C++: string的模拟实现
- 一.前置说明
- 1.模拟实现string容器的目的
- 2.我们要实现的大致框架
- 二.默认成员函数
- 1.构造函数
- 2.拷贝构造函数
- 1.传统写法
- 2.现代写法
- 3.析构函数
- 4.赋值运算符重载
- 1.传统写法
- 2.现代写法
- 三.遍历和访问
- 1.operator[]运算符重载
- 2.iterator迭代器
- 四.容量相关函数
- 1.size,capacity
- 2.reserve
- 3.resize
- 五.尾插
- 1.push_back
- 2.append
- 3.operator+=运算符重载
- 六.指定位置插入删除
- 1.insert
- 1.插入一个字符的版本
- 2. 插入一个字符串的版本
- 2.erase
- 七.查找,交换,截取操作
- 1.find
- 2.swap
- 3.substr
- 八.几个小函数
- 1.c_str
- 2.clear
- 3.empty
- 九.流插入和流提取
- 1.<<流插入
- 2.>>流提取
- 十.完整代码
- 1.my_string.h:
- 2.my_string.cpp
- 3.test.cpp
一.前置说明
注意:本文会用到strcpy,strstr,strncpy,strlen这几个函数
我会说明它们的功能和用法
如果大家想要彻底了解这几个函数
可以看一下我之前的博客:
征服C语言字符串函数(超详细讲解,干货满满)
1.模拟实现string容器的目的

比如说leetcode字符串相加这道题



既然string的模拟实现对我们这么重要
那就让我们一起踏上string的模拟实现之旅吧
2.我们要实现的大致框架
我们经过string容器的使用的学习之后
我们知道string容器其实就是一个顺序表,只不过这个顺序表里面存储的都是char类型的数据
而且末尾有一个隐含的’\0’
因此我们的string容器可以这样定义
#define _CRT_SECURE_NO_WARNINGS 1
#pragma once
#include <iostream>
using namespace std;
#include <assert.h>
namespace wzs
{
class string
{
public:
//npos
static size_t npos;
private:
char* _str;//这就是string容器中的那个字符数组
int _size;
int _capacity;
};
//static size_t string::npos = -1;//err
size_t string::npos = -1;//yes
}
下面就是我们要实现的框架
#define _CRT_SECURE_NO_WARNINGS 1
#pragma once
#include <iostream>
using namespace std;
#include <assert.h>
namespace wzs
{
class string
{
public:
//npos
static size_t npos;
//1.全缺省的构造函数
string(const char* str = "");
~string();
//2.拷贝构造函数
string(const string& s);
//3.赋值运算符重载
string& operator=(const string& s);
//4.返回C风格的字符串
const char* c_str() const;
//5.iterator
typedef char* iterator;
iterator begin();
iterator end();
typedef const char* const_iterator;
const_iterator begin() const;
const_iterator end() const;
//6.流插入运算符重载
//friend ostream& operator<<(ostream& out, const string& s);
//7.operator[]重载
char& operator[](int index);
const char& operator[](int index) const;
//8.size() capacity()
const int size() const;
const int capacity() const;
//9..reserve:这里不允许缩容
void reserve(int capacity);
//10.push_back
void push_back(const char c);
//11.append
void append(const char* str);
//12.+=
string& operator+=(const char c);
string& operator+=(const char* str);
//13.insert
void insert(size_t pos, const char c);
void insert(size_t pos, const char* str);
//14.erase
void erase(size_t pos = 0, size_t len = npos);
//15.resize
void resize(size_t n, char c = '\0');
//16.swap
void swap(string& s);
//17.find
size_t find(const string& s, size_t pos = 0) const;
size_t find(const char c, size_t pos = 0) const;
//18.substr
string substr(size_t pos = 0, size_t len = npos)const;
//19.clear
void clear();
//20.empty
bool empty()const;
//21.>>
//friend istream& operator>>(istream& in, string& s);
private:
char* _str;
int _size;
int _capacity;
};
//static size_t string::npos = -1;//err
size_t string::npos = -1;//yes
ostream& operator<<(ostream& out, const string& s);
istream& operator>>(istream& in, string& s);
}
下面我们就逐个完成这些函数
大家会发现,我这里把流插入和流提取的友元给注释掉了
其实对于string类来说,流插入和流提取是不需要在类内用友元的
因为:
首先,友元是一种突破封装的方式,会增加耦合度,所以并不建议使用
其次,我们使用友元是因为我们想要访问类内的私有数据
可是对于string类来说
它的私有数据:size,capacity,_str都已经对外提供接口了
因此流插入和流提取只需要调用那些接口即可
无需使用友元来访问类内私有数据了
二.默认成员函数
1.构造函数
//1.全缺省的构造函数
string(const char* str = "")
{
//1.申请空间
int len = strlen(str);
_str = new char[len + 1];
//2.拷贝数据
strcpy(_str, str);
//3.修改_size和_capacity
_size = len;
_capacity = len;
}
在这里我们实现的是一个全缺省的构造函数
注意几点:
1.strlen求字符串长度时不会算上’\0’,因此我们开空间时要开len+1大小,因为我们还要在末尾存储’\0’
2.这里的
strcpy(_str,str);
会把str字符串中的从首元素开始一直延伸到'\0'为止的数据拷贝给_str
'\0'也会被拷贝进去!!!

