能力使其在广泛的视觉应用中非常有前景,其潜在优势超出了与视觉相关的任务。为了进一步提高 HVT 的性能,更深入地了解图像内容和相关操作非常重要,这有助于设计更好的混合和深度架构。在不久的将来,对手工制作的算子与 CNN-Transformer 架构的混合和动态特征提取机制相结合的潜在利用的研究可能会特别重要。使用卷积和自注意力机制开发新的有效块也是一个有前途的研究领域。
综上所述,HVT 的未来看起来很光明,在图像分析、计算机视觉等领域的各种应用中具有巨大的潜力。我们认为,最好也关注融合自注意力和卷积层的可能集成方法在用于特定视觉任务的 HVT 架构中。这一重点还应该扩展到理解图像内容和操作,开发结合卷积和自注意力的有效模块,利用 ViT 和 HVT 架构中的多模态和多任务处理。
7. Conclusion
ViT 由于其在特定图像相关任务中的良好表现而在研究中获得了广泛关注。这一成功归功于集成到 ViT 架构中的 MSA 模块,支持对图像内的全局交互进行建模。为了增强其性能,引入了各种架构改进。这些改进可以分为基于补丁、基于知识蒸馏、基于注意力、基于多变压器和混合方法。本文不仅研究了 ViT 的架构分类,还探讨了 ViT 架构背后的基本概念。
虽然 ViT 具有令人印象深刻的学习能力,但由于缺乏可以捕获图像中局部关系的归纳偏差,它们在某些应用中可能会受到有限的泛化能力。为了解决这个问题,研究人员开发了 HVT,也称为 CNN-Transformers,它利用自注意力和卷积机制来学习局部和全局信息。
一些研究提出了将卷积特定感应偏置集成到变压器中的方法,以提高其泛化性和容量。集成方法包括早期层集成、横向层集成、顺序集成、并行集成、分层集成和基于通道增强的集成。除了根据集成方法介绍 HVT 架构的分类之外,我们还概述了它们如何在各种现实世界的计算机视觉应用中使用。尽管面临当前的挑战,我们相信 HVT 具有巨大的潜力,因为它们有能力在本地和全球层面进行学习。