大型语言模型(llm)已经彻底改变了自然语言处理领域。随着这些模型在规模和复杂性上的增长,推理的计算需求也显著增加。为了应对这一挑战利用多个gpu变得至关重要。

所以本文将在多个gpu上并行执行推理,主要包括:Accelerate库介绍,简单的方法与工作代码示例和使用多个gpu的性能基准测试。
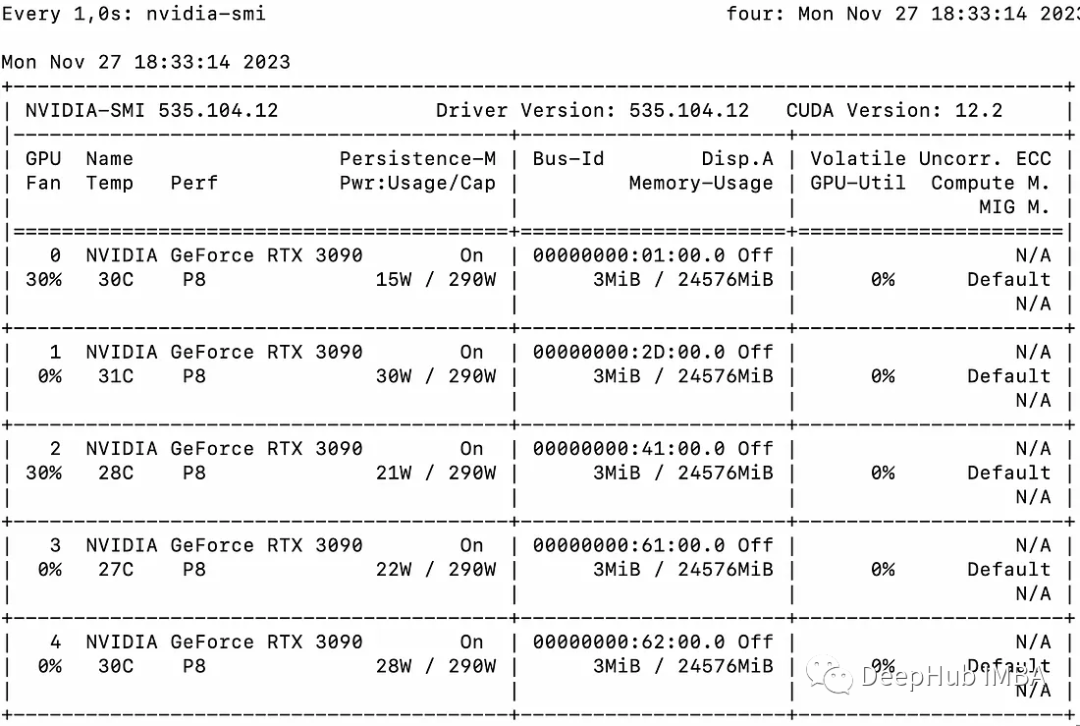
本文将使用多个3090将llama2-7b的推理扩展在多个GPU上
基本示例
我们首先介绍一个简单的示例来演示使用Accelerate进行多gpu“消息传递”。
from accelerate import Accelerator
from accelerate.utils import gather_object
accelerator = Accelerator()
# each GPU creates a string
message=[ f"Hello this is GPU {accelerator.process_index}" ]
# collect the messages from all GPUs
messages=gather_object(message)
# output the messages only on the main process with accelerator.print()
accelerator.print(messages)
输出如下:
['Hello this is GPU 0',
'Hello this is GPU 1',
'Hello this is GPU 2',
'Hello this is GPU 3',
'Hello this is GPU 4']
多GPU推理
下面是一个简单的、非批处理的推理方法。代码很简单,因为Accelerate库已经帮我们做了很多工作,我们直接使用就可以:
from accelerate import Accelerator
from accelerate.utils import gather_object
from transformers import AutoModelForCausalLM, AutoTokenizer
from statistics import mean
import torch, time, json
accelerator = Accelerator()
# 10*10 Prompts. Source: https://www.penguin.co.uk/articles/2022/04/best-first-lines-in-books
prompts_all=[
"The King is dead. Long live the Queen.",
"Once there were four children whose names were Peter, Susan, Edmund, and Lucy.",
"The story so far: in the beginning, the universe was created.",
"It was a bright cold day in April, and the clocks were striking thirteen.",
"It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife.",
"The sweat wis lashing oafay Sick Boy; he wis trembling.",
"124 was spiteful. Full of Baby's venom.",
"As Gregor Samsa awoke one morning from uneasy dreams he found himself transformed in his bed into a gigantic insect.",
"I write this sitting in the kitchen sink.",
"We were somewhere around Barstow on the edge of the desert when the drugs began to take hold.",
] * 10
# load a base model and tokenizer
model_path="models/llama2-7b"
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map={"": accelerator.process_index},
torch_dtype=torch.bfloat16,
)
tokenizer = AutoTokenizer.from_pretrained(model_path)
# sync GPUs and start the timer
accelerator.wait_for_everyone()
start=time.time()
# divide the prompt list onto the available GPUs
with accelerator.split_between_processes(prompts_all) as prompts:
# store output of generations in dict
results=dict(outputs=[], num_tokens=0)
# have each GPU do inference, prompt by prompt
for prompt in prompts:
prompt_tokenized=tokenizer(prompt, return_tensors="pt").to("cuda")
output_tokenized = model.generate(**prompt_tokenized, max_new_tokens=100)[0]
# remove prompt from output
output_tokenized=output_tokenized[len(prompt_tokenized["input_ids"][0]):]
# store outputs and number of tokens in result{}
results["outputs"].append( tokenizer.decode(output_tokenized) )
results["num_tokens"] += len(output_tokenized)
results=[ results ] # transform to list, otherwise gather_object() will not collect correctly
# collect results from all the GPUs
results_gathered=gather_object(results)
if accelerator.is_main_process:
timediff=time.time()-start
num_tokens=sum([r["num_tokens"] for r in results_gathered ])
print(f"tokens/sec: {num_tokens//timediff}, time {timediff}, total tokens {num_tokens}, total prompts {len(prompts_all)}")
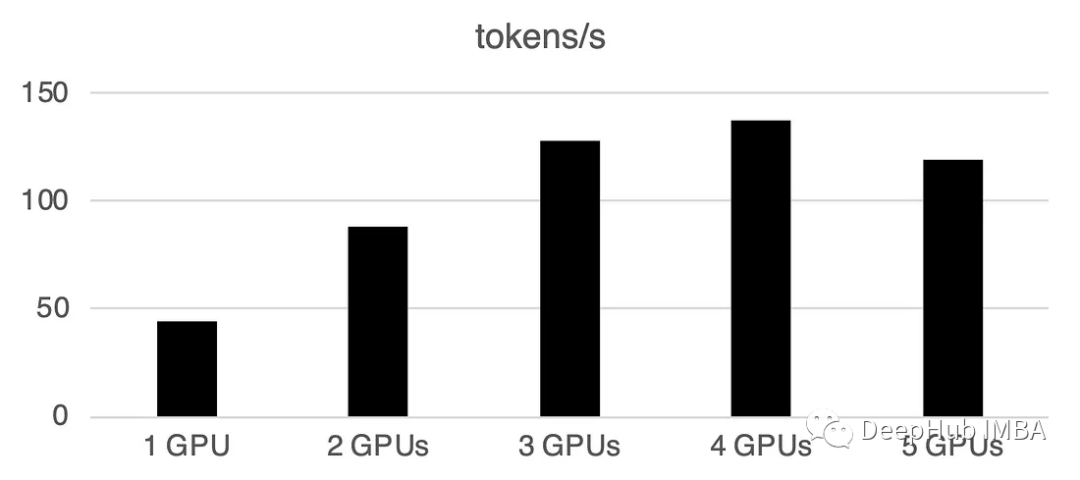
使用多个gpu会导致一些通信开销:性能在4个gpu时呈线性增长,然后在这种特定设置中趋于稳定。当然这里的性能取决于许多参数,如模型大小和量化、提示长度、生成的令牌数量和采样策略,所以我们只讨论一般的情况
1 GPU: 44个token /秒,时间:225.5s
2 gpu: 88个token /秒,时间:112.9s
3 gpu: 128个token /秒,时间:77.6s
4 gpu: 137个token /秒,时间:72.7s
5 gpu: 119个token /秒,时间:83.8s
在多GPU上进行批处理
现实世界中,我们可以使用批处理推理来加快速度。这会减少GPU之间的通讯,加快推理速度。我们只需要增加prepare_prompts函数将一批数据而不是单条数据输入到模型即可:
from accelerate import Accelerator
from accelerate.utils import gather_object
from transformers import AutoModelForCausalLM, AutoTokenizer
from statistics import mean
import torch, time, json
accelerator = Accelerator()
def write_pretty_json(file_path, data):
import json
with open(file_path, "w") as write_file:
json.dump(data, write_file, indent=4)
# 10*10 Prompts. Source: https://www.penguin.co.uk/articles/2022/04/best-first-lines-in-books
prompts_all=[
"The King is dead. Long live the Queen.",
"Once there were four children whose names were Peter, Susan, Edmund, and Lucy.",
"The story so far: in the beginning, the universe was created.",
"It was a bright cold day in April, and the clocks were striking thirteen.",
"It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife.",
"The sweat wis lashing oafay Sick Boy; he wis trembling.",
"124 was spiteful. Full of Baby's venom.",
"As Gregor Samsa awoke one morning from uneasy dreams he found himself transformed in his bed into a gigantic insect.",
"I write this sitting in the kitchen sink.",
"We were somewhere around Barstow on the edge of the desert when the drugs began to take hold.",
] * 10
# load a base model and tokenizer
model_path="models/llama2-7b"
