作者前言
🎂 ✨✨✨✨✨✨🍧🍧🍧🍧🍧🍧🍧🎂
🎂 作者介绍: 🎂🎂
🎂 🎉🎉🎉🎉🎉🎉🎉 🎂
🎂作者id:老秦包你会, 🎂
简单介绍:🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂
喜欢学习C语言和python等编程语言,是一位爱分享的博主,有兴趣的小可爱可以来互讨 🎂🎂🎂🎂🎂🎂🎂🎂
🎂个人主页::小小页面🎂
🎂gitee页面:秦大大🎂
🎂🎂🎂🎂🎂🎂🎂🎂
🎂 一个爱分享的小博主 欢迎小可爱们前来借鉴🎂
二叉树的顺序结构实现
- **作者前言**
- 小知识
- 堆的实现
- 结构体
- 插入
- 删除
- 根节点
- 长度
- 是否为空
- TOP-K问题
- 堆排序
- 总结
小知识
完全二叉树的堆的创建时间复杂度
假设我们随意给出一个长度为n的数组,如果我们要建堆,最坏的情况就是全部节点都要向下调整
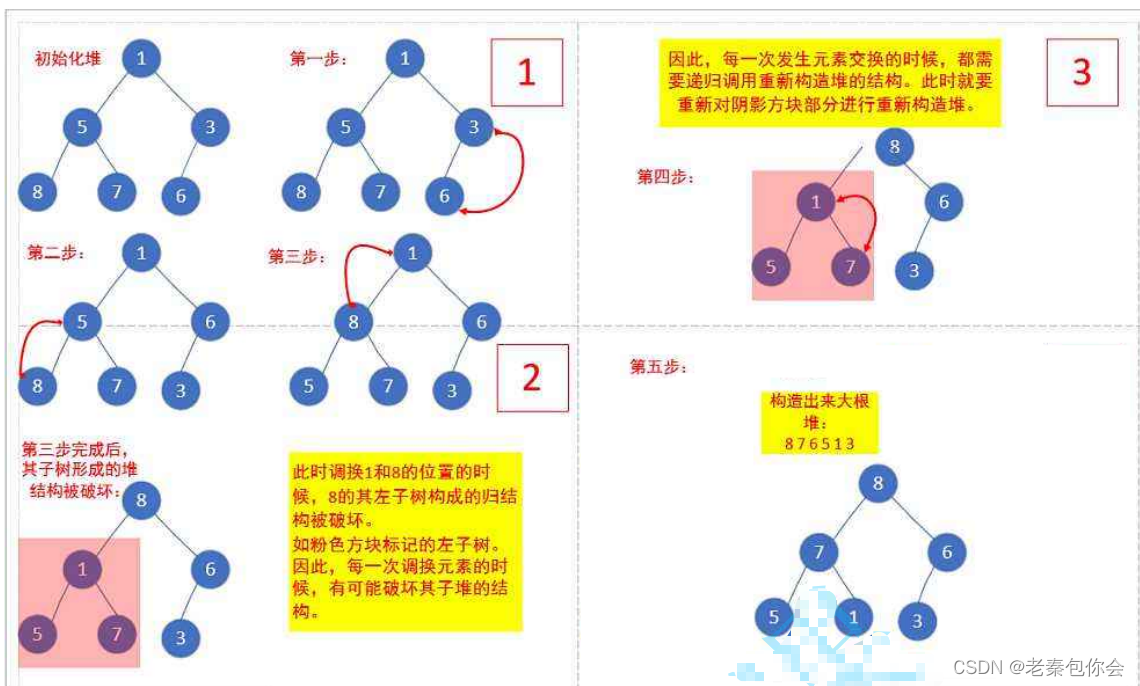
我们可以当完全二叉树是满二叉树进行计算
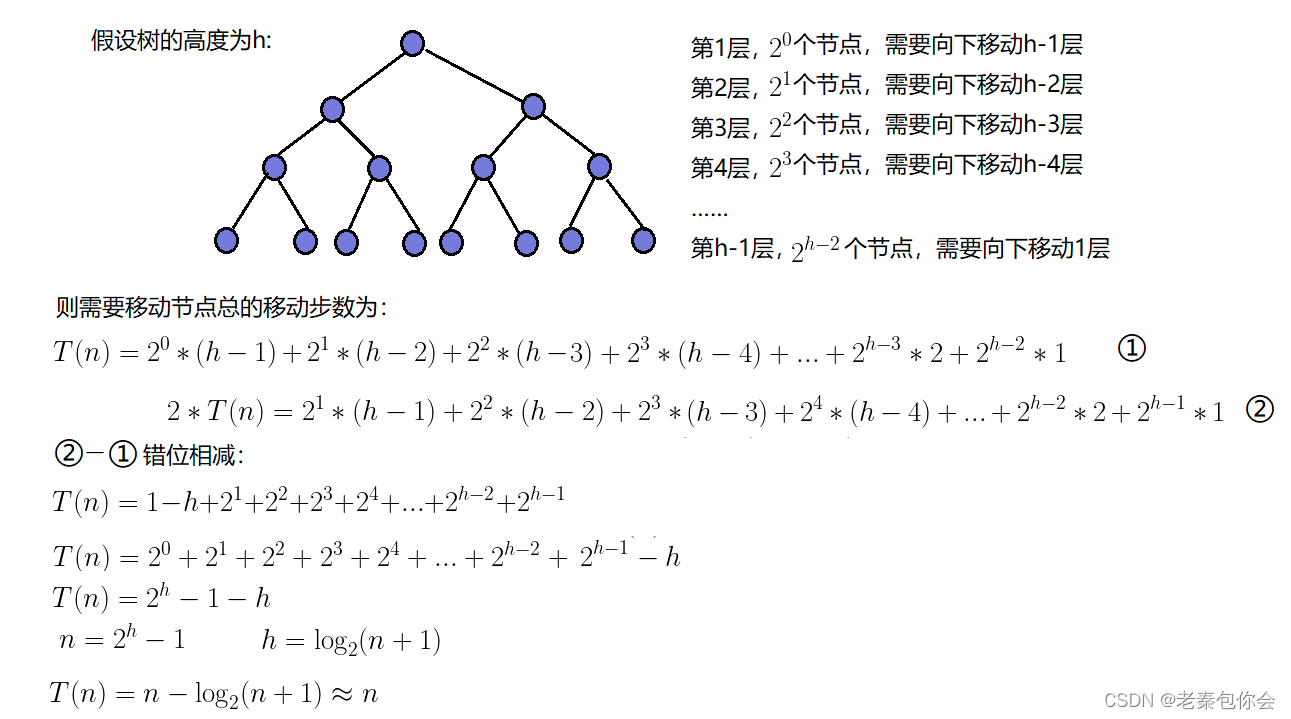
我们需要统计全部节点的移动次数,最终全部计算出 2^h -1 - h,因为是每个节点要往下移动一个高度次, 满二叉树是 的节点数 N = 2 ^h - 1 所以 h = log(N +1),代入 2^h -1 - h得出n - log(n+1) 大约就是n次 而每个节点的时间复杂度是大约是O(log(N))(每个节点向下调整高度次).这个就是向下调整的时间复杂度O(N)
向上调整的时间复杂度
二叉树的最后一层占据所有节点的一半
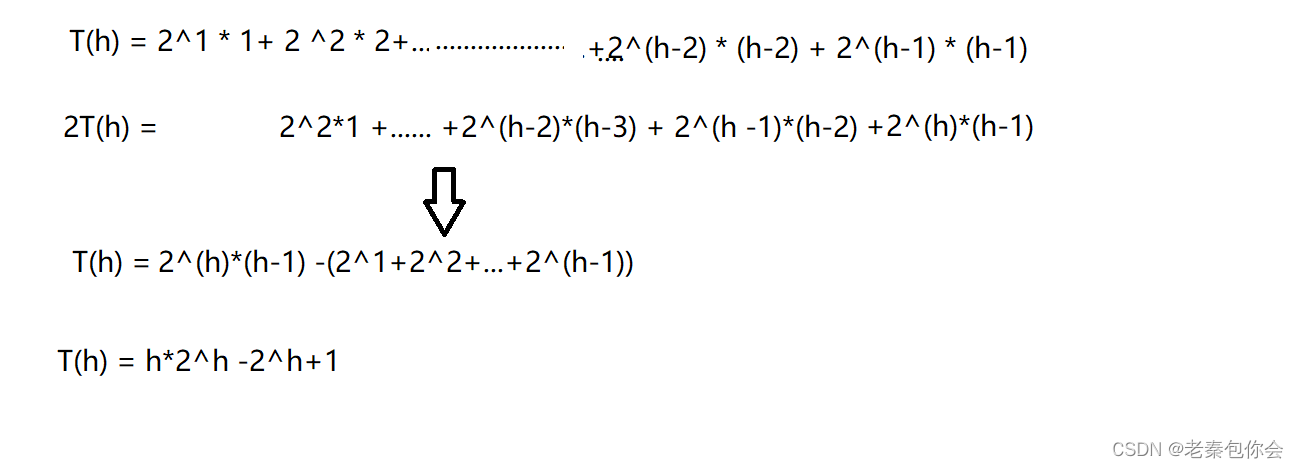
最终化简就是T(n) = (n+1)*(log(n+1) - 1) +1 -n 大概就是O(N *log(N))
堆的实现
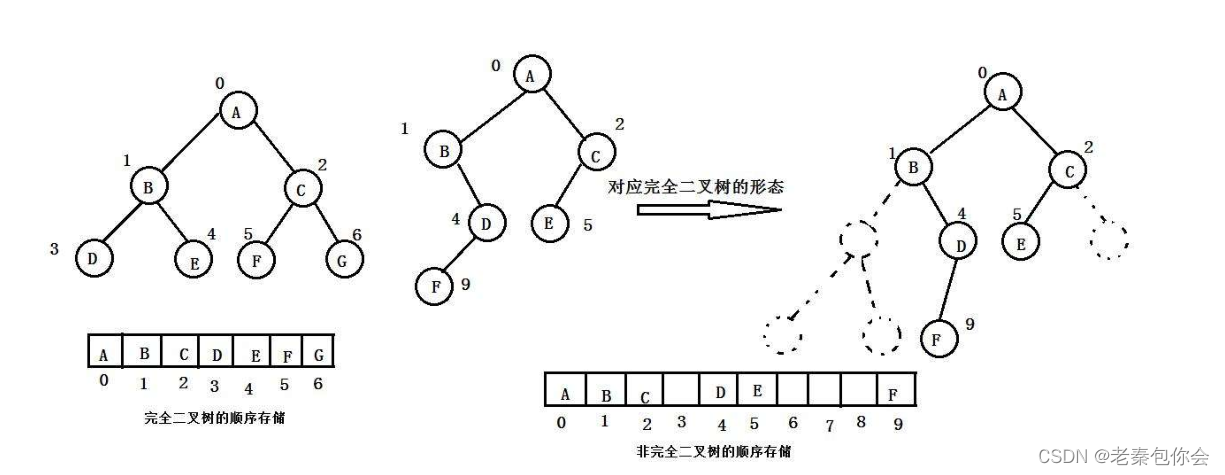
可以发现我们的要想实现二叉树就得借助顺序表来进行操作,因为二叉树是逻辑结构,我们要想实现就得利用物理结构,也就是堆 ,堆有大小堆的区分,下面我以小堆来实现
结构体

这里是利用顺序表来存储,所以结构和顺序表是一样的,但是本质上还是二叉树
