爬虫(Web Scraping)是指通过编程自动化地获取互联网上的信息的过程。爬虫的目的通常是从网页中抓取数据,进行数据分析、处理或展示。以下是爬虫的基本流程和一些重要的概念:
爬虫基本流程:
确定目标: 确定要爬取的网站或网页。
发送请求: 使用编程语言(如Python)发送HTTP请求,获取网页内容。
解析页面: 对获取的页面进行解析,提取出所需的信息。
存储数据: 将提取的信息存储到本地文件、数据库或其他数据存储方式中。
定期更新: 如果需要定期获取信息,可以设置定时运行爬虫。
爬虫的一些重要概念:
User-Agent: 请求头中的一部分,用于标识爬虫的身份。有些网站会检测User-Agent,如果检测到是爬虫,则可能限制访问。
Cookie: 网站为了识别用户身份而存储在用户本地的数据。在爬虫中,有时需要使用Cookie来模拟用户登录状态。
HTTP请求: 使用HTTP协议进行通信,通过GET或POST请求获取网页内容。
HTML解析: 使用解析库(如BeautifulSoup、lxml等)对HTML进行解析,提取所需的信息。
XPath和CSS选择器: 用于在HTML中定位元素的语法,便于提取信息。
Robots.txt: 一种标准,规定了哪些页面可以被爬虫访问,哪些不可以。
反爬虫: 一些网站采取反爬虫策略,如限制请求频率、验证码、动态加载等,爬虫需要相应地处理这些情况。
代理: 通过代理服务器发送请求,避免被封IP。
数据存储: 将爬取到的数据存储到本地文件或数据库中。
爬虫技术在数据采集、搜索引擎、舆情监测等领域有广泛的应用,但在使用爬虫时需要遵守法律法规和网站的使用规定,以及尊重隐私和版权。
示例:
import os
import urllib.request
from urllib.parse import quote
import re
import urllib.error
import requests
import time
# 设置请求头获取Cookie
get_cookie_headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/92.0.4515.159 Safari/537.36 "}
get_cookie_html = "https://www.baidu.com/?tn=49055317_4_hao_pg"
get_cookie_target = requests.session()
cookie_target = get_cookie_target.get(get_cookie_html, headers=get_cookie_headers)
cookie = requests.utils.dict_from_cookiejar(cookie_target.cookies)
print(cookie)
key = []
value = []
result_cookie = ""
# 将Cookie转化为字符串形式
for i in cookie.keys():
key.append(i)
for i in cookie.values():
value.append(i)
for i in range(len(key)):
result_cookie += key[i] + '=' + value[i] + ";"
print(result_cookie)
# 设置请求头
myheaders = {
"Cookie": result_cookie,
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/92.0.4515.159 Safari/537.36 "
}
# 输入爬取的主题
pic_dir_name = input("输入想要爬取的主题:****")
# 设置保存路径
base_dir = r"E:\shezu\图/"
pic_dir = base_dir + pic_dir_name
# 创建文件夹
if os.path.exists(base_dir):
if os.path.exists(pic_dir):
print(pic_dir + " 文件已存在")
else:
os.mkdir(pic_dir)
else:
os.mkdir(base_dir)
os.mkdir(pic_dir)
# 对主题进行URL编码
keyword = quote(pic_dir_name, encoding='utf-8')
start_number = 0
base_url = "https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&queryWord=" + keyword + "&word=" + keyword + "&pn%d=&rn=60" % start_number
# 正则表达式预编译
key = r'thumbURL":"(.*?)"'
pic_url = re.compile(key)
number = 1
# 爬取图片
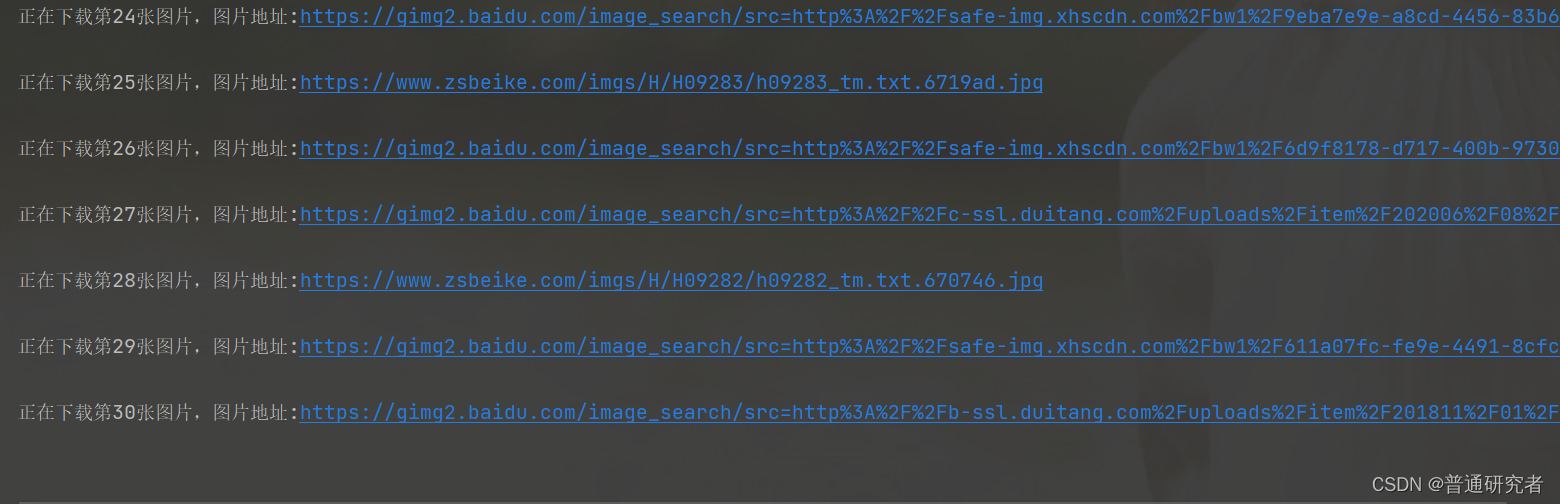
while start_number < 1800:
response = urllib.request.Request(base_url, headers=myheaders)
result = urllib.request.urlopen(response).read().decode("utf-8")
for i in re.findall(pic_url, result):
print(i)
try:
response = urllib.request.Request(i, headers=myheaders)
pic_result = urllib.request.urlopen(response).read()
with open(pic_dir + "/" + pic_dir_name + str(number) + ".jpg", "wb+") as f:
f.write(pic_result)
number += 1
time.sleep(0.5)
except urllib.error.URLError:
print("下载失败")
start_number += 60
这个脚本的原理是:
- 获取百度图片搜索页面的Cookie。
- 构造百度图片搜索的URL,并设置请求头带上Cookie。
- 解析返回的JSON数据,提取出图片的URL。
- 使用获取到的图片URL,下载图片到指定目录。
需要注意的是,爬取网站内容需要遵循网站的相关规定,以及尊重图片的版权。