1.实验目的
1.熟悉知识的表示方法
2.掌握产生式系统的运行机制
3.产生式系统推理的基本方法。
2.实验内容
运用所学知识,设计并编程实现一个小型动物识别系统,能识别虎、金钱豹、斑马、长颈鹿、鸵鸟、企鹅、信天翁等七种动物的产生式系统。
规则库:
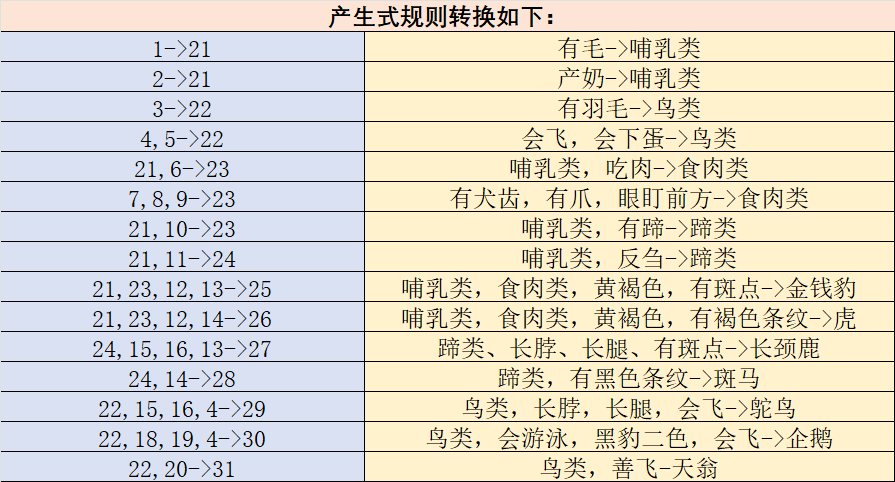
r1: IF 该动物有毛发 THEN 该动物是哺乳动物
r2: IF 该动物有奶 THEN 该动物是哺乳动物
r3: IF 该动物有羽毛 THEN 该动物是鸟
r4: IF 该动物会飞 AND 会下蛋 THEN 该动物是鸟
r5: IF 该动物吃肉 THEN 该动物是食肉动物
r6: IF 该动物有犬齿 AND 有爪 AND 眼盯前方 THEN 该动物是食肉动物
r7: IF 该动物是哺乳动物 AND 有蹄 THEN 该动物是有蹄类动物
r8: IF 该动物是哺乳动物 AND 是反刍动物 THEN 该动物是有蹄类动物
r9: IF 该动物是哺乳动物 AND 是食肉动物 AND 是黄褐色 AND 身上有暗斑点 THEN 该动物是金钱豹
r10:IF 该动物是哺乳动物 AND 是食肉动物 AND 是黄褐色 AND 身上有黑色条纹 THEN 该动物是虎
r11:IF 该动物是有蹄类动物 AND 有长脖子 AND 有长腿 AND 身上有暗斑点 THEN 该动物是长颈鹿
r12:IF 该动物有蹄类动物 AND 身上有黑色条纹 THEN 该动物是斑马
r13:IF 该动物是鸟 AND 有长脖子 AND 有长腿 AND 不会飞 AND 有黑白二色 THEN 该动物是鸵鸟
r14:IF 该动物是鸟 AND 会游泳 AND 不会飞 AND 有黑白二色 THEN 该动物是企鹅
r15:IF 该动物是鸟 AND 善飞 THEN 该动物是信天翁
要求给定初始条件,能识别出是哪种动物。
比如已知初始事实存放在综合数据库中:
有毛发 吃肉 是黄褐色 身上有黑色条纹
运行后得该动物是:虎
3.实验原理
产生式通常用于表示事实、规则以及它们的不确定性度量,适合于表示事实性知识和规则性知识。
确定性规则知识的产生式表示
不确定性规则知识的产生式表示
确定性事实性知识的产生式表示
不确定性事实性知识的产生式表示
产生式与谓词逻辑中的蕴含式的区别:
除逻辑蕴含外,产生式还包括各种操作、规则、变换、算子、函数等。例如,“如果炉温超过上限,则立即关闭风门”是一个产生式,但不是蕴含式。
蕴含式只能表示精确知识,而产生式不仅可以表示精确的知识,还可以表示不精确知识。蕴含式的匹配总要求是精确的。产生式匹配可以是精确的,也可以是不精确的,只要按某种算法求出的相似度落在预先指定的范围内就认为是可匹配的。
产生式的形式描述及语义——巴科斯范式BNF(backus normal form)

符号“::=”表示“定义为”;符号“|”表示“或者是”;符号“[ ]”表示“可缺省”。
产生式系统的基本结构

产生式系统
1,规则库:用于描述相应领域内知识的产生式集合
2,综合数据库:一个用于存放问题求解过程中各种当前信息的数据结构
3,控制系统:由一组程序组成,负责整个产生式系统的运行,实现对问题的求解。控制系统要做以下几项工作:
从规则库中选择与综合数据库中的已知事实进行匹配。
匹配成功的规则可能不止一条,进行冲突消解。
执行某一规则时,如果其右部是一个或多个结论,则把这些结论加入到综合数据库中:如果其右部是一个或多个操作,则执行这些操作。
对于不确定性知识,在执行每一条规则时还要按一定的算法计算结论的不确定性。
检查综合数据库中是否包含了最终结论,决定是否停止系统的运行
产生式表示法的特点
优点:自然性、模块性、有效性、清晰性
缺点:效率不高、不能表达结构性知识
4.解题思路

5.Python编程实现
# 动物识别系统
# 规则库
txt_rule = '''有毛发,是哺乳动物
有奶,是哺乳动物
有羽毛,是鸟
会飞,会下蛋,是鸟
吃肉,是肉食动物
有犬齿,有爪,眼盯前方,是食肉动物
是哺乳动物,有蹄,是蹄类动物
是哺乳动物,是咀嚼反刍动物,是蹄类动物
是哺乳动物,是食肉动物,是黄褐色,身上有暗斑点,金钱豹
是哺乳动物,是肉食动物,是黄褐色,身上有黑色条纹,虎
是蹄类动物,有长脖子,有长腿,身上有暗斑点,长颈鹿
是蹄类动物,身上有黑色条纹,斑马
是鸟,有长脖子,有长腿,不会飞,有黑白二色,鸵鸟