对于这个构造函数:
其实就是
1.申请一个空间
2.拷贝数据
3.修改_size和_capacity
2.拷贝构造函数
1.传统写法
注意:string中的_str是开辟在堆区的
所以我们要实现深拷贝,否则会造成同一空间多次释放等问题
//2.拷贝构造函数
string(const string& s)
{
//1.申请空间
int len = s._size;
_str = new char[len + 1];
//2.拷贝数据
strcpy(_str, s._str);
//3.修改_size和_capacity
_size = len;
_capacity = len;
}
跟刚才的构造函数基本相同
2.现代写法
string(const string& s)
:_str(nullptr)
,_size(0)
,_capacity(0)
{
string tmp(s._str);
swap(tmp);//this->swap(tmp)
}
使用s._str调用构造函数来构造tmp
然后再去把tmp和*this交换
非常巧妙
3.析构函数
~string()
{
//释放空间
delete[] _str;
_str=nullptr;
//重置_size和_capacity
_size = 0;
_capacity = 0;
}
1.释放空间
2.重置_size和_capacity
4.赋值运算符重载
1.传统写法
//3.赋值运算符重载
string& operator=(const string& s)
{
if (this != &s)//这里是为了防止自己给自己拷贝的冗余操作
{
//1.开辟一块新空间
int len = s._size;
char* tmp = new char[len + 1];
//2.拷贝数据 把s._str的数据拷贝给tmp
strcpy(tmp, s._str);
//3.释放原有空间
delete[] _str;
_str = tmp;
tmp = nullptr;
//4.修改_size和_capacity
_size = len;
_capacity = len;
}
return *this;
}
其实就是
1.开辟一块新空间
2.拷贝数据
3.释放原有空间
4.修改_size和_capacity
2.现代写法
//现代写法1
string& operator = (const string& s)
{
if (this != &s)
{
//调用拷贝构造函数,然后交换
string tmp(s);
swap(tmp);
}
return *this;
}
//现代写法2
//直接传值传参,然后交换
string& operator = (string s)
{
swap(s);
return *this;
}
三.遍历和访问
1.operator[]运算符重载
//7.operator[]重载
//同STL库中的operator[]重载:有两个重载版本
//一个没有被const修饰
//另一个是被const修饰的
char& operator[](int index)
{
//STL中的string允许[]访问最后的'\0'
assert(index >= 0 && index <= _size);
return _str[index];
}
const char& operator[](int index) const
{
//STL中的string允许[]访问最后的'\0'
assert(index >= 0 && index <= _size);
return _str[index];
}
就是直接返回对应位置的引用的即可
2.iterator迭代器
我们在C++ 带你吃透string容器的使用末尾提到了iterator迭代器
这里就不赘述了
同STL库,iterator有两个版本:const和非const
//5.iterator
typedef char* iterator;
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
typedef const char* const_iterator;
const_iterator begin() const
{
return _str;
}
const_iterator end() const
{
return _str + _size;
}
四.容量相关函数
1.size,capacity
因为size和capacity对于类外是只读属性,因此用const修饰
//8.size() capacity()
const int size() const
{
return _size;
}
const int capacity() const
{
return _capacity;
}
2.reserve
我们在这里实现的版本是不允许缩容的
能不能缩容取决于编译器的具体实现
这一点我们这篇博客: C++ 带你吃透string容器的使用也提到过
//9.reserve:这里不允许缩容
void reserve(int capacity)
{
//只有需要扩容时才会进行扩容
if (_capacity < capacity)
{
//1.开辟新空间
char* tmp = new char[capacity + 1];
//2.将原有数据拷贝至新空间
strcpy(tmp, _str);
//3.释放原有空间
delete[] _str;
//4.将_str指向新空间
_str = tmp;
tmp = nullptr;
//5.修改_capacity
_capacity = capacity;
}
}
1.开辟新空间
2.将原有数据拷贝至新空间
3.释放原有空间
4.将_str指向新空间
5.修改_capacity
3.resize
这里我复用了erase和push_back
大家可以最后再来看这个resize,因为这个resize不会再其他接口中调用,最后看也无妨
//15.resize
//这里给字符设置了缺省参数'\0',将两个版本合二为一
void resize(size_t n, char c = '\0')
{
//1.n<_size : 删除多余字符,修改_size,但不修改_capacity
if (n < _size)
{
erase(n);//erase负责修改_size
}
//2._size<=n<=_capacity : 尾插字符c直到_size == n
else if (n <= _capacity)
{
//尾插数据
while (_size < n)
{
push_back(c);//push_back负责修改_size
}
}
//3.n>_capacity: 需要reserve
else
{
//扩容:将容量扩为n
reserve(n);//reserve负责修改_capacity
//尾插数据
while (_size < n)
{
push_back(c);//push_back负责修改_size
}
}
}
分为三种情况:

五.尾插
1.push_back
//10.push_back
void push_back(const char c)
{
//1.容量不够了的话:扩容
if(_capacity==_size)
{
int newcapacity = _capacity == 0 ? 4 : _capacity * 2;
reserve(newcapacity);
}
//2.尾插
_str[_size] = c;
//3.修改_size
_size++;
//4.不要忘了末尾的'\0'
_str[_size] = '\0';
}
1.容量不够了的话:扩容
2.尾插
3.修改_size
4.不要忘了末尾的’\0’
2.append
//11.append
void append(const char* str)
{
//1.容量不够的话: 扩容
int len = strlen(str);
int newcapacity = _size + len;
//如果容量够,reserve不会执行任何语句(具体原因请看reserve函数)
reserve(newcapacity);
//2.拷贝数据
strcpy(_str + _size, str);
//3.修改_size
_size += len;
}
1.容量不够的话: 扩容
2.拷贝数据
3.修改_size
注意:
_str+_size就指向了_str的末尾(‘\0’)
然后strcpy从_str末尾(‘\0’)开始进行拷贝
问题来了:
能不能用strcat呢?
不建议用
因为strcat使用时会先遍历目标字符串找到’\0’
然后再去进行拷贝
这样的话就多了一个遍历目标字符串的消耗
而我们直接_str+_size就找到目标字符串末尾(‘\0’)了
可以看出:当我们掌握了一些库函数的底层实现之后就是可以优化掉很多不必要的消耗
3.operator+=运算符重载
直接复用push_back和append即可
也是两个版本
//12.+=
string& operator+=(const char c)
{
push_back(c);
return *this;
}
string& operator+=(const char* str)
{
append(str);
return *this;
}
六.指定位置插入删除
1.insert
1.插入一个字符的版本
注意:下面就有坑了
大家看一下下面这个代码有什么问题?
提示:
1.while循环位置的错误
2.而且这个错误只有当我进行头插的时候才会出现
void insert(size_t pos, const char c)
{
assert(pos >= 0 && pos <= _size);
//1.容量不够的话要扩容
if (_capacity == _size)
{
int newcapacity = _capacity == 0 ? 4 : _capacity * 2;
reserve(newcapacity);
}
//2.将[pos,_size]的数据往后挪动
//这里把_size位置的数据(也就是'\0')也往后挪动是为了
//让我们最后的时候就不用单独再去在末尾添加'\0'了
//因为'\0'已经被我们挪动到最后了
size_t end = _size;
while (end >= pos)
{
_str[end + 1] = _str[end];
end--;
}
//3.在pos位置插入字符c
_str[pos]=c;
//4.修改_size
_size++;
}
1.容量不够的话要扩容
2.将[pos,_size]的数据往后挪动
3.在pos位置插入字符c
4.修改_size
下面我们来调试看一下
一开始时大家可以重点看_str的变化(理解数据后移的过程)
等到end快要减为0时再去看end的变化

