早停机制,一种机器学习模型调优策略,提升调优效率
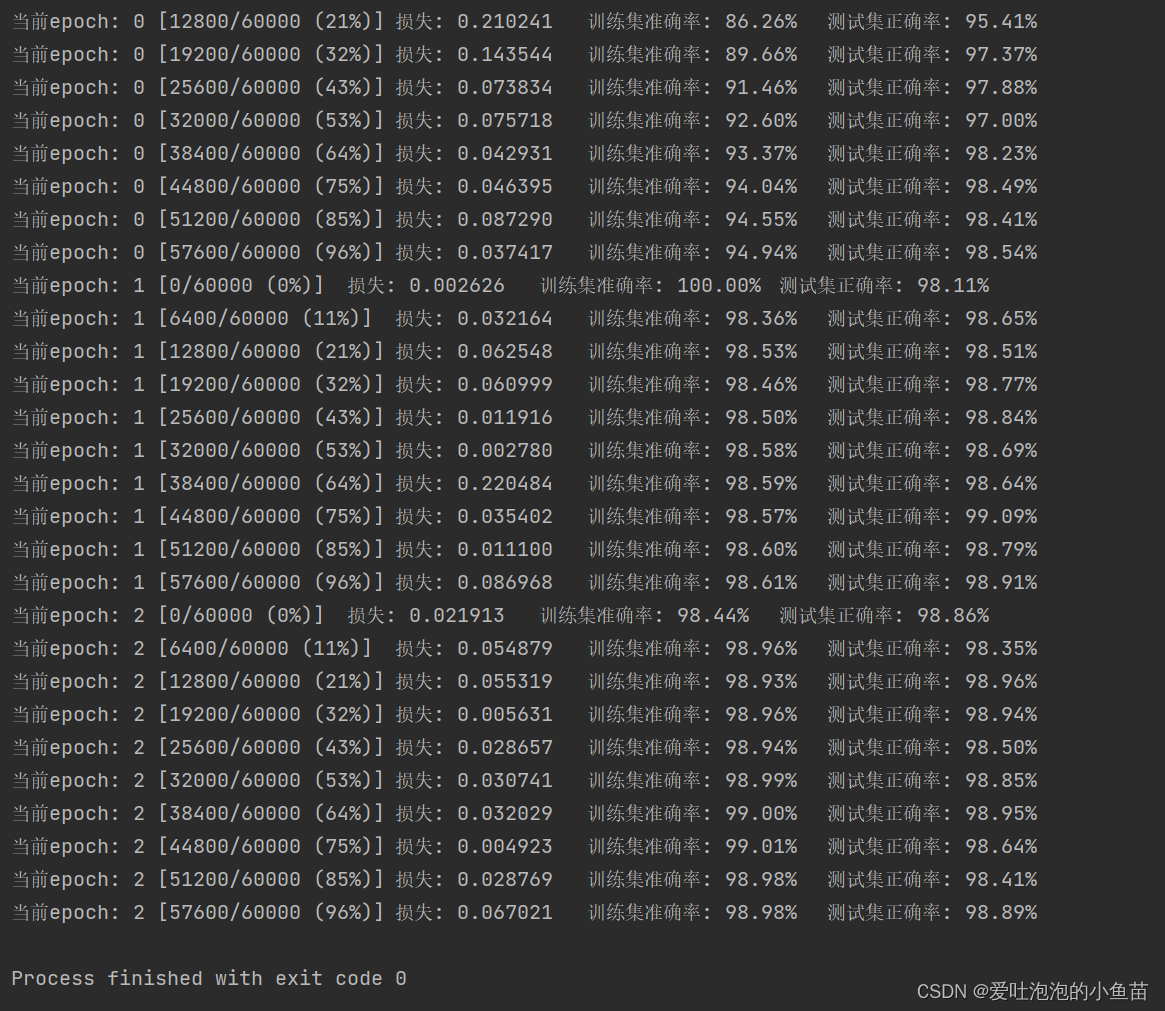
下图损失值明显经过了欠拟合到过拟合

使用早停机制后,模型不再过拟合

模型早停是面向模型训练过程的。而在模型内部,也会出现类似的现象,这一现象被叫做过度思考(Overthinking)现象,好比爱迪生让助理计算灯泡的容积。一个博士生助理将问题过度复杂化,计算半天计算不出来。而一个头脑清晰的普通助理反而可以直接用灯泡能容纳的水量,很快就计算出容积。
模型早退参考:模型早退技术(一): 经典动态早退机制介绍 - 知乎
1.Early stopping
在机器学习中,早期停止是一种正则化形式,用于在使用梯度下降等迭代法训练学习器时避免过拟合。这种方法会更新学习器,使其每次迭代都能更好地适应训练数据。在一定程度上,这可以提高学习器在训练集以外数据上的性能。然而,超过了这一点,学习器与训练数据拟合度的提高是以泛化误差的增加为代价的。早期停止规则为学习器开始过度拟合之前可以运行多少次迭代提供了指导。许多不同的机器学习方法都采用了早期停止规则,其理论基础各不相同。
(1)Overfitting(过拟合)
机器学习算法根据有限的训练数据集来训练模型。在训练过程中,会根据模型对训练集中观测数据的预测结果进行评估。不过,一般来说,机器学习方案的目标是生成一个能够泛化的模型,即能够预测以前未见过的观测结果。当模型很好地拟合了训练集中的数据,却产生了较大的泛化误差时,就会出现过拟合。
(2)Regularization(过拟合)
在机器学习中,正则化是指修改学习算法以防止过度拟合的过程。这通常涉及对学习到的模型施加某种平滑性约束。这种平滑性可以通过固定模型中的参数数量来明确执行,也可以通过增强代价函数来执行,如在 Tikhonov 正则化中。Tikhonov 正则化以及主成分回归和许多其他正则化方案都属于频谱正则化的范畴,正则化的特点是应用滤波器。Early stopping也属于这一类方法。
(3)Method---code
Train the Model using Early Stopping
# import EarlyStopping
from pytorchtools import EarlyStopping
def train_model(model, batch_size, patience, n_epochs):
# to track the training loss as the model trains
train_losses = []
# to track the validation loss as the model trains
valid_losses = []
# to track the average training loss per epoch as the model trains
avg_train_losses = []
# to track the average validation loss per epoch as the model trains
avg_valid_losses = []
# initialize the early_stopping object
early_stopping = EarlyStopping(patience=patience, verbose=True)
for epoch in range(1, n_epochs + 1):
###################
# train the model #
###################
model.train() # prep model for training
for batch, (data, target) in enumerate(train_loader, 1):
# clear the gradients of all optimized variables
optimizer.zero_grad()
