这是DDD&微服务系列的第17篇,欢迎持续关注~
概述
在软件开发过程中,我们经常会遇到需要生成全局唯一流水号的场景,例如各种流水号和分库分表的分布式主键ID。特别是在使用MySQL数据库时,除了要求流水号具有“全局唯一”性外,还需要具备“递增趋势”,以减少MySQL的数据页分裂,从而降低数据库IO压力并提升服务器性能。
因此,在项目中通常需要引入一种算法,能够生成满足“全局唯一”、“递增趋势”和“高性能”要求的数据。
关于全局分布式ID的生成,网上有很多相关文章。其中最常见的方法是借助第三方开源组件实现,如百度开源的Uidgenerator、滴滴开源的TinyID、美团开源的Leaf以及雪花算法SnowFlake等。然而,大部分开源组件都需要依赖数据库或Redis中间件来实现,对于非特大型项目来说可能过于繁重。因此,我更倾向于在项目中使用雪花算法SnowFlake来生成全局唯一ID。
标准版雪花算法网上已经有很多解读文章了,此处就不再赘述了。
然而,标准版的雪花算法存在 时钟敏感 问题。由于ID生成与当前操作系统时间戳绑定(利用了时间的单调递增性),当操作系统的时钟出现回拨时,生成的ID可能会重复(尽管通常不会人为地回拨时钟,但服务器可能会出现偶发的“时钟漂移”现象)。为了解决这个问题,我们可以在获取 ID 时记录当前的时间戳。然后在下一次获取 ID 时,比较当前时间戳和上次记录的时间戳。如果发现当前时间戳小于上次记录的时间戳,说明出现了时钟回拨现象,此时可以拒绝服务并等待时间戳追上记录值。
因此,在项目中我们不能直接使用标准版的雪花算法,而需要寻找一个改良后的方案。
这里我推荐大家使用开源分布式事务处理组件Seata的改良方案,它完美的解决了雪花算法时钟敏感的问题,并且代码简洁,可以非常方便集成在你项目中。
下面让我们来分析一下Seata改进后的方案。
Seata的优化方案
在原版雪花算法中,分布式ID的格式是这样的。
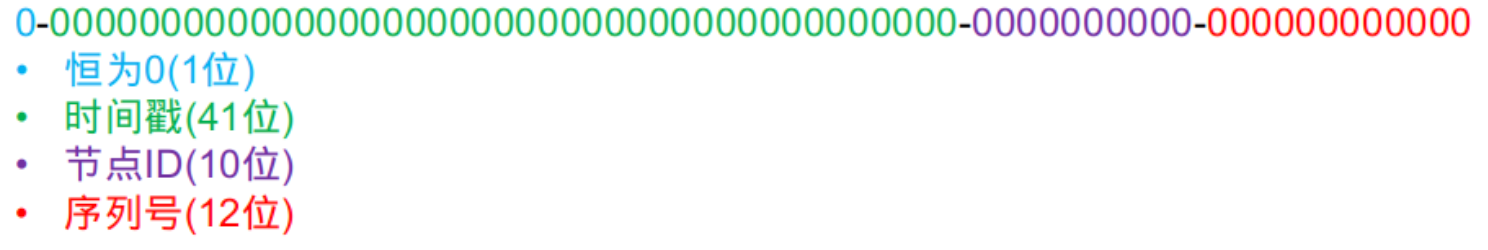
雪花算法主要是利用时间的单调递增特性,并且与操作系统的时间戳时刻绑定,一旦出现时间“回退”,则打破了时间 “单调递增”这个前提,所以可能会出现重复。
而在改良后的Seata方案中,其ID格式是这样的。

通过观察Seata代码,我们可以发现它只是简单地调整了节点ID和时间戳的位置。那么这样做的目的是什么呢?