因为end是size_t类型(也就是无符号整数)
永远大于等于0
当pos==0时,while(end>=pos)永远都成立
因此陷入死循环
那么怎么办呢?
第一种解决方案:强制类型转换
//把[pos,_size]的数据右移
//解决方案1:强制类型转换
size_t end = _size;
while ((int)end >= (int)pos)
{
_str[end + 1] = _str[end];
end--;
}
此时insert就正常运行了

尽管我end还是会减为-1时变为42亿多
但是while循环中我end强制类型转换转为了int类型(其实是产生了int类型的临时变量,然后用临时变量去比较的)
所以真实的比较场景是while(-1>=0),此时就退出while循环了
不过还有一个小点:
如果我这样写呢? 能不能顺利运行呢?
int end = _size;
while (end >= pos)
{
_str[end + 1] = _str[end];
end--;
}

答案是:还是不行
因为int类型的end跟size_t类型的pos比较时
int类型会进行整形提升产生size_t类型的临时变量,然后用临时变量跟pos去比较
也就是size_t类型的-1,-2,-3…跟size_t类型的pos去比
我们都知道size_t类型的-1,-2,-3那可是无符号整型的前几个最大值啊
肯定比我这个pos大嘛
所以还是死循环
只能强制类型转换吗?
当然不是,条条大路通罗马
还可以这样挪动数据
//13.insert
void insert(size_t pos, const char c)
{
assert(pos >= 0 && pos <= _size);
if (_capacity == _size)
{
int newcapacity = _capacity == 0 ? 4 : _capacity * 2;
reserve(newcapacity);
}
//把[pos,_size]的数据右移
//解决方案2
size_t end = _size + 1;
while (end > pos)
{
_str[end] = _str[end - 1];
end--;
}
_str[pos] = c;
_size++;
}
此时当end减为0时就已经挪动完数据了
并且while循环也可以正常退出

我们在这里就采用第二种解决方案啦
大家也可以用一下第一种解决方案
2. 插入一个字符串的版本
跟插入字符的操作差不多
只不过挪动的步长不是1而是字符串的长度
void insert(size_t pos, const char* str)
{
assert(pos >= 0 && pos <= _size);
//1.容量不够的话要扩容
int len = strlen(str);
int newcapacity = _size + len;
reserve(newcapacity);
//2.将[pos,_size]的数据往后挪动len个位置
int end = _size + 1;
while (end > pos)
{
_str[end + len - 1] = _str[end - 1];
end--;
}
//3.在pos位置插入字符串的前len个字符(也就是不插入'\0')
strncpy(_str + pos, str, len);//使用strncpy,而不能使用strcpy
//因为我们不要拷贝'\0'
//而strcpy是拷贝到'\0'才结束
//4.修改_size
_size += len;
}
1.容量不够的话要扩容
2.将[pos,_size]的数据往后挪动len个位置
3.在pos位置插入字符串的前len个字符(也就是不插入’\0’)
4.修改_size
strncpy就是可以指定拷贝n个字符
而不是跟strcpy一样直接拷贝到’\0’

