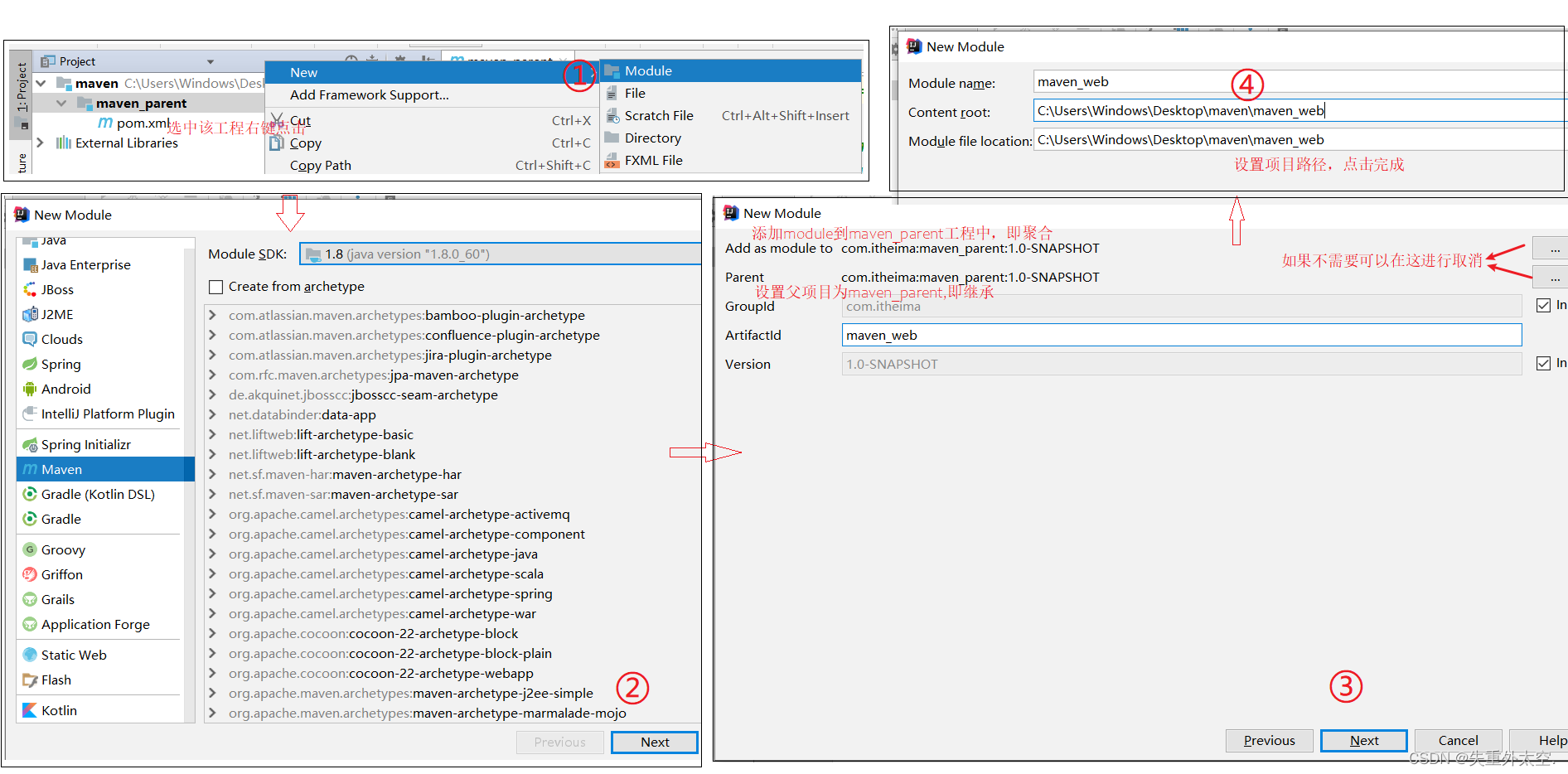
多模态融合是多模态学习领域的基础问题,也是多模态研究中非常关键的研究点。它旨在从多个模态(例如语音、图像、文本等)中提取有价值的信息和特征,并将这些信息融合在一起以提高系统的性能。这一领域的研究内容广泛,包括但不限于多模态算法的开发和优化、多模态数据的处理和分析、以及多模态产品的规划和设计。
目前有关多模态融合的研究工作已有了许多值得一看的成果,我简单整理了一下,今天就和大家分享16篇相关论文。项目源码以及论文原文需要的同学看文末
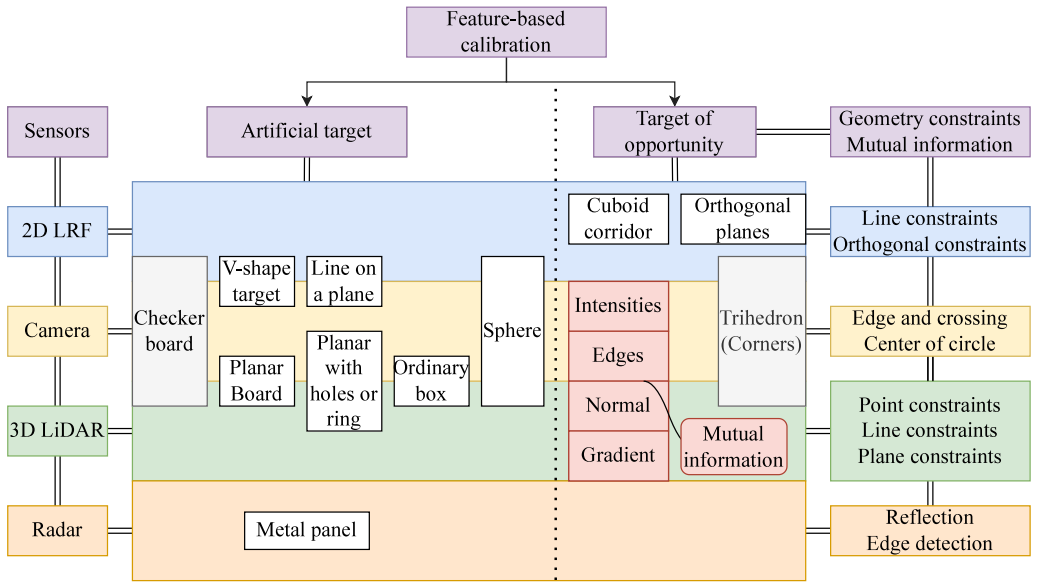
1、External multi-modal imaging sensor calibration for sensor fusion: A review
传感器融合的外部多模态成像传感器标定:综述
概览:本文综述了多模态成像传感器标定的研究现状,包括传统基于运动的标定和基于特征的标定。其中,目标基标定和无目标标定是两种常见的基于特征的标定方法。此外,系统标定是一个新兴研究方向。最后,本文总结了评估标定方法的关键因素,并讨论了其应用。未来的研究应该关注在线无目标标定和系统多模态传感器标定的能力。
2、Provable Dynamic Fusion for Low-Quality Multimodal Data
低质量多模态数据的可证明动态融合
概览:本文研究了多模态融合中的固有挑战,提出了动态多模态融合作为学习范式。通过理论分析,揭示了不确定性估计解决方案可以实现鲁棒的多模态融合。作者还提出了一种名为“质量感知多模态融合”的新型框架,可以提高分类准确性和模型鲁棒性。
