前言
本期我们讨论字符串字面量。
这是一种基于字符串的东西,上一章我们讲过字符串,你一定要去先去看看那一期的内容。
P23 C++字符串-CSDN博客
01 什么是字符串字常量呢?
字符串字面量就是在双引号之间的一串字符
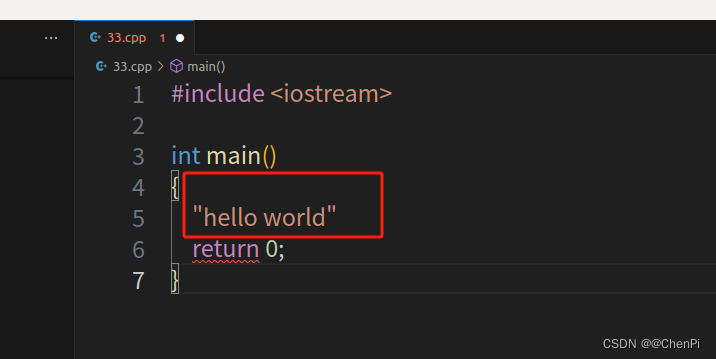
在上面的代码中,我们通过双引号定义了一个字符串字常量。
当指针悬停在“hello world0” 时,会弹出下面语句
(const char [12])"hello world"
你可以看到这是一个 const char 数组,长度为12。
可是这里很明显只有11个字符,那为什么 const char 数组的长度是12呢?
原因是在这种情况下,在字符串的最后有一个额外的字符,一个空终止字符,它的 ASCII 码值为 0,可以写做 ‘\0’,是null字符的意思,表示字符串的结束。注意,这和字符0完全不一样。
如果我们想在这个字符串中间插入一个 \0,这样操作会破坏这个字符串的行为,让我们设置个断点查看下内存

我在第五行设置了一个断点,当程序运行到第六行的时候,我们可以看到左边红框data = hello
这是为什么呢?

我们可以看到在 hello 和 world 的后面各有一个点,在 ACSII 中,点表示 0。它在最后标记字符串的结尾标记字符串的结尾。
如果我想看到我的字符串是什么,我可以运行 C 函数 strlen,计算一下这个字符串的长度,看看结果。
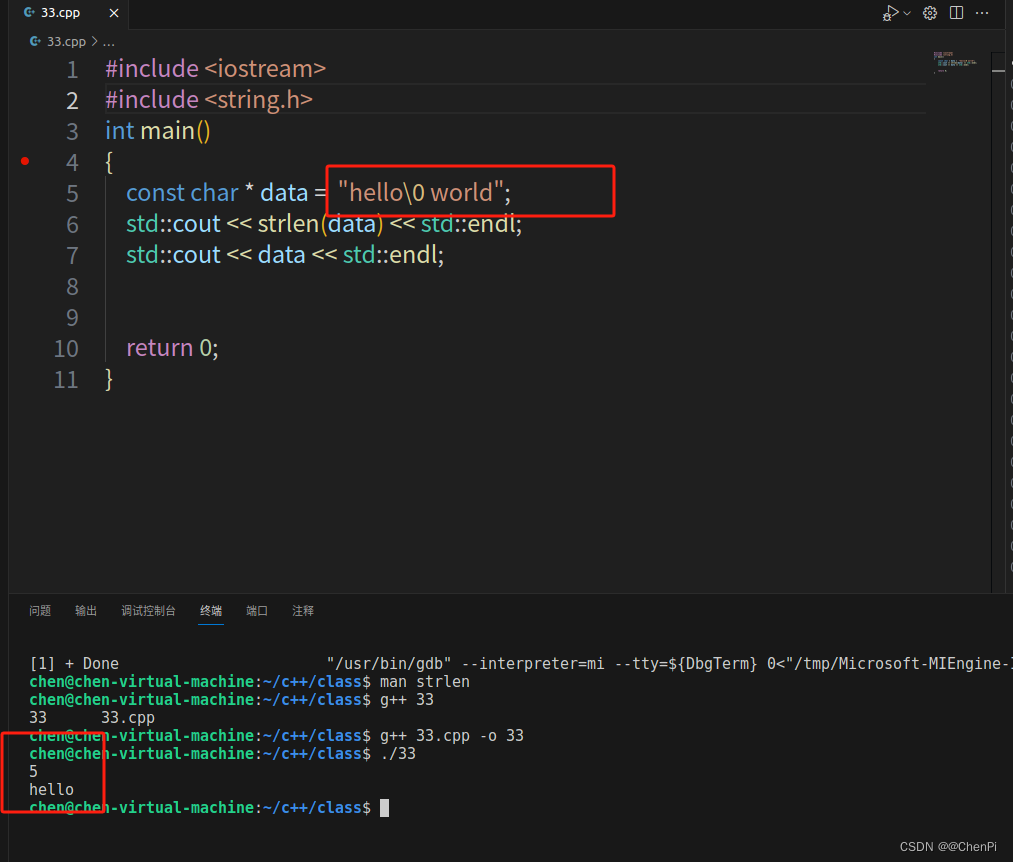
结果是5,可是明明字符串的长度不是5啊,得到这个结果的原因是它只计算直到 \0 之前的字符数。因为一旦它到0,它就认为是结束了,这就是字符串的结尾了。
这就是它现在的样子,是一个 const char* 。
我们也可以把它赋值给另一个 const char* ,这完全没问题。
const 保证了你不会操纵字符串。当然,如果不写 const,你是可以修改其中的字符的,不过我不建议你这样做,这可能会导致所谓的未定义行为,因为 C++ 标准并没有定义在这种情况下应该发生什么,因此,一些编译器可能会为此生成有效的代码,但是你不能依赖它,所以还是不要这样操作了,一些编译器甚至不会让你通过编译。
未定义是不被允许的,原因是你取了一个指向那个字符串的字面量的内存位置的指针,而字符串字面量是存储在内存的只读部分的,它是存储在二进制文件的 const 部分。当我们引用它的时候,实际上指的是一个我们不能编辑的常量区域。
测试的代码
#include <iostream>
#include <string.h>
int main()
{
const char * data = "hello\0 world";
std::cout << strlen(data) << std::endl;
std::cout << data << std::endl;
return 0;
}02 其他一些关于字符串的有趣的常识。
有一种叫做 wchar_t 的字符,也是就是所谓的宽字符。
现在快速的过一遍这些类型。