2.erase
//14.erase
void erase(size_t pos = 0, size_t len = npos)
{
assert(pos >= 0 && pos <= _size);
//1.判断要删除的长度和[pos,_size)长度的大小
//要删除的长度大于等于[pos,_size)的长度
//此时直接将pos位置置为'\0'并且修改_size即可
if (len >= _size - pos)
{
_str[pos] = '\0';
_size = pos;
}
//要删除的长度小于[pos,_size)的长度
//那么把[pos+len,_size]的数据往前移动len位置来覆盖我们要删除的字符
//然后修改_size即可
else
{
strcpy(_str + pos, _str + pos + len);
_size -= len;
}
}
1.判断要删除的长度和[pos,_size)长度的大小
2.如果要删除的长度大于等于[pos,_size)的长度
那么直接将pos位置置为’\0’并且修改_size即可
3.如果要删除的长度小于[pos,_size)的长度
那么把[pos+len,_size]的数据往前移动len位置来覆盖我们要删除的字符
并且修改_size即可
注意:这里if语句中要使用len>=_size-pos
而不能使用len+pos>=_size
因为如果len为npos的话
那么len+pos就会溢出
会出现一些意想不到的错误
比如这样:
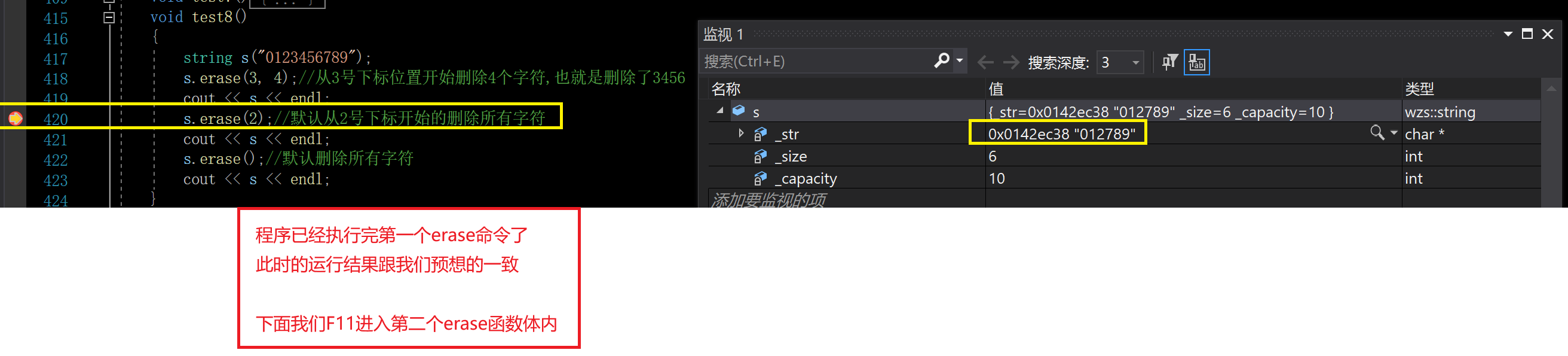

最后的结果:

我们注意到len+pos溢出之后变为了1
而我们的pos是2
因此:
strcpy(_str + pos, _str + pos + len);
就是把1位置的数据往2位置去拷贝,直到遇到’\0’为止
这就搞得非常荒诞了,因此这里使用的是len>=_size-pos
使用len>=_size-pos的话
因为len本身是npos
所以就会执行if语句的那个分支,而不是进入else执行strcpy导致出现千奇百怪的错误

七.查找,交换,截取操作
1.find
跟STL库一样,我们实现两个版本
查找字符串和查找字符
//17.find
size_t find(const char c, size_t pos = 0) const
{
assert(pos >= 0 && pos < _size);
for (size_t i = pos; i < _size; i++)
{
if (_str[i] == c)
{
return i;
}
}
return npos;
}
这个查找字符就很简单了,遍历一遍即可
但是这个查找字符串我们要用到strstr字符串匹配函数

size_t find(const string& s, size_t pos = 0) const
{
assert(pos >= 0 && pos < _size);
char* index = strstr(_str + pos, s._str);
if (index == nullptr)
{
return npos;
}
else
{
return index - _str;
}
}
唯一需要注意的一点就是:
返回空指针的话代表没有查找到,需要加一个if判断
如果查找到了
返回index-_str即可(指针-指针的问题,是C语言的基础知识)
2.swap
//16.swap
void swap(string& s)
{
//这里调用的是std(标准库中的那个swap函数)
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}
这里的swap的实现其实就是
交换指针,交换_size和_capacity
这样做的好处是无需再去拷贝string了,而是直接交换指针即可,大大优化了swap的效率
可见这个设计是非常巧妙的
3.substr
大家看一下这个代码有没有什么问题
string& substr(size_t pos = 0, size_t len = npos)const
{
assert(pos >= 0 && pos < _size);
string s;
//1.判断要截取的长度和[pos,_size)长度的大小
//要截取的长度大于[pos,_size)的长度 -> 那么修改len方便后续形成子串
if (len >= _size - pos)
{
len = _size - pos;
}
//2.插入数据形成子串
for (size_t i = 0; i < len; i++)
{
s += _str[i + pos];
}
//3.返回子串
return s;
}
1.判断要截取的长度和[pos,_size)长度的大小 如果大了,那么就修改len
2.插入数据形成子串
3.返回子串
其实这个代码是有问题的,只不过并不是我们实现逻辑的问题
而是这个引用做返回值的问题
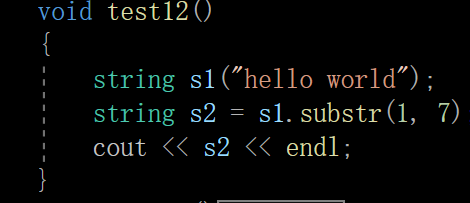

因为我们的这个s串是substr函数中的局部变量
出了作用域后会自动销毁(调用析构函数)
但是因为我们是引用作为返回值
因此s1.substr(1,7)这个对象就是我们刚才析构后的s串
然后用这个已经析构了的串给s2进行拷贝构造

于是拷贝构造时
strcpy访问s._str导致出现了对空指针的解引用操作
因此报错
怎么办呢?
把引用做返回值改为值做返回值
就好了
但是好的前提一定是你的拷贝构造,赋值运算符重载都是用的深拷贝,而不是浅拷贝
否则就会出现同一空间多次释放的错误

下面我把拷贝构造函数给干掉
那么就会用编译器默认形成的拷贝构造函数(默认形成的是浅拷贝)