是鸟,会游泳,不会飞,有黑白二色,企鹅
是鸟,善飞,信天翁'''
# 特征值字典
character_dict = {'1': '有毛发', '2': '有奶', '3': '有羽毛', '4': '会飞', '5': '会下蛋',
'6': '吃肉', '7': '有犬齿', '8': '有爪', '9': '眼盯前方', '10': '有蹄',
'11': '是咀嚼反刍动物', '12': '是黄褐色', '13': '身上有暗斑点',
'14': '身上有黑色条纹', '15': '有长脖子', '16': '有长腿',
'17': '不会飞', '18': '会游泳', '19': '有黑白二色',
'20': '善飞', '21': '是哺乳动物', '22': '是鸟',
'23': '是食肉动物', '24': '是蹄类动物', }
# 结果值字典
result_dict = {'25': '信天翁', '26': '鸵鸟', '27': '斑马', '28': '长颈鹿',
'29': '虎', '30': '金钱豹', '31': '企鹅'}
# 数据库对应的过程,合并两个字典
database = {**character_dict, **result_dict}
# 规则库数据转换为了列表
def get_data_list():
# 用于储存中间过程
data_process_list = []
# 用于存储过程对应的结果
data_result_list = []
# 将规则库数据预处理
data_str = txt_rule.split('\n')
for data in data_str:
data = data.split(',')
data_process_list.append(data[:-1])
data_result_list.append(data[-1].replace('\n', ''))
return data_process_list, data_result_list
# 特征值字典转为提示词
def character_dict_trans():
# 使用enumerate()函数获取字典的键值对及其索引
indexed_data = list(enumerate(character_dict.items()))
rsp_str = ''
# 使用for循环遍历这些键值对,每5个元素输出为1行
for i in range(0, len(indexed_data), 5):
line = ''
for j in range(5):
if i + j < len(indexed_data):
line += str(indexed_data[i + j][1][0] + ':' + indexed_data[i + j][1][1]) + ' '
# print(line)
rsp_str += line + '\n'
return rsp_str
# 通过传入的列表寻找结果
def find_data(process_data_list, dict_output):
# 依次进行循环查找并对过程排序
for index, data_process in enumerate(data_process_list):
# 用于判断此过程是否成立
num = 0
for data in process_data_list:
if data in data_process:
num += 1
# 过程成立则数值相同,可以进入下一步
if num == len(data_process):
# 此过程中结果是否为最终结果,不是将此过程结果加入到过程中
if data_result_list[index] not in result_dict.values():
# 弹出过程和此过程结果,因为此过程已经进行过,此结果存入需要查找的过程中
result = data_result_list.pop(index)
process = data_process_list.pop(index)
# 判断结果是否已经存在过程中,存在则重新寻找,不存在则加入过程,并将其存入最终结果
if result not in process_data_list:
dict_output[','.join(process)] = result