答案是通过这种方式解除了算法与操作系统时间戳的强绑定关系。生成器仅在初始化时获取系统时间戳作为初始时间戳,之后不再与系统时间戳同步。生成器的递增仅由序列号的递增驱动。例如,当序列号的当前值达到4095时,下一个请求到来时,序列号将溢出12位空间并重新归零,同时溢出的进位将加到时间戳上,使时间戳+1。因此,时间戳和序列号实际上可以视为一个整体。
这样,时间戳和序列号在内存中是连续存储的,可以使用一个AtomicLong来同时保存它们。下面是相关核心代码的示例:
/**
* timestamp and sequence mix in one Long
* highest 11 bit: not used
* middle 41 bit: timestamp
* lowest 12 bit: sequence
*/
private AtomicLong timestampAndSequence;
/**
* The number of bits occupied by sequence
*/
private final int sequenceBits = 12;
/**
* init first timestamp and sequence immediately
*/
private void initTimestampAndSequence() {
long timestamp = getNewestTimestamp();
long timestampWithSequence = timestamp << sequenceBits;
this.timestampAndSequence = new AtomicLong(timestampWithSequence);
}
代码解释:
在初始化方法中,获取当前时间戳
getNewestTimestamp()以后将其左移12位,留出了序列号的位置。而Long类型转化成二进制以后是64位,前11位不使用,中间的41位代表时间戳,后面的12位代表序列号。
最高11位在初始化时就直接确定好,之后不再变化,核心代码如下:
/**
* init workerId
* @param workerId if null, then auto generate one
*/
private void initWorkerId(Long workerId) {
if (workerId == null) {
workerId = generateWorkerId();
}
if (workerId > maxWorkerId || workerId < 0) {
String message = String.format("worker Id can't be greater than %d or less than 0", maxWorkerId);
throw new IllegalArgumentException(message);
}
this.workerId = workerId << (timestampBits + sequenceBits);
}
/**
* auto generate workerId, try using mac first, if failed, then randomly generate one
* @return workerId
*/
private long generateWorkerId() {
try {
return generateWorkerIdBaseOnMac();
} catch (Exception e) {
return generateRandomWorkerId();
}
}
/**
* use lowest 10 bit of available MAC as workerId
* @return workerId
* @throws Exception when there is no available mac found
*/
private long generateWorkerIdBaseOnMac() throws Exception {
Enumeration<NetworkInterface> all = NetworkInterface.getNetworkInterfaces();
while (all.hasMoreElements()) {
NetworkInterface networkInterface = all.nextElement();
boolean loopBack = networkInterface.isLoopback();
boolean isVirtual = networkInterface.isVirtual();
if (loopBack || isVirtual) {
continue;
}
byte[] mac = networkInterface.getHardwareAddress();
