目录
- 1 设置 Seurat 对象
- 2 标准预处理工作流程
- 2.1 QC 和选择细胞进行进一步分析
- 3 数据归一化
- 4 识别高变特征(特征选择)
- 5 标准化数据
- 6 执行线性降维
- 7 确定数据集的维度
- 8 细胞聚类
- 9 运行非线性降维 (UMAP/tSNE)
- 10 寻找差异表达特征(cluster biomarkers)
- 11 将细胞类型标识分配给类群
1 设置 Seurat 对象
在本教程中,我们将分析 10X Genomics 免费提供的外周血单核细胞 (PBMC) 数据集。在 Illumina NextSeq 500 上对 2,700 个单细胞进行了测序。原始数据可以通过以下链接下载:
# 数据下载
https://cf.10xgenomics.com/samples/cell/pbmc3k/pbmc3k_filtered_gene_bc_matrices.tar.gz
我们从读取数据开始。Read10X() 函数从 10X cellranger pipeline 的输出中读取数据,返回一个唯一的分子识别 (UMI) 计数矩阵。此矩阵中的值表示在每个 cell (column) 中检测到的每个 feature (i.e. gene; row) 的分子数。
接下来我们使用 count matrix 创建一个 Seurat 对象。该对象作为一个容器,包含了单细胞数据集的 data (like the count matrix) 和 analysis (like PCA, or clustering results)。有关 Seurat 对象结构的技术讨论,请查看 seurat 的 GitHub Wiki。例如,count matrix 存储在 pbmc[["RNA"]]@counts 中。
# Seurat GitHub Wiki
https://github.com/satijalab/seurat/wiki
导入软件包和数据集:
library(dplyr)
library(Seurat)
library(patchwork)
# 导入 PBMC 数据集
pbmc.data <- Read10X(data.dir = "../data/pbmc3k/filtered_gene_bc_matrices/hg19/")
# 初始化 Seurat 对象,使用原始数据(non-normalized data)
pbmc <- CreateSeuratObject(counts = pbmc.data, project = "pbmc3k", min.cells = 3, min.features = 200)
pbmc
## An object of class Seurat
## 13714 features across 2700 samples within 1 assay
## Active assay: RNA (13714 features, 0 variable features)
计数矩阵中的数据是什么样的?
# 让我们检查前三十个细胞中的一些基因
pbmc.data[c("CD3D", "TCL1A", "MS4A1"), 1:30]
## 3 x 30 sparse Matrix of class "dgCMatrix"
##
## CD3D 4 . 10 . . 1 2 3 1 . . 2 7 1 . . 1 3 . 2 3 . . . . . 3 4 1 5
## TCL1A . . . . . . . . 1 . . . . . . . . . . . . 1 . . . . . . . .
## MS4A1 . 6 . . . . . . 1 1 1 . . . . . . . . . 36 1 2 . . 2 . . . .
矩阵中的.值代表 0(未检测到分子)。由于 scRNA-seq 矩阵中的大多数值都是 0,因此 Seurat 尽可能地使用稀疏矩阵表示。这会显着节省数据的内存和速度。
dense.size <- object.size(as.matrix(pbmc.data))
dense.size
## 709591472 bytes
sparse.size <- object.size(pbmc.data)
sparse.size
## 29905192 bytes
dense.size/sparse.size
## 23.7 bytes
2 标准预处理工作流程
以下步骤包含 Seurat 中 scRNA-seq 数据的标准预处理工作流程。这些代表了基于 QC 指标的细胞选择和过滤、数据归一化和标准化,以及高变特征的检测。
2.1 QC 和选择细胞进行进一步分析
Seurat 允许您根据任何用户定义的标准轻松探索 QC 指标和过滤细胞。社区常用的一些质量控制指标包括:
- 在每个细胞中检测到的独特基因的数量。
- 低质量细胞或空液滴通常含有很少的基因
- Cell doublets 或 multiplets 可能表现出异常高的基因计数
- 同样,细胞内检测到的分子总数(与独特基因密切相关)
- 映射到线粒体基因组的 reads 百分比
- 低质量/垂死的细胞通常表现出广泛的线粒体污染
- 我们使用
PercentageFeatureSet()函数计算线粒体 QC 指标,该函数计算源自一组特征的计数百分比 - 我们使用以
MT-开头的所有基因的集合作为一组线粒体基因
# [[ 运算符可以向对象 metadata 添加列。这是存储 QC 统计数据的好地方
pbmc[["percent.mt"]] <- PercentageFeatureSet(pbmc, pattern = "^MT-")
Seurat 中的 QC 指标存储在哪里?