typedef int HDataType;
typedef struct Heap
{
HDataType* tree;
int size;
int capacity;
}Heap;
插入
思路:我们先插入最后一个,然后向上调整,因为我们是小堆,要保证每个父亲<= 孩子
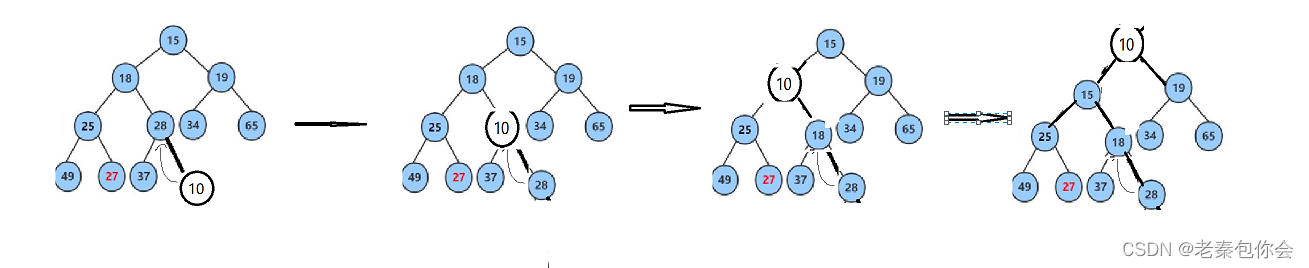
这里我们要注意不能越界,
//向上调整
void adjust(HDataType* tree, int Hsize)
{
int child = Hsize - 1;
int parent = (Hsize - 1 - 1) / 2;
while (child > 0)
{
if (tree[child] < tree[parent])
{
HDataType b = tree[child];
tree[child] = tree[parent];
tree[parent] = b;
child = parent;
parent = (child - 1) / 2;
}
else
return;
}
}
// 插入
void Heappush(Heap* obj, HDataType elemest)
{
//判断释放满
if (obj->size == obj->capacity)
{
obj->capacity = (obj->capacity == 0 ? 4 : obj->capacity * 2);
HDataType * tmp = realloc(obj->tree, sizeof(Heap) * obj->capacity);
if (tmp == NULL)
{
perror("realloc");
return;
}
obj->tree = tmp;
}
obj->tree[obj->size++] = elemest;
//开始检查是否大于父节点
adjust(obj->tree, obj->size);
}
我们主要就是考虑 根节点和自己的孩子这里,是有可能越界的
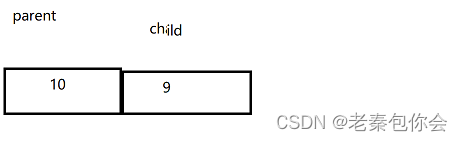
如图,可以利用child == 0来结束,
删除