# forward pass: compute predicted outputs by passing inputs to the model
output = model(data)
# calculate the loss
loss = criterion(output, target)
# backward pass: compute gradient of the loss with respect to model parameters
loss.backward()
# perform a single optimization step (parameter update)
optimizer.step()
# record training loss
train_losses.append(loss.item())
######################
# validate the model #
######################
model.eval() # prep model for evaluation
for data, target in valid_loader:
# forward pass: compute predicted outputs by passing inputs to the model
output = model(data)
# calculate the loss
loss = criterion(output, target)
# record validation loss
valid_losses.append(loss.item())
# print training/validation statistics
# calculate average loss over an epoch
train_loss = np.average(train_losses)
valid_loss = np.average(valid_losses)
avg_train_losses.append(train_loss)
avg_valid_losses.append(valid_loss)
epoch_len = len(str(n_epochs))
print_msg = (f'[{epoch:>{epoch_len}}/{n_epochs:>{epoch_len}}] ' +
f'train_loss: {train_loss:.5f} ' +
f'valid_loss: {valid_loss:.5f}')
print(print_msg)
# clear lists to track next epoch
train_losses = []
valid_losses = []
# early_stopping needs the validation loss to check if it has decresed,
# and if it has, it will make a checkpoint of the current model
early_stopping(valid_loss, model)
if early_stopping.early_stop:
print("Early stopping")
break
# load the last checkpoint with the best model
model.load_state_dict(torch.load('checkpoint.pt'))
return model, avg_train_losses, avg_valid_losses
batch_size = 256
n_epochs = 100
train_loader, test_loader, valid_loader = create_datasets(batch_size)