- 在
CreateSeuratObject()过程中自动计算独特基因的数量和分子总数- 您可以在对象地 meta data 找到它们
# 显示前 5 个细胞的 QC 指标
head(pbmc@meta.data, 5)
## orig.ident nCount_RNA nFeature_RNA percent.mt
## AAACATACAACCAC-1 pbmc3k 2419 779 3.0177759
## AAACATTGAGCTAC-1 pbmc3k 4903 1352 3.7935958
## AAACATTGATCAGC-1 pbmc3k 3147 1129 0.8897363
## AAACCGTGCTTCCG-1 pbmc3k 2639 960 1.7430845
## AAACCGTGTATGCG-1 pbmc3k 980 521 1.2244898
在下面的示例中,我们可视化 QC 指标,并使用它们来过滤细胞。
- 我们过滤具有超过 2,500 或少于 200 的唯一特征计数的细胞
- 我们过滤线粒体计数 >5% 的细胞
# 将 QC 指标可视化为小提琴图
VlnPlot(pbmc, features = c("nFeature_RNA", "nCount_RNA", "percent.mt"), ncol = 3)

# FeatureScatter 通常用于可视化特征与特征之间的关系,但也可以用于由对象计算的任何内容,即对象 metadata 中的列、PC 分数等。
plot1 <- FeatureScatter(pbmc, feature1 = "nCount_RNA", feature2 = "percent.mt")
plot2 <- FeatureScatter(pbmc, feature1 = "nCount_RNA", feature2 = "nFeature_RNA")
plot1 + plot2
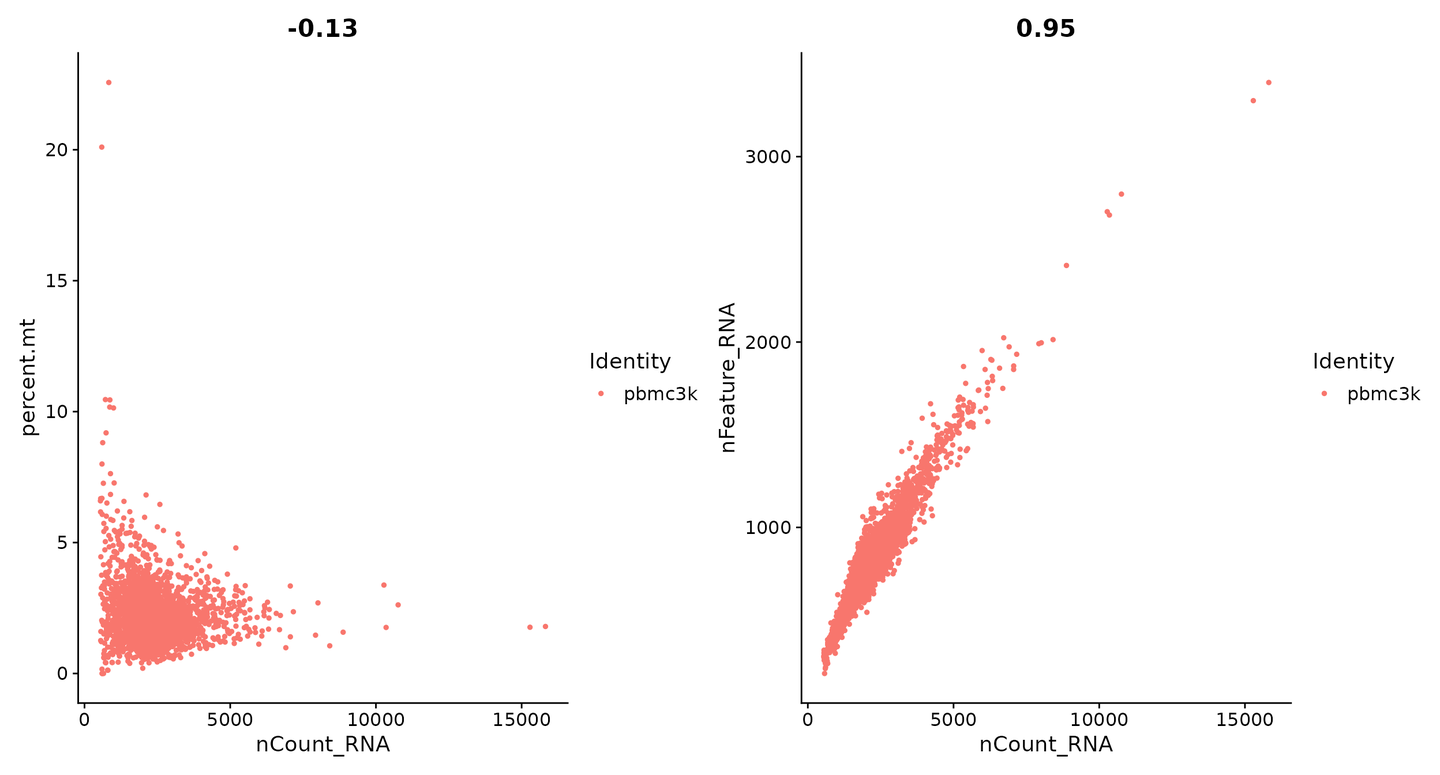
pbmc <- subset(pbmc, subset = nFeature_RNA > 200 & nFeature_RNA < 2500 & percent.mt < 5)
3 数据归一化
从数据集中删除不需要的细胞后,下一步是归一化数据。默认情况下,我们采用全局尺度归一化方法“LogNormalize”,通过总表达量对每个细胞的特征表达测量值进行归一化,将其乘以 scale factor (10,000 by default),并对结果进行 log-transforms。归一化值存储在 pbmc[["RNA"]]@data 中。
pbmc <- NormalizeData(pbmc, normalization.method = "LogNormalize", scale.factor = 10000)
为清楚起见,在前面的代码行(以及未来的命令中),我们为函数调用中的某些参数提供了默认值。但是,这不是必需的,可以通过以下方式实现相同的行为:
pbmc <- NormalizeData(pbmc)
4 识别高变特征(特征选择)
接下来,我们计算在数据集中表现出高细胞间变异的特征子集(即,它们在某些细胞中高表达,而在其他细胞中低表达)。我们和其他人发现,在下游分析中关注这些基因有助于突出单细胞数据集中的生物信号。
Seurat V3 文章中详细描述了 Seurat 的过程,并通过直接对单细胞数据中固有的均值-方差关系进行建模来改进以前的版本,并在 FindVariableFeatures() 函数中实现。默认情况下,我们为每个数据集返回 2,000 个特征。这些将用于下游分析,如 PCA。
pbmc <- FindVariableFeatures(pbmc, selection.method = "vst", nfeatures = 2000)
# 确定前 10 个变异最大的基因
top10 <- head(VariableFeatures(pbmc), 10)
# 绘制带标签和不带标签的变异特征
plot1 <- VariableFeaturePlot(pbmc)
plot2 <- LabelPoints(plot = plot1, points = top10, repel = TRUE)
plot1 + plot2

5 标准化数据
接下来,我们应用线性变换("scaling"),这是在 PCA 等降维技术之前的标准预处理步骤。ScaleData() 函数:
- 改变每个基因的表达,使细胞间的平均表达为 0
- 缩放每个基因的表达,使细胞间的方差为 1
- 此步骤在下游分析中给予同等权重,因此高表达基因不会占主导地位
- 结果存储在
pbmc[["RNA"]]@scale.data中
all.genes <- rownames(pbmc)
pbmc <- ScaleData(pbmc, features = all.genes)
这一步耗时太长了!我可以让它更快吗?