这里的删除和前面我们学习过的顺序表和链表的删除不太一样,这里的删除是要删除二叉树的根节点,删除后又要构成一样的小堆
思路: 根节点和最后一个叶节点进行交换,然后删除叶节点(新的叶节点),交换后的根节点(新的根节点),然后让左右孩子进行比较大小,比较出最小值,然后再和根节点进行比较,如果根节点大于,就交换,然后依次循环直到符合小堆, 如果小于或者等于则不用调整,但是因为我们是把最后一个叶节点交换,交换的节点可能会大于等于,这种情况可以忽略,但是思路还是可以借鉴,
需要注意的是我们交换是循环进行的要找到结束条件
// 删除 (删除根节点)
void HeapPop(Heap* obj)
{
assert(obj);
assert(obj->size > 0);
//两节点交换
HDataType elemest = obj->tree[0];
obj->tree[0] = obj->tree[obj->size - 1];
obj->tree[obj->size - 1] = elemest;
obj->size--;
//向下调整
int parent = 0;
int child = parent * 2 + 1;
if (parent * 2 + 1 < obj->size && parent * 2 + 2 < obj->size && obj->tree[parent * 2 + 1] > obj->tree[parent * 2 + 2] )
{
child = parent * 2 + 2;
}
while (child < obj->size)
{
//判断孩子和父亲的大小
if (obj->tree[parent] > obj->tree[child])
{
//两节点交换
HDataType elemest = obj->tree[parent];
obj->tree[parent] = obj->tree[child];
obj->tree[child] = elemest;
parent = child;
}
else
break;
child = parent * 2 + 1;