return ((mac[4] & 0B11) << 8) | (mac[5] & 0xFF);
}
throw new RuntimeException("no available mac found");
}
代码解读:
算法规定了节点ID最长为10位,2的10次方是1024,所以可以服务1024台机器,体现在数字上的取值范围是为[0,1023);
在原版雪花算法中,如果未指定节点ID,会截取本地IPv4地址的低10位作为节点ID,这样在生成实践中如果出现IP的第4个字节和第3个字节的低2位一样就会重复。如:192.168.4.10 和 192.168.8.10
新版算法generateWorkerIdBaseOnMac()是从从本机网卡的MAC地址截取低10位,最后通过(mac[4] & 0B11) << 8) | (mac[5] & 0xFF)保证其取值范围最大值为1023,算法有点难懂,分步解释:
mac[4]和mac[5]是无符号8位整数的变量,其取值范围是[0,255)
(mac[4] & 0B11)运算会保留mac[4]的最后两位00,01,10,11,也就是取值范围为 0 到 3。
(mac[4] & 0B11) << 8。左移 8 位相当于乘以 256,所以结果的取值范围是 0 到 3 * 256 = 0 到 768。
(mac[5] & 0xFF)最大值就是0xFF, 也就是取值范围是 0 到 255所以最后结果的取值范围是从 0 到 768 | 255 = 1023。
计算出节点ID以后,将其左移,this.workerId = workerId << (timestampBits + sequenceBits),这样就完成了算法ID的组装。
最后看看生成ID的算法
private final int timestampBits = 41;
private final int sequenceBits = 12;
private final long timestampAndSequenceMask = ~(-1L << (timestampBits + sequenceBits));
public long nextId() {
// 获得递增后的时间戳和序列号
long next = timestampAndSequence.incrementAndGet();
// 截取低53位
long timestampWithSequence = next & timestampAndSequenceMask;
// 跟先前保存好的高11位进行一个或的位运算
return workerId | timestampWithSequence;
}
看完Seata雪花算法的实现逻辑,你觉得怎么样呢? 反正我只会直呼 ”卧槽,牛皮“~
通过对Seata改良算法代码的解读,可以知道,算法生成器仅在启动时获取了一次系统时钟,可以说是弱依赖于操作系统时钟,这样在运行期间,生成器不再受时钟回拨的影响。
同时由于序列号有12位,最大取值范围是[0,4095]。
如果在当前毫秒下序列号生成到了 4096 ,这个时候序列号回重新归0,同时让时间戳+1,也就是 "借用"下一个时间戳的序列号空间,这种超前消费会不会导致生成器内的时间戳大大超前于系统的时间戳,从而导致重启时ID重复呢?
理论上有,实际上并不会。因为要达到这个效果,也就意味着生成器的QPS得持续稳定在4096/ms,约400W/s之上,这得什么场景才能有这样的流量呢?就算有了,瓶颈一定不在生成器这里。
通过对Seata改良算法代码的解读,我们可以了解到算法生成器仅在启动时获取一次系统时钟,因此它在运行期间对操作系统时钟的依赖相对较弱。这意味着生成器不会受到时钟回拨的影响。
此外,根据序列号的位数为12位,其取值范围为[0, 4095]。
如果在当前毫秒内序列号生成到了4096,这时序列号会重新归0,并且时间戳会增加1,即"借用"下一个时间戳的序列号空间。这种超前消费是否会导致生成器内部的时间戳大大超前于系统的时间戳,从而导致在重启时出现重复的ID呢?
理论上来说,这种情况是有可能发生的。然而,在实际情况下并不会出现这种问题。因为要达到这种效果,也就意味着生成器的每秒请求数(QPS)需要持续稳定在4096次以上,相当于每秒处理约400万个请求。这样高的流量场景是非常罕见的,而且即使存在这样的流量,天塌下来有高个子顶着,一定会是其他组件先出问题。
Seata雪花算法的 “缺陷”
经过观察,我们可以发现一个问题:Seata改良版的算法在单节点内部确实是单调递增的,但是在多实例部署时,它不再保证全局单调递增。这是因为节点ID在生成的ID中占据了高位,因此节点ID较大的生成的ID一定大于节点ID较小的生成的ID,与它们的生成时间先后顺序无关。
相比之下,原版雪花算法将时间戳放在高位,并且始终追随系统时钟,可以确保早期生成的ID小于后期生成的ID。只有当两个节点恰好在同一时间戳生成ID时,两个ID的大小才由节点ID决定。
从这个角度来看,新版算法是否存在问题呢?