此时,尽管你是值拷贝,但是你是浅拷贝
也就是说返回是我指向已经析构后的空间的那个指针
因此在s2析构的时候会对那个空间再次进行析构
也就是发生了同一空间多次释放的问题
也就是野指针的问题
下面我把拷贝构造函数恢复
string substr(size_t pos = 0, size_t len = npos)const
{
assert(pos >= 0 && pos < _size);
string s;
//1.判断要截取的长度和[pos,_size)长度的大小
//要截取的长度大于[pos,_size)的长度 -> 那么修改len方便后续形成子串
if (len >= _size - pos)
{
len = _size - pos;
}
//2.插入数据形成子串
for (size_t i = 0; i < len; i++)
{
s += _str[i + pos];
}
//3.返回子串
return s;
}
此时就正常运行了
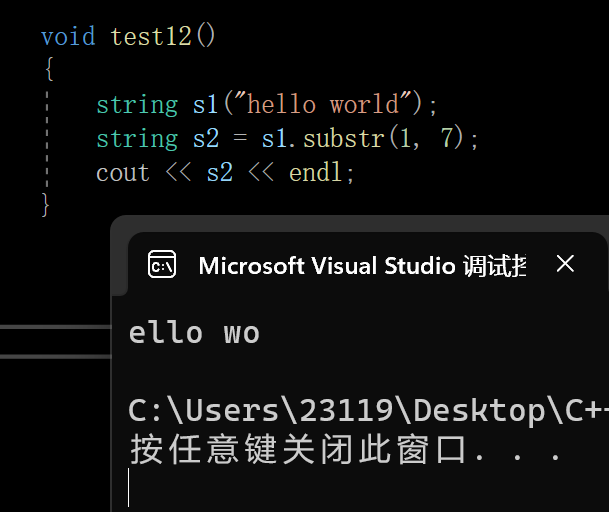
整个流程是:
s串返回值进行拷贝构造形成临时变量
然后返回那个临时变量
然后再由那个临时变量给这个s2进行拷贝构造
关于引用的知识点:
C++入门-引用
深浅拷贝的知识点
C++类和对象中(构造函数,析构函数,拷贝构造函数)详解
八.几个小函数
1.c_str
//4.返回C风格的字符串
const char* c_str() const
{
return _str;
}
2.clear
//19.clear
void clear()
{
_str[0] = '\0';//关于这里为什么要把第一个字符置为'\0'
//是因为我们要保证
//此时即使使用cout<<c_str()来打印string对象时也不会跟使用流插入打印string对象产生歧义
//因为使用cout<<c_str()是打印到'\0'才会停止
//而流插入是按照size来打印的
_size = 0;
}
3.empty
//20.empty
bool empty()const
{
return _size == 0;
}
九.流插入和流提取
对于流插入和流提取我们之前就在日期类接触了。
不能重载成成员,因为会和this指针抢占第一个位置。
所以需要定义成全局的
不过无需使用友元,因为可以调用接口来访问类内数据
1.<<流插入
按照_size打印
ostream& operator<<(ostream& out, const string& s)
{
for (int i = 0; i < s.size(); i++)
{
out << s[i];
}
return out;
}
对于<<和c_str()的区别:<<按照size进行打印,跟\0没有关系,而c_str()遇到\0结束
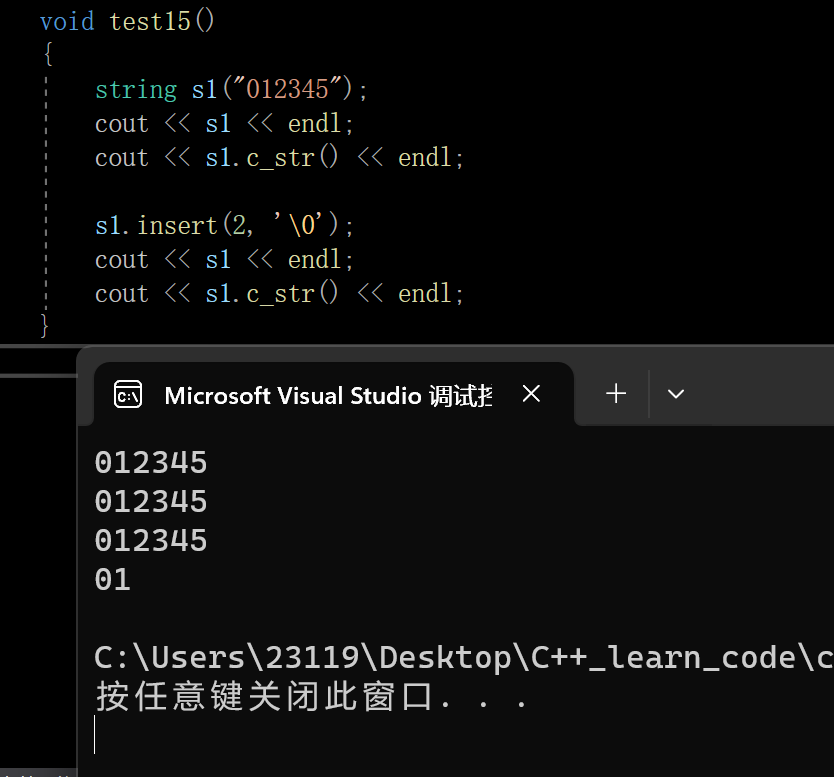
因此推荐使用<<
2.>>流提取
cin和scanf一样,都是读到’ ‘或者’\n’后就会停止
因此我们需要一个字符一个字符地读取
所以使用get()函数来读取字符
第一个版本:
istream& operator>>(istream& in, string& s)
{
//注意:使用流提取时,会覆盖原有数据
//因此需要先clear一下
s.clear();
char ch = in.get();
while (ch != ' ' && ch != '\n')
{
s += ch;
ch = in.get();
}
return in;
}
但是第一个版本有一个缺陷:
当我们想要读取的数据特别特别多的时候
就会频繁扩容,造成不必要的麻烦
因此我们可以设置一个"缓冲区"似的数组
第二个版本:
istream& operator>>(istream& in, string& s)
{
s.clear();
char tmp[128] = { '\0' };
char ch = in.get();
size_t index = 0;
while (ch != ' ' && ch != '\n')
{
if(index == 127)
{
s += tmp;
index = 0;
}
tmp[index++] = ch;
ch = in.get();
}
if (index >= 0)
{
tmp[index] = '\0';
s += tmp;
}
return in;
}
十.完整代码
1.my_string.h:
#define _CRT_SECURE_NO_WARNINGS 1
#pragma once
#include <string>
#include <iostream>
using namespace std;
#include <assert.h>
//小函数定义在.h里面,弄成内联函数
namespace wzs
{
class string
{
public:
//npos
static size_t npos;
//1.全缺省的构造函数
string(const char* str = "");
~string();
//2.拷贝构造函数
string(const string& s);
//18.substr
string substr(size_t pos = 0, size_t len = npos)const;
//3.赋值运算符重载
string& operator=(string s);
//4.返回C风格的字符串
const char* c_str() const
{
return _str;
}
//5.iterator
typedef char* iterator;
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
typedef const char* const_iterator;
const_iterator begin() const
{
return _str;
}
const_iterator end() const
{
return _str + _size;
}
//6.流插入运算符重载
//friend ostream& operator<<(ostream& out, const string& s);
//7.operator[]重载
char& operator[](int index);
const char& operator[](int index) const;
//8.size() capacity()
const int size() const
{
return _size;
}
const int capacity() const
{
return _capacity;
}
//9..reserve:这里不允许缩容
void reserve(int capacity);
//10.push_back
void push_back(const char c);
//11.append
void append(const char* str);
//12.+=
string& operator+=(const char c);
string& operator+=(const char* str);
//13.insert
void insert(size_t pos, const char c);
void insert(size_t pos, const char* str);
//14.erase
void erase(size_t pos = 0, size_t len = npos);
//15.resize
void resize(size_t n, char c = '\0');
//16.swap
void swap(string& s);
//17.find