标准化是 Seurat 工作流程中的重要步骤,但仅限于将用作 PCA 输入的基因。因此,ScaleData() 中默认仅对先前识别的可变特征(2,000 by default)执行标准化。为此,请省略上一个函数调用中的 features 参数,即:
pbmc <- ScaleData(pbmc)
您的 PCA 和聚类结果将不受影响。然而,Seurat 热图(如下所示,使用 DoHeatmap() 生成)需要对热图中的基因进行标准化,以确保高表达的基因不会主导热图。为了确保我们稍后不会将任何基因遗漏在热图中,我们将标准化本教程中的所有基因。
如何删除不需要的变异来源,如 Seurat v2 中那样?
在 Seurat v2 中,我们还使用 ScaleData() 函数从单细胞数据集中删除不需要的变异源。例如,我们可以“regress out”与细胞周期阶段或线粒体污染相关的异质性。Seurat v3 中的 ScaleData() 仍然支持这些功能,即:
pbmc <- ScaleData(pbmc, vars.to.regress = "percent.mt")
但是,特别是对于想要使用此功能的高级用户,我们强烈建议使用新的归一化工作流程 SCTransform()。我们的论文中描述了该方法,此处使用 Seurat v3 提供了一个单独的小插图。与 ScaleData() 一样,函数 SCTransform() 也包含 vars.to.regress 参数。
6 执行线性降维
接下来我们对标准化后的数据执行 PCA。默认情况下,仅将先前确定的变量特征用作输入,但如果您希望选择不同的子集,则可以使用 features 参数进行定义。
pbmc <- RunPCA(pbmc, features = VariableFeatures(object = pbmc))
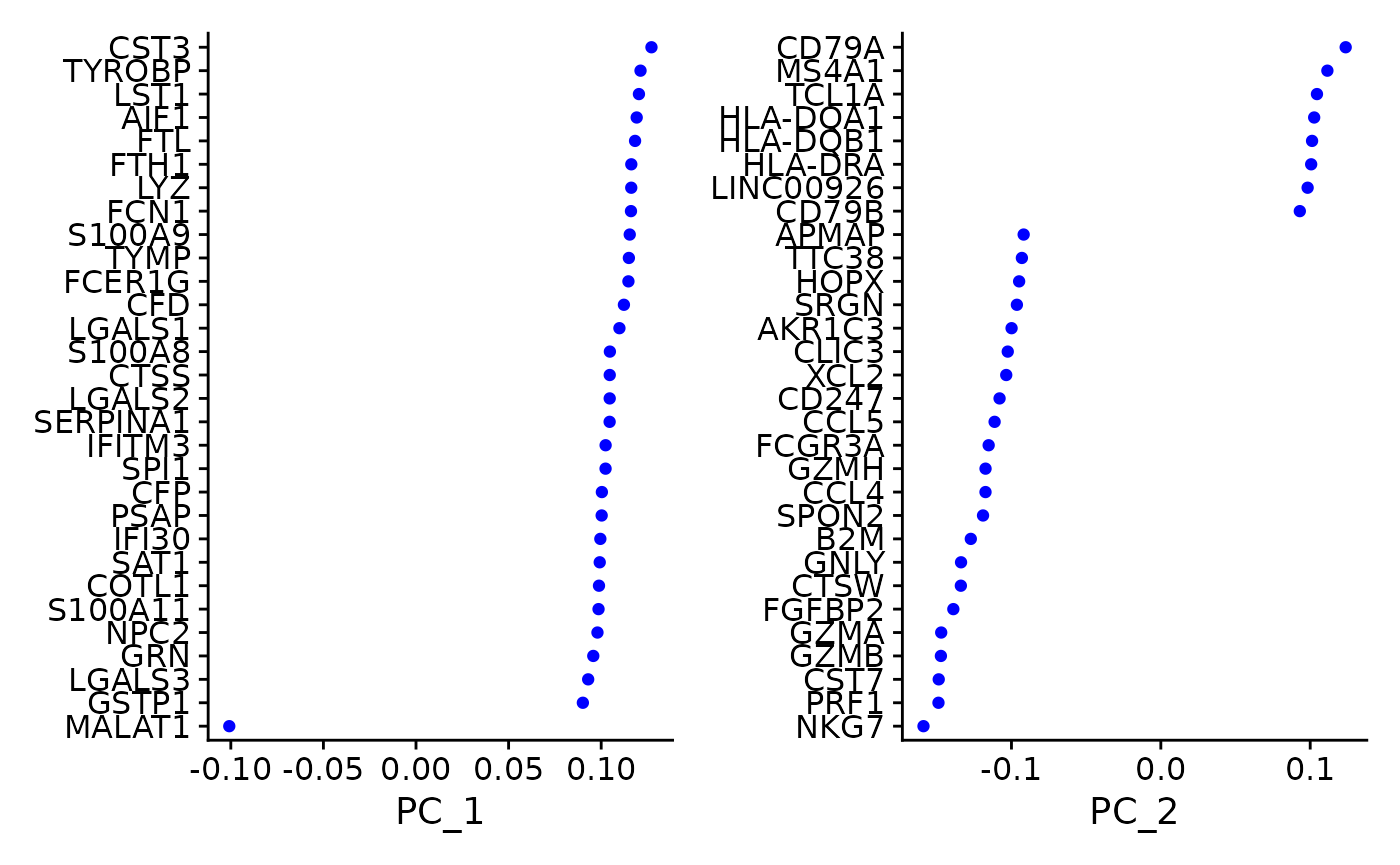