注意,如果不加那个 L,是不能通过编译的。
会报下面的错误"const char *" 类型的值不能用于初始化 "const wchar_t *" 类型的实体C/C++(144)
上面的例子表示引号里的字符串字面值由宽字符组成。
C++ 还引入了一些其它的字符,比如 char16_t,你需要设置为小写 u,然后是双引号包含你的文本。还有 char32_t,这里是大写的 U,加上你的文本。
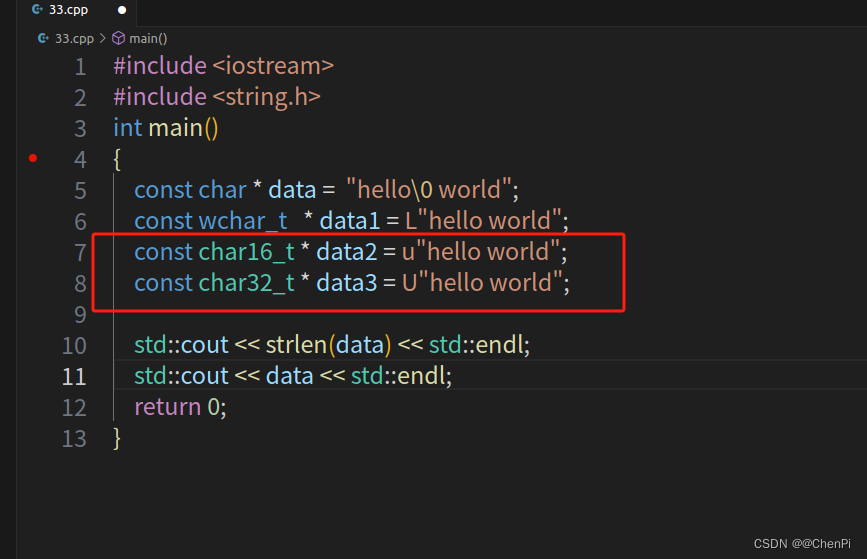
如果为了强调,你也可以将普通的 const char 前面加上 u8 前缀。有一些编译器设置可以控制是使用 char 还是使用 wchar。
做一个简单的总结:char 是一个字节的字符,也就是utf8;char16 是两个字节的16个比特的字符,也就是utf16;char32 是32比特,4字节的字符,也就是utf32。
2.1 wchar 和 char16 之间的区别是什么?
因为它们似乎都是两个字节的字符。
虽然我一直在说,一个字符是两个字节,实际情况是,这是由编译器决定的,它可能是一个字节,也可能是两个字节,也可能是四个字节,在实际应用中,好像还没有见过是一个字节的,通常不是2个就是4个,在 windows 上是2个字节,在 linux上是4个字节,mac 上也是四个字节。所以,这其实是一个变动的值,如果你确实要的是2个字节的,你就用 char16吧。
2.2 字符串附加。
在 C++14 中,有个 std::string_literals,它给出了一些方便的字符串函数。
如果你想在这个上面附加一些其它的字符串,你不能直接使用加号拼接一个字符串。因为这些都是字符串字面量,它们实际上是数组或者指针,所以不能将它们相加。在 C++14 的 string_literals 库中,有办法可以让事情变得更加简单一些。
你可以直接把字母 s 加到字符串的末尾,就像下面的例子一样。

如果你把鼠标悬浮在上面可以看到,它是一个操作符函数,返回标准字符串对象,类似的,你把 u8 放在前面,把 L 放在前面,可以得到对应的字符串,都是一样的道理。
我们还可以通过另外一种方法来附加字符串字面量,使用字母 R。

R 表示可以忽略转义字符,这样操作可以让这个过程变的简单了一些,因为如果没有它,要完成同的效果,我们需要把所有的这些东西都加在一起,或者我们也可以这样,直接加上 \n。

这种做法还是比较常见的,如果你想写一段完整的文本,或者代码中的某个字符串,你想简单的定义它的话就比较复杂了,所以 R 还是很有用的。
好了,以上就是字符串字常量。
#include <iostream>
#include <string.h>
int main()
{
using namespace std::string_literals;
const char * data = "hello\0 world";
const wchar_t * data1 = L"hello world";
const char16_t * data2 = u"hello world";
const char32_t * data3 = U"hello world";
std::string buf = "hello"s + "world";
const char * buf2 =R"(hello
world
i am
chenpi
)";
const char * buf3 = "hello\n"
"world";
std::cout << buf3 << std::endl;
return 0;
}