关于这个问题,官方已经给出了结论:
新版算法的确不具备全局的单调递增性,但这不影响我们的初衷(减少数据库的页分裂)。这个结论看起来有点违反直觉,但可以被证明。
现在让我们来进一步优化和解释这个结论。
B+树原理
在证明之前我们需要先回顾一下数据库页分裂的相关知识(基于B+数索引的MySQL InnoDB引擎)。
在B+树索引中,主键索引的叶子节点除了保存键的值之外,还保存了数据行的完整记录。叶子节点之间以双向链表的形式连接在一起。叶子节点在物理存储上被组织为数据页,每个数据页最多可以存储N条行记录。
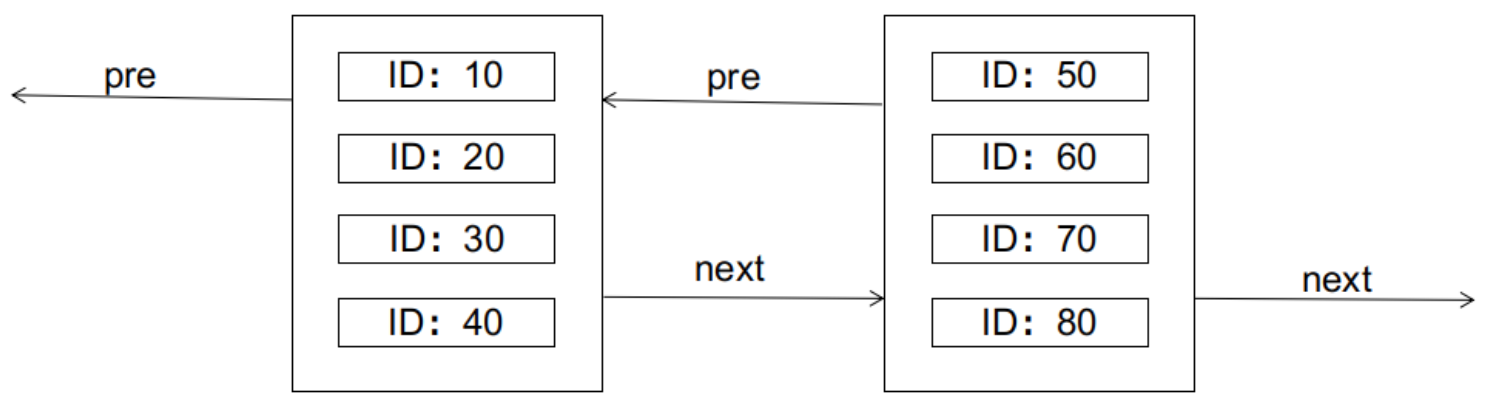
B+树的特性要求左边的节点的键值小于右边节点的键值。如果现在要插入一条ID为25的记录,会发生什么呢?(假设每个数据页只能容纳4条记录)答案是会导致页分裂,如下图所示:
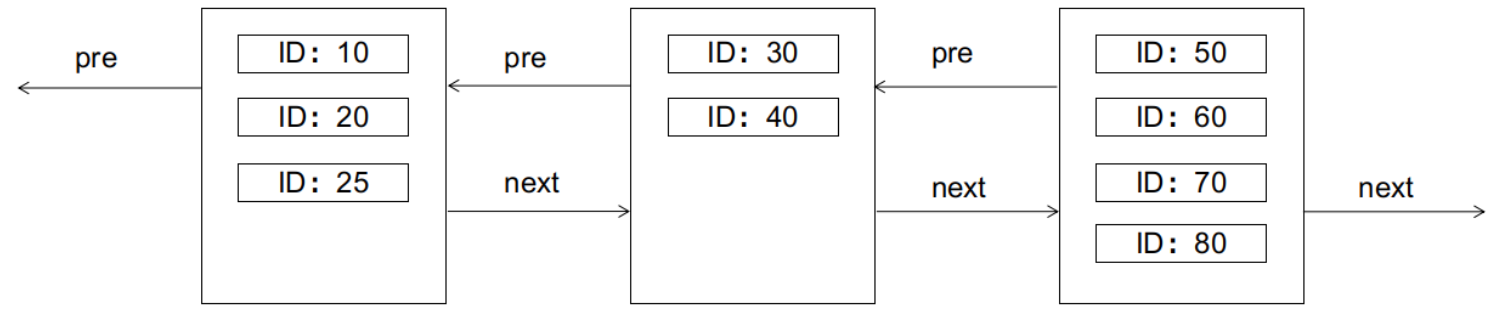
页分裂对IO操作不友好,需要创建新的数据页,并复制和转移旧数据页中的部分记录。因此,我们应该尽量避免页分裂的发生。
如果你想直观地了解B+树节点分裂的过程,建议访问以下网站:
B+ Tree Visualization -> https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
理想的情况下,主键ID最好是顺序递增的(例如把主键设置为auto_increment),这样就只会在当前数据页放满了的时候,才需要新建下一页,双向链表永远是顺序尾部增长的,不会有中间的节点发生分裂的情况。