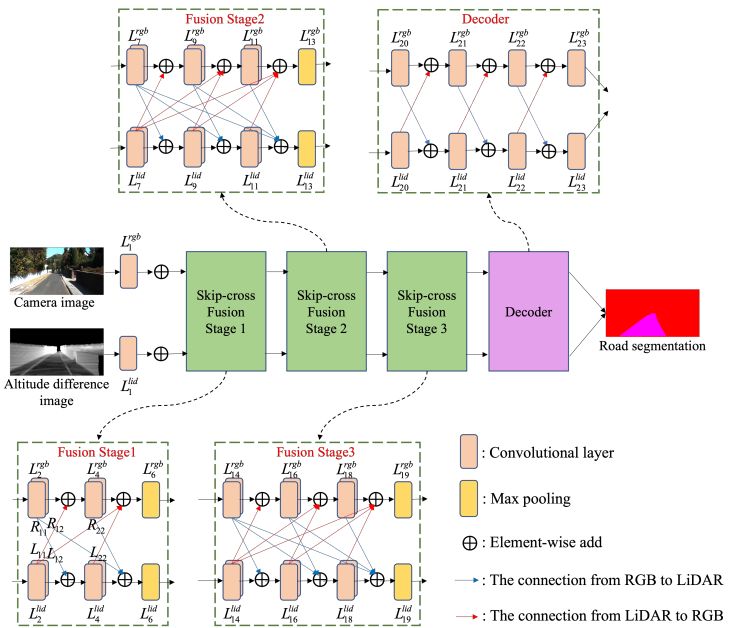
3、SkipcrossNets: Adaptive Skip-cross Fusion for Road Detection
用于道路检测的自适应跳过交叉融合
概览:本文提出了一种新型融合架构SkipcrossNets,用于自适应地将LiDAR点云和相机图像进行融合,以进行自动驾驶任务。该网络通过前向方式连接每一层,并使用所有先前层的特征图作为输入,并将其自身的特征图作为输入传递给后续层的另一种模态,从而增强特征传播和多模态特征融合。该网络还被分成几个块,以减少特征融合的复杂性和模型参数的数量。
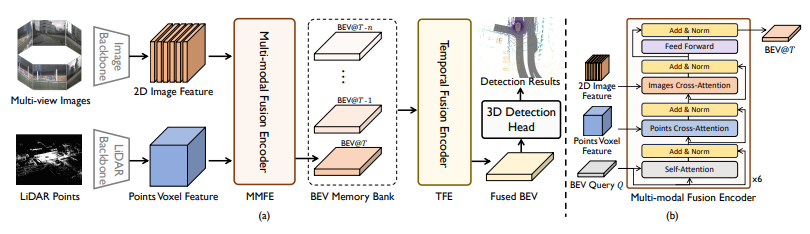
4、FusionFormer: A Multi-sensory Fusion in Bird's-Eye-View and Temporal Consistent Transformer for 3D Object Detection
面向三维目标检测的多传感器融合与时间一致性Transformer
概览:本文提出了一种名为FusionFormer的新型端到端多模态融合框架,用于3D物体检测任务。该框架通过在融合编码模块中引入可变形注意力和残差结构来解决现有方法需要将特征转换为鸟瞰图空间并可能丢失Z轴上的某些信息的问题。具体而言,该方法通过开发统一的采样策略,可以自然地从2D图像和3D体素特征中进行采样,从而利用灵活的适应性,并在特征拼接过程中避免显式转换到鸟瞰图空间。
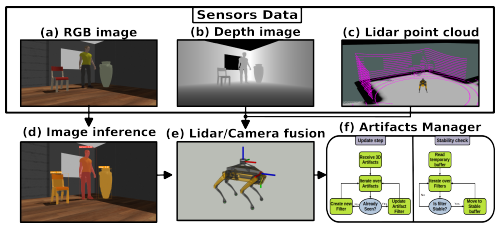