Seurat 提供了几种有用的方法来可视化定义 PCA 的细胞和特征,包括 VizDimReduction()、DimPlot() 和 DimHeatmap()
# 通过几种不同的方式检查和可视化 PCA 结果
print(pbmc[["pca"]], dims = 1:5, nfeatures = 5)
## PC_ 1
## Positive: CST3, TYROBP, LST1, AIF1, FTL
## Negative: MALAT1, LTB, IL32, IL7R, CD2
## PC_ 2
## Positive: CD79A, MS4A1, TCL1A, HLA-DQA1, HLA-DQB1
## Negative: NKG7, PRF1, CST7, GZMB, GZMA
## PC_ 3
## Positive: HLA-DQA1, CD79A, CD79B, HLA-DQB1, HLA-DPB1
## Negative: PPBP, PF4, SDPR, SPARC, GNG11
## PC_ 4
## Positive: HLA-DQA1, CD79B, CD79A, MS4A1, HLA-DQB1
## Negative: VIM, IL7R, S100A6, IL32, S100A8
## PC_ 5
## Positive: GZMB, NKG7, S100A8, FGFBP2, GNLY
## Negative: LTB, IL7R, CKB, VIM, MS4A7
VizDimLoadings(pbmc, dims = 1:2, reduction = "pca")
DimPlot(pbmc, reduction = "pca")
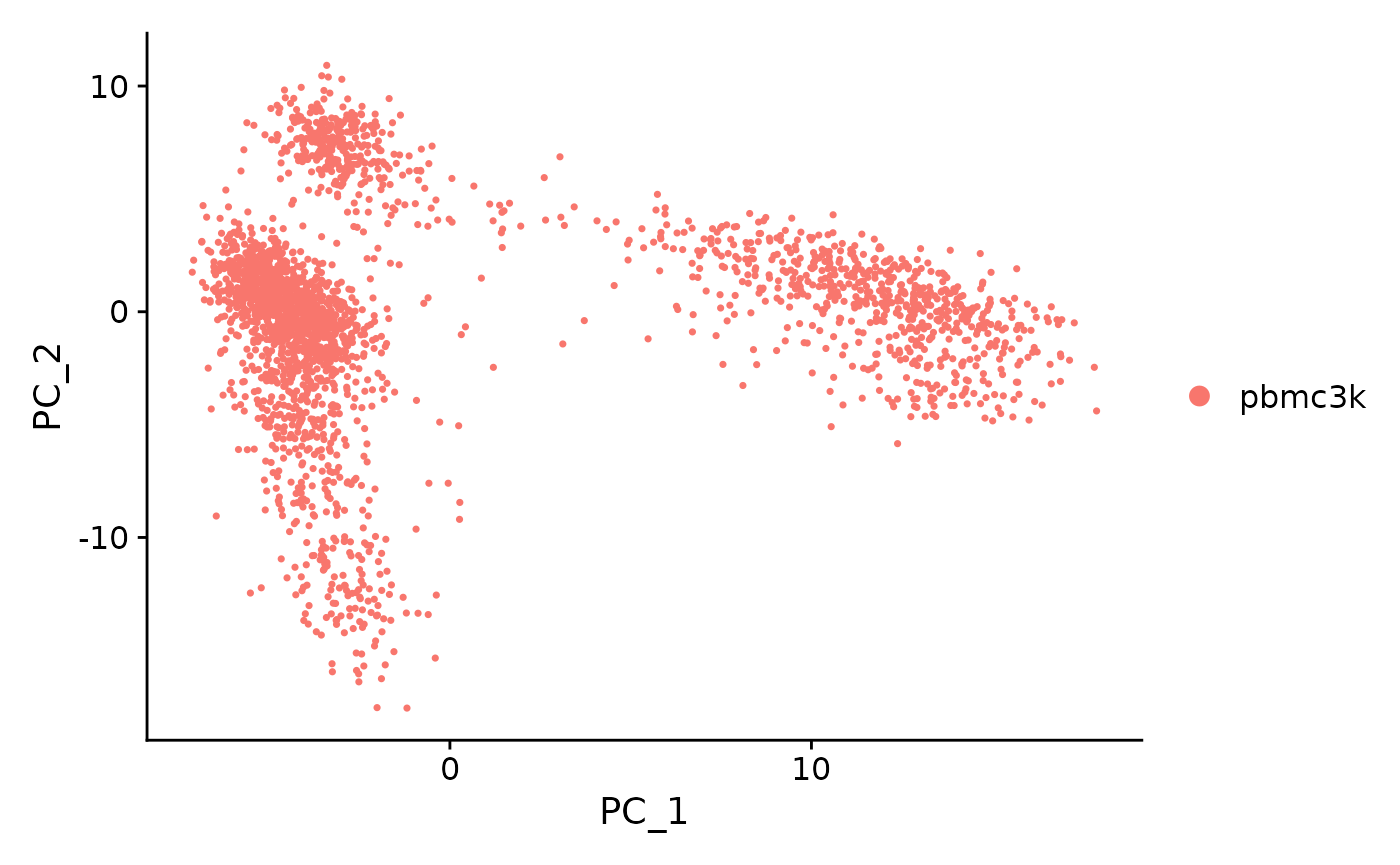
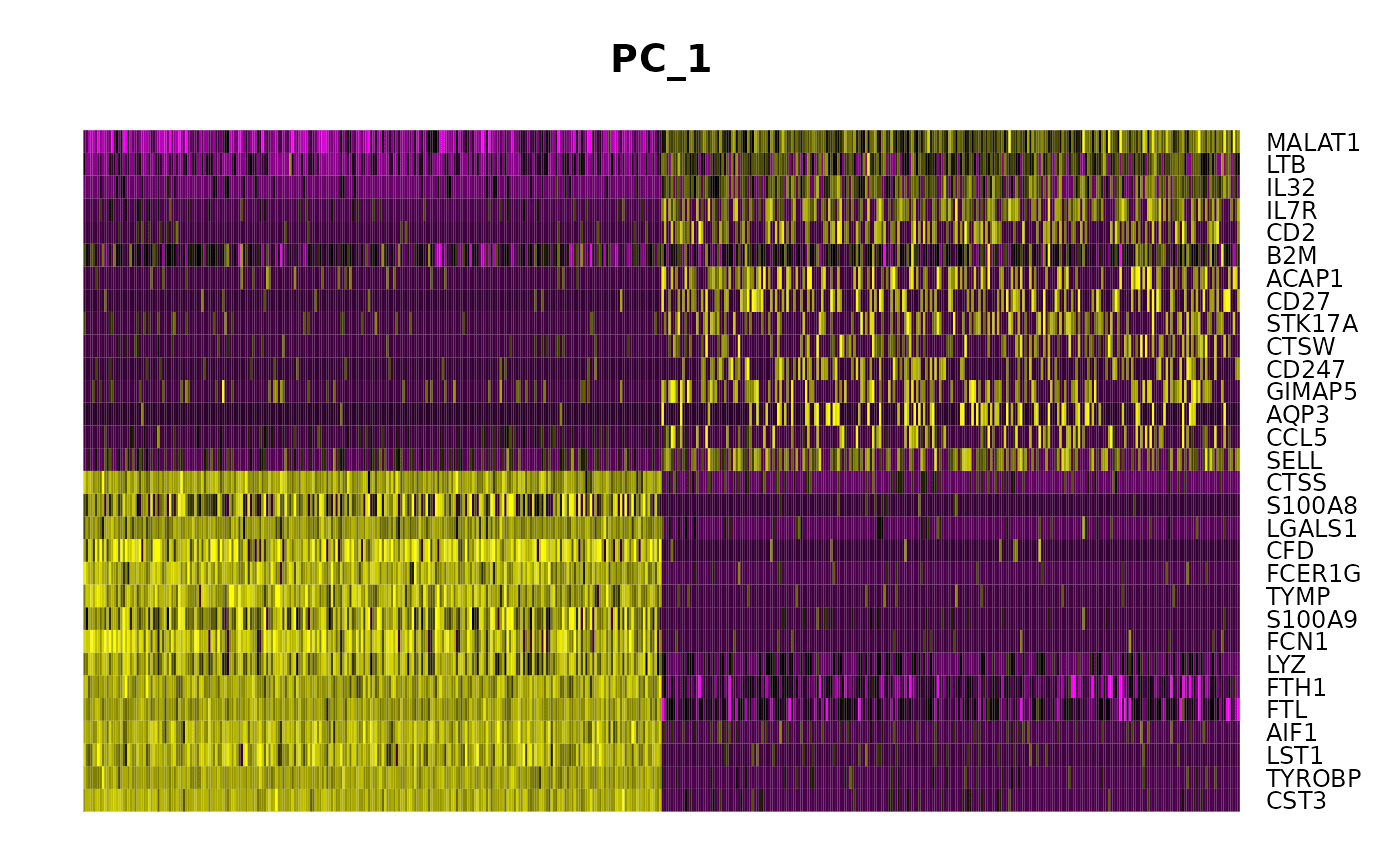