end_result = find_data(process_data_list + [result], dict_output)
if end_result == 1:
return 1
else:
return 0
# 存在则直接寻找
else:
end_result = find_data(process_data_list, dict_output)
if end_result == 1:
return 1
else:
return 0
# 找到最终结果,取出结果后返回
else:
process = data_process_list.pop(index)
dict_output[','.join(process)] = data_result_list[index]
return 1
# 快速排序算法
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + middle + quick_sort(right)
if __name__ == '__main__':
# 规则库数据转换为了列表
data_process_list, data_result_list = get_data_list()
print_str_start = '''输入对应条件前面的数字编号:
*************************************************************
'''
print_str_end = '''*************************************************************
*********************当输入数字0时!程序结束******************
'''
# 特征值字典转为提示词
character_str = character_dict_trans()
character_all_str = print_str_start + character_str + print_str_end
print(character_all_str)
# 存储用于查询的数据
list_data = []
# 循环进行输入,直到碰见0后退出
while 1:
input_num = input("请输入数字编号:")
# 当输入数字0时!程序结束
if input_num == '0':
break
# 输入数字编号,不在查询数据的列表中
if input_num not in list_data:
# 则加入查询列表
list_data.append(input_num)
# 将查询数字编号从小到大排序
sorted_list_data = quick_sort([int(i) for i in list_data])
# 打印查询条件
list_data_str = [character_dict[str(i)] for i in sorted_list_data]
print('查询条件为:' + ' '.join(list_data_str) + '\n')
# 用于存储输出结果
dict_output = {}
# 进行递归查找,直到找到最终结果,返回1则找到最终结果
end_result = find_data(list_data_str, dict_output)
# 查找成功时
if end_result == 1:
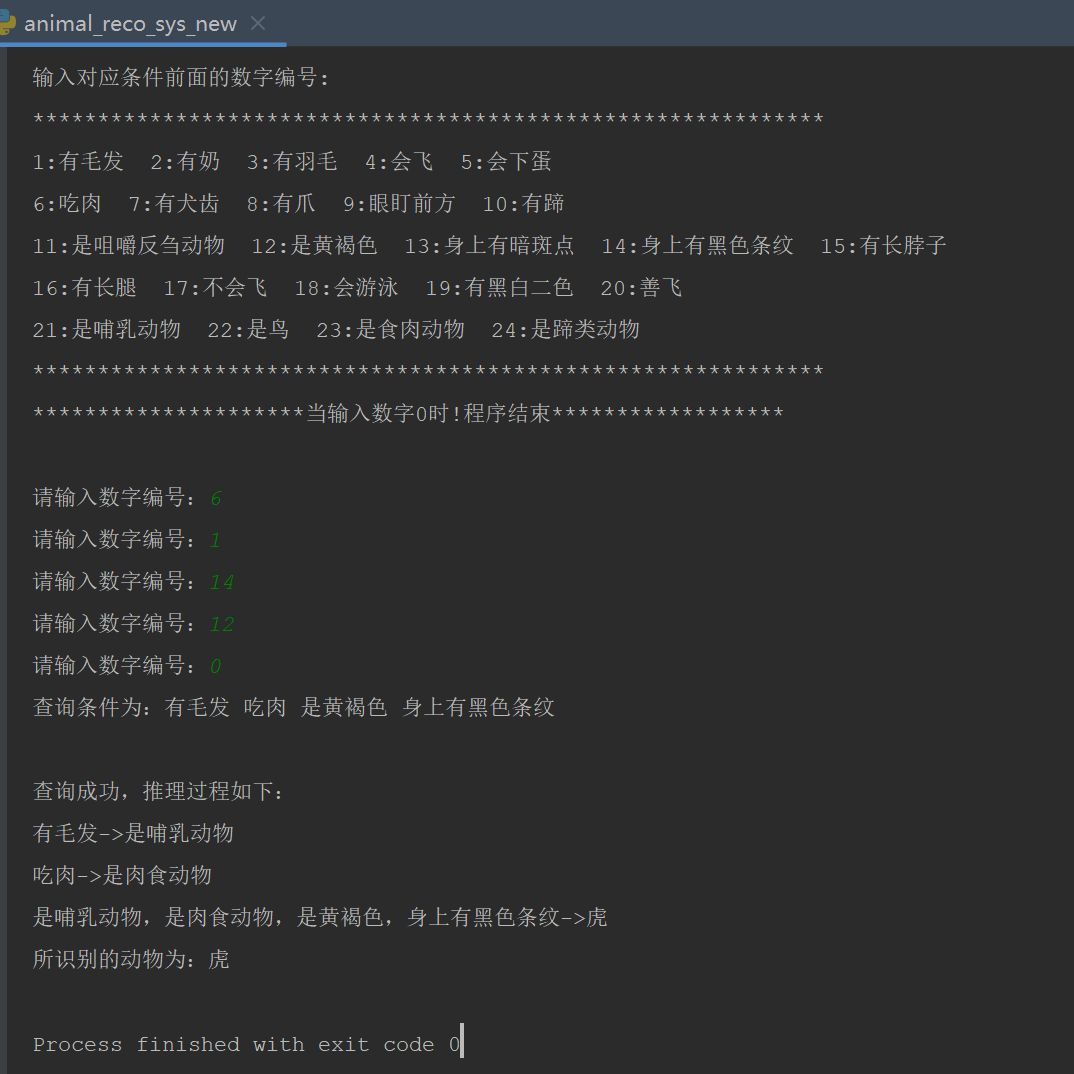
print('查询成功,推理过程如下:')
# 将结果进行打印
for data in dict_output.keys():
print(f"{data}->{dict_output[data]}")
# 得到最终结果即输出所识别动物
if dict_output[data] in result_dict.values():
print(f'所识别的动物为:{dict_output[data]}')
else: # 查找失败时
print('条件不足,无匹配规则,查询失败.')
6.运行测试效果
==========结束==========


![flutter 文本不随系统设置而改变大小[最全的整理]](https://img-blog.csdnimg.cn/78cdd58c983b4adb9293b3e00bbb0bac.jpeg)