5、Artifacts Mapping: Multi-Modal Semantic Mapping for Object Detection and 3D Localization
多模态语义映射用于物体检测和3D定位
概览:本文提出了一种基于多模态传感器融合的框架,用于在已知环境中自主检测和定位预定义对象。该框架结合了RGB-D相机和激光雷达的RGB和深度数据,并能够准确地检测到真实样本环境中98%的对象。与单传感器实验相比,传感器融合允许机器人准确地检测近和远距离障碍物。
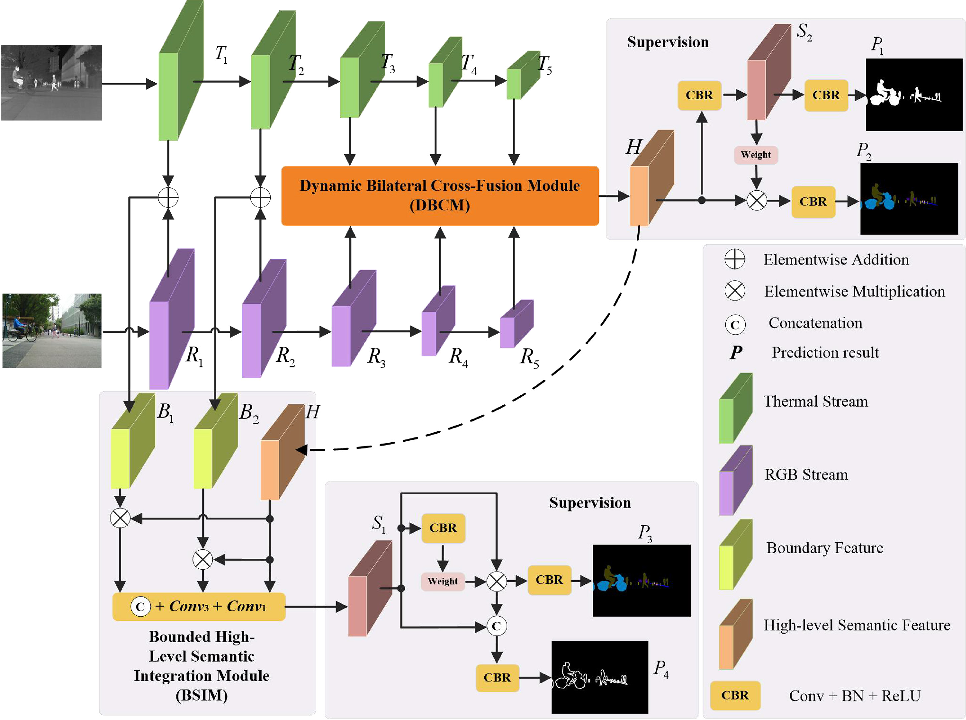
6、DBCNet:Dynamic Bilateral Cross-Fusion Network for RGB-T Urban Scene Understanding in Intelligent Vehicles
用于智能车辆RGB-T城市场景理解的动态双边交叉融合网络
概览:本文提出了一种名为DBCNet的动态双边交叉融合网络,用于智能车辆中RGB-T城市场景的理解。作者利用了RGB-T图像中的多模态信息,通过引入DBCNet来进行RGB-T城市场景理解。实验表明,DBCNet能够有效地聚合多层次的深层特征,并优于最先进的深度学习场景理解方法。
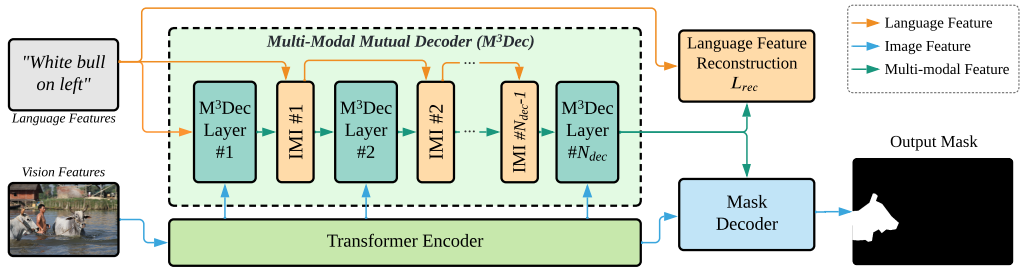
7、Multi-Modal Mutual Attention and Iterative Interaction for Referring Image Segmentation
多模态相互关注和迭代交互用于参考图像分割