if (parent * 2 + 1 < obj->size && parent * 2 + 2 < obj->size && obj->tree[parent * 2 + 1] > obj->tree[parent * 2 + 2])
{
child = parent * 2 + 2;
}
}
}
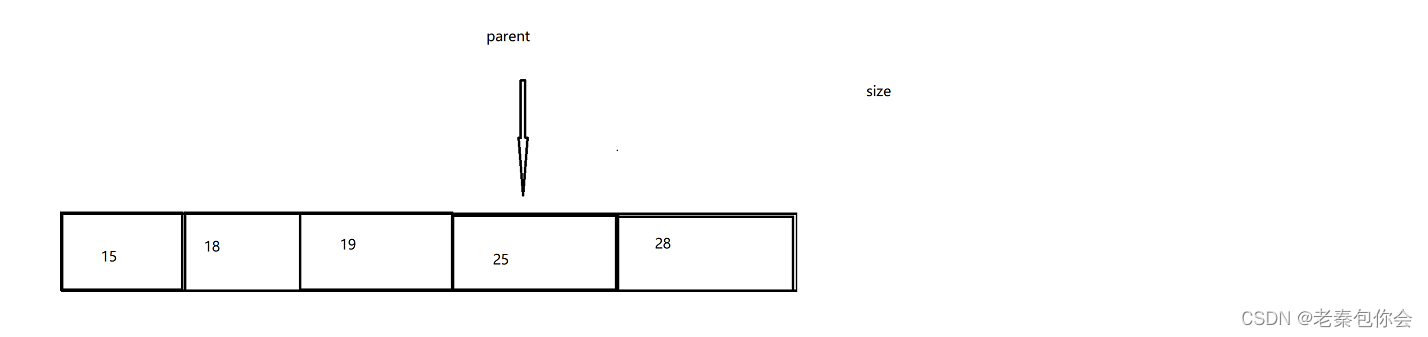
我们可以判断child是否大于等于size,,因为我们的思路就是要找到叶节点,我们只需child大于等于size就停止循环
根节点
// 根
HDataType HeapTop(Heap* obj)
{
assert(obj);
assert(obj->size > 0);
return obj->tree[0];
}
长度
// 长度
size_t HeapSize(Heap* obj)
{
assert(obj);
return obj->size;
}
是否为空
//是否为空
bool HeapEmpty(Heap* obj)
{
assert(obj);
return obj->size == 0;
}
TOP-K问题
TOP-K问题: 即求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
在N个数中找出前K个大的数(N远大于K)
- 思路: 把N个数创建成大堆,然后pop K次
这种算法的时间复杂度是 N *log(N) + K *log(N),每个节点向下调整
最终大约是O(N *log(N))
这种算法还是有差异
如果N是100亿, k = 10, 一个整形4个字节
那么我们就需要400亿字节,也就大约40G内存,我们电脑内存最多就32G,这个方法行不通 - 思路:
1.读取N个数的K个,创建一个K个数的小堆,
2.然后依次把剩下的N-K个数进行和堆顶比较,如果大于堆顶就顶替堆顶,然后向下调整形成小堆,
注意的是我们是要大于堆顶的数顶替原来的堆顶,不是让小的顶替, 我们知识借鉴了小堆的思路,并不是完全是按照小堆的思路走
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
void exchange(int *a, int *b)
{
int e = *a;
*a = *b;
*b = e;
}
