位图
题目:

第一种方法:二分查找。虽然二分的时间复杂度为o(log n),但是这个方法是不可行的,我们就算假设这40亿个数据是已经排序完成了的数据,但是40亿个整数在内存需要消耗的内存就是差不多16G,这个消耗是非常巨大的,并且这16个g还必须是连续的空间。(这里最大的问题就是内存很难开出这样巨大的空间),放到红黑树,和哈希表自然也是不可行的,因为这些还具有其它的消耗(红黑树,哈希表的结构体中的其它消耗)。
分析一下这里其实询问的是我们去标记一个值到底在不在,而标记一个值到底在不在的最小的单位是bite。
因此这里我们就让每一个值映射一个bite,此时40亿个整数需要多少内存,多少个比特位,需要2^32个次方的比特位 42亿+(这里是按照开辟空间的范围去开的,不是按照需要多少整数去开的)

虽然我们在开空间的时候,能够让我们创建的最小的空间是1字节但是,不要忘了在c中是支持一个东西叫做位运算的。所以假设下面我们开设3个整型大小的空间。然后要记录某一个数在不在,那就去找到对应的整型然后,去整型中找到对应的位

例如40就是在第二个整型对应的空间中,然后是第八个位置。
然后下面的问题就是:

要计算在第几个整型很简单直接除以32就可以了。
一个整型大小就是32,使用x/32自然能够得到这个x在第几个整型,至于在第几个位直接使用x%32就能得到x/32的余数这个余数自然就是x在第几个位。
例如40/32等于1那么40就是在第1个位置的整型。
而40%32 = 8 代表40映射在第1个整型第8个比特位上 。
下面就是如何让整型单独的比特位如何设置的问题了。
例如此时这里存在一个整型,要如何做到让这个整型的第j位变成1呢?其余位不变
方法如下:
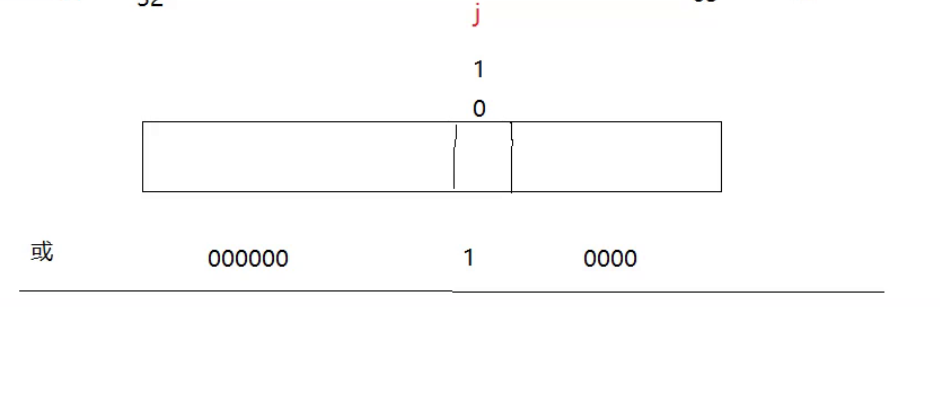
让这个整型或上横线上的那个数,横线上的那个数就是除了第j位是一个1其余位都是0.
那么下面的问题就是如何得到这个数。
方法就是让整型1左移j位就能得到这个数,然后按位或就完成了让整型的第j位变成1,其余位不变。
代码:

这里存在一个知识点就是左移一定是将当前位往高位移动,而右移一定是将当前位往低位移动,不能值认为数字1往左移动就一定是左移,因为存在大端机和小端机的区别
例如这里:

我要将这个1移动到第8位上从我们现在来看是不是往右移动,但是是左移。
这里我们要知道一点:左移和右移不是方向:
左移指的是往高位移动(具体是往左移动,还是往右移动不确定,因为存在大小端),右移是往低位移动 。
这里还可以将解一下整型在小端机中是如何储存的:

首先每一个字节整体都是低地址储存低位的整型数据,高地址储存高位的整型数据。但是在一个整型的内部空间中低位又是在右边高位在左边。上图中蓝色的0就在第一个整型的最右端。7在最左端。
总结就是:

下一个问题如果要将整型的第j位改为0要如何做呢?
方法如下:
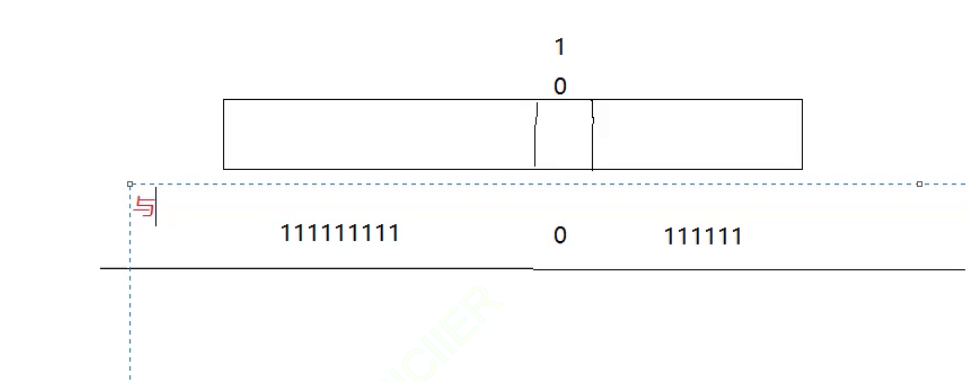
按位与的效果就是有0则为0,那么第j位就一定变成了0,其余位与上一个1是不会有任何的变化的。
那么如何得到这个数呢?很简单,让1左移j位之后按位取反即可。
代码:

下一个问题我要如何检测第j位是0还是1要如何检测
方法:
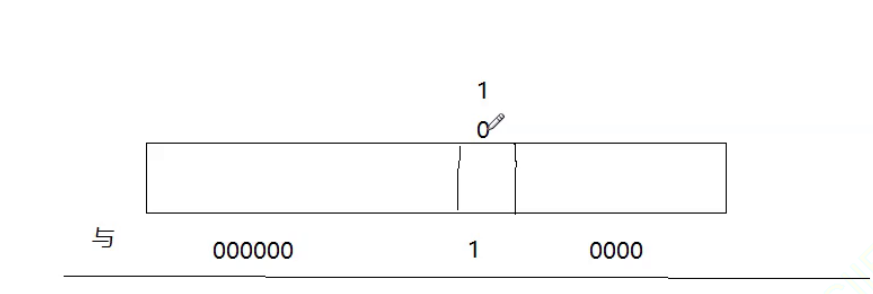
此时除了第j位可能是1之外其它位都是0如果,第j位是1此时与出来的数就是非0的,如果第j位是0那么与出来的数就是0。转化成bool的话,是1就是true,是0就是false
代码:

那么开空间的问题如何解决呢?
这里我们使用的是非类型模板参数来创建空间,问题在于vector中要创建多少的空间呢?
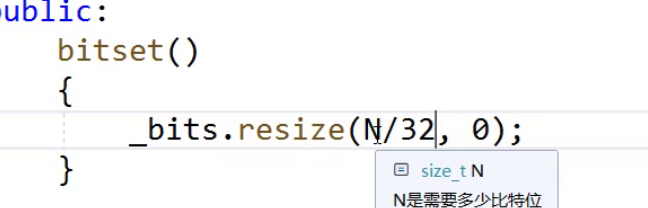
使用下面的方法是存在风险的,例如如果N是40,但是N/32得到是1,1个整型大小的空间只能映射1到32/0到31个数,是达不到40的所以使用N/32的方法创建空间是不可行的。
下面来解决这个问题:

首先第一步我们要如何表示40亿呢?
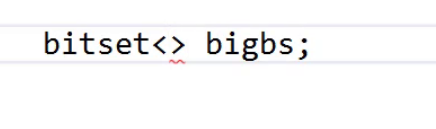
这里中间要怎么写呢?
这里不能使用INT_MAX,为什么不行呢?
因为INT_MAX真实的大小只是21亿多所以这里不可以使用INT_MAX
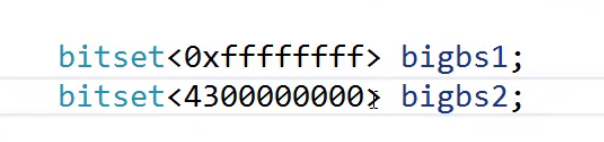
这里使用第一种是可以的,但是第二种不可行,存在截断的问题,因为整型的

这种方法也是可行的。然后解决方法就很简单了,将40亿个整数都映射到bitset中后,输入要找的数就可以解决这个问题。
下一个问题:
![]()
这里需要注意一点的是我们开辟空间的时候,不需要真实的开辟两个100亿的bitset因为这里并没有说是无重复数字的整数,所以其实这里面的整数是存在重复的,大概只会有40亿个整数。
此时不管你是100亿还是1000亿都只需要开42亿9千万个比特位即可(因为都会存在重复的数字)
这个问题如何解决呢?要找到只出现一次的。
这里要找到只出现一次的数,那么此时我们需要标记出三种状态。
刚才的寻找在不在只需要两个状态,而这里的判断只出现一次就需要三个状态。
因为数据量很大我们如何使用bit_set表示这三种状态呢?
第一种方法我们使用两个值表示一个位,
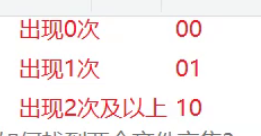
之前的一个比特位映射的就是一个数,现在是两个比特位来映射一个数。

此时一个整型能够映射的数就是0到15了。
这是其中的一种方法,但是其实还有一个方法能够解决这个问题。
此时如果你是使用一个biteset那么 i = x/16了,而j = x%16了,但是还有一种方法能够完成00,01和10完成设定的,那就是使用两个st来完成:
那么此时的set要如何判断呢?
如果一个数没有出现过那么就是00,出现过一次那就变成了01,而如果是从出现一次变成了出现两次那就变成了10,此时的10不仅代表这个数出现了两次还有可能是这个数已经出现了两次即以上了。
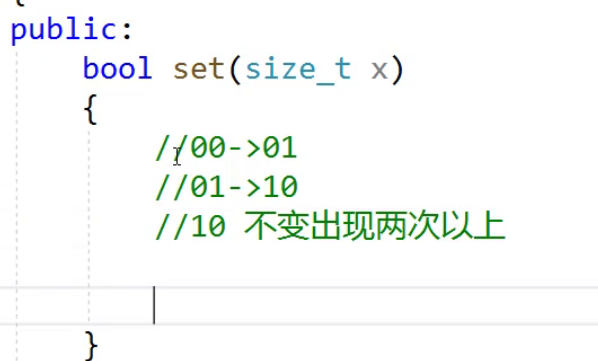
那么此时位图是如何映射数字的呢?

就是这样映射的。
然后下面就是代码的实现:

此时的第一个代码如果你是00,那么就会变成01,如果你是01,那就变成10。如果这个数已经是10,那么就不做任何的变化。
下一个问题:

逻辑很简单就不再重复了。
下一个问题:

首先就是分析每一个数出现次数的状态:

那么此时我们只需要修改一下twobit的代码就可以了。
布隆过滤器
我们首先来梳理一下搜索的场景:

那么要如何解决其它类型存在大量数据的情况呢?
我们之前是将一个整型,映射到一个比特位上,这样也就极大的节省了空间。
那么现在这里存在的是一个字符串,能不能也使用上面的方法判断呢?
直接使用肯定是不行的,但是我们可以将字符串(其它类型)转化成对应的整型,然后映射到对应的比特位上。
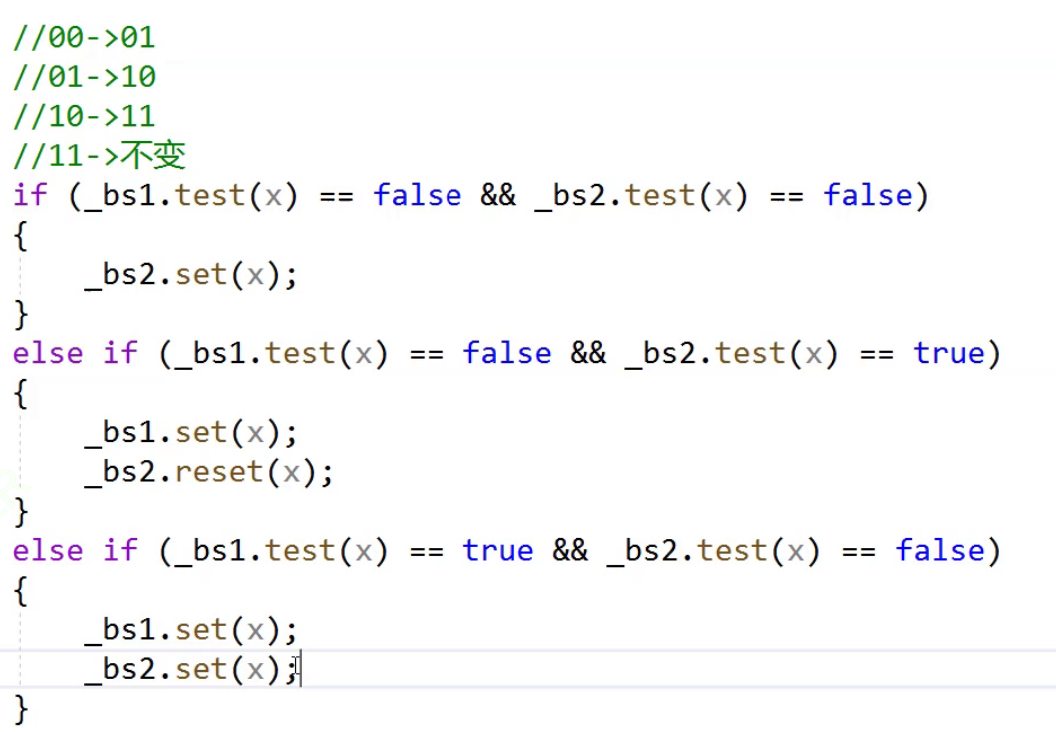
例如下面我们就能够使用一个byte,来表示sort和insert,在不在的问题。这列的优点也就很明显了,面对大量的字符串节省空间,并且非常的快。
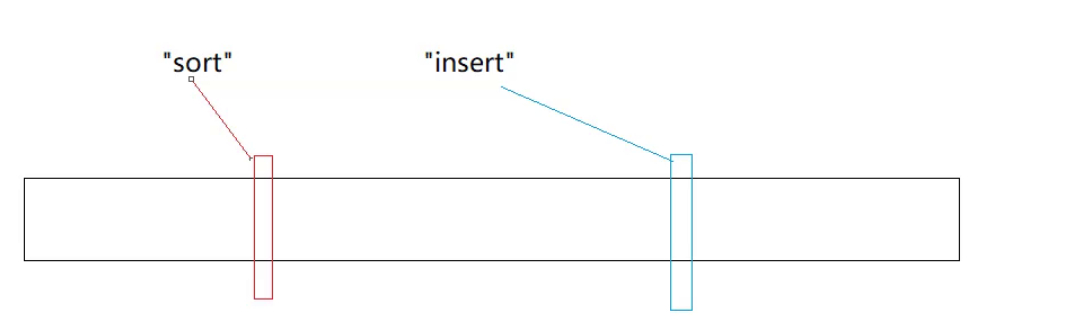
但是这样使用也是存在问题的,那么这么使用的问题是什么呢?
首先位图是一个整型值对应一个位,四个字节的整型最多也就是42亿多个数字。但是字符串是无限的,即使你限制了字符串的长度,排列出来的字符串数量也很多。
假设只取小写字母那么就是26^10,这个数量级很恐怖,更何况这还只是,小写字母,并没有将大写字母或数字加上。
这里的本质就是经过了两层的哈希,第一层将字符串映射到整型上,然后将整型映射到位图上:

但是因为字符串的数量是远远的大于整型的,所以一定会出现下面的问题:
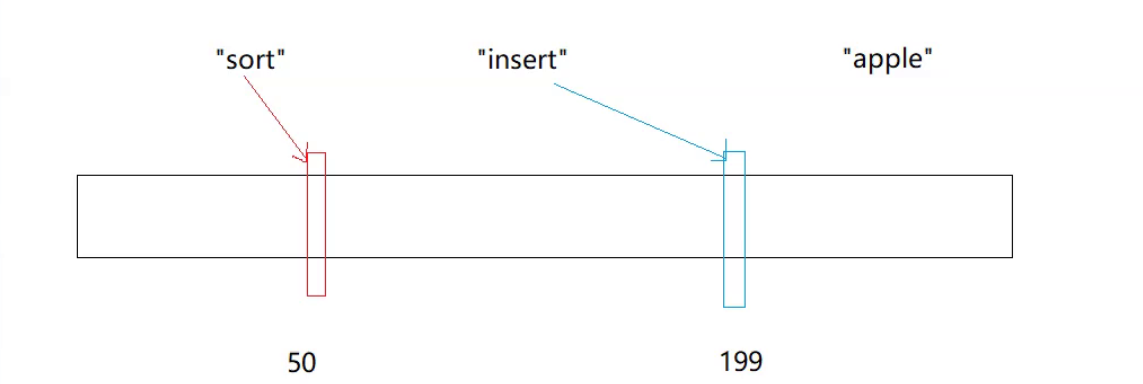
假设这里存在一个新的字符串为apple原出来的值也是199,那么如果此时你去寻找insert就就会出现误判的情况。
所以如果我们使用这个模型去储存的话,判断字符串在是准确的,还是不在是准确的呢?还是都不准确呢?
总结:
在是不准确的,例如上面insert不在容器中,但是返回的是在(apple也是199)。
但是不在是准确的,因为当容器中如果没有这个值,那么一定是不存在这个值的。