概览:本文提出了一种名为多模态相互关注和多模态相互解码器的方法来解决参考图像分割问题。该方法通过更好地融合语言和视觉信息来提高模型对多模态信息的理解能力,并引入了迭代多模态交互和语言特征重建来允许连续和深入的交互以及防止丢失或扭曲语言信息。实验表明,该方法显著改善了基线并始终优于最先进的参考图像分割方法。
8、Transfusion:Multi-modal Fusion Network for Semantic Segmentation
用于语义分割的多模态融合网络
概览:本文提出了一种名为TransFusion的新模型,用于语义分割,该模型直接将图像与点云融合,无需对点云进行有损预处理。相比于使用带有深度图的图像的基本层FCN模型,TransFusion在Vaihingen和Potsdam数据集上将mIoU提高了4%和2%。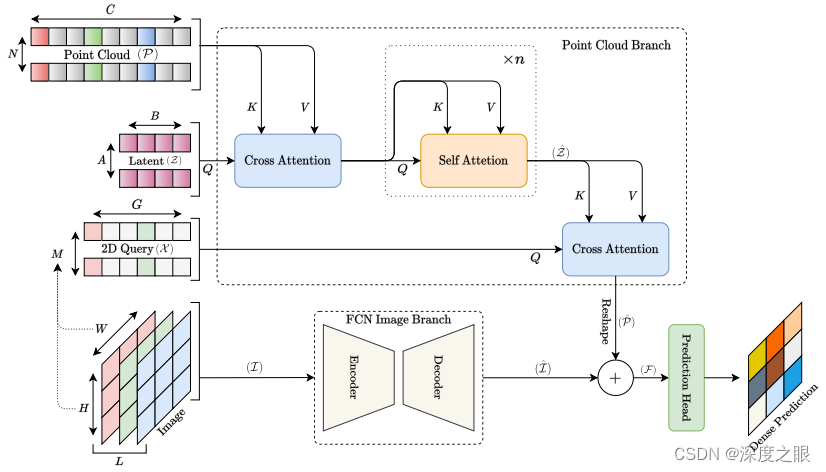
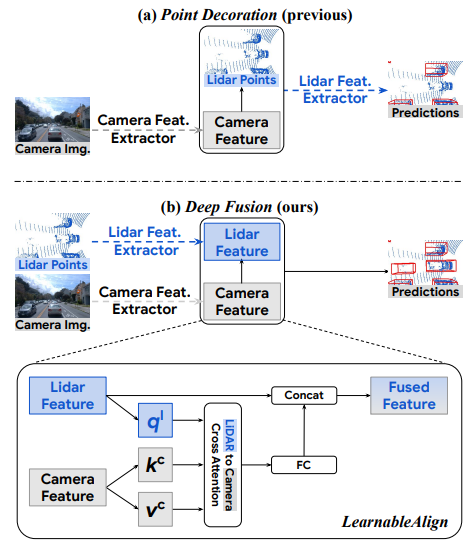
9、DeepFusion:Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection
用于多模态3D对象检测的激光雷达-相机深度融合
概览:本文提出了一种通用多模态3D检测模型,用于自动驾驶中激光雷达和相机的深度融合。作者认为融合深层激光雷达特征和相机特征可以获得更好的性能。为了解决两种模态的特征对齐问题,作者提出了InverseAug和LearnableAlign两种新技巧。基于这些技巧,作者开发了一组名为DeepFusion的通用多模态3D检测模型,该模型比以前的方法更准确。
10、Multi-exposure image fusion via deep perceptual enhancement
