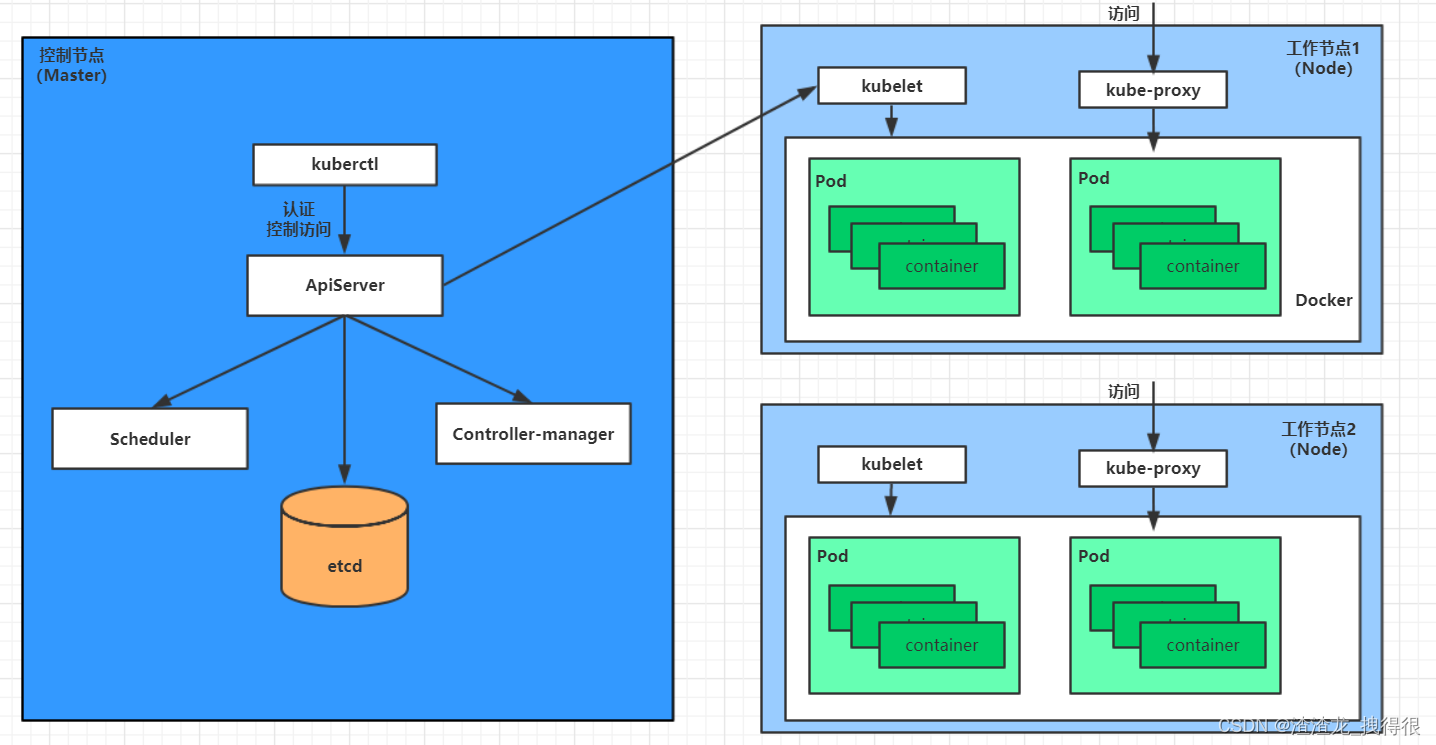
在前文中陆续基于不同类型的目标检测模型开发构建了钢铁产业产品缺陷质检系统,关于yolov6除了刚提出的时候有过使用,后续使用较少了,今天就以yolov6最新0.4.1分支模型为基准来开发实践目标检测项目开发。
首先看下实例效果:

官方项目地址在这里,如下所示:

分支详情在这里,如下所示:
这里选择的是最新的0.4.1分支。
如果对yolov6的详细实践有疑问的可以阅读下面的文章:
《基于美团技术团队最新开源的yolov6模型实现裸土检测》
这里就不再赘述了。
本文选取的是n系列最轻量级的模型,如下所示:
# YOLOv6s model
model = dict(
type='YOLOv6n',
pretrained='weights/yolov6n.pt',
depth_multiple=0.33,
width_multiple=0.25,
backbone=dict(
type='EfficientRep',
num_repeats=[1, 6, 12, 18, 6],
out_channels=[64, 128, 256, 512, 1024],
fuse_P2=True,
cspsppf=True,
),
neck=dict(
type='RepBiFPANNeck',
num_repeats=[12, 12, 12, 12],
out_channels=[256, 128, 128, 256, 256, 512],
),
head=dict(
type='EffiDeHead',
in_channels=[128, 256, 512],
num_layers=3,
begin_indices=24,
anchors=3,
anchors_init=[[10,13, 19,19, 33,23],
[30,61, 59,59, 59,119],
[116,90, 185,185, 373,326]],
out_indices=[17, 20, 23],
strides=[8, 16, 32],
atss_warmup_epoch=0,
iou_type='siou',
use_dfl=False, # set to True if you want to further train with distillation
reg_max=0, # set to 16 if you want to further train with distillation
distill_weight={
'class': 1.0,
'dfl': 1.0,
},
)
)
solver = dict(
optim='SGD',
lr_scheduler='Cosine',
lr0=0.0032,
lrf=0.12,
momentum=0.843,
weight_decay=0.00036,
warmup_epochs=2.0,
warmup_momentum=0.5,
warmup_bias_lr=0.05
)
data_aug = dict(
hsv_h=0.0138,
hsv_s=0.664,
hsv_v=0.464,
degrees=0.373,
translate=0.245,
scale=0.898,
shear=0.602,
flipud=0.00856,
fliplr=0.5,
mosaic=1.0,
mixup=0.243,
)
我这里是选择使用预训练微调的形式,当然了如果不想使用微调的方式,想要从头开始训练也都是可以的,如下所示:
# YOLOv6n model
model = dict(
type='YOLOv6n',
pretrained=None,
depth_multiple=0.33,
width_multiple=0.25,
backbone=dict(
type='EfficientRep',
num_repeats=[1, 6, 12, 18, 6],
out_channels=[64, 128, 256, 512, 1024],
fuse_P2=True,
cspsppf=True,
),
neck=dict(
type='RepBiFPANNeck',
num_repeats=[12, 12, 12, 12],
out_channels=[256, 128, 128, 256, 256, 512],
),
head=dict(
type='EffiDeHead',
in_channels=[128, 256, 512],
num_layers=3,
begin_indices=24,
anchors=3,
anchors_init=[[10,13, 19,19, 33,23],
[30,61, 59,59, 59,119],
[116,90, 185,185, 373,326]],
out_indices=[17, 20, 23],
strides=[8, 16, 32],
atss_warmup_epoch=0,
iou_type='siou',
use_dfl=False, # set to True if you want to further train with distillation
reg_max=0, # set to 16 if you want to further train with distillation
distill_weight={
'class': 1.0,
'dfl': 1.0,
},
)
)
solver = dict(
optim='SGD',
lr_scheduler='Cosine',
lr0=0.02,
lrf=0.01,
momentum=0.937,
weight_decay=0.0005,
warmup_epochs=3.0,
warmup_momentum=0.8,
warmup_bias_lr=0.1
)
data_aug = dict(
hsv_h=0.015,
hsv_s=0.7,
hsv_v=0.4,
degrees=0.0,
translate=0.1,
scale=0.5,
shear=0.0,
flipud=0.0,
fliplr=0.5,
mosaic=1.0,
mixup=0.0,
)
数据集的构建方式和形式与yolov5系列完全相同,当然了前面yolov6的操作教程里面也有很详细的数据集构建流程。
完成对应的操作之后就可以启动模型训练了,如下所示:
python tools/train.py --batch-size 32 --conf configs/yolov6n_finetune.py --data data/self.yaml --fuse_ab --device 0 --name yolov6n --epochs 100 --workers 2训练启动日志输出如下所示:
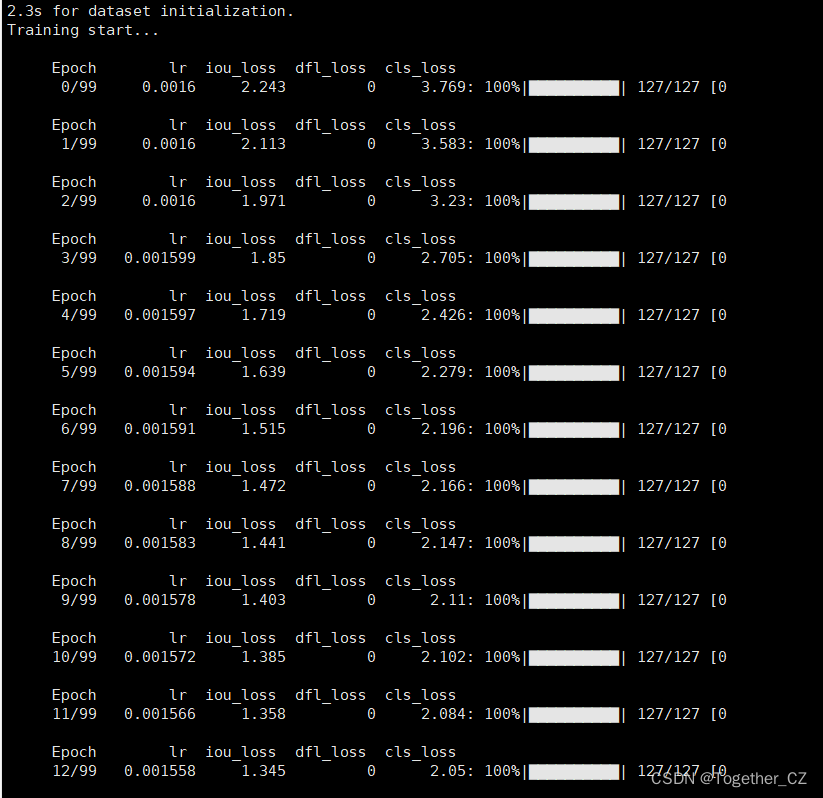
训练完成如下所示:

从终端日志可以看出来:yolov6系列模型是基于pycocotools完成评估计算的,训练完成结果详情如下所示:

一直都觉得yolov6的结果内容太薄弱了,尤其是跟yolov5相比。
weights目录如下所示:
实例推理效果如下:



感兴趣的话都可以自己动手实践下!