size_t find(const string& s, size_t pos = 0) const;
size_t find(const char c, size_t pos = 0) const;
//19.clear
void clear()
{
_str[0] = '\0';
_size = 0;
}
//20.empty
bool empty()const
{
return _size == 0;
}
//21.>>
//friend istream& operator>>(istream& in, string& s);
private:
char* _str;
int _size;
int _capacity;
};
ostream& operator<<(ostream& out, const string& s);
istream& operator>>(istream& in, string& s);
void test1();
void test2();
void test3();
void test4();
void test5();
void test6();
void test7();
void test8();
void test9();
void test10();
void test11();
void test12();
void test13();
void test14();
void test15();
void test16();
void test17();
}
2.my_string.cpp
#include "my_string.h"
namespace wzs
{
//1.全缺省的构造函数
string::string(const char* str)
{
int len = strlen(str);
_str = new char[len + 1];
strcpy(_str, str);
_size = len;
_capacity = len;
}
string::~string()
{
delete[] _str;
_str = nullptr;
_size = 0;
_capacity = 0;
}
//2.拷贝构造函数
/*
string(const string& s)
{
int len = s._size;
_str = new char[len + 1];
strcpy(_str, s._str);
_size = len;
_capacity = len;
}
*/
//拷贝构造的现代写法
//有些编译器上有问题
//因为如果_str没有被初始化为nullptr
//那么就完了,因为tmp除了这个构造函数就会调用析构
//所以我们可以先给缺省值或者初始化列表来让这个_str初始化为nullptr
string::string(const string& s)
:_str(nullptr)
, _size(0)
, _capacity(0)
{
//先构造
string tmp(s.c_str());
//再交换
swap(tmp);
}
//18.substr
string string::substr(size_t pos, size_t len)const
{
assert(pos >= 0 && pos < _size);
string s;
if (len >= _size - pos)
{
len = _size - pos;
}
for (size_t i = 0; i < len; i++)
{
s += _str[i + pos];
}
return s;
}
//3.赋值运算符重载
/*
string& operator=(const string& s)
{
if (this != &s)
{
int len = s._size;
char* tmp = new char[len + 1];
strcpy(tmp, s._str);
delete[] _str;
_str = tmp;
tmp = nullptr;
_size = len;
_capacity = len;
}
return *this;
}
*/
//赋值运算符重载的现代写法1
/*
string& operator=(const string& s)
{
if (this != &s)
{
//先拷贝构造
string tmp(s);
//再交换
swap(tmp);
return *this;
}
}
*/
//赋值运算符重载的现代写法2
//直接传值调用
//传参的时候值传参 -> 调用拷贝构造函数传参
string& string::operator=(string s)
{
//没有必要判断是否是自己给自己赋值
//因为这个对象已经拷贝出来了,覆水已经难收
swap(s);
//*this原来的空间是这个形参s释放的
return *this;
}
//7.operator[]重载
char& string::operator[](int index)
{
//stl中的string允许[]访问最后的'\0'
assert(index >= 0 && index <= _size);
return _str[index];
}
const char& string::operator[](int index) const
{
//stl中的string允许[]访问最后的'\0'
assert(index >= 0 && index <= _size);
return _str[index];
}
//9..reserve:这里不允许缩容
void string::reserve(int capacity)
{
if (_capacity < capacity)
{
char* tmp = new char[capacity + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
tmp = nullptr;
_capacity = capacity;
}
}
//10.push_back
void string::push_back(const char c)
{
if (_capacity == _size)
{
int newcapacity = _capacity == 0 ? 4 : _capacity * 2;
reserve(newcapacity);
}
_str[_size] = c;
_size++;
_str[_size] = '\0';
}
//11.append
void string::append(const char* str)
{
int len = strlen(str);
int newcapacity = _size + len;
reserve(newcapacity);
strcpy(_str + _size, str);
_size += len;
}
//12.+=
string& string::operator+=(const char c)
{
push_back(c);
return *this;
}
string& string::operator+=(const char* str)
{
append(str);
return *this;
}
//13.insert
void string::insert(size_t pos, const char c)
{
assert(pos >= 0 && pos <= _size);
if (_capacity == _size)
{
int newcapacity = _capacity == 0 ? 4 : _capacity * 2;
reserve(newcapacity);
}
//把[pos,_size]的数据右移
//size_t end = _size;