最糟糕的情况下,主键ID是随机无序生成的(例如java中一个UUID字符串),这种情况下,新插入的记录会随机分配到任何一个数据页,如果该页已满,就会触发页分裂。
如果主键ID由标准版雪花算法生成,最好的情况下,是每个时间戳内只有一个节点在生成ID,这时候算法的效果等同于理想情况的顺序递增,即跟auto_increment无差。最坏的情况下,是每个时间戳内所有节点都在生成ID,这时候算法的效果接近于无序(但仍比UUID的完全无序要好得多,因为workerId只有10位决定了最多只有1024个节点)。实际生产中,算法的效果取决于业务流量,并发度越低,算法越接近理想情况。
在理想情况下,主键ID最好是按顺序递增的(例如使用auto_increment设置主键),这样只有在当前数据页已满时才需要创建下一页,双向链表的增长总是在尾部进行的,不会导致中间节点的分裂。
在最糟糕的情况下,主键ID是随机无序生成的(例如在Java中使用UUID字符串),这种情况下,新插入的记录会被随机分配到任意一个数据页,如果该页已满,则触发页分裂。
这也是为什么不推荐使用UUID作为主键ID的原因,UUID会导致频繁出现页裂变,影响数据库性能。
如果主键ID由标准版雪花算法生成,最理想的情况是每个时间戳内只有一个节点生成ID,这种情况下算法的效果与理想情况的顺序递增相同,即与auto_increment没有区别。最糟糕的情况是每个时间戳内的所有节点都在生成ID,这种情况下算法的效果接近于无序(但仍比完全无序的UUID要好得多,因为workerId只有10位,限制了节点数量最多为1024个)。在实际生产环境中,算法的效果取决于业务流量,较低的并发度会使算法接近理想情况。