void PrintTop(int n)
{
//创建一个n个数的小堆
FILE* pf = fopen("./test.txt", "r");
if (pf == NULL)
{
perror("fopen");
return 1;
}
int* Heap = (int*)malloc(sizeof(int) * n);
int i = 0;
for (i = 0; i < n; i++)
{
int elemest;
fscanf(pf, "%d", &elemest);
Heap[i] = elemest;
//向上调整
int child = i;
int parent = (child - 1) / 2;
while (child > 0)
{
if (Heap[child] < Heap[parent])
{
exchange(&Heap[child], &Heap[parent]);
}
else
break;
child = parent;
parent = (child - 1) / 2;
}
}
// 继续读取下面的数据
int ch = 0;
while ( fscanf(pf, "%d", &ch) != EOF)
{
if (ch <= Heap[0])
{
continue;
}
Heap[0] = ch;
//向下调整
int parent = 0;
int child = parent * 2 + 1;
while (child < n)
{
if (child + 1 < n && Heap[child] > Heap[child + 1])
{
child += 1;
}
if (Heap[child] < Heap[parent])
exchange(&Heap[child], &Heap[parent]);
else
break;
parent = child;
child = parent * 2 + 1;
}
}
//打印数据
for (i = 0; i < n; i++)
{
printf("%d ", Heap[i]);
}
free(Heap);
fclose(pf);
}
void random(int n)
{
FILE* pf = fopen("./test.txt", "w");
