1.prinf隐藏的缓冲区
1.思考:为什么会有缓冲区的存在?
2.演示及思考?
1).演示缓存区没有存在感
那为什么我们感觉不到缓冲区的存在呢?我们要打印东西直接就打印了呢?
我们用代码演示一下:
比如打开一个main.c,输入内容如下:
#include <stdio.h>
int main()
{
printf("hello");
}
我们运行的之后直接就打印了hello,好像没有感觉到缓冲区 的存在;
原因是因为此时程序已经结束了,它会刷新缓冲区的内容;
2)演示缓冲区的存在
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
printf("hello");
sleep(3);
exit(0);
}
3.强制刷新
(1)方法一:遇到\n自动刷新
printf("hello\n");
(2)使用fflush刷新屏幕
fflush(stdout);
- _exit与exit
exit是先刷新缓冲区,然后再调用_exit(真正的退出);
_exit直接退出,不会刷新缓冲区;
比如如下的代码:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>int main()
{
printf("hello");
//fflush(stdout);
sleep(3);
_exit(0);//注意这里,不输出hello
}
5.总结
printf将内容先写入到缓冲区中,缓冲区刷新到界面(屏幕)上的条件是:
(1)缓冲区放满
(2)缓冲区未满,强制刷新缓冲区到屏幕(方法一:\n;方法二:主动刷新:fflush(stdout));
(3)程序结束时,自动刷新缓冲区:exit方法;
6.为什么会有缓冲区的存在?
屏幕是一个硬件设备,是由操作系统来管理的,因此printf打印的时候需要调用操作系统的接口才能完成,这个时候我们需要从用户态切换到内核态,这个开销是比较大的.
2.fork复制进程:
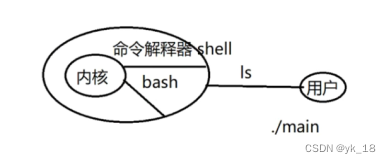
1)shell:
在计算机科学中,Shell俗称壳(用来区别于核),是指“为使用者提供操作界面”的软件(command interpreter,命令解析器)。它类似于DOS下的COMMAND.COM和后来的cmd.exe。它接收用户命令,然后调用相应的应用程序。

我们就是通过命令解释器(称为shell)(bash是命令解释器中的一种)和内核和系统进行交互的(Windows通过图形界面进行交互的);例如我们把ls交给bash,bash帮我们运行ls,然后把结果给用户;
2)fork如何复制进程?
fork是把已有的进程复制一份,当然把PCB也复制了一份,然后申请一个PID,子进程的PID=父进程的PID+1;
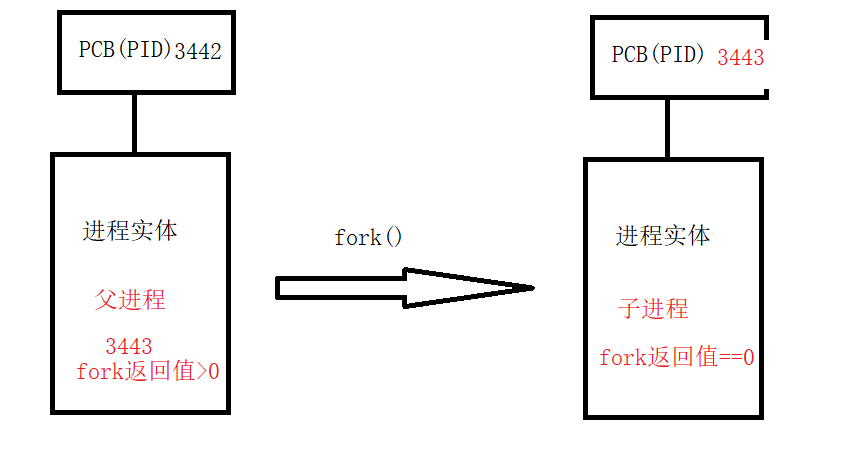
如果父子进程想要做不同的事情,那么我们通过返回值来判断;
man fork
代码如下
#include <stdio.h>
#include <unistd.h>
#include <assert.h>
#include <stdlib.h>int main()
{
char *s=NULL;
int n=0;//控制父子进程执行的次数;pid_t id=fork();
assert(id!=-1);if(id==0)//子进程
{
s="child";
n=3;
}
else//父进程
{
s="parent";
n=7;
}
//父子进程
int i=0;
for(;i<n;i++)
{
printf("s=%s\n",s);
sleep(1);
}
exit(0);
}
父子进程是两个独立的进程,各自执行各自的代码;如果父子进程要做不一样的事情,就通过if else返回值来操作;
3)fork的时机
fork产生的这个子进程不是从头开始执行的,而是从fork之后开始执行的,就是说fork下面的代码子进程才开始执行,具体的是说从返回值这里子进程开始执行,子进程不会再fork了,所以不会出现子进程再去fork产生一个子进程的问题.
也就是说:从返回值这里开始,父进程返回子进程的PID,子进程返回0;
4)getppid与getpid
getppid:得到一个进程的父进程的PID;
getpid:得到当前进程的PID;
man getpid;
man getppid
3.fork补充:
操作系统精髓与设计原理第101页;