# early stopping patience; how long to wait after last time validation loss improved.
patience = 20
model, train_loss, valid_loss = train_model(model, batch_size, patience, n_epochs)Visualizing the Loss and the Early Stopping Checkpoint
# visualize the loss as the network trained
fig = plt.figure(figsize=(10,8))
plt.plot(range(1,len(train_loss)+1),train_loss, label='Training Loss')
plt.plot(range(1,len(valid_loss)+1),valid_loss,label='Validation Loss')
# find position of lowest validation loss
minposs = valid_loss.index(min(valid_loss))+1
plt.axvline(minposs, linestyle='--', color='r',label='Early Stopping Checkpoint')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.ylim(0, 0.5) # consistent scale
plt.xlim(0, len(train_loss)+1) # consistent scale
plt.grid(True)
plt.legend()
plt.tight_layout()
plt.show()
fig.savefig('loss_plot.png', bbox_inches='tight')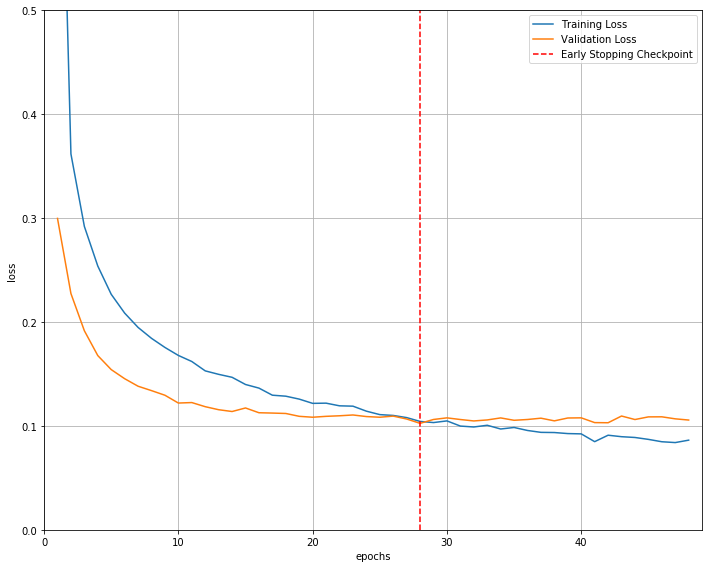
2.Early exiting
虽然深度神经网络得益于大量的层数,但在分类任务中,很多数据点往往只需要更少的工作就能准确分类。最近有几项研究涉及在神经网络正常终点之前退出的想法。Panda 等人在 Conditional Deep Learning for Energy-Efficient and Enhanced Pattern Recognition 一文中指出,与一些难度较高的数据点相比,很多数据点都可以轻松分类,所需的处理量也更少,他们认为这可以节省电能。Surat 等人在BranchyNet: Fast Inference via Early Exiting from Deep Neural Networks一文中,研究了退出位置的选择性方法和早期退出的标准。
(1)Early Exiting为什么有效
早期退出是一种概念简单易懂的策略 ,下图显示了二维特征空间中的一个简单示例。虽然深度网络可以表示类别之间更复杂、更有表现力的边界(假设我们有信心避免过度拟合数据),但很明显,即使是最简单的分类边界,也能对大部分数据进行正确分类。

与靠近边界的数据点相比,远离边界的数据点可被视为 "易于分类",并能更快地获得高置信度。事实上,我们可以把外侧直线之间的区域看作是 "难以分类 "的区域,需要神经网络的全部表现力才能准确分类。
(2)Method---code
paper: BranchyNet: Fast Inference via Early Exiting from Deep Neural Networks
代码参考:GitHub - kunglab/branchynet
import torch
import torch.nn as nn
#import numpy as np
#from scipy.stats import entropy
class ConvPoolAc(nn.Module):
def __init__(self, chanIn, chanOut, kernel=3, stride=1, padding=1, p_ceil_mode=False,bias=True):
super(ConvPoolAc, self).__init__()
self.layer = nn.Sequential(
nn.Conv2d(chanIn, chanOut, kernel_size=kernel,
stride=stride, padding=padding, bias=bias),
nn.MaxPool2d(2, stride=2, ceil_mode=p_ceil_mode), #ksize, stride
nn.ReLU(True),
)
def forward(self, x):
return self.layer(x)
# alexnet version
class ConvAcPool(nn.Module):
def __init__(self, chanIn, chanOut, kernel=3, stride=1, padding=1, p_ceil_mode=False,bias=True):
super(ConvAcPool, self).__init__()
self.layer = nn.Sequential(
nn.Conv2d(chanIn, chanOut, kernel_size=kernel,
stride=stride, padding=padding, bias=bias),
nn.ReLU(True),
nn.MaxPool2d(3, stride=2, ceil_mode=p_ceil_mode), #ksize, stride
)
def forward(self, x):
return self.layer(x)
#def _exit_criterion(x, exit_threshold): #NOT for batch size > 1
# #evaluate the exit criterion on the result provided
# #return true if it can exit, false if it can't
# with torch.no_grad():
# #print(x)
# softmax_res = nn.functional.softmax(x, dim=-1)
# #apply scipy.stats.entropy for branchynet,
# #when they do theirs, its on a batch
# #print(softmax_res)
# entr = entropy(softmax_res[-1])
# #print(entr)
# return entr < exit_threshold
#
#@torch.jit.script