通过深度感知增强的多曝光图像融合
概览:本文提出了一种名为DPE-MEF的深度感知增强网络,用于多曝光图像融合。通过整合不同曝光的多个镜头来解决这个问题,本质上是一个增强问题。在融合过程中,应同时关注两个感知因素,包括信息量和视觉真实性。所提出的DPE-MEF包含两个模块,其中一个模块负责从输入中收集内容细节,另一个模块则负责最终结果的颜色映射/校正。实验表明,该网络在数量和质量上优于其他最先进的替代方案,并且在提高单个图像曝光质量方面具有灵活性。
11、Rethinking multi-exposure image fusion with extreme and diverse exposure levels: A robust framework based on Fourier transform and contrastive learning
一种基于傅里叶变换和对比学习的鲁棒框架
概览:本文提出了一种基于傅里叶变换和对比学习的鲁棒多曝光图像融合框架,可以处理具有极端和多样化曝光水平的图像。作者开发了一种基于傅里叶变换的像素强度转移策略来合成具有不同曝光水平的图像,并训练了一个编码器-解码器网络来重建原始自然图像。同时,作者还提出了一种对比正则化损失来进一步增强网络恢复正常曝光水平的能力。在三个基准数据集上进行广泛比较后,该方法在主观视觉效果和客观评价指标上都优于其他方法。
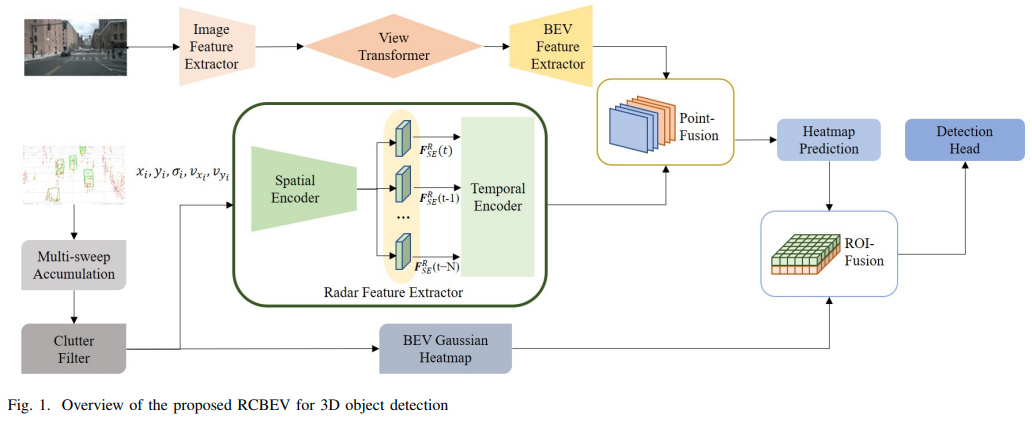
12、Bridging the View Disparity Between Radar and Camera Features for Multi-modal Fusion 3D ObjectDetection