总结:布隆过滤器就是这样的一个具有一半准确的容器,即布隆过滤器判断不在是准确的,但是布隆过滤器判断在是准确的。
那么这里我们能否解决这个冲突呢?
答案是不能因为之前的哈希表能够解决是因为我们保存了这个值,但是布隆过滤器是不能保存值的。
那么能否缩小这个冲突发生的概率呢?
当然可以。
例如现在你的同学正在食堂吃饭,那你一定能够确定他在食堂吃饭吗?不能你要确认,只有让别人去帮你看一下,或者自己去确认,如果你让别人去帮你看了,那么别人的话一定是正确的吗?也不一定,有可能他也看错了,但是增加了你的同学正在食堂吃饭的概率,同理这里也是这个道理。
这里就是你使用多个哈希函数去让一个值映射在多个地方。
例如下面:
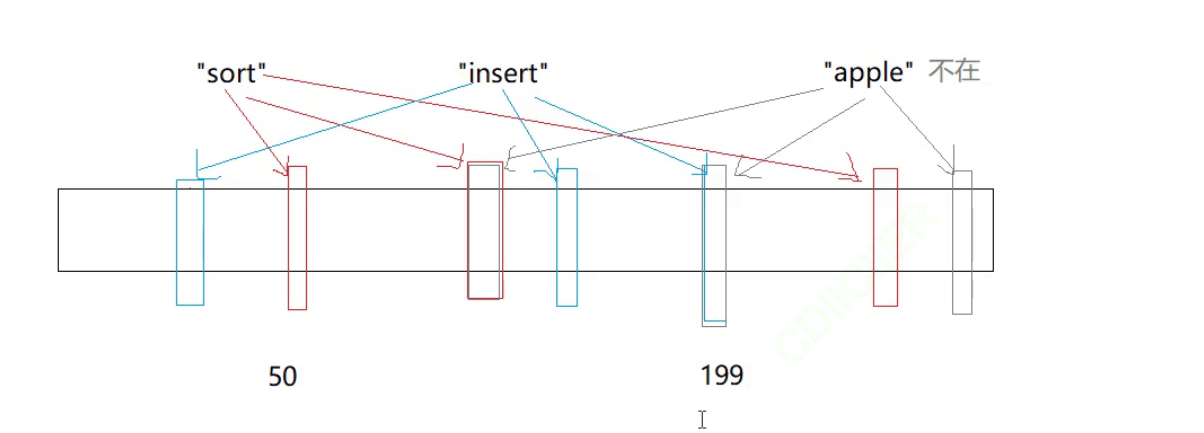
此时apple映射的三个比特位中有两个值已经冲突了,但是还有一个值是不在的,所以apple就是不在的,此时也就降低了apple误判的可能性。
总结:

这里也不能让一个值映射很多很多的位,因为布隆过滤器设计的特点就是位了节省空间,如果一个值映射很多很多的位了,那就不能节省空间了。
所以布隆过滤器的使用场景:

例如下面的情景:
例如这里存在一个需要注册账号的情景,

如果此时这个昵称在数据库中已经注册过了,那么这里就会返回一个错误。那么假设我们这里的要求是快速的判断这个名称是否被注册过呢?(即不去数据库中查找一遍)。
如何做到呢?这个时候我们可以在当前的客户端上搞一个布隆过滤器。将所有的昵称都放到布隆过滤器中,映射出来(并没有储存昵称只是使用byte储存了这些昵称映射的值)。
那么下面我输入一个昵称如果不在那就是勾,如果在就是差,那么会不会导致一个昵称存在两个用户都在使用?
答案是不会导致这种现象的发生。
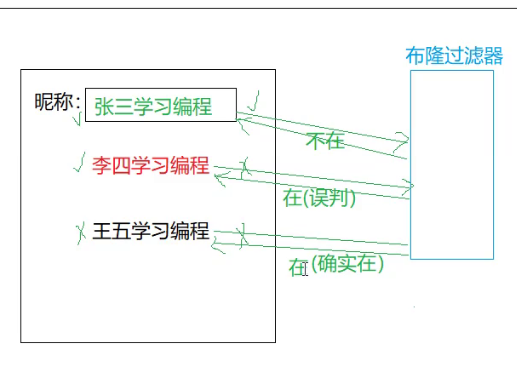
下面就是模拟实现图:

此时张三学习编程这个名字肯定是不存在于这个数据库中的。
但是下面李四学习编程这个名字布隆过滤器返回的是这个名字已经存在与数据库中了,但是这个其实是不准确的,此时存在两种情况情况一就是李四学习编程这个名字确实已经在数据库中存在了。但是还有一种情况就是出现了误判。此时能够保证的如果这个名称没有用过就一定没有人用过。但是如果返回的是有人用过是存在误判的,但是不存在太大的影响。此时这就是一个可以接收误判的场景。
即:

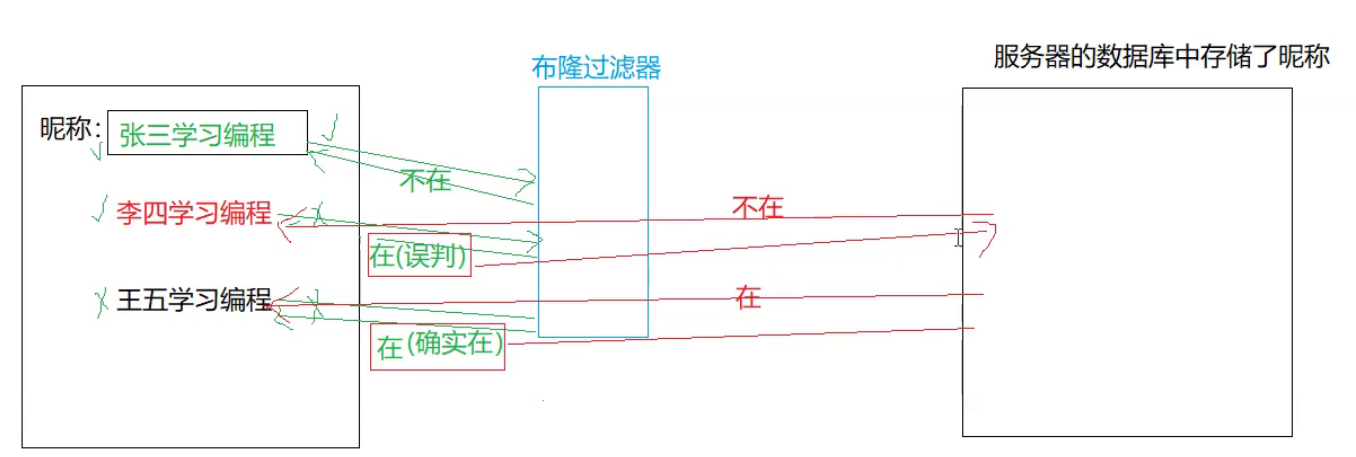
下面我们来看这个情景的拓展问题,假设这里不能容忍这种误判了(李四学习编程没有人注册出现了误判了),那么要如何处理呢?
假设下面的情景:

此时张三没有注册过所以此时返回的结果是准确的。而李四也是没有注册过的,但是返回值不准确,而最后的王五是注册过的,最后返回的也是在。
那么现在要如何做到将误判也处理了呢?
解决思路就是:如果布隆过滤器最后返回的是不在代表此时的结果是准确的,不会做任何的处理,但是如果最后返回的是一个在,那么此时为了能够所有的结果都是准确的,这里选择的就是对布隆过滤器返回在的结果都交给服务器端在去做一个准确的判断,如果这个值在,那么这就是真的在了,如果这个值不在那么这个值就是不在。
此时的这个布隆过滤器就过滤了某些情况,对于布隆过滤器返回不在的结果是不需要在进行判断的,而对于在的结果是需要进行二次确定的。
虽然最后都是去服务器上找了,但是过滤了一些数据,减少了去服务器上寻找的次数。