#def _fast_inf_forward(x, backbone, exits, exit_threshold):
# for i in range(len(backbone)):
# x = backbone[i](x)
# ec = exits[i](x)
# res = ec
# if _exit_criterion(ec):
# break
# return res
#Main Network
class B_Lenet(nn.Module):
def __init__(self, exit_threshold=0.5):
super(B_Lenet, self).__init__()
# call function to build layers
#probably need to fragment the model into a moduleList
#having distinct indices to compute the classfiers/branches on
#function for building the branches
#this includes the individual classifier layers, can keep separate
#last branch/classif being terminal linear layer-included here not main net
self.fast_inference_mode = False
#self.fast_inf_batch_size = fast_inf_batch_size #add to input args if used
#self.exit_fn = entropy
self.exit_threshold = torch.tensor([exit_threshold], dtype=torch.float32) #TODO learnable, better default value
self.exit_num=2 #NOTE early and late exits
self.backbone = nn.ModuleList()
self.exits = nn.ModuleList()
self.exit_loss_weights = [1.0, 0.3] #weighting for each exit when summing loss
#weight initialisiation - for standard layers this is done automagically
self._build_backbone()
self._build_exits()
self.le_cnt=0
def _build_backbone(self):
#Starting conv2d layer
c1 = nn.Conv2d(1, 5, kernel_size=5, stride=1, padding=3)
#down sampling is duplicated in original branchynet code
c1_down_samp_activ = nn.Sequential(
nn.MaxPool2d(2,stride=2),
nn.ReLU(True)
)
#remaining backbone
c2 = ConvPoolAc(5, 10, kernel=5, stride=1, padding=3, p_ceil_mode=True)
c3 = ConvPoolAc(10, 20, kernel=5, stride=1, padding=3, p_ceil_mode=True)
fc1 = nn.Sequential(nn.Flatten(), nn.Linear(720,84))
post_ee_layers = nn.Sequential(c1_down_samp_activ,c2,c3,fc1)
self.backbone.append(c1)
self.backbone.append(post_ee_layers)
def _build_exits(self): #adding early exits/branches
#early exit 1
ee1 = nn.Sequential(
nn.MaxPool2d(2, stride=2), #ksize, stride
nn.ReLU(True),
ConvPoolAc(5, 10, kernel=3, stride=1, padding=1, p_ceil_mode=True),
nn.Flatten(),
nn.Linear(640,10, bias=False),
)
self.exits.append(ee1)
#final exit
eeF = nn.Sequential(
nn.Linear(84,10, bias=False),
)
self.exits.append(eeF)
def exit_criterion(self, x): #NOT for batch size > 1
#evaluate the exit criterion on the result provided
#return true if it can exit, false if it can't
with torch.no_grad():
#NOTE brn exits do not compute softmax in our case
pk = nn.functional.softmax(x, dim=-1)
#apply scipy.stats.entropy for branchynet,
#when they do theirs, its on a batch - same calc bu pt
entr = -torch.sum(pk * torch.log(pk))
#print("entropy:",entr)
return entr < self.exit_threshold
def exit_criterion_top1(self, x): #NOT for batch size > 1
#evaluate the exit criterion on the result provided
#return true if it can exit, false if it can't
with torch.no_grad():
#exp_arr = torch.exp(x)
#emax = torch.max(exp_arr)
#esum = torch.sum(exp_arr)