特别是 DimHeatmap() 允许轻松探索数据集中异质性的主要来源,并且在尝试决定要包括哪些 PC 以进行进一步的下游分析时非常有用。细胞和特征都根据其 PCA 分数排序。将 cells 设置为一个数字会绘制光谱两端的“极端”细胞,这会显着加快大型数据集的绘制速度。虽然显然是监督分析,但我们发现这是探索相关特征集的宝贵工具。
DimHeatmap(pbmc, dims = 1, cells = 500, balanced = TRUE)
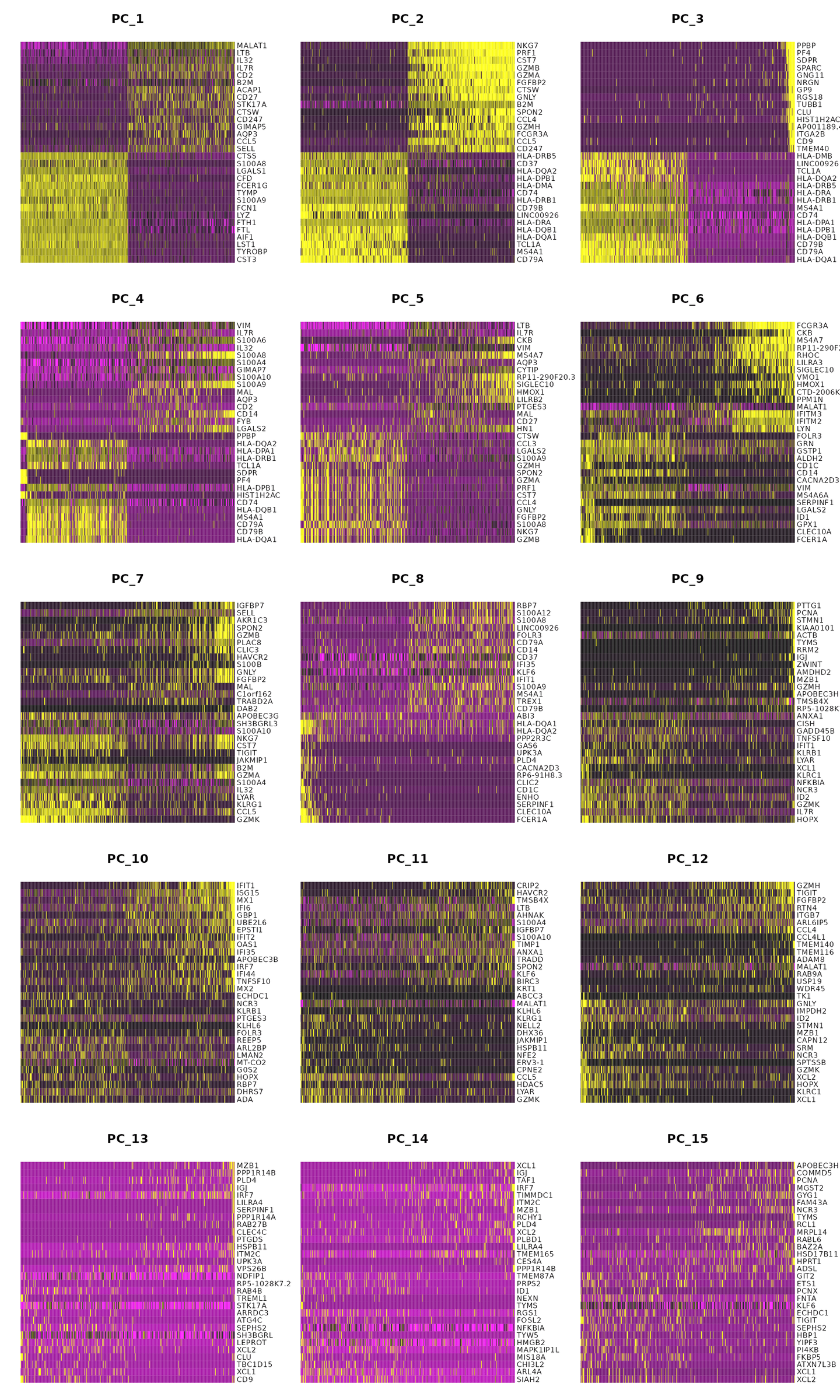
DimHeatmap(pbmc, dims = 1:15, cells = 500, balanced = TRUE)
7 确定数据集的维度
为了克服 scRNA-seq 数据的任何单一特征中广泛的技术噪音,Seurat 根据其 PCA 分数对细胞进行聚类,每个 PC 本质上代表一个“metafeature”,它结合了相关特征集的信息。因此,顶级主成分代表了数据集的强大压缩。但是,我们应该选择包含多少个成分?10?20?100?
在 Macosko et al 文章中,我们实施了受 JackStraw 程序启发的重采样测试。我们随机排列数据的一个子集(默认为 1%)并重新运行 PCA,构建特征分数的“null distribution”,然后重复此过程。我们将“重要”PC 识别为具有低 p-value 特征的大量丰富的 PC。
# 注意:对于大数据集,此过程可能需要很长时间,为了方便起见,请注释掉。更多的近似技术,例如在 ElbowPlot() 中实现的技术,可用于减少计算时间
pbmc <- JackStraw(pbmc, num.replicate = 100)
pbmc <- ScoreJackStraw(pbmc, dims = 1:20)
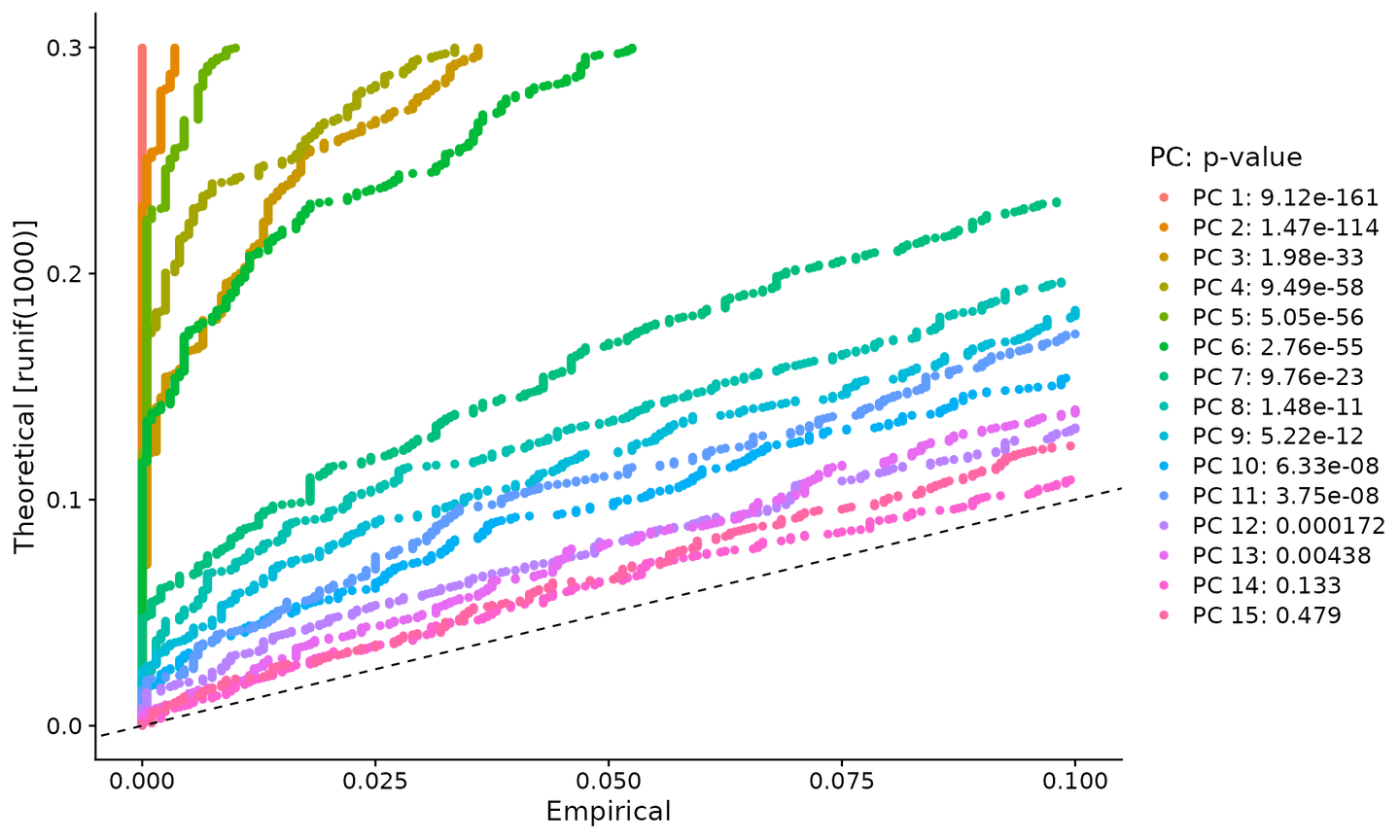