假设存在上面的数据,如果是之前的方案,那么最后需要在服务器上寻找1w次,但是经过布隆过滤器之后,就只需要去服务器上查找5000次了。去服务器上查找数据对比直接在布隆过滤器上查找数据是慢了很多的。
此时上面的两种场景都是适合于使用布隆过滤器的。
第一种我能够接受名称出现误判的情况,第二种一定要要求结果准确的话,那么也可以过滤掉一些准确的数据,增加效率
在以上的两种实际情况中布隆过滤器使用的是很多的。
布隆过滤器也给了我们一个新的思路,虽然布隆过滤器是存在误判的,但是依旧是存在可以使用的很好的场景,一般人如果看到了布隆过滤器可能会出现误判,然后想着怎么解决,发现无法解决就不想了,但是设计布隆过滤器的大佬,既然你映射在无法做到完全准确,那就降低一下概率(映射多个位),还有就是上面的如何使用布隆过滤器的场景即使出现了误判,也能够使用布隆过滤器。这些大佬在设计布隆过滤器的时候,肯定是已经将这两个情景想明白了的。
现实中还有一个情景使用这个布隆过滤器使用的很广。
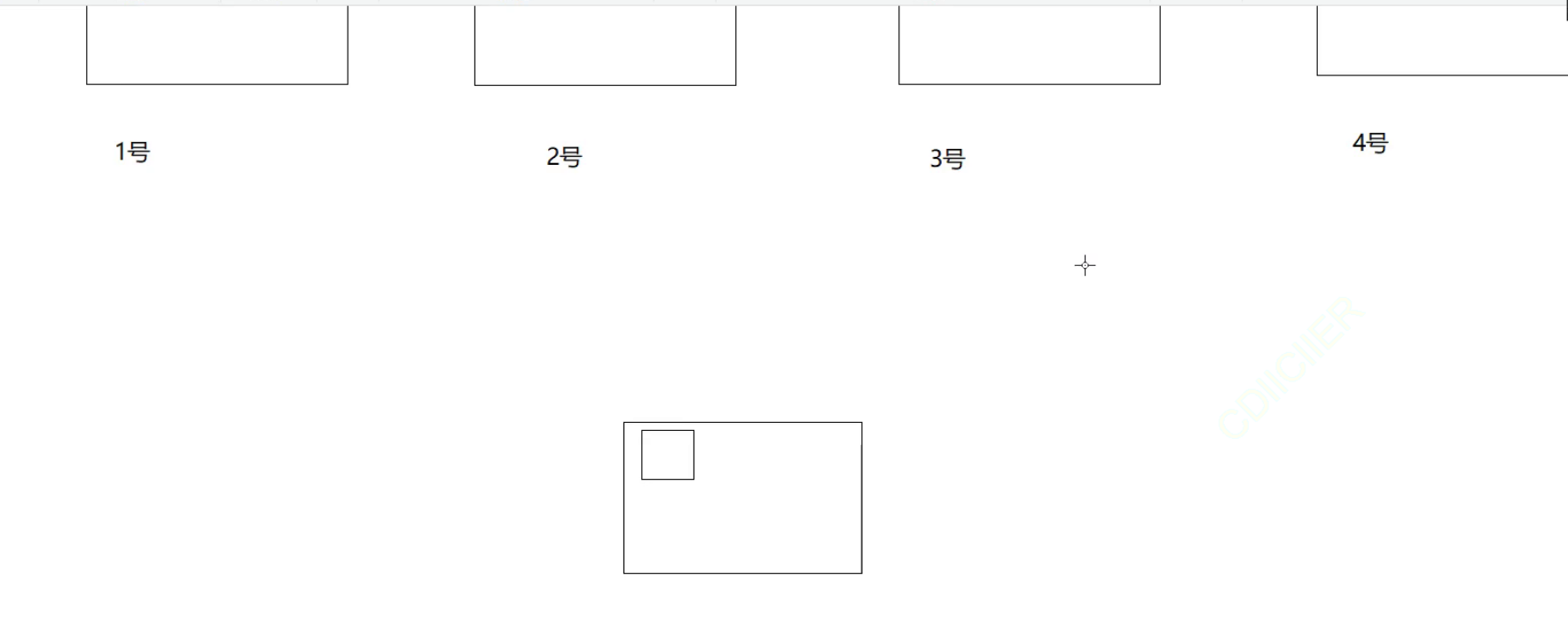
此时这里存在四台存放信息的服务器(因为信息很多,难以做到一台服务器储存),那么此时我在自己的电脑上寻找查找某些信息,我怎么知道是存在哪一台服务器上的呢?
这里就是使用你账号上的id去进行哈希然后模上四,得到的这个数就是你的信息所在的服务器。
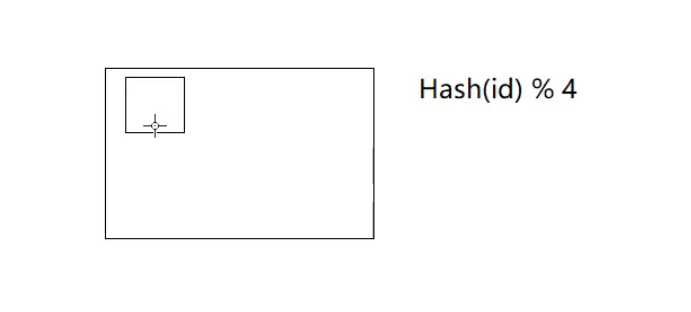
id是不变的。因为你储存信息的时候走的是这个步骤,取的时候走的也是这个步骤最后得到的服务器号自然也是一致的。但是如果出现了4台服务器都无法完全储存这些信息了,需要扩展服务器,而为了不出现错误,所有用户信息的映射规则自然也是需要做出改变的,此时如果还是使用上面的哈希方法在扩展服务器的时候代价是很大的。
所以就有人提出了一致性哈希(这里不细说了)。
下面我们需要看一下:如果要实现这个布隆过滤器,就有几个考虑的点,哈希函数的个数和布隆过滤器长度。
对于这两个点的影响有一个数据影响图:
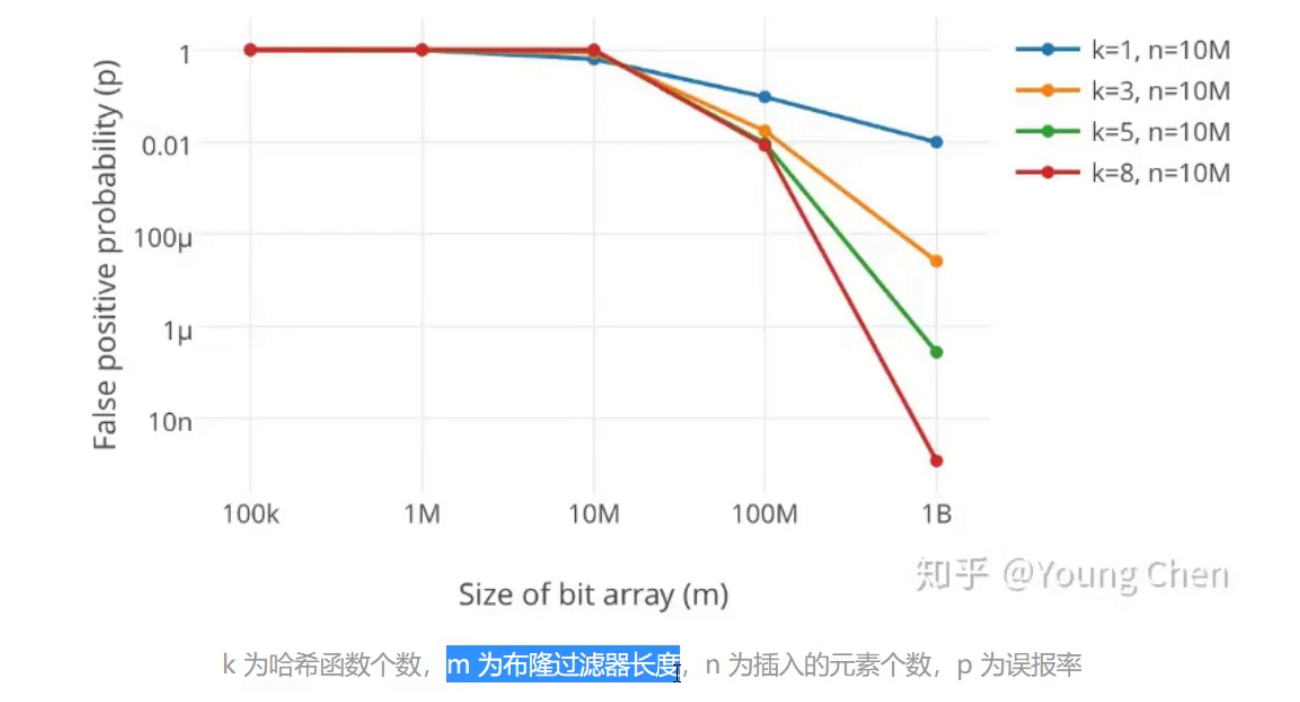
从这张图我们可以看到这个误判率和空间以及哈希函数的个数有关。
在空间和值呈现10倍的情况下,哈希函数越多误判率也就越低。但是在100m布隆过滤器的情况下:k在1和3个的情况下,误判率下降是很明显的,但是在3到5和8的时候误判率下降就不明显了。
关系图如下:

根据这个公式就能够得到一个结论:


所以元素和空间大小的关系差不多呈4/5倍的关系。
由此我们就能够来模拟实现布隆过滤器了。实现布隆过滤器的很多规则都是很简单的,但是在一般情况下Reset函数在默认情况下是不能实现的。原因如下:
如果要完成删除映射,那么就需要将key对映的三个哈希数设置为0,为何不能将这三个数设置为0呢?因为这一个哈希数映射的key可能不止一个,如果此时就将哈希映射的数设置为0,那么其它映射的数就出错了。

