-
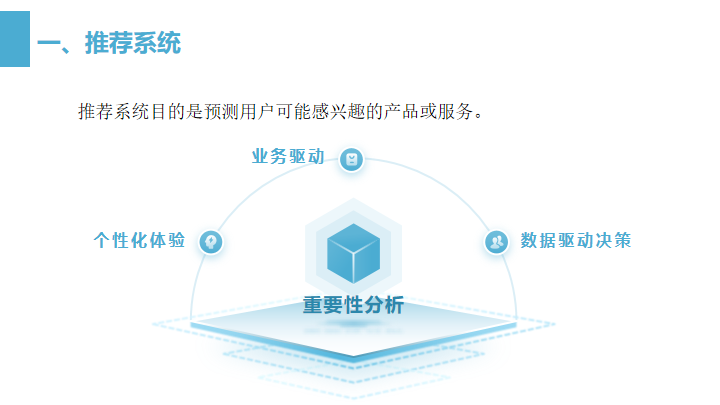
推荐系统是信息过滤系统的一种,它们的目的是预测用户可能感兴趣的产品或服务。
-
它们在各种在线平台中都非常重要,包括电子商务、视频流服务、社交媒体和在线广告(如谷歌广告)。
推荐系统不仅可以增加用户满意度和用户留存,还可以提高销售额和广告收入。 -
从以上三点进行重要性分析
个性化体验:随着信息量的爆炸性增长,用户需要过滤和发现对他们来说有价值的内容。
业务驱动:对于企业来说,推荐系统可以提高用户参与度,促进产品发现,从而增加销售和收入。
数据驱动决策:推荐系统利用用户行为数据(如浏览、购买、评分、点击等)来提供智能决策支持,从而提高营销和广告的效率。

-
点击率预测的目的是:预测用户 在看到某个广告 或 推荐内容时 点击的概率。
-
预测的准确性直接影响到广告和推荐内容的效果,以及最终的商业收入。
-
在线平台通常需要实时或近实时预测点击率(CTR),以动态地优化内容推送和广告展示。
-
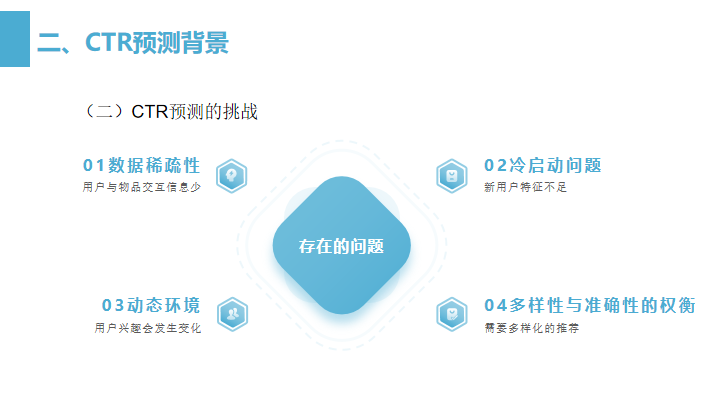
数据稀疏性:用户可能只与系统中的极少数项目互动,比如用户登录网站,只选择了自己感兴趣的内容点击。这样会导致用户-项目矩阵非常稀疏。
-
冷启动问题:对于新用户或新商品,系统缺乏足够的数据来做出准确的推荐。
-
动态环境:用户的兴趣可能会随时间变化,而且新的产品和信息也会不断地出现。
-
多样性与准确性的权衡:用户可能希望看到多样化的推荐,而不仅仅是系统认为他们可能会点击或购买的项目。
-
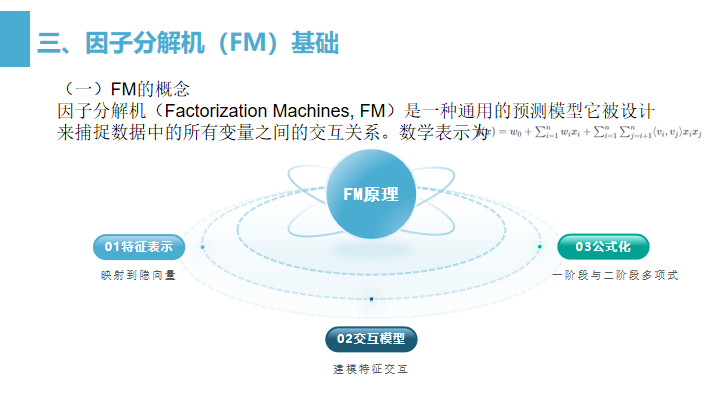
因子分解机(Factorization Machines, FM)是一种通用的预测模型它被设计来捕捉数据中的所有变量之间的交互关系。
-
特征表示:在FM模型中,每一个特征都被映射到一个隐向量中,这个向量能够捕捉该特征与其他特征之间的交互关系。
-
交互建模:FM通过对这些隐向量的点积来建模特征交互,使得即使是非常稀疏的数据集也能够学习到特征间的相关性。