//while (end >= pos)
//{
// _str[end + 1] = _str[end];
// end--;
//}
//解决方案1:强制类型转换
//int end = _size;
//while (end >= pos)
//{
// _str[end + 1] = _str[end];
// end--;
//}
//解决方案2
size_t end = _size + 1;
while (end > pos)
{
_str[end] = _str[end - 1];
end--;
}
_str[pos] = c;
_size++;
}
void string::insert(size_t pos, const char* str)
{
assert(pos >= 0 && pos <= _size);
int len = strlen(str);
int newcapacity = _size + len;
reserve(newcapacity);
//[pos,_size]的数据右移len位
int end = _size + 1;
while (end > pos)
{
_str[end + len - 1] = _str[end - 1];
end--;
}
strncpy(_str + pos, str, len);//使用strncpy,而不能使用strcpy
//因为我们不要拷贝'\0'
//而strcpy是拷贝到'\0'才结束
_size += len;
}
//14.erase
void string::erase(size_t pos, size_t len)
{
assert(pos >= 0 && pos <= _size);
//要删除的长度大于[pos,_size)的长度
if (len >= _size - pos)
//if (len + pos >= _size)
{
_str[pos] = '\0';
_size = pos;
}
//把[pos+len,_size]的数据往前移动len位置
else
{
strcpy(_str + pos, _str + pos + len);
_size -= len;
}
}
//15.resize
void string::resize(size_t n, char c)
{
//1.n<_size : 删除多余字符,修改_size,但不修改_capacity
if (n < _size)
{
erase(n);//erase负责修改_size
}
//2._size<=n<=_capacity : 尾插字符c直到_size == n
else if (n <= _capacity)
{
while (_size < n)
{
push_back(c);//push_back负责修改_size
}
}
//3.n>_capacity: 需要reserve
else
{
reserve(n);//reserve负责修改_capacity
while (_size < n)
{
push_back(c);//push_back负责修改_size
}
}
}
//16.swap
void string::swap(string& s)
{
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}
//17.find
size_t string::find(const string& s, size_t pos) const
{
assert(pos >= 0 && pos < _size);
char* index = strstr(_str + pos, s._str);
if (index == nullptr)
{
return npos;
}
else
{
return index - _str;
}
}
size_t string::find(const char c, size_t pos) const
{
assert(pos >= 0 && pos < _size);
for (size_t i = pos; i < _size; i++)
{
if (_str[i] == c)
{
return i;
}
}
return npos;
}
//static size_t string::npos = -1;//err
size_t string::npos = -1;//yes
ostream& operator<<(ostream& out, const string& s)
{
for (int i = 0; i < s.size(); i++)
{
out << s[i];
}
return out;
}
istream& operator>>(istream& in, string& s)
{
//库里的流提取输入的时候会覆盖之前的旧内容!!
//运行看一下
//因此要clear
s.clear();//clear一般不会释放空间,就是把第一个元素置为'\0'并且把size置为0
//如果clear不把第一个元素置为'\0'
//那么>>和c_str就不一样了!!!!
//因为>>是按size打印,c_str打印到'\0'之前为止
char tmp[128] = { '\0' };
//get是istream类型调用的成员函数
char ch = in.get();
//get()是C++的,getchar()是C语言的,C++和C语言的缓冲区是不一样的,(C++是可以设计成不兼容C语言的)
//
//尽管C++是兼容C语言的,不过尽量还是用C++的
size_t index = 0;
//getline其实是当ch遇到'\n'之后才会停止while循环!!!!
while (ch != ' ' && ch != '\n')
{
//index是下一个要插入数据的下标
//注意:这里是127时就要放s里面并清空
//因为tmp的最后一个数据一定要保证是'\0'!!!!!!
if (index == 127)
{
s += tmp;
index = 0;
}
tmp[index++] = ch;
ch = in.get();
}
if (index >= 0)
{
tmp[index] = '\0';
s += tmp;
}
return in;
}
}
3.test.cpp
#include "my_string.h"
namespace wzs
{
void test1()
{
const string s1("hello world");
string s2;
cout << s1.c_str() << endl;
cout << s2.c_str() << endl;
string s3(s1);
cout << s3.c_str() << endl;
s2 = s1;
cout << s2.c_str() << endl;
}
void test2()
{
//string s2 = "hello iterator";
//string::iterator it = s2.begin();
//while (it != s2.end())//注意:我们使用iterator访问和遍历时要注意左闭右开使用[begin,end)
//{
// cout << *it << " ";//这里可以暂时理解为像是指针解引用的用法一样
// it++;//这里可以暂时理解为像是指针自增(也就是后移)的用法一样
//}
//cout << endl;
//cout << s2 << endl;
string s2 = "hello iterator";
string::iterator it = s2.begin();
while (it != s2.end())//注意:我们使用iterator访问和遍历时要注意左闭右开使用[begin,end)