那么有没有什么方法能够完成删除功能呢?
此时我们这里出现的问题就是,删除一个值就会影响其它的值,那么有没有什么方法能够让删除一个值不会影响其它的值呢?
这个方法就是引用计数。
例如某一个位置是两个值映射那就++这个地方的值,那么此时这个地方就不能是一个比特位了因为一个比特位只能是0和1了。如果需要增加引用计数自然也需要增加比特位,那么究竟需要几个比特位呢?如果你使用8个比特位来当作引用计数,那么一个哈希地就能够对映255个值,也就是可以存在255个key指向这个哈希值。此时映射一个值就需要使用八个比特位了,当然这个值能够对应的key就有255个了,这里就是消耗了空间来达到删除的功能的。此时当需要删除某一个节点的时候,只需要将对应的引用计数-1就可以了,也不会影响其它的值。所以如果要支持删除也是可以的,只需要使用多个位来标记一个值。

此时布隆过滤器的优势也就降低了,因为布隆过滤器的优势就是节省空间。
有一个需要注意的点就是当空间足够大的时候,能够让布隆过滤器的误判率达到0(字符串已经可以被确定数量了),但是这就让布隆过滤器的节省空间的优点被降低了。
对于布隆过滤器最重要的一点就是要注意布隆过滤器在什么情况下会造成误判,当这个值不存在于布隆过滤器时,此时的布隆过滤器返回的答案是准确的,而这个值存在是返回的true反而是不准确的(因为可能存在其他值映射到了这个地方造成来返回值为true)。
下面我们来看一下下面的题:

这里的query指的就是查询 。例如一个网站的链接就是一个query,网站的网址就是一个查询,需要网址所在的服务器做出回应。
此时这里存在很多的查询此时需要我们找出两个文件的交集。
此时这里需要使用使用近似算法和精确算法两种方法,近似算法也就是使用布隆过滤器,那么精确算法呢?
近似算法就是先将一个文件1中的query映射到布隆过滤器中,然后将文件2中的query读取出来用于判断这个query是否出现在文件1中,此时返回的true就可能会误判,因为可能在文件1中映射到这个位置的query和文件2中的query只是得到的hashi一样。但是query不一样。
此时的交集就是不纯粹的。此时是交集的一定会被计算入内,但是某些不是交集的query也可能会进入到交集中。这也就是近似算法,那么准确算法要如何做呢?
首先我们计算一下这个文件占据多少空间。

那要怎么做呢?

首先这里存在两个100g的文件,首先你可以从A中读取一个query然后去B中遍历一遍,如果在B中那就是一个交集。然后在从A中读取第二个query。依次将A中的每一个query都和B中的每一个query比较一次。
但是这个暴力查找非常慢。有没有其它方法呢?
那么既然大文件搞不了,那就将大文件不断的分解成小文件,

但是现在这样做了但是效率任然没有本质的提升。
所以这里切小的时候一定不是平均切分,使用的是下面的切分方法:

这就是哈希切割,那么切了之后,要如何找交集呢?
此时找交集就很轻松了,A0只需要和B0比较,A1也只需要和B1比较以此不断比较,此时A0和B0等小文件比较小是可以放到内存中去的。然后在内存中使用寻找交集算法即可。那么为什么Ai和Bi找交集即可呢?
原因就在于哈希切分,由于哈希切分的存在,那么A和B中的相同的query经过哈希切分之后,一定会进入的是编号相同的小文件。
此时一个小文件就不需要和另外一边所有的小文件比较了。
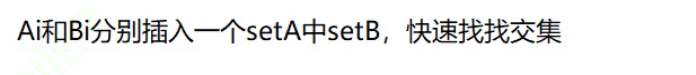
那么上面使用的这个方法存不存在什么问题呢?哪一个部分有问题呢?
首先这里将大文件切割成小文件的目的是能够让小文件被加载得到内存(直接切割会导致遍历时很慢,所以这里使用了一个哈希切割),那么当哈希切割之后有没有可能某一个文件太大了无法加载到内存中(平均切分不会出现但是哈希切分会出现),即此时某个query冲突的很厉害,让某个小文件的内存达到了10G,那么此时这个小文件自然也是无法进入内存中了。

如何处理呢?

这里就是不要一个文件太大就直接继续切分,而是继续放到set中进行去重,如果set抛异常了在去进行哈希切分。
因为情况1二次切分是无法处理的,而进入到set中就能够进行去重。
下一个问题:

或者题目和上面的题思路是类似的,首先还是切分

这里模的是100,因为这里总的文件大小就是100GB,那么在理想的情况下,我摸上100,那么得到的就是1GB(能够让内存放下),然后统计ip出现的次数即可。
如果这里使用的是平均切分是不可行的,因为某一个同样的ip使用平均切分的方法,可能会出现在A0,A1,A99等不同的小文件,那么我们只统计一个小文件是不准确的。
所以这里使用的依旧是哈希切分。在切分之后在内存中使用map统计次数。经过哈希切分之后相同的ip也就进入了同一个文件(虽然可能会存在不同的ip也进入同一个文件,但是相同的一定也是进入了同一个文件)。此时就不会出现同一个ip即在A1,又在A2了。