if (pf == NULL)
{
perror("fopen");
return 1;
}
srand(time(NULL));
int i = 0;
for (i = 0; i < 10000; i++)
{
fprintf(pf, "%d\n", (rand() + i) % 100000);
}
fclose(pf);
}
int main()
{
int n = 10;
PrintTop(n);
return 0;
}
上面的代码中的建堆的代码可以使用插入小堆然后进行向上调整的方法,还有一种方法是假设一棵二叉树的
左右子树都是大堆或者小堆,然后我们只需进行根节点和左右子树点进行调整
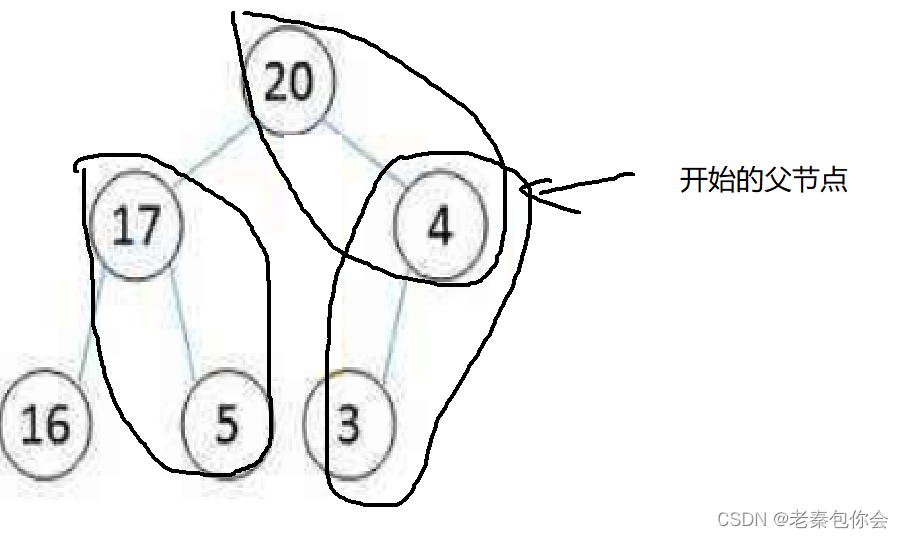
我们只需对最后叶节点的父节点开始进行向下调整,然后依次往下,
// 第二种方法
//从最后一个节点的父亲开始向下调整,我们创建的是小堆 ,
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
//向下调整
int parent = i;
int child = parent * 2 + 1;
while (child < n)
{
if (child + 1 < n && Heap[child] > Heap[child + 1])
{
child += 1;
}
if (Heap[child] < Heap[parent])
exchange(&Heap[child], &Heap[parent]);
else
break;
parent = child;
child = parent * 2 + 1;
}
}
这种算法的效率更高,第一种方法是我们慢慢学习了堆总结出来的,先插入值进堆,然后向上调整,这样很蛮烦
但是这种方法从一开始就是左右子树就是大堆或者小堆,然后只需进行根节点的向下调整就可以,这个是递归思想的一种体现
堆排序
升序排序建大堆 ,降序排序建小堆
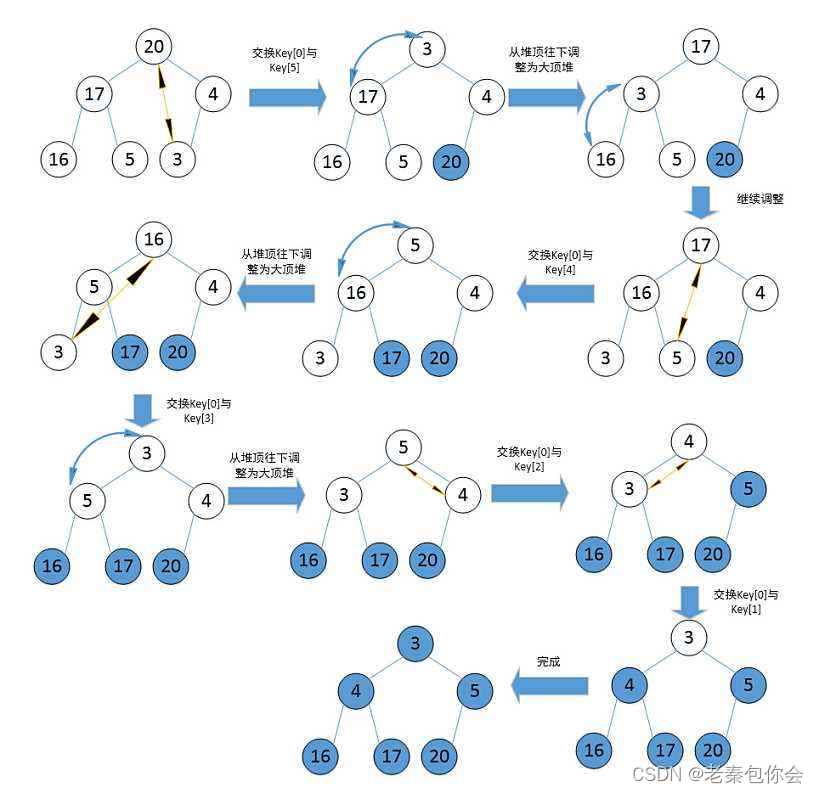
思路: 先 根节点和最后一个叶节点进行交换,这样就可以把最大的数放在数组的末尾,然后长度再减1