那么,Seata改良版的雪花算法又是如何呢?
Seata 改良算法会导致频繁页裂变吗?
新版算法从全局角度来看,生成的ID是无序的。然而,对于每个节点而言,它所生成的ID序列是严格单调递增的。由于节点ID是有限的,因此最多可以划分出1024个子序列,每个子序列都是单调递增的。
对于数据库而言,在初始阶段接收到的ID可能是无序的,来自各个子序列的ID会混合在一起。假设节点ID的值是递增的,初始阶段的效果如下图所示:
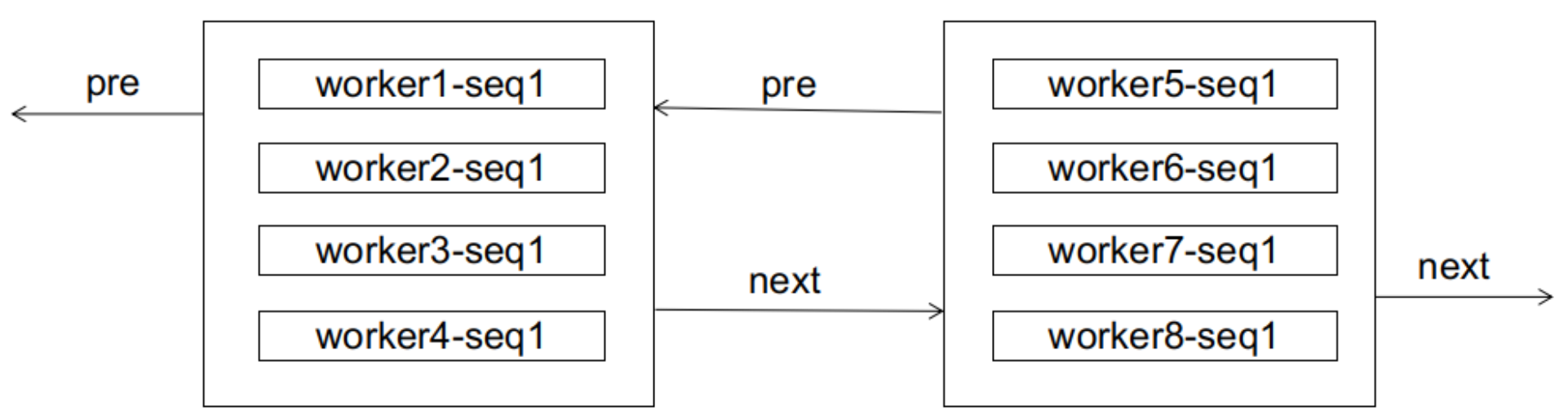
假设此时出现了一个worker1-seq2的ID,由于数据页已经存满,会触发一次页分裂,如下图所示:
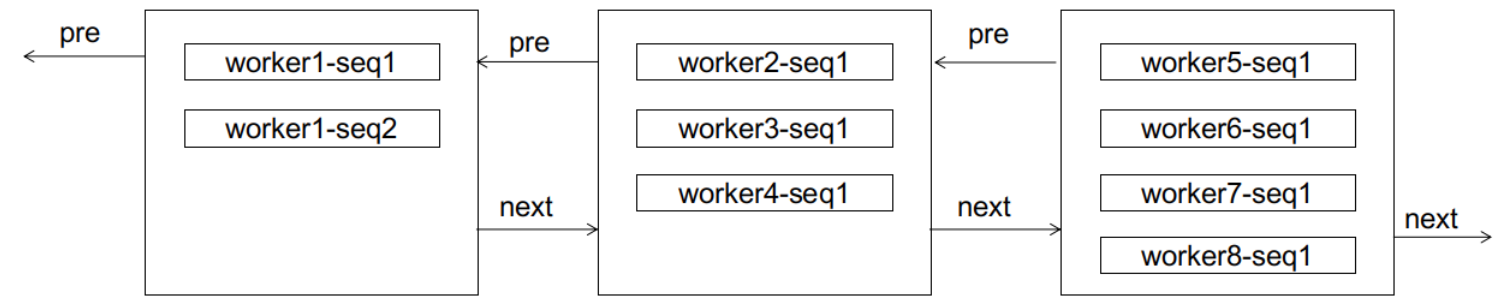
然而,分裂之后发生了一件有趣的事情。对于worker1而言,后续的seq3、seq4由于可以直接放入数据页,不会再触发页分裂。而seq5只需要像顺序递增一样,在新建的页中进行链接。值得注意的是,由于worker1的后续ID都比worker2的ID小,它们不会被分配到worker2及其之后的节点,因此不会导致后续节点的页分裂。同样地,由于是单调递增,它们也不会被分配到worker1当前节点的前面,因此不会导致前面节点的页分裂。
