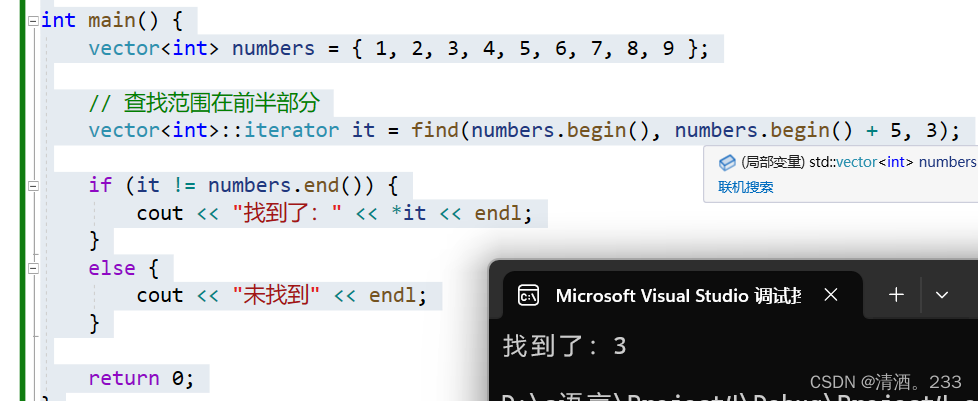
参考:
https://stackoverflow.com/questions/67707828/how-to-get-every-seconds-gpu-usage-in-python
自己测试
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
import torchvision
from torchvision import transforms
# 加载数据
import subprocess as sp
import os
from threading import Thread , Timer
import sched, time
def get_gpu_memory():
output_to_list = lambda x: x.decode('ascii').split('\n')[:-1]
ACCEPTABLE_AVAILABLE_MEMORY = 1024
COMMAND = "nvidia-smi --query-gpu=memory.used --format=csv"
try:
memory_use_info = output_to_list(sp.check_output(COMMAND.split(),stderr=sp.STDOUT))[1:]
except sp.CalledProcessError as e:
raise RuntimeError("command '{}' return with error (code {}): {}".format(e.cmd, e.returncode, e.output))
memory_use_values = [int(x.split()[0]) for i, x in enumerate(memory_use_info)]
# print(memory_use_values)
return memory_use_values
def print_gpu_memory_every_5secs():
"""
This function calls itself every 5 secs and print the gpu_memory.
"""
file = open("./GPU_usage.csv", "a+")
Timer(5.0, print_gpu_memory_every_5secs).start()
#print(get_gpu_memory())
mem = get_gpu_memory()[0]
print("{}".format(mem), file=file)
print_gpu_memory_every_5secs()
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize(mean=0.5, std=0.5)])
train_ds = torchvision.datasets.MNIST('data/',
train=True,
transform=transform,
download= True)
dataloader = torch.utils.data.DataLoader(train_ds, batch_size=256, shuffle=True,num_workers=4,pin_memory=True)
print(len(dataloader))
# 定义生成器
class Generator(nn.Module):
def __init__(self):
super(Generator,self).__init__()
self.linear1 = nn.Linear(100, 256*7*7)
self.bn1 = nn.BatchNorm1d(256*7*7)
self.deconv1 = nn.ConvTranspose2d(256, 128,
kernel_size=(3,3),
stride=1,
padding=1
) # 得到128*7*7的图像
self.bn2 = nn.BatchNorm2d(128)
self.deconv2 = nn.ConvTranspose2d(128, 64,
kernel_size=(4,4),
stride=2,
padding=1 # 64*14*14
)
self.bn3 = nn.BatchNorm2d(64)
self.deconv3 = nn.ConvTranspose2d(64, 1,
kernel_size=(4, 4),
stride=2,
padding=1 # 1*28*28
)
def forward(self, x):
x = F.relu(self.linear1(x))
x = self.bn1(x)
x = x.view(-1, 256, 7, 7)
x = F.relu(self.deconv1(x))
x = self.bn2(x)
x = F.relu(self.deconv2(x))
x = self.bn3(x)
x = torch.tanh(self.deconv3(x))
return x
# 定义判别器
# input:1,28,28
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.conv1 = nn.Conv2d(1, 64, kernel_size=3, stride=2) # 第一层不适用bn 64,13,13