JackStrawPlot() 函数提供了一个可视化工具,用于将每个 PC 的 p-value 分布与均匀分布(虚线)进行比较。“显着”PCs 将显示具有低 p-value(虚线上方的实线)的特征的强烈富集。在这种情况下,似乎在前 10-12 个 PCs 之后显着性急剧下降。
JackStrawPlot(pbmc, dims = 1:15)
另一种启发式方法生成“Elbow plot”:根据每个主成分解释的方差百分比(ElbowPlot() function)对主成分进行排名。在此示例中,我们可以在 PC9-10 周围观察到一个“elbow”,这表明大部分真实信号是在前 10 个 PC 中捕获的。
ElbowPlot(pbmc)
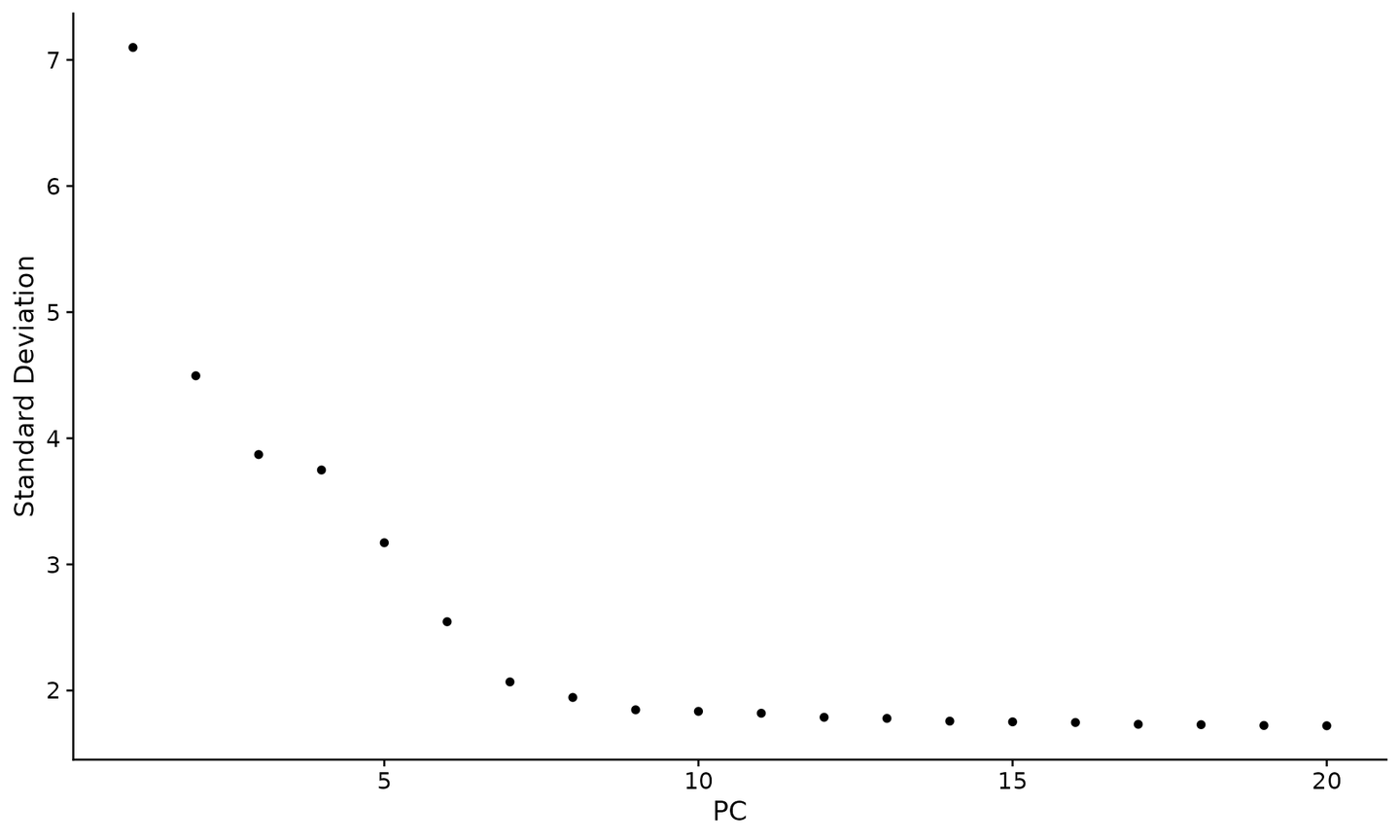
识别数据集的真实维度——对用户来说可能具有挑战性/不确定性。因此,我们建议考虑这三种方法。第一个是更有监督的,探索 PCs 以确定相关的异质性来源,并且可以与 GSEA 结合使用。第二种实现基于随机空模型的统计检验,但对于大型数据集来说很耗时,并且可能无法返回明确的 PC cutoff。第三种是常用的启发式算法,可以立即计算。在此示例中,所有三种方法都产生了相似的结果,但我们可能有理由选择 PC 7-12 之间的任何值作为 cutoff。
我们在这里选择了 10,但鼓励用户考虑以下几点:
- Dendritic cell 和 NK aficionados 可能认识到与 PC 12 和 13 密切相关的基因定义了罕见的免疫亚群 (i.e. MZB1 is a marker for plasmacytoid DCs)。然而,这些群体非常罕见,在没有先验知识的情况下,很难将它们与这种规模的数据集的背景噪声区分开来。
- 我们鼓励用户使用不同数量的 PCs(10,15,or even 50!)重复下游分析。正如您将观察到的,结果通常不会有显着差异。
- 我们建议用户在选择更大的值。例如,仅使用 5 个 PCs 执行下游分析会对结果产生重大不利影响。
8 细胞聚类