在这里,我们称具有这种性质的子序列达到了稳态,意味着该子序列已经"稳定"下来,其后续增长只会发生在子序列的尾部,而不会引起其他节点的页分裂。同样的情况也可以推广到其他子序列上。无论初始阶段数据库接收到的ID有多么混乱,在有限次页分裂之后,双向链表总能达到这样一个稳定的终态:
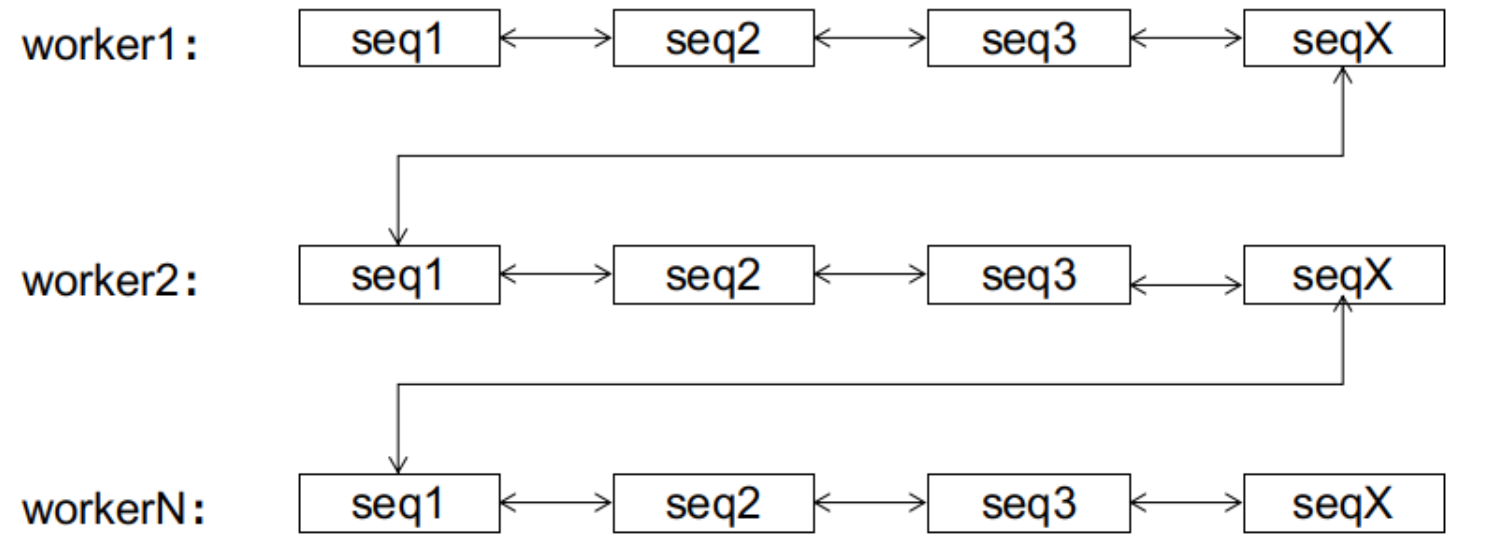
到达终态后,后续的ID只会在该ID所属的子序列上进行顺序增长,而不会造成页分裂。
该状态下的顺序增长与auto_increment的顺序增长的区别是,前者有1024个增长位点(各个子序列的尾部),后者只有尾部一个。
小结
综上所述,改进版的雪花算法虽然不具备全局单调递增的特性,但在同一节点下能够保持单调递增。此外,经过几次数据页分裂后,它会达到一个稳定状态,不会频繁触发数据库的页分裂。同时,该算法仍然满足高性能和全局唯一的要求。因此,完全可以将改进版的雪花算法引入到项目中使用。
然而,需要注意的是,在实际业务系统中,最好将此算法应用于那些需要长期保存数据的场景,而对于需要频繁删除的表则不太适用。
这是因为该算法利用前期的页分裂,逐渐将不同子序列分离,从而实现算法的收敛到稳定状态。如果频繁删除数据,会触发数据库的页合并操作,这会阻碍数据的收敛。在极端情况下,刚刚分离的数据可能会立即发生页合并,导致数据无法保持稳定状态。因此,在使用改进版的雪花算法时需要谨慎考虑业务需求和数据操作的频率。
DailyMart集成全局ID算法