统计完后记录出现最多的,然后遍历完所有的文件,就能够找到出现次数最多的ip了,对于前k个出现次数直接建立一个小堆即可。如果分割内存不够了,那就再次切分(冲突太多了,再次切分)。
位图代码
#pragma once
#include<vector>
namespace LHY
{
template<size_t N> // 这里使用的是非类型模板参数
// 用于开辟空间
class bitset
{
public:
bitset()
{
_set.resize(N/32+1); // 这里需要按照N开辟足够的空间
// 一个整型能够映射的数是32个
// 这里为了防止最后除法会导致某些值被销毁,导致空间出错,所以这里需要加上一个1
}// 到此构造函数完成
void set(int t)
{
// 第一不需要找到这个t在第几个int中
int i = t / 32;// 找到在第一个整型的byte中
int j = t % 32;// 找到在第几个整型的第几个比特位中
// 下面就需要将第i个整型的第j个比特位给变成一个1;
_set[i] |= (1 << j);
}//set函数的功能就是将t映射到bitset中去
void reset(int t)
{
// 将一个已经映射完成的数,接触映射
int i = t / 32;// 找到在第一个整型的byte中
int j = t % 32;// 找到在第几个整型的第几个比特位中
// 下面需要将第i个整型的第j个byte位变成0,并且不能影响到其余byte位
_set[i] &= (~(1 << j));// 将1先左移到第j位,之后按位取反,然后再让这个整型按位与上即可完成
}
bool test(int t)
{
int i = t / 32;// 找到在第一个整型的byte中
int j = t % 32;// 找到在第几个整型的第几个比特位中
// 这里就是需要检测第i个整型的第j位是1还是0
// 如何获取呢
// 让对应的byte按位与上一个数(这个数除了第j位是1之外其它位是一个0)
return _set[i] & (1 << j);
//如果这个数最后是0代表这个数没有放到set中返回的自然是false
//如果是非0的数那么证明这个数已经存在与bitset中返回的自然是true
}// 这个函数的功能就是探测t这个位是否出现过了
size_t size()
{
return N;
}
private:
vector<int> _set;// bitset容器
};
}
布隆过滤器代码(没有实现删除)
#pragma once
struct BKDRHash
{
size_t operator()(const string& key)
{
// BKDR
size_t hash = 0;
for (auto e : key)
{
hash *= 31;
hash += e;
}
return hash;
}
};
struct APHash
{
size_t operator()(const string& key)
{
size_t hash = 0;
for (size_t i = 0; i < key.size(); i++)
{
char ch = key[i];
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ ch ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ ch ^ (hash >> 5)));
}
}
return hash;
}
};
struct DJBHash
{
size_t operator()(const string& key)
{
size_t hash = 5381;
for (auto ch : key)
{
hash += (hash << 5) + ch;
}
return hash;
}
};// 以上三种是将字符串转化为哈希数的三种不同方法。
// 下面来实现布隆过滤器
template<size_t N,
class K=string,
class HashFunc1 = BKDRHash,
class HashFunc2 = APHash,
class HashFunc3 = DJBHash>// 使用非类型模板参数
//因为需要创造三个不同的哈希函数所以这里使用了三个不同的获取哈希数的方法
class BloomFilter
{
public:
void set(const K& key)
{
// 首先就要获取三个不同的哈希数
size_t hashi1 = HashFunc1()(key) % _bt.size();
_bt.set(hashi1);
size_t hashi2 = HashFunc2()(key) % _bt.size();
_bt.set(hashi2);
size_t hashi3 = HashFunc3()(key) % _bt.size();
_bt.set(hashi3);
}//将key对应的三个哈希数设置为存在
//void reset();//在一般情况下是不需要完成删除映射的关系的,因为如果要完成删除映射的关系需要增加空间
bool test(const K& key)
{
size_t hashi1 = HashFunc1()(key) % _bt.size();
if (_bt.test(hashi1) == false)
{
//此时代表key这个值是一定不存在于布隆过滤器中的
return false;
}
size_t hashi2 = HashFunc2()(key) % _bt.size();
if (_bt.test(hashi2) == false)
{
return false;
}
size_t hashi3 = HashFunc3()(key) % _bt.size(); // 以上都是使用了匿名对象
if (_bt.test(hashi3) == false)
{
return false;
}
//以上三种方式都是准确的,因为布隆过滤器返回false是一定准确的
//使用哈希函数找到这个key映射的三个地方
return true;// 此时返回的true就不一定了,会出现误判。
}//这里就是检测了
private:
LHY::bitset<N> _bt;
};
void testFilter()
{
BloomFilter<1000> count;
count.set("孙悟空");
count.set("猪八戒");
count.set("沙悟净");
count.set("唐三藏");
count.set("二郎神");
count.set("太上老君");
cout<< count.test("孙悟空") << endl;
cout << count.test("孙悟空1") << endl;
cout << count.test("孙悟空2") << endl;
cout << count.test("孙悟空 ") << endl;
}
void TestBF2()
{
srand(time(0));
const size_t N = 10000;
BloomFilter<N * 40> bf;
std::vector<std::string> v1;
//std::string url = "https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html";
std::string url = "猪八戒";
for (size_t i = 0; i < N; ++i)
{
v1.push_back(url + std::to_string(i));
}//首先创建了N个字符串,将这些字符串放到了vector中
for (auto& str : v1)
{
bf.set(str);
}//将vector中的字符串全部放到bf中将其设置为存在
// v2跟v1是相似字符串集(前缀一样),但是不一样
std::vector<std::string> v2;
for (size_t i = 0; i < N; ++i)
{
std::string urlstr = url;
urlstr += std::to_string(9999999 + i);
v2.push_back(urlstr);
}//然后这里再创建了N个相似的字符串
size_t n2 = 0;
for (auto& str : v2)
{
if (bf.test(str)) // 误判
{
++n2;
}//因为并没有将str放到放到bf中,但是如果还是出现了true,那就让n2++
}
cout << "相似字符串误判率:" << (double)n2 / (double)N << endl;//然后输出误判率,这里的误判率就是相似字符串
// 不相似字符串集
std::vector<std::string> v3;
for (size_t i = 0; i < N; ++i)
{
//string url = "zhihu.com";
string url = "孙悟空";
url += std::to_string(i + rand());
v3.push_back(url);
}
size_t n3 = 0;
for (auto& str : v3)
{
if (bf.test(str))
{
++n3;
}// 这里就是测试不相似字符串
}
cout << "不相似字符串误判率:" << (double)n3 / (double)N << endl;
}希望这篇博客能对你有所帮助,写的不好请见谅,如果发现任何错误欢迎指出。