基于multi-moda的雷达和相机特征之间的视差桥接
概览:本文提出了一种在鸟瞰图下实现雷达和相机特征融合的新方法,以用于3D目标检测。该方法使用多尺度图像2D特征和空间-时间编码器提取的雷达特征,通过视图变换将图像特征转换为BEV,并使用点融合和ROI融合模型进行多模态特征融合。实验结果表明,该方法在nuScenes数据集上实现了最先进的性能。
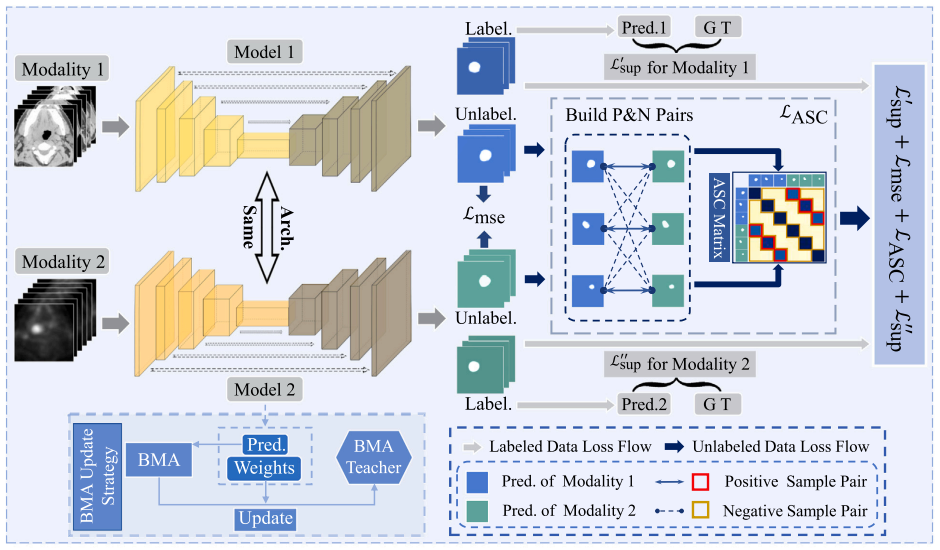
13、Multi-modal contrastive mutual learning and pseudo-label re-learning for semi-supervised medical image segmentation
半监督医学图像分割的多模态对比互学习与伪标签再学习
概览:本文提出了一种半监督对比互学习分割框架Semi-CML,该框架利用跨模态信息和不同模态之间的预测一致性进行对比互学习。虽然Semi-CML可以同时提高两种模态的分割性能,但两种模态之间存在性能差距,即存在一种模态的分割性能通常优于另一种模态的情况。因此,作者进一步开发了一种软伪标签再学习(PReL)方案来弥补这种差距。
14、Homogeneous Multi-modal Feature Fusion and Interaction 3D Object Detection
同质多模态特征融合和交互的三维物体检测
概览:本文提出了一种同质多模态特征融合和交互的三维物体检测方法(HMFI),用于自动驾驶中的多模态3D目标检测。该方法通过设计图像体素提升模块、查询融合机制和体素特征交互模块等技术,实现了点云和图像之间的跨模态特征融合和交互,避免了信息损失,提高了性能。