{
*it += 1;//(*it)++;这样也可以,不过不要忘了加小括号(运算符优先级的问题)
cout << *it << " ";//这里可以暂时理解为像是指针解引用的用法一样
it++;//这里可以暂时理解为像是指针自增(也就是后移)的用法一样
}
cout << endl;
cout << s2 << endl;
}
void test3()
{
std::string s("hello world");
char c = s[s.size()];
cout << s[s.size()] << endl;
}
void test4()
{
string s1("hello world");
s1.reserve(100);
}
void test5()
{
string s1;
int old_capacity = s1.capacity();
cout << old_capacity << endl;
cout << s1 << endl;
for (int i = 0; i < 100; i++)
{
s1.push_back('w');//将'w'这个字符尾插进入s1当中
if (old_capacity != s1.capacity())
{
cout << s1.capacity() << endl;
old_capacity = s1.capacity();
}
}
cout << s1 << endl;
}
void test6()
{
string s("hello world");
/*s.push_back('2');
s.push_back('3');
s.append(" 1124");*/
s += "2";
s += '3';
s += " 1124";
cout << s << endl;
}
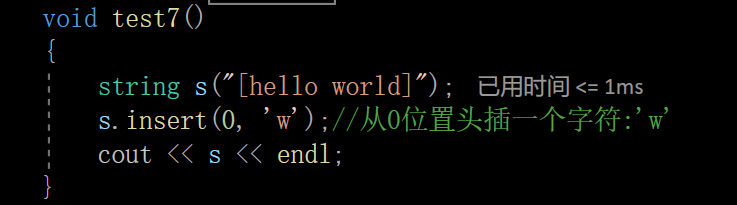
void test7()
{
string s("[hello world]");
s.insert(0, 'w');//从0位置头插一个字符:'w'
cout << s << endl;
}
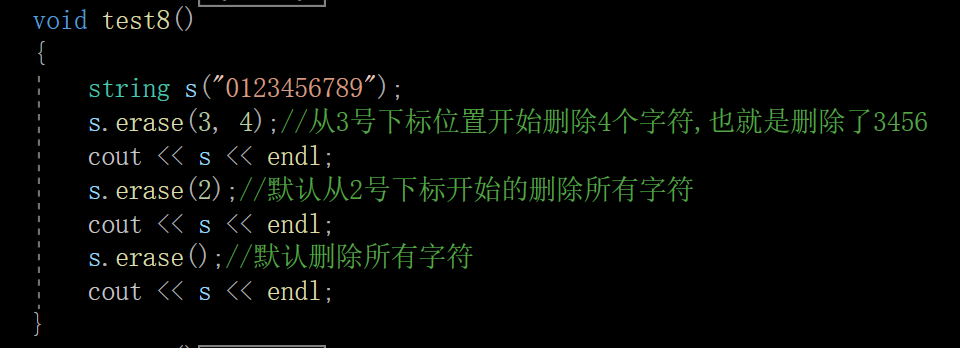
void test8()
{
string s("0123456789");
s.erase(3, 4);//从3号下标位置开始删除4个字符,也就是删除了3456
cout << s << endl;
s.erase(2);//默认从2号下标开始的删除所有字符
cout << s << endl;
s.erase();//默认删除所有字符
cout << s << endl;
}
void test9()
{
//string s1("hello world");
1.n<size
//s1.resize(4);
//cout << s1 << endl;
//string s1("hello world");
//2.size<n<capacity
//cout << s1.capacity() << endl;
s1.resize(13,'q');
//s1.resize(30, '2');
//cout << s1;
string s1;
s1.resize(10, 'w');
cout << s1 << endl;
}
void test10()
{
string s1("123");
string s2("456");
s1.swap(s2);
cout << s1 << endl;
cout << s2 << endl;
}
void test11()
{
string s1("abcd 1234 xxxx");
size_t index1 = s1.find("cd", 1);//从1号下标开始查找字符串cd
cout << index1 << endl;
size_t index3 = s1.find(' ', 1);//从1号下标开始查找字符' '
cout << index3 << endl;
//查不到的情况:
size_t index4 = s1.find("abcd", 1);//从1号下标开始查找字符串abcd -> 查不到,返回npos
cout << index4 << endl;//无符号整形最大值
}
void test12()
{
string s1("hello world");
string s2 = s1.substr(1, 7);
cout << s2 << endl;
}
void test13()
{
string s("http://www.baidu.com/index.html?name=mo&age=25#dowell");
string substr1, substr2, substr3;
//我们的目标是:
//substr1:http
//substr2:www.baidu.com
//substr3:index.html?name=mo&age=25#dowell
size_t pos1 = s.find(':', 0);//从0下标开始出发查找':'
substr1 = s.substr(0, pos1 - 0);//[0,pos1):左闭右开的区间:长度是右区间-左区间 也就是pos1-0
size_t pos2 = s.find('/', pos1 + 3);//pos1位置此时是':' 我们下一次要从pos1+3的位置开始查找 也就是第一个'w'的位置
substr2 = s.substr(pos1 + 3, pos2 - (pos1 + 3));//[pos1+3,pos2):这个区间内的子串
substr3 = s.substr(pos2 + 1);//从pos2+1开始一直截取到最后即可
//substr传值返回,是临时变量,临时变量具有常性
cout << substr1 << endl;
cout << substr2 << endl;
cout << substr3 << endl;
}
void test14()
{
//char ch1, ch2;
//cin >> ch1 >> ch2;
//因为输入多个值时,' '和'\n'默认是分割符,不是有效数据!!!!!!
//scanf也是拿不到的
string s1, s2, s3;
cin >> s1 >> s2 >> s3;
cout << s1 << endl << s2 << endl << s3 << endl;
}
void test15()
{
string s1("012345");
cout << s1 << endl;
cout << s1.c_str() << endl;
s1.insert(2, '\0');
cout << s1 << endl;
cout << s1.c_str() << endl;
}
void test16()
{
string s1("hello world");
cout << s1 << endl;
cout << s1.c_str() << endl;
//此时clear没有把第一个元素置为'\0'
s1.clear();
cout << s1 << endl;
cout << s1.c_str() << endl;
}
//整形转字符串:to_string
//stoi:字符串转整形
void test17()
{
//整形转字符串:to_string
std::string s = std::to_string(123);
//stoi:字符串转整形
int i = stoi(s);
cout << s << endl;
cout << i << endl;
}
}
以上就是C++: string的模拟实现的全部内容,希望能对大家有所帮助!