依次循环往下直到长度为1,或者下标为0就停止
#include<stdio.h>
typedef int Heapdata;
void exchange(Heapdata *a, Heapdata *b)
{
Heapdata e = *a;
*a = *b;
*b = e;
}
void Heapsort(Heapdata* heap, int size)
{
//建大堆
int i = 0;
for (i = 1; i < size; i++)
{
//向上调整
int child = i;
int parent = (child - 1) / 2;
while (child > 0)
{
if (heap[child] > heap[parent])
{
//交换
exchange(&heap[child], &heap[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
break;
}
}
//开始升序排序
while (size > 0)
{
// 根节点和最后一个叶节点交换
exchange(&heap[0], &heap[--size]);
//向下调整
int parent = 0;
int child = parent * 2 + 1;
while (child < size)
{
if (child + 1 < size && heap[child] < heap[child + 1])
{
child += 1;
}
if (heap[child] > heap[parent])
exchange(&heap[child], &heap[parent]);
else
break;
parent = child;
child = parent * 2 + 1;
}
}
}
int main()
{
Heapdata a[] = { 2,1,48,5,2,4,7,5,63,8 };
int size = sizeof(a) / sizeof(a[0]);
//堆排序
Heapsort(a, size);
return 0;
}
总结
这里简单介绍了堆 堆排序和Top K问题,还介绍了向下调整的时间复杂度和向上调整的时间复杂度