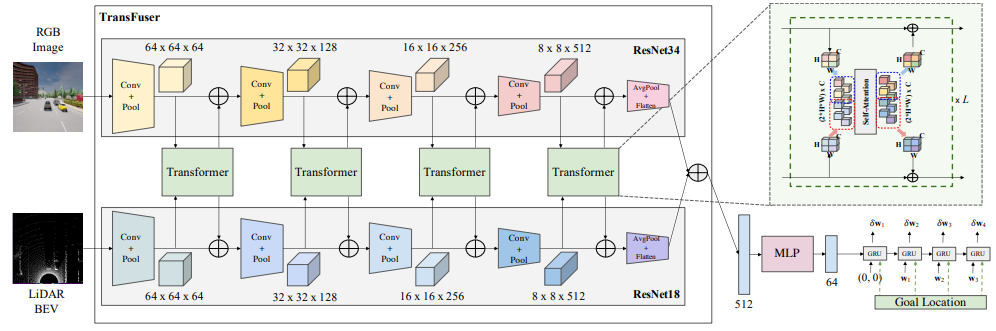
15、Multi-modal policy fusion for end-to-end autonomous driving
用于端到端自动驾驶的多模态策略融合
概览:本文探讨了如何将来自互补传感器的表示进行集成以实现自动驾驶。作者提出了一种名为TransFuser的新型多模态融合Transformer,使用注意力机制来集成图像和LiDAR表示。通过实验验证,该方法在复杂的场景中实现了最先进的驾驶性能,与基于几何的融合相比,碰撞减少了76%。
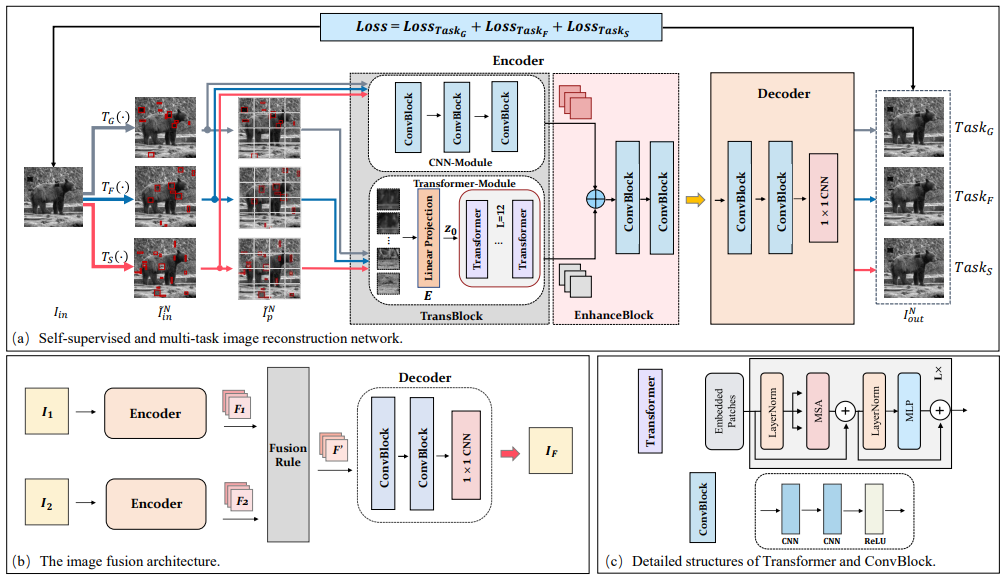
16、TransMEF:A Transformer-Based Multi-Exposure Image Fusion Framework using Self-Supervised Multi-Task Learning
基于Transformer的多曝光图像融合框架
概览:本文提出了一种基于Transformer的多曝光图像融合框架TransMEF,该框架使用自监督多任务学习。该框架通过三个自监督重建任务来学习多曝光图像的特征并提取更通用的特征。同时,为了弥补CNN架构在建立长期依赖关系方面的缺陷,设计了一个结合了CNN模块和Transformer模块的编码器。在多曝光图像融合基准数据集上,该方法在主观和客观评估中都取得了最佳性能。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“多模态融合”领取论文原文及源码
码字不易,欢迎大家点赞评论收藏!