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=2) #128,6,6
self.bn = nn.BatchNorm2d(128)
self.fc = nn.Linear(128*6*6, 1) # 输出一个概率值
def forward(self, x):
x = F.dropout2d(F.leaky_relu(self.conv1(x)))
x = F.dropout2d(F.leaky_relu(self.conv2(x))) # (batch, 128,6,6)
x = self.bn(x)
x = x.view(-1, 128*6*6) # (batch, 128,6,6)---> (batch, 128*6*6)
x = torch.sigmoid(self.fc(x))
return x
# 初始化模型
device = 'cuda' if torch.cuda.is_available() else 'cpu'
gen = Generator().to(device)
dis = Discriminator().to(device)
# 损失计算函数
loss_function = torch.nn.BCELoss()
# 定义优化器
d_optim = torch.optim.Adam(dis.parameters(), lr=1e-5)
g_optim = torch.optim.Adam(gen.parameters(), lr=1e-4)
def generate_and_save_images(model, epoch, test_input):
predictions = np.squeeze(model(test_input).cpu().numpy())
fig = plt.figure(figsize=(4, 4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i + 1)
plt.imshow((predictions[i] + 1) / 2, cmap='gray')
plt.axis("off")
plt.show()
test_input = torch.randn(16, 100, device=device)
# 开始训练
D_loss = []
G_loss = []
# 训练循环
for epoch in range(10):
d_epoch_loss = 0
g_epoch_loss = 0
count = len(dataloader)
# 对全部的数据集做一次迭代
for step, (img, _) in enumerate(dataloader):
img = img.to(device)
size = img.shape[0] # 返回img的第一维的大小
random_noise = torch.randn(size, 100, device=device)
d_optim.zero_grad() # 将上述步骤的梯度归零
real_output = dis(img) # 对判别器输入真实的图片,real_output是对真实图片的预测结果
d_real_loss = loss_function(real_output,
torch.ones_like(real_output, device=device)
)
d_real_loss.backward() #求解梯度
# 得到判别器在生成图像上的损失
gen_img = gen(random_noise)
fake_output = dis(gen_img.detach())
d_fake_loss = loss_function(fake_output,
torch.zeros_like(fake_output, device=device))
d_fake_loss.backward()
d_loss = d_real_loss + d_fake_loss
d_optim.step() # 优化
# 得到生成器的损失
g_optim.zero_grad()
fake_output = dis(gen_img)
g_loss = loss_function(fake_output,
torch.ones_like(fake_output, device=device))
g_loss.backward()
g_optim.step()
with torch.no_grad():
d_epoch_loss += d_loss.item()
g_epoch_loss += g_loss.item()
with torch.no_grad():
d_epoch_loss /= count
g_epoch_loss /= count
D_loss.append(d_epoch_loss)
G_loss.append(g_epoch_loss)
generate_and_save_images(gen, epoch, test_input)
print('Epoch:', epoch)
plt.plot(D_loss, label='D_loss')
plt.plot(G_loss, label='G_loss')
plt.legend()
plt.show()
print("done")
最终的结果如下

这个和
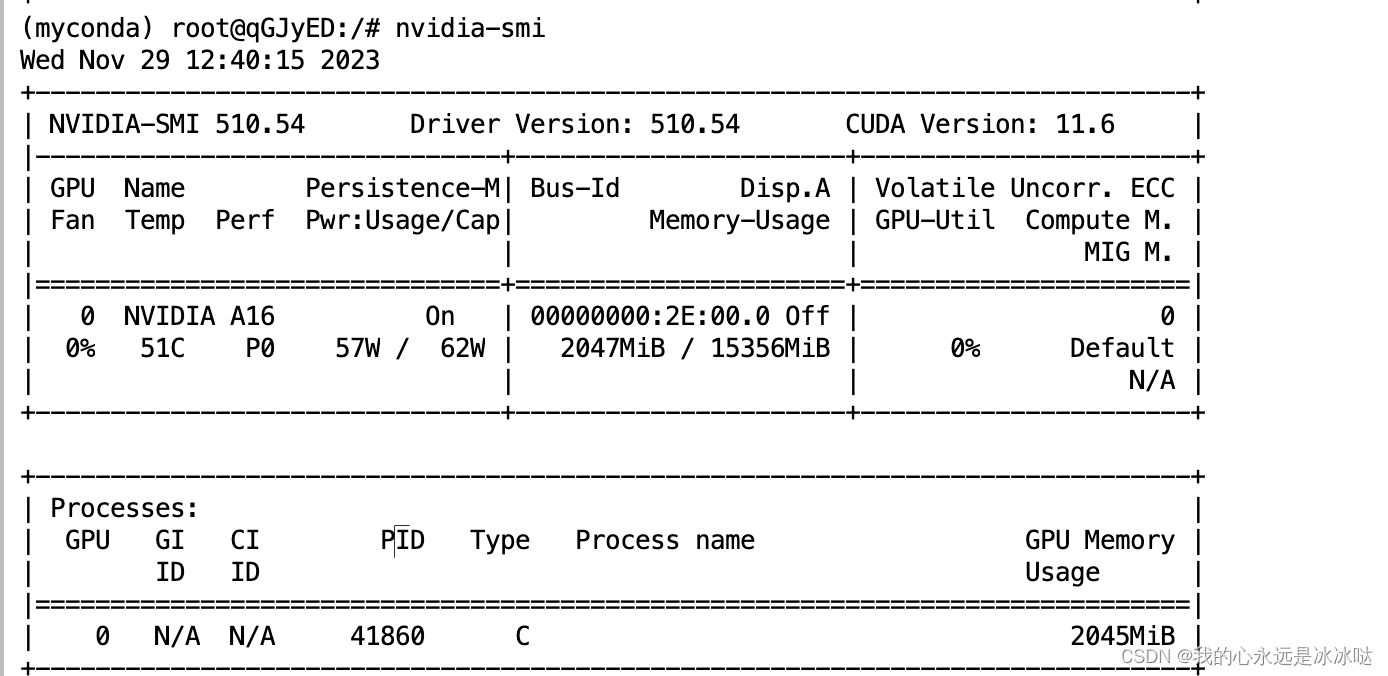
是差不多的,
但是目前这个做法有一个问题,就是我的主程序停止了,print_GPU_memory()函数还在跑,只能自己手动关闭,这个我不知道怎么解决