目录
前言:
一、软件工程中的软件设计种类:根据宏观到微观分
(1)软件架构设计(层次划分、模块划分、职责分工):
(2)软件高层设计、概要设计(功能模块的接口与协作细节):
(3)软件详细设计(模块内具体实现方式):
二、软件设计的性能指标:高内聚、低耦合分类
2.1 概述
2.2 内聚类型(模块内部):高内聚
2.3 耦合类型(模块之间):低耦合
参考:
前言:
软件设计按照阶段分为:架构设计、高层设计/概要设计、详细设计。结构化设计是软件设计的基础,高内聚、低耦合是评估软件设计非常重要的指标。在开始软件设计之前,我们先讨论一下这个主题。
一、软件工程中的软件设计种类:根据宏观到微观分
软件架构设计、软件高层设计和软件详细设计是软件开发中三个重要的设计层次,它们各自关注不同的设计方面,如下所述:
(1)软件架构设计(层次划分、模块划分、职责分工):
确定软件系统的整体结构和组织方式,包括系统的分层、模块划分、框架选择等。系统架构设计关注系统的稳定性、可靠性和可扩展性,以及系统各个组成部分之间的交互和接口。软件架构设计是从系统整体级别出发,通过对系统的组成部分、各部分之间的关系及其所承担的功能等进行梳理和设计,确定系统总体的结构风格、包括框架和组件的分配、接口、数据流动等。软件架构设计的目的是为整个系统提供一个坚实、可靠、高效、稳定和可维护的基础,需要考虑因素包括系统的可用性、可伸缩性、可维护性、可安全性等。关注整体的非功能性需求!!!
(2)软件高层设计、概要设计(功能模块的接口与协作细节):
软件高层设计是在软件架构设计的基础上进行的,它关注的是系统中各个模块和组件的功能细节和交互方式,确定系统各个模块之间的接口方式和合理的协作关系,从而实现系统的预期功能。由于高层设计服务于架构设计,其需要考虑到诸如结构合理、功能完备,以及后期的扩展和调整等目标。关注接口定义,与编程语言无关!!!
(3)软件详细设计(模块内具体实现方式):
软件详细设计是在软件高层设计的基础上进一步细化,关注的是每个模块和组件的实现和具体实现方式,包括数据结构、算法、代码实现等方面的细节问题,其目的是为软件开发的人员提供具有可行性和可实现性的详细设计方案。详细设计涉及到诸如如何编写代码、如何测试代码、如何实现功能等具体实现问题,其层次较为具体化,详细设计直接指导编码实现!与具体的编程语言相关!!!
因此,软件架构设计、软件高层设计和软件详细设计在软件开发的不同阶段发挥着至关重要的作用。一个好的设计方案可以有效地解决软件开发中的复杂性和不确定性,并提高软件的可靠性、可维护性和可扩展性。
二、软件设计的性能指标:高内聚、低耦合分类
2.1 概述
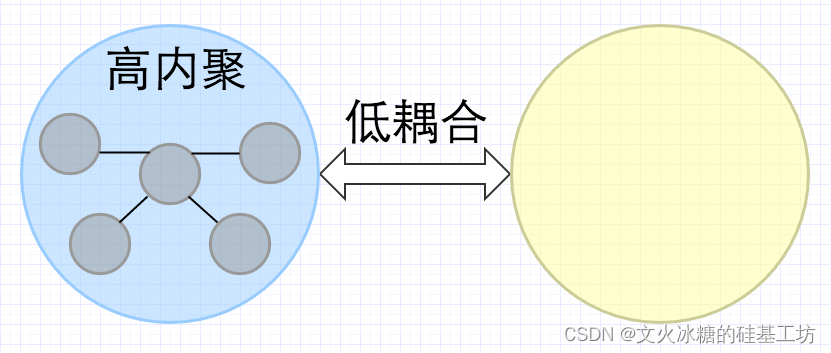
高内聚和低耦合是面向对象设计中的两个重要原则,它们分别指对象内部的功能关系和对象之间的关系。