#return emax > esum*self.exit_threshold
pk = nn.functional.softmax(x, dim=-1)
top1 = torch.max(pk) #x)
return top1 > self.exit_threshold
@torch.jit.unused #decorator to skip jit comp
def _forward_training(self, x):
#TODO make jit compatible - not urgent
#broken because returning list()
res = []
for bb, ee in zip(self.backbone, self.exits):
x = bb(x)
res.append(ee(x))
return res
def forward(self, x):
#std forward function - add var to distinguish be test and inf
if self.fast_inference_mode:
for bb, ee in zip(self.backbone, self.exits):
x = bb(x)
res = ee(x) #res not changed by exit criterion
if self.exit_criterion_top1(res):
#print("EE fired")
return res
#print("### LATE EXIT ###")
#self.le_cnt+=1
return res
#works for predefined batchsize - pytorch only for same reason of batching
'''
mb_chunk = torch.chunk(x, self.fast_inf_batch_size, dim=0)
res_temp=[]
for xs in mb_chunk:
for j in range(len(self.backbone)):
xs = self.backbone[j](xs)
ec = self.exits[j](xs)
if self.exit_criterion(ec):
break
res_temp.append(ec)
print("RESTEMP", res_temp)
res = torch.cat(tuple(res_temp), 0)
'''
else: #used for training
#calculate all exits
return self._forward_training(x)
def set_fast_inf_mode(self, mode=True):
if mode:
self.eval()
self.fast_inference_mode = mode
#FPGAConvNet friendly version:
#ceiling mode flipped, FC layer sizes adapted, padding altered,removed duplicated layers
class B_Lenet_fcn(B_Lenet):
def _build_backbone(self):
strt_bl = ConvPoolAc(1, 5, kernel=5, stride=1, padding=4)
self.backbone.append(strt_bl)
#adding ConvPoolAc blocks - remaining backbone
bb_layers = []
bb_layers.append(ConvPoolAc(5, 10, kernel=5, stride=1, padding=4) )
bb_layers.append(ConvPoolAc(10, 20, kernel=5, stride=1, padding=3) )
bb_layers.append(nn.Flatten())
bb_layers.append(nn.Linear(720, 84))#, bias=False))
remaining_backbone_layers = nn.Sequential(*bb_layers)
self.backbone.append(remaining_backbone_layers)
#adding early exits/branches
def _build_exits(self):
#early exit 1
ee1 = nn.Sequential(
ConvPoolAc(5, 10, kernel=3, stride=1, padding=1),
nn.Flatten(),
nn.Linear(640,10), #, bias=False),
)
self.exits.append(ee1)
#final exit
eeF = nn.Sequential(
nn.Linear(84,10),#, bias=False),
)
self.exits.append(eeF)
#Simplified exit version:
#stacks on _fcn changes, removes the conv
class B_Lenet_se(B_Lenet):
def _build_backbone(self):
strt_bl = ConvPoolAc(1, 5, kernel=5, stride=1, padding=4)
self.backbone.append(strt_bl)
#adding ConvPoolAc blocks - remaining backbone
bb_layers = []
bb_layers.append(ConvPoolAc(5, 10, kernel=5, stride=1, padding=4) )
bb_layers.append(ConvPoolAc(10, 20, kernel=5, stride=1, padding=3) )
bb_layers.append(nn.Flatten())
#NOTE original: bb_layers.append(nn.Linear(720, 84, bias=False))
#se original: bb_layers.append(nn.Linear(1000, 84)) #, bias=False))
remaining_backbone_layers = nn.Sequential(*bb_layers)
self.backbone.append(remaining_backbone_layers)
#adding early exits/branches
def _build_exits(self):