4.如何学好多进程以及面试考点?
1)充分理解多进程的概念(每次程序多执行几次,多理解一下)
2)考点:
fork多以笔试的形式出现;
面试的考点:
例如:
1.我们在进程中看到的地址是进程的物理地址还是逻辑地址?(为什么这么问,单进程不分物理地址和逻辑地址吗);
2.进程同步设计(比如多进程抢夺资源)(难点,用程序实现)
3.fork与文件指针
(1)fork 以后,父进程打开的文件指针位置在子进程里面是否一样?(先open再fork)
(2)能否用代码简单的验证一下?
(3)先fork再打开文件父子进程是否共享偏移量?父进程打开的文件指针位置在子进程里面是否一样?能否用代码简单验证一下.(先fork再open会怎么样?)
4.fork+exec
5.僵死进程原因及处理方法;
5.内存管理相关概念
1.简单分页 逻辑页 物理页 页表的概念:
从哲学层次看操作系统157页(需要详细看)

2.虚拟内存:
虚拟内存提供的三个重要的能力:
1) 它将主存看成是一个存储在磁盘上的地址空间的高速缓存,在主存中只保存活动区域,根据需要在磁盘和主存之间来回传送数据,使得能够运行比内存大的多的进程。
2) 它为每个进程提供了一致的地址空间,从而简化了存储器管理.
3) 它保护每个进程的地址空间不被其他进程破坏 .
6.写时拷贝技术:
不采用写时拷贝,如何fork?
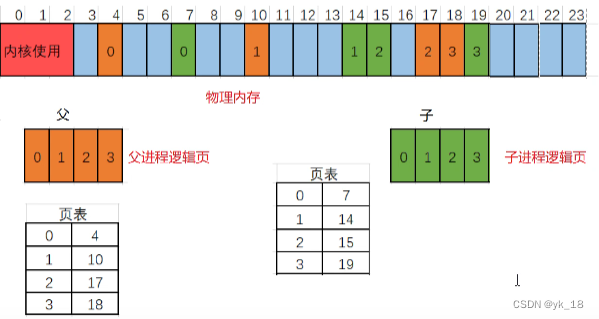
第一:复制开销比较大;
第二:占用内存空间;
所以我们对fork复制进程的过程就做了一个优化-----写时拷贝技术;
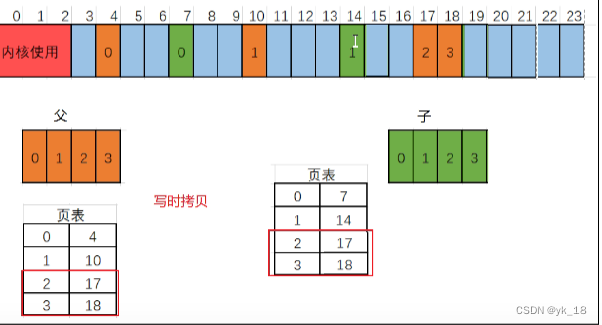
综上,就是fork的时候,子进程直接把父进程的页表复制过来,子进程发生写入(修改)的时候才分配内存复制,然后进行相应的页表修改.
写时拷贝是一种可以推迟甚至免除拷贝数据的技术.