DailyMart项目中涉及到多个场景需要使用全局唯一ID,因此我已经将Seata改进版的雪花算法通过自定义Starter的方式集成到了项目中。使用时只需要调用IdUtils.nextId()方法即可获取全局唯一ID,你可以参考源代码进行具体实现。
同时,之前的文章中提到了在使用Mybatis-Plus时,由于没有正确配置worker-id和datacenter-id参数,导致生成的ID可能会出现重复。基于此我还在datasources公共模块中替换了Mybatis-Plus的ID生成算法,使用了Seata改进后的雪花算法。
以下为代码具体实现:
public class CustomIdGenerator implements IdentifierGenerator {
@Override
public Number nextId(Object entity) {
return IdUtils.nextId();
}
}
/**
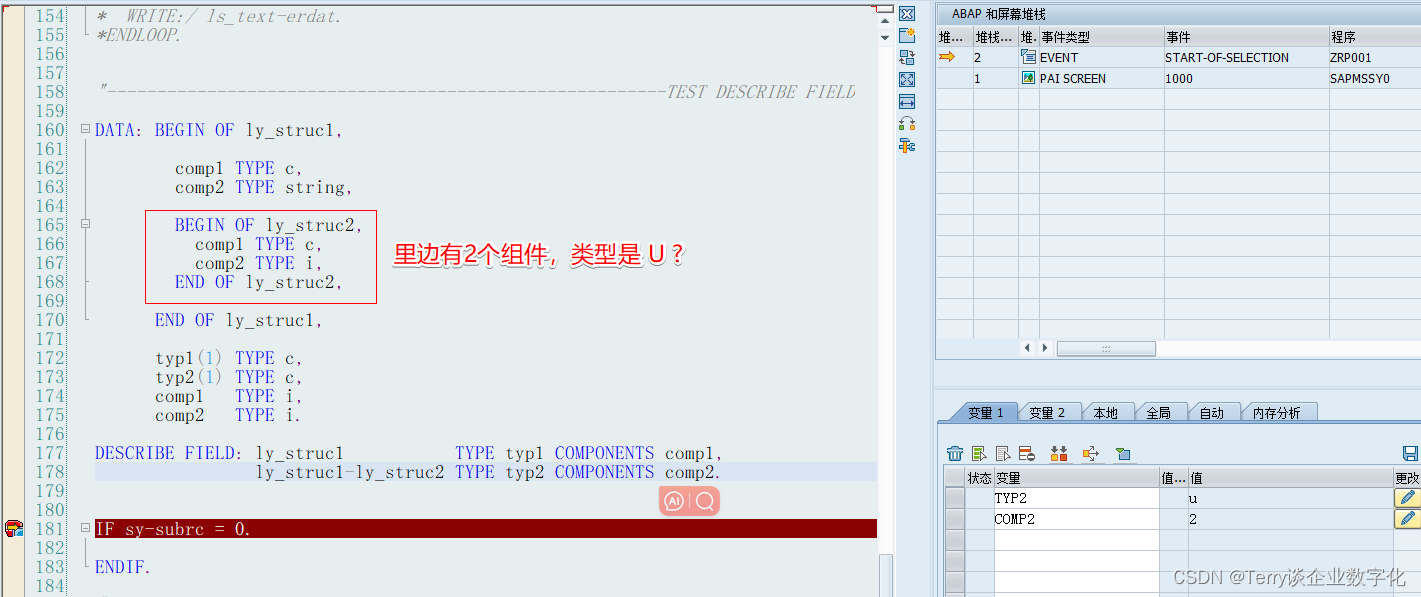
* 替换Mybatis-plus的算法生成器
*/
@Bean
public IdentifierGenerator identifierGenerator() {
return new CustomIdGenerator();
}
DailyMart是一个DDD 和 Spring Cloud Alibaba的微服务商城系统,同时在该系列中还会整合博主其他专栏的精华文章。如果你对这两大技术栈感兴趣,可以在公众号 JAVA日知录 回复关键词 DDD 以获取相关源码。