#early exit 1
ee1 = nn.Sequential(
ConvPoolAc(5, 10, kernel=3, stride=1, padding=1),
nn.Flatten(),
nn.Linear(640,10), #, bias=False),
# NOTE original se lenet but different enough so might work??
# NOTE brn_se_SMOL.onnx is different to both of these... backbones are the same tho
#nn.Flatten(),
#nn.Linear(1280,10,) #bias=False),
)
self.exits.append(ee1)
#final exit
eeF = nn.Sequential(
#NOTE original nn.Linear(84,10, ) #bias=False),
nn.Linear(720,10)
)
self.exits.append(eeF)
#cifar10 version - harder data set
class B_Lenet_cifar(B_Lenet_fcn):
def _build_backbone(self):
#NOTE changed padding from 4 to 2
# changed input number of channels to be 3
strt_bl = ConvPoolAc(3, 5, kernel=5, stride=1, padding=2)
self.backbone.append(strt_bl)
#adding ConvPoolAc blocks - remaining backbone
bb_layers = []
bb_layers.append(ConvPoolAc(5, 10, kernel=5, stride=1, padding=4) )
bb_layers.append(ConvPoolAc(10, 20, kernel=5, stride=1, padding=3) )
bb_layers.append(nn.Flatten())
bb_layers.append(nn.Linear(720, 84))#, bias=False))
remaining_backbone_layers = nn.Sequential(*bb_layers)
self.backbone.append(remaining_backbone_layers)
class B_Alexnet_cifar(B_Lenet):
# attempt 1 exit alexnet
def __init__(self, exit_threshold=0.5):
super(B_Lenet, self).__init__()
self.exit_num=3
self.fast_inference_mode = False
self.exit_threshold = torch.tensor([exit_threshold], dtype=torch.float32)
self.backbone = nn.ModuleList()
self.exits = nn.ModuleList()
self.exit_loss_weights = [1.0, 1.0, 1.0] #weighting for each exit when summing loss
#weight initialisiation - for standard layers this is done automagically
self._build_backbone()
self._build_exits()
self.le_cnt=0
def _build_backbone(self):
bb_layers0 = nn.Sequential(
ConvAcPool(3, 32, kernel=5, stride=1, padding=2),
# NOTE LRN not possible on hw
#nn.LocalResponseNorm(size=3, alpha=0.000005, beta=0.75),
)
self.backbone.append(bb_layers0)
bb_layers1 = []
bb_layers1.append(ConvAcPool(32, 64, kernel=5, stride=1, padding=2))
#bb_layers1.append(nn.LocalResponseNorm(size=3, alpha=0.000005, beta=0.75))
bb_layers1.append(nn.Conv2d(64, 96, kernel_size=3,stride=1,padding=1) )
bb_layers1.append(nn.ReLU())
self.backbone.append(nn.Sequential(*bb_layers1))
bb_layers2 = []
bb_layers2.append(nn.Conv2d(96, 96, kernel_size=3,stride=1,padding=1))
bb_layers2.append(nn.ReLU())
bb_layers2.append(nn.Conv2d(96, 64, kernel_size=3,stride=1,padding=1))
bb_layers2.append(nn.ReLU())
bb_layers2.append(nn.MaxPool2d(3,stride=2,ceil_mode=False))
bb_layers2.append(nn.Flatten())
bb_layers2.append(nn.Linear(576, 256))
bb_layers2.append(nn.ReLU())
bb_layers2.append(nn.Dropout(0.5))
bb_layers2.append(nn.Linear(256, 128))
bb_layers2.append(nn.ReLU())
self.backbone.append(nn.Sequential(*bb_layers2))
#adding early exits/branches
def _build_exits(self):
#early exit 1
ee1 = nn.Sequential(
nn.Conv2d(32, 64, kernel_size=3,stride=1,padding=1),
nn.ReLU(),
nn.MaxPool2d(3,stride=2,ceil_mode=False),
nn.Conv2d(64, 32, kernel_size=3,stride=1,padding=1),
nn.ReLU(),
nn.MaxPool2d(3,stride=2,ceil_mode=False),
nn.Flatten(),
nn.Linear(288,10), #, bias=False),
)
self.exits.append(ee1)
ee2 = nn.Sequential(
nn.MaxPool2d(3,stride=2,ceil_mode=False),
nn.Conv2d(96, 32, kernel_size=3,stride=1,padding=1),
nn.MaxPool2d(3,stride=2,ceil_mode=False),
nn.Flatten(),
nn.Linear(32,10),
)
self.exits.append(ee2)
#final exit
eeF = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(128,10)
)
self.exits.append(eeF)
class TW_SmallCNN(B_Lenet):
# TODO make own class for TW
# attempt 1 exit from triple wins
def __init__(self, exit_threshold=0.5):