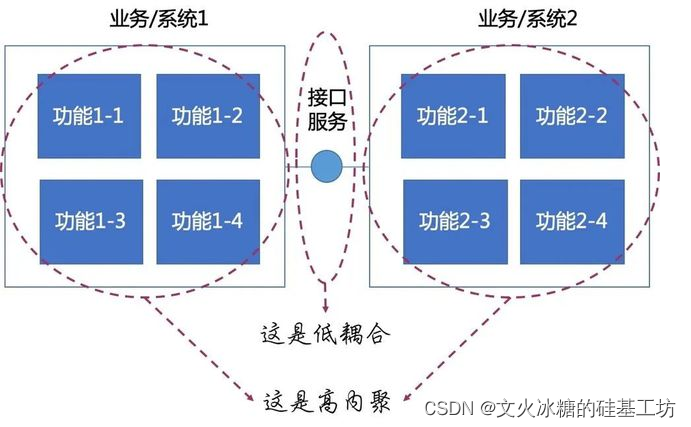
(1)高内聚:模块内部
高内聚是指一个对象或一个模块内部的各个元素(属性、方法)之间的联系越紧密,协同工作的完成度越高,这个对象或模块的内聚性就越高。
高内聚的设计方法能够带来以下好处:
- 提高了对象或模块的可读性、可维护性和可重用性,因为每个元素都具有独立的功能且与对象或模块的整体功能相关;
- 降低了系统中出现错误的概率,因为缺少的元素会影响到整个对象或模块的功能。
(2)低耦合:模块之间
低耦合是指对象或模块之间的耦合度越低,它们之间的关系越少、越简单,这个对象或模块的耦合性就越低。
低耦合的设计方法能够带来以下好处:
- 提高了系统的模块化程度,各个对象或模块之间相互独立,便于分工协作和并行开发;
- 降低了系统中出现错误的概率,因为更改一个对象或模块不会影响到其他对象或模块,减少了错误蔓延的风险。
在面向对象设计中,高内聚和低耦合是非常重要的原则,它们能够帮助设计出更加稳定、可靠、可维护和可扩展的软件系统。其中,高内聚和低耦合被认为是相辅相成的原则,一个对象或模块内部高内聚同时和其他对象或模块之间低耦合是最优的设计方法。
如下是:高内聚、低耦合 与 低内聚、高耦合的比较:

内聚(Cohesion)和耦合(Coupling)是软件设计中两个极其重要的概念,它们都是衡量软件模块质量的重要标准,且密切相关。
内聚是指一个模块内部元素(属性、方法)之间相互联系的程度,即判断一个模块内的元素是否紧密相关的能力。如果一个模块内的元素彼此关联紧密,相互依赖程度高,那么它就具有高内聚性。高内聚表示模块内的元素能够很好地协同工作,以完成共同的任务,能够提高模块的可读性、维护性和可重用性。
耦合是指两个模块之间的相互依赖程度。例如,一些模块之间需要互相调用,传递数据或共享状态。如果两个模块依赖紧密,那么它们就具有高耦合性。高耦合表示两个模块之间可能难以独立变更和测试,会影响到整个系统的可维护性和可扩展性,应该尽量避免高耦合的设计。
因此,内聚和耦合都是衡量软件模块质量的重要指标,高内聚和低耦合的设计有利于提高软件系统的质量和可维护性。在设计软件时,需要尽量保证模块内部具有高内聚,模块之间具有低耦合。这可以通过遵循设计原则(如单一职责原则、接口分离原则、依赖倒置原则等)以及使用设计模式等方法实现。
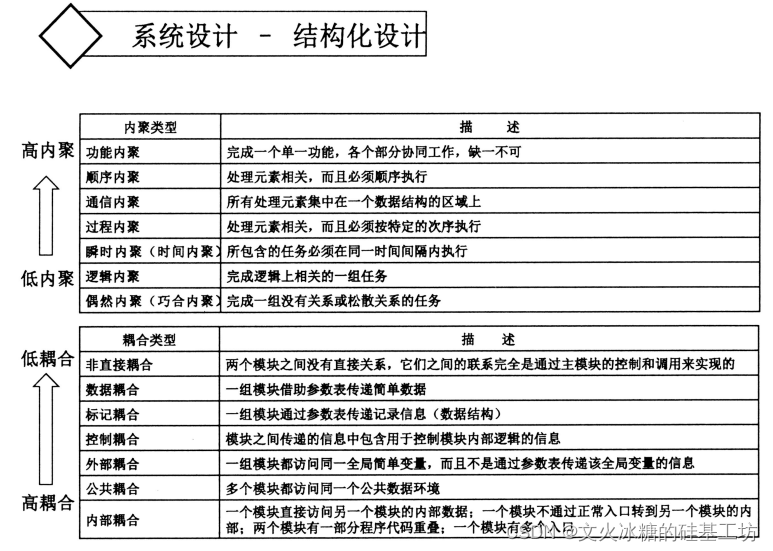
2.2 内聚类型(模块内部):高内聚
内聚(Cohesion)是软件设计中一个重要的概念,指的是模块或组件内部元素相互关联程度的度量。
内聚性高意味着模块内部的元素彼此相关联,共同完成一个明确的功能或任务,而内聚性低则表示模块内部的元素关联性较弱,功能不够集中。
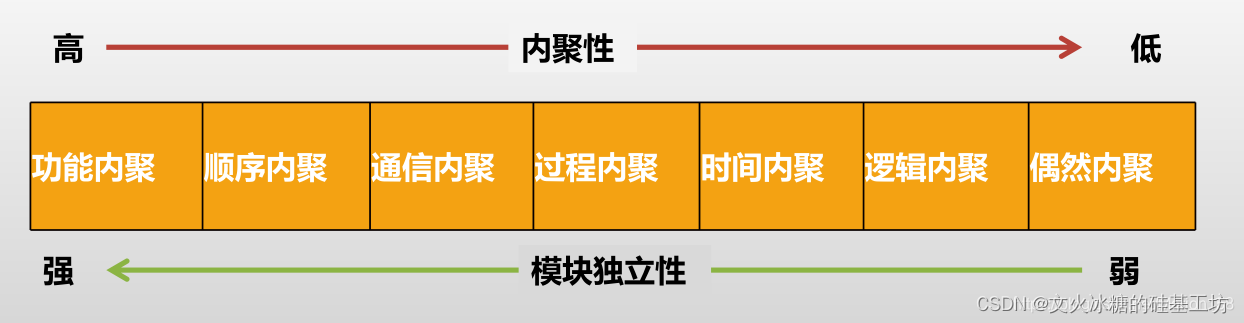
根据元素之间的关联程度不同,内聚性可分为以下几种类型:
-
功能内聚(Functional Cohesion)- 业务目标一致:模块内的元素共同完成一个明确的功能或任务,各个元素之间相关性紧密,协同工作完成特定的功能。例如,一个计算器模块包括加法、减法、乘法和除法等函数,这些函数在功能上紧密相关,代表了功能内聚。
-
顺序内聚(Sequential Cohesion)- 业务步骤相邻:模块内的元素按照一定的步骤或顺序进行操作,前一个元素的输出作为后一个元素的输入,形成一个操作序列。例如,一个文件处理模块包括打开文件、读取文件内容、处理数据和保存结果等步骤,这些步骤由于其操作顺序而形成顺序内聚。
-
通信内聚(Communicational Cohesion)- 信息传递相邻:模块内的元素之间通过共享数据进行通信,它们共同处理相关的数据。例如,一个邮件发送模块包括输入收件人、输入邮件内容、验证发送权限和发送邮件等元素,这些元素通过共享邮件内容进行通信,代表了通信内聚。
-
过程/函数内聚(Procedural Cohesion)- 函数功能相似:模块内的元素执行相似的操作,并且在同一个流程或算法中相关联。例如,一个排序模块包括选择排序、冒泡排序和快速排序等函数,这些函数在相关算法的上下文中执行相似的操作,代表了过程内聚。
-
数据内聚(Data Cohesion)-- 数据访问相邻或共享:模块内的元素对同一数据或数据结构进行操作,它们共同对该数据进行处理。例如,一个学生信息管理模块包括添加学生信息、修改学生信息和删除学生信息等操作,这些操作都是围绕学生信息数据进行的,代表了数据内聚。
-
时间内聚(Temporal Cohesion)- 代码执行时间相邻:模块内的元素在同一时间段内执行,并且需要在同一时间段进行调用。例如,一个报告生成模块包括收集数据、处理数据和生成报告等操作,这些操作需要在同一时间段内执行,代表了时间内聚。
-
逻辑内聚:逻辑内聚是高内聚的一种形式,指的是在一个模块或对象内部,各个元素(属性、方法)按照其功能逻辑上相关的程度进行组织和协作。
具有逻辑内聚的模块或对象,其内部的元素之间存在着紧密的功能联系,彼此协同工作以完成共同的任务。
-
偶然内聚:偶然内聚是指在一个模块或对象内部的各个元素(属性、方法)之间缺乏明确的功能关联或逻辑联系的情况。这种内聚类型是适用于一些临时性或无明确功能划分的模块或对象。
具有偶然内聚的模块或对象往往由于一些历史原因、设计折衷或外部要求等因素而形成,它们内部的元素可能缺乏明确的关联,功能之间可能相互独立或者无关。
偶然内聚的情况下,模块或对象内部的元素之间可能杂乱无章,难以理解和维护。
不同类型的内聚都对软件设计和开发有不同的影响,高内聚是设计的目标,因为高内聚度通常意味着模块的功能清晰,易于理解、维护和测试。设计时需要根据具体需求和设计目标选择合适的内聚类型。
2.3 耦合类型(模块之间):低耦合
耦合(Coupling)是软件设计中描述模块或组件之间相互依赖程度的概念。
耦合度高表示模块之间的相互依赖程度强,耦合度低表示模块之间的相互依赖程度弱。根据模块之间的相互依赖性不同,耦合度可分为以下几种类型:
-
无耦合(No Coupling):模块之间没有直接的相互依赖关系,彼此独立存在,并且不共享数据或信息。这是理想的耦合类型,但在实际设计中很难完全实现。因为,模块与外界没有交换就成了孤岛。
-
数据耦合(Data Coupling):模块之间通过共享数据进行通信,一个模块将数据传递给另一个模块。这种耦合方式通常是通过参数传递来实现的。模块之间只有数据和信息传递,没有业务逻辑的耦合。这是最理想的模块间低耦合的情况。
-
标记耦合(Stamp Coupling):模块之间通过标记或标识进行通信,一个模块将标记传递给另一个模块,接收方根据标记来识别并处理相应的操作。这种耦合方式通常需要模块之间有共同的标记定义。
-
控制耦合(Control Coupling):一个模块直接控制另一个模块的执行流程,通常通过调用另一个模块的方法或函数来实现。这种耦合方式通常需要模块之间有相互调用的关系。
-
外部耦合(External Coupling):模块之间通过共享外部实体(如文件、数据库、网络等)进行通信,一个模块通过读取或写入外部实体来与另一个模块进行交互。
-
公共耦合(Common Coupling):多个模块共享同一个全局数据或全局变量,它们可能同时读取或同时写入该全局数据。这种耦合方式容易导致模块之间的竞争和潜在的冲突。
-
内容耦合(Content Coupling):一个模块直接访问另一个模块的内部数据或内部实现细节,这种耦合方式是最强的,也是应尽量避免的。
降低耦合性是良好软件设计的目标之一。高内聚和低耦合度有助于提高软件的可维护性、可重用性和可测试性。在设计时,应尽量选择低耦合度的设计模式和技术,以减少模块之间的相互依赖,使各个模块能够独立变更和演化。
备注:
模块间耦合无法通过两种方式发生耦合关系:
- 数据
- 逻辑
参考:
[架构之路-252]:目标系统 - 设计方法 - 软件工程 - 软件设计 - 分析VS设计、设计层次(架构、高层、详细); 界面设计、结构化设计(高内聚低耦合)和面向对象设计(23种设计模式)-CSDN博客
[架构之路-183]-《软考-系统分析师》-13-系统设计 - 高内聚低耦合详解、图解以及技术手段-CSDN博客
![[设计模式] 常见的设计模式](https://img-blog.csdnimg.cn/img_convert/cb3cc887fc5cb970ba3ac6e122ad1121.png)