Seurat v3 应用基于图的聚类方法,建立在 (Macosko et al) 的初始策略之上。重要的是,驱动聚类分析的距离度量(基于先前识别的 PC)保持不变。然而,我们将细胞距离矩阵划分为 clusters 的方法有了显着改进。我们的方法深受近期手稿的启发,这些手稿将基于图的聚类方法应用于 scRNA-seq 数据 [SNN-Cliq, Xu and Su, Bioinformatics, 2015] 和 CyTOF 数据 [PhenoGraph, Levine et al., Cell, 2015]。简而言之,这些方法将细胞嵌入到图结构中——例如 K-nearest neighbor(KNN) graph,在具有相似特征表达模式的细胞之间绘制边,然后尝试将该图划分为高度互连的“quasi-cliques”或“communities”。
与 PhenoGraph 一样,我们首先基于 PCA 空间中的欧几里得距离构建 KNN 图,并根据其局部邻域中的共享重叠(Jaccard similarity)细化任意两个单元之间的边权重。此步骤使用 FindNeighbors() 函数执行,并将先前定义的数据集维度(前 10 个 PCs)作为输入。
为了对细胞进行聚类,我们接下来应用模块化优化技术,例如 Louvain 算法(默认)或 SLM [SLM, Blondel et al., Journal of Statistical Mechanics],以迭代方式将细胞组合在一起,以优化标准模块化函数。FindClusters() 函数实现了这个过程,并包含一个分辨率参数,该参数设置下游聚类的“granularity”,增加的值会导致更多的聚类。我们发现将此参数设置在 0.4-1.2 之间通常会为大约 3K 细胞的单细胞数据集返回良好的结果。对于较大的数据集,最佳分辨率通常会增加。可以使用 Idents() 函数找到 clusters。
pbmc <- FindNeighbors(pbmc, dims = 1:10)