-
公式化:FM的预测公式不仅包括了特征的线性组合(与线性回归相似),还包括了任意两个特征隐向量的点积,用以模拟这两个特征的交互。
-
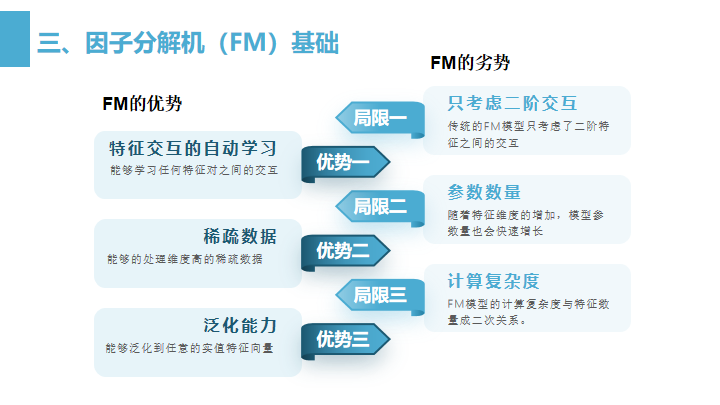
FM的优势
- 特征交互的自动学习:FM能够学习任何特征对之间的交互,而不需要人工设定交互项。比如牛奶与纸尿裤之间的交互联系。
- 高维稀疏数据:FM特别适合处理高维稀疏数据,比如在用户-物品矩阵中,用户只与少数物品有交互。
- 泛化能力:FM能够泛化到任意的实值特征向量,因此可以应用于多种不同的数据集和预测任务中。
-
FM的局限
- 只考虑二阶交互:传统的FM模型只考虑了特征之间的二阶交互,而实际上高阶特征交互(如用户-物品-上下文)也很重要。
- 参数数量:虽然FM处理高维特征的方式比较有效,但随着特征维度的增加,模型参数量(特别是隐向量)也会快速增长。
- 计算复杂度:对于每个预测,FM模型的计算复杂度与特征数量成二次关系,虽然有技巧可以减少复杂度,但对于非常大的数据集仍然是个挑战。
深度学习在特征学习中的作用是多方面的,其主要优势在于它能自动发现给定数据中的表示,而无需手动特征工程。
-
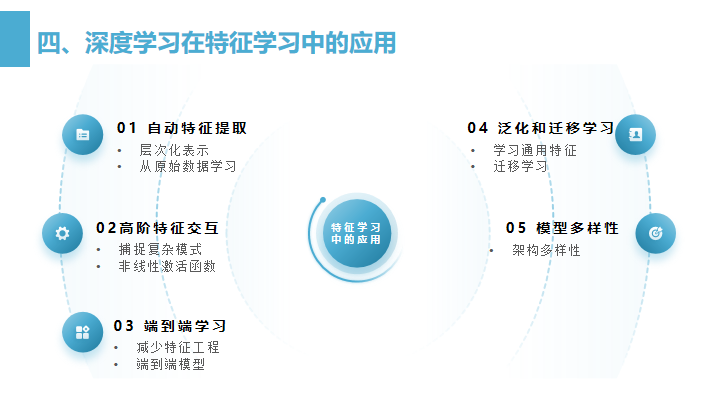
自动特征提取
层次化表示:深度学习模型通过多层非线性变换自动学习数据的层次化表示,每一层都构建在前一层的表示之上。这意味着深度模型可以从原始数据中提取出越来越抽象和复杂的特征。
从原始数据学习:与传统机器学习算法不同,深度学习模型可以直接从原始数据(如图像像素、音频波形或文本字符)中学习复杂的模式和表示。 -
高阶特征交互
捕捉复杂模式:深度神经网络通过多层结构能够捕捉输入特征之间的复杂高阶交互,这对于解决非线性问题非常有帮助。
非线性激活函数:网络中的非线性激活函数(如ReLU、Sigmoid或Tanh)允许网络学习非线性决策边界。 -
端到端学习
减少特征工程:深度学习减少了对专家知识和手动特征工程的依赖,因为网络能够自己发现有效的特征。