super(B_Lenet, self).__init__()
# copied from b-alexnet
self.fast_inference_mode = False
self.exit_threshold = torch.tensor([exit_threshold], dtype=torch.float32)
self.backbone = nn.ModuleList()
self.exits = nn.ModuleList()
self.exit_loss_weights = [1.0, 0.3] #weighting for each exit when summing loss
#weight initialisiation - for standard layers this is done automagically
self._build_backbone()
self._build_exits()
self.le_cnt=0
def _build_backbone(self):
strt_bl = nn.Sequential(
nn.Conv2d(1, 32, 3),
nn.ReLU(True),
)
self.backbone.append(strt_bl)
bb_layers = []
bb_layers.append(nn.Conv2d(32,32,3),)
bb_layers.append(nn.ReLU(True),)
bb_layers.append(nn.MaxPool2d(2,2),)
bb_layers.append(nn.Conv2d(32,64,3),)
bb_layers.append(nn.ReLU(True),)
#branch2 - ignoring
bb_layers.append(nn.Conv2d(64,64,3),)
bb_layers.append(nn.ReLU(True),)
bb_layers.append(nn.MaxPool2d(2,2),)
bb_layers.append(nn.Flatten(),)
bb_layers.append(nn.Linear(64*4*4, 200),)
bb_layers.append(nn.ReLU(True),)
# drop
bb_layers.append(nn.Linear(200,200),)
bb_layers.append(nn.ReLU(True),)
remaining_backbone_layers = nn.Sequential(*bb_layers)
self.backbone.append(remaining_backbone_layers)
#adding early exits/branches
def _build_exits(self):
#early exit 1
ee1 = nn.Sequential(
nn.Conv2d(32, 16, 3, stride=2),
nn.MaxPool2d(2, 2),
nn.Flatten(),
nn.Linear(16 * 6 * 6, 200),
#nn.Dropout(drop),
nn.Linear(200, 200),
nn.Linear(200, 10)
)
self.exits.append(ee1)
##early exit 2
#ee2 = nn.Sequential(
# nn.MaxPool2d(2, 2),
# View(-1, 64 * 5 * 5),
# nn.Linear(64 * 5 * 5, 200),
# nn.Dropout(drop),
# nn.Linear(200, 200),
# nn.Linear(200, self.num_labels)
# )
#self.exits.append(ee2)
#final exit
eeF = nn.Sequential(
nn.Linear(200,10)
)
self.exits.append(eeF)
class C_Alexnet_SVHN(B_Lenet):
# attempt 1 exit alexnet
def __init__(self, exit_threshold=0.5):
super(B_Lenet, self).__init__()
self.fast_inference_mode = False
self.exit_threshold = torch.tensor([exit_threshold], dtype=torch.float32)
self.backbone = nn.ModuleList()
self.exits = nn.ModuleList()
self.exit_loss_weights = [1.0, 0.3] #weighting for each exit when summing loss
#weight initialisiation - for standard layers this is done automagically
self._build_backbone()
self._build_exits()
self.le_cnt=0
def _build_backbone(self):
strt_bl = nn.Sequential(
ConvAcPool(3, 64, kernel=3, stride=1, padding=2),
ConvAcPool(64, 192, kernel=3, stride=1, padding=2),
nn.Conv2d(192, 384, kernel_size=3,stride=1,padding=1),
nn.ReLU()
)
self.backbone.append(strt_bl)
bb_layers = []
bb_layers.append(nn.Conv2d(384, 256, kernel_size=3,stride=1,padding=1))
bb_layers.append(nn.ReLU())
bb_layers.append(nn.Conv2d(256, 256, kernel_size=3,stride=1,padding=1))
bb_layers.append(nn.ReLU())
bb_layers.append(nn.MaxPool2d(3,stride=2,ceil_mode=False))
bb_layers.append(nn.Flatten())
bb_layers.append(nn.Linear(2304, 2048))
bb_layers.append(nn.ReLU())
#dropout
bb_layers.append(nn.Linear(2048, 2048))
bb_layers.append(nn.ReLU())
remaining_backbone_layers = nn.Sequential(*bb_layers)
self.backbone.append(remaining_backbone_layers)
#adding early exits/branches
def _build_exits(self):
#early exit 1
ee1 = nn.Sequential(
nn.Conv2d(384, 128, kernel_size=3,stride=1,padding=1),
nn.ReLU(),
nn.MaxPool2d(3,stride=2,ceil_mode=False),
nn.Flatten(),
nn.Linear(1152,10), #, bias=False),
)
self.exits.append(ee1)
#final exit
eeF = nn.Sequential(
nn.Flatten(),
nn.Linear(2048,10)
)
self.exits.append(eeF)






![[栈迁移+ret滑梯]gyctf_2020_borrowstack](https://img-blog.csdnimg.cn/a7f45b4e7fdb4915b2075037f066577b.png)