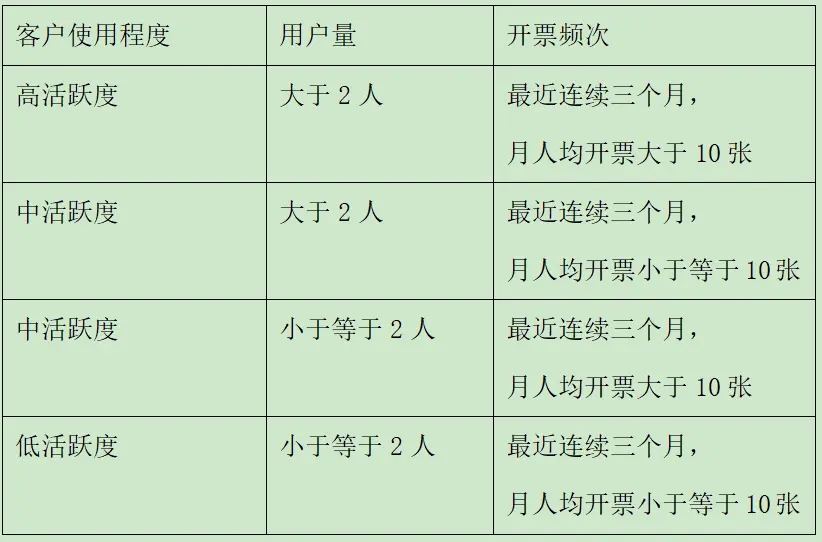
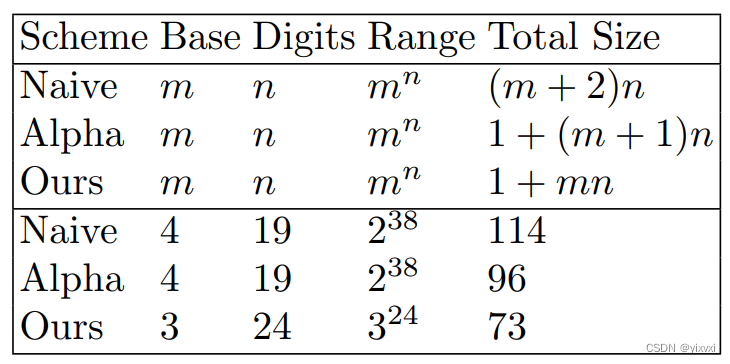
本文记录python环境下使用selenium的一些步骤
Step1:安装并配置驱动
pip install selenium # 使用pip在对应python中安装selenium包
为了让selenium能调用指定的浏览器,需要下载对应浏览器的驱动程序(这里以edge为例子)
#Firefox浏览器驱动:
https://link.zhihu.com/?target=https%3A//github.com/mozilla/geckodriver/releases
#Chrome浏览器驱动:
https://registry.npmmirror.com/binary.html?path=chromedriver/
#IE浏览器驱动:IEDriverServer
https://link.zhihu.com/?target=http%3A//selenium-release.storage.googleapis.com/index.html
#Edge浏览器驱动:MicrosoftWebDriver
https://link.zhihu.com/?target=https%3A//developer.microsoft.com/en-us/microsoft-edge/tools/webdriver
在下载edge驱动时,请先在edge浏览器中输入:edge://settings/help用于查看版本和位数,选择相匹配的驱动版本,具体可以参考官方的教程:https://learn.microsoft.com/zh-cn/microsoft-edge/webdriver-chromium/?tabs=c-sharp
下载驱动后,需要放在项目的主目录下,或添加到全局变量中,如图所示:
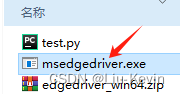
Step2:打开网页返回代码
from selenium import webdriver
options = webdriver.EdgeOptions()
options.add_experimental_option("detach", True) # 该选项可避免打开的网页闪退
browser = webdriver.Edge(options=options)
browser.maximize_window() #最大化窗口
browser.get( [link] ) # link_target为目标网页的网址的字符串
browser.implicitly_wait(2) # 等待一段时间使网页打开
time.sleep(2) # 这里是用time.sleep()可能更有效
browser.page_source #返回网页的代码,可以和beautifusoup包搭配使用
Step3:查找特定元素
在edge浏览器中可以在网页中对目标点击:右键–检查,查看网页源码,从而锁定目标查询并互动。
selenium提供八种查找方式,其中:“XPATH”和“CSS_SELECTOR”,可以在网页源码“元素”栏点击:右键–“复制XPath”和“复制selector”获得。其余的可以在元素栏中找到
from selenium.webdriver.common.by import By # 新版selenium使用By实现元素检索
browser.find_element(By.XPATH, [str])
browser.find_element(By.CSS_SELECTOR, [str])
browser.find_element(By.ID, [str])
browser.find_element(By.TAG_NAME, [str])
browser.find_element(By.CLASS_NAME, [str])
browser.find_element(By.PARTIAL_LINK_TEXT, [str])
browser.find_element(By.LINK_TEXT, [str])
browser.find_element(By.NAME, [str])
Step4:常见元素的互动方式
# 4-1 : Anchor链接类型
# 例如:<a href="#" class="zdy-btn zdy-btn-cur">查询<em></em></a>
# 注释:其中href是链接地址,使用:.click()点击
# 发现:有些网页使用By.LINK_TEXT更好用
browser.find_element(By.LINK_TEXT, '查询').click()
# 4-2 : input文本框类型
# 例如:<input type="text" class="ipt-sc issueFrom" title="">
# 注释:使用:.send_keys()填写
# 发现:如出现经常匹配不到的情况,可以增加等待时间,或者用try配合多种匹配方法
browser.find_element(By.XPATH, r'//*[@id="notie"]/body/strong/strong/div[6]/div[2]/ul/li[5]/div/div/div[2]/div[2]/p[1]/input[1]').send_keys( [str] )