端到端模型:深度学习模型通常被设计为端到端模型,这意味着它们可以直接从输入到输出进行学习,中间不需要人为干预。 -
泛化和迁移学习
学习通用特征:在足够多的数据上训练时,深度学习模型能够学习到通用的特征表示,这些表示可以在不同的任务之间迁移和重用。
迁移学习:预训练的深度学习模型(如在大型图像数据集上训练的模型)可以用于新任务,只需少量调整即可。 -
模型多样性
不同架构:深度学习提供了多种架构,如卷积神经网络(CNNs)适用于图像,循环神经网络(RNNs)适用于时序数据,以及最近的注意力和Transformer模型在自然语言处理中的应用。
-
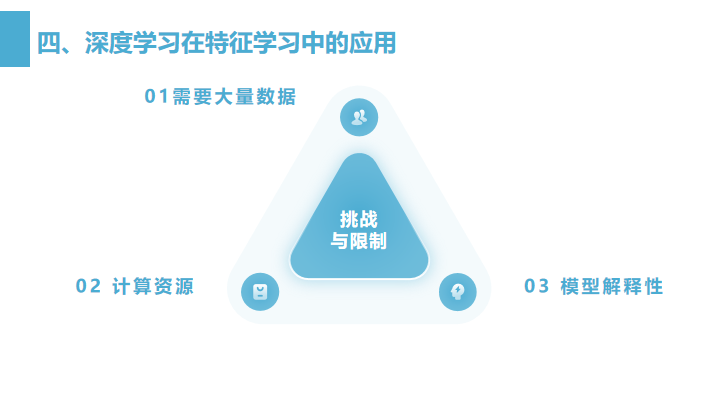
需要大量数据:深度学习模型通常需要大量数据来训练,以避免过拟合。
-
计算资源:训练深度学习模型通常需要显著的计算资源,如GPU或TPU。
-
模型解释性:深度学习模型通常被认为是“黑盒”,其决策过程的解释性较差。
-
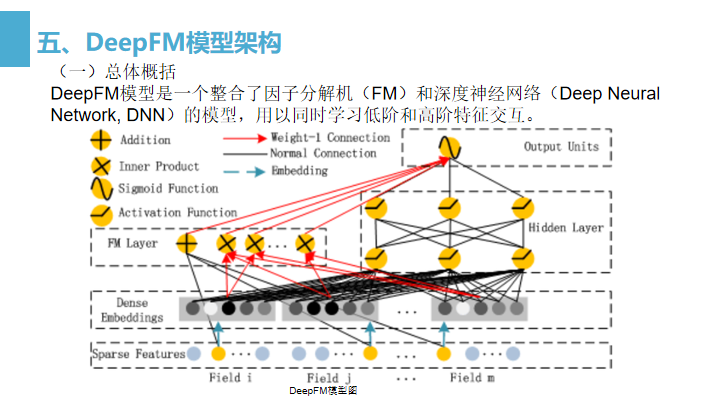
输入层(Sparse Features):输入数据包括类别特征和连续特征;
-
Embedding层(Dense Embeddings):该层的作用是对类别特征进行Embedding向量化,将离散特征映射为稠密特征。该层的结果同时提供给FM Layer和Hidden Layer,即FM Layer和Hidden Layer共享相同的Embedding层。
-
FM Layer:该模型主要提取一阶特征和两两交叉特征;
-
Hidden Layer:该模块主要是应用DNN模型结构,提取深层次的特征信息;
-
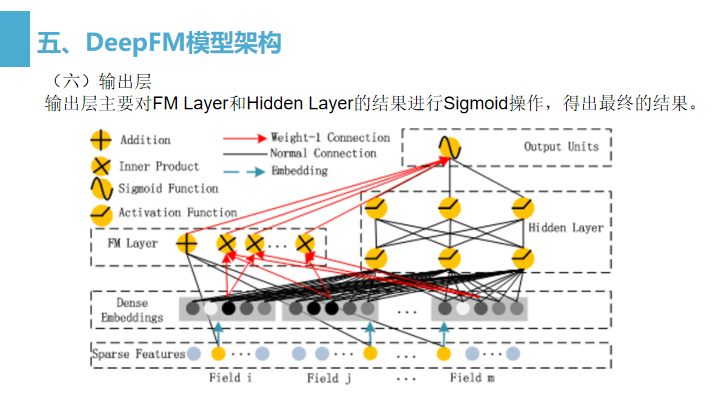
输出层(Output Units):对FM Layer和Hidden Layer的结果进行Sigmoid操作,得出最终的结果。
-
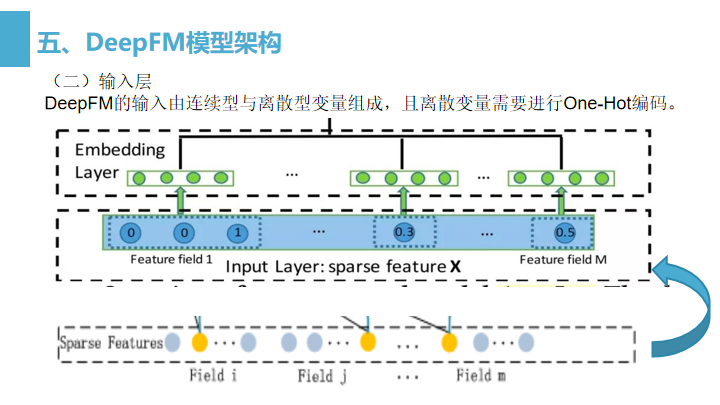