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map={"": accelerator.process_index},
torch_dtype=torch.bfloat16,
)
tokenizer = AutoTokenizer.from_pretrained(model_path)
tokenizer.pad_token = tokenizer.eos_token
# batch, left pad (for inference), and tokenize
def prepare_prompts(prompts, tokenizer, batch_size=16):
batches=[prompts[i:i + batch_size] for i in range(0, len(prompts), batch_size)]
batches_tok=[]
tokenizer.padding_side="left"
for prompt_batch in batches:
batches_tok.append(
tokenizer(
prompt_batch,
return_tensors="pt",
padding='longest',
truncation=False,
pad_to_multiple_of=8,
add_special_tokens=False).to("cuda")
)
tokenizer.padding_side="right"
return batches_tok
# sync GPUs and start the timer
accelerator.wait_for_everyone()
start=time.time()
# divide the prompt list onto the available GPUs
with accelerator.split_between_processes(prompts_all) as prompts:
results=dict(outputs=[], num_tokens=0)
# have each GPU do inference in batches
prompt_batches=prepare_prompts(prompts, tokenizer, batch_size=16)
for prompts_tokenized in prompt_batches:
outputs_tokenized=model.generate(**prompts_tokenized, max_new_tokens=100)
# remove prompt from gen. tokens
outputs_tokenized=[ tok_out[len(tok_in):]
for tok_in, tok_out in zip(prompts_tokenized["input_ids"], outputs_tokenized) ]
# count and decode gen. tokens
num_tokens=sum([ len(t) for t in outputs_tokenized ])
outputs=tokenizer.batch_decode(outputs_tokenized)
# store in results{} to be gathered by accelerate
results["outputs"].extend(outputs)
results["num_tokens"] += num_tokens
results=[ results ] # transform to list, otherwise gather_object() will not collect correctly
# collect results from all the GPUs
results_gathered=gather_object(results)
if accelerator.is_main_process:
timediff=time.time()-start
num_tokens=sum([r["num_tokens"] for r in results_gathered ])
print(f"tokens/sec: {num_tokens//timediff}, time elapsed: {timediff}, num_tokens {num_tokens}")
可以看到批处理会大大加快速度。
1 GPU: 520 token /sec,时间:19.2s
2 gpu: 900 token /sec,时间:11.1s
3 gpu: 1205个token /秒,时间:8.2s
4 gpu: 1655 token /sec,时间:6.0s
5 gpu: 1658 token /sec,时间:6.0s

总结
截止到本文为止,llama.cpp,ctransformer还不支持多GPU推理,好像llama.cpp在6月有个多GPU的merge,但是我没看到官方更新,所以这里暂时确定不支持多GPU。如果有小伙伴确认可以支持多GPU请留言。
huggingface的Accelerate包则为我们使用多GPU提供了一个很方便的选择,使用多个GPU推理可以显着提高性能,但gpu之间通信的开销随着gpu数量的增加而显著增加。
https://avoid.overfit.cn/post/8210f640cae0404a88fd1c9028c6aabb
作者:Geronimo