pbmc <- FindClusters(pbmc, resolution = 0.5)
## Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
##
## Number of nodes: 2638
## Number of edges: 95927
##
## Running Louvain algorithm...
## Maximum modularity in 10 random starts: 0.8728
## Number of communities: 9
## Elapsed time: 0 seconds
# 查看前 5 个细胞的 cluster IDs
head(Idents(pbmc), 5)
## AAACATACAACCAC-1 AAACATTGAGCTAC-1 AAACATTGATCAGC-1 AAACCGTGCTTCCG-1
## 2 3 2 1
## AAACCGTGTATGCG-1
## 6
## Levels: 0 1 2 3 4 5 6 7 8
9 运行非线性降维 (UMAP/tSNE)
Seurat 提供了多种非线性降维技术,例如 tSNE 和 UMAP,以可视化和探索这些数据集。这些算法的目标是学习数据的底层流形,以便将相似的细胞放在低维空间中。上面确定的基于图的 cluster 中的细胞应该在这些降维图上共同定位。作为 UMAP 和 tSNE 的输入,我们建议使用相同的 PCs 作为聚类分析的输入。
# 如果你还没有安装 UMAP,你可以通过 reticulate::py_install(packages = 'umap-learn')
pbmc <- RunUMAP(pbmc, dims = 1:10)
# 请注意,您可以设置 `label = TRUE` 或使用 LabelClusters 函数来帮助标记单个类群
DimPlot(pbmc, reduction = "umap")