DeepFM的输入可由连续型变量和类别型变量共同组成,且类别型变量需要进行One-Hot编码。
正是由于One-Hot编码,导致了输入特征变得高维且稀疏。 -
针对高维稀疏的输入特征,DeepFM采用了word2vec的词嵌入(WordEmbedding)思想,把高维稀疏的向量 映射到相对低维 且向量元素都不为零的空间向量中,并且DeepFM根据特征类型进行了field区分,即将特征分为了不同的field。
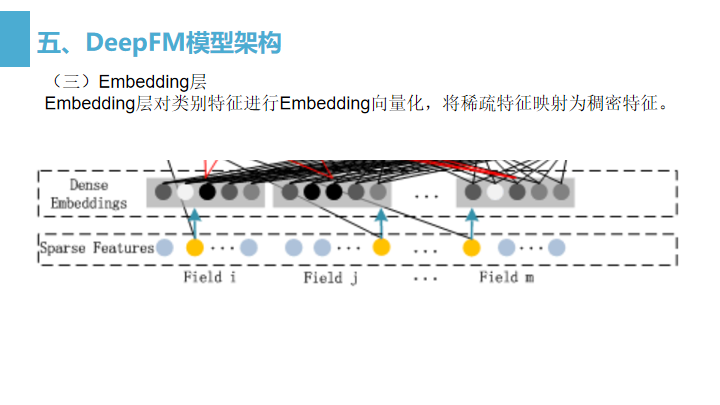
- embedding层对类别特征进行embedding向量化,将离散特征映射为稠密特征。
- embedding层的输入就是分field的特征,也就是说embedding层完成了对不同特征按field进行了向量化。
FM层和Hidden层共享的就是embedding层的输出结果。
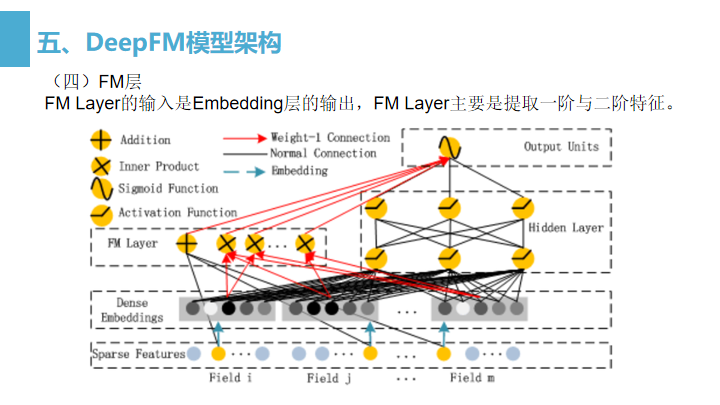
- FM Layer的输入是embedding层的输出,FM Layer主要是提取一阶特征和两两交叉的二阶特征。
如上图所示,Field_i、Field_j、Field_m中的黄色圆点指向Addition节点的黑线表示的是FM直接对原始特征做的一阶计算, - 而embedding层每个field对应的embedding会有两条红线连接到Inner Product节点表示的是FM对特征进行的二阶交叉计算。
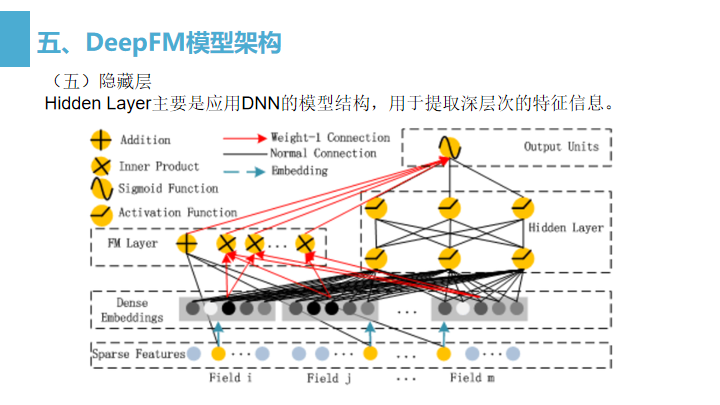
- Hidden Layer主要是应用DNN的模型结构,用于提取深层次的特征信息。
- Hidden Layer的输入也是embedding层的输出(与FM Layer共享输入)。从embedding层输出到Hidden Layer是一种全连接计算。
好好学习,天天向上。


![详解—[C++ 数据结构]—AVL树](https://img-blog.csdnimg.cn/direct/8c551d0403ba426081ad4c526c9d3544.png)