7.我们在进程中看到的地址是进程的物理地址还是逻辑地址?
printf("s=%s,pid=%d,ppid=%d,n的地址为:%p\n",s,getpid(),getppid(),&n);//打印n的地址
8.进程的逻辑地址与物理地址
父子进程中n的值都不一样,那么我们为什么看到n的地址是相同的呢?
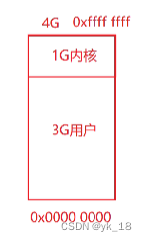
我们在进程中看到的地址就是进程的逻辑地址(进程的4G空间,从0开始,一直往上增长);
32位系统上,都有一个0-4G的地址空间:
在Linux系统上,最上面这1G由内核使用,下面3G是用户在使用;
为什么是4G呢?在32位系统上,能够寻址的范围就是2^32=4294967296字节/1000=4294976K /1000=4294M /1000=4.29 G 约等于4G .

而我们把所有的地址都编号,
1K=2^10 ,4K=2^12
物理页面能有多少个页面呢?4G/4K=2^32 / 212=2(32-12)=2^20个页面
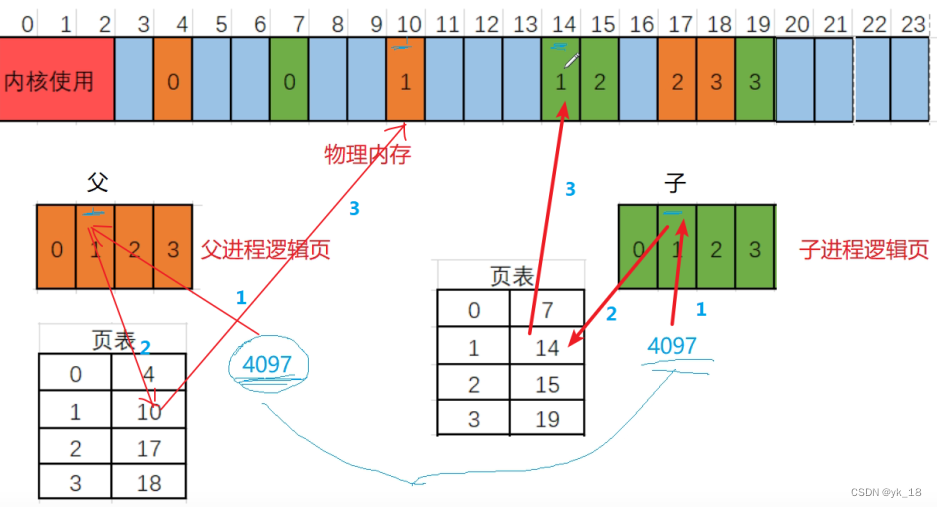
所以说,父子进程逻辑地址一样,但是物理地址是不一样的;
以前我们的程序都是只有一个进程,我们逻辑地址相同,那么我们的逻辑地址映射过去的物理地址肯定也是相同的一块空间,只有一个进程,就不用刻意去理解逻辑地址和物理地址的差异;对于同一进程,逻辑地址相同,物理地址肯定相同.
现在,我们的程序都是多进程的,逻辑地址相同,对应的物理地址就不一定相同了;也就是说A进程和B进程的逻辑地址相同,就不能说明物理地址一定相同,我们还需要看各自的页表,看看页表是否相同.(页表就是逻辑页和物理页的映射关系);
不同进程的逻辑地址是没有比较的意义的;
9.为什么在程序中不直接使用物理地址呢?
我们无法预知哪些物理地址是空闲的,同时空闲的也是动态变化的,程序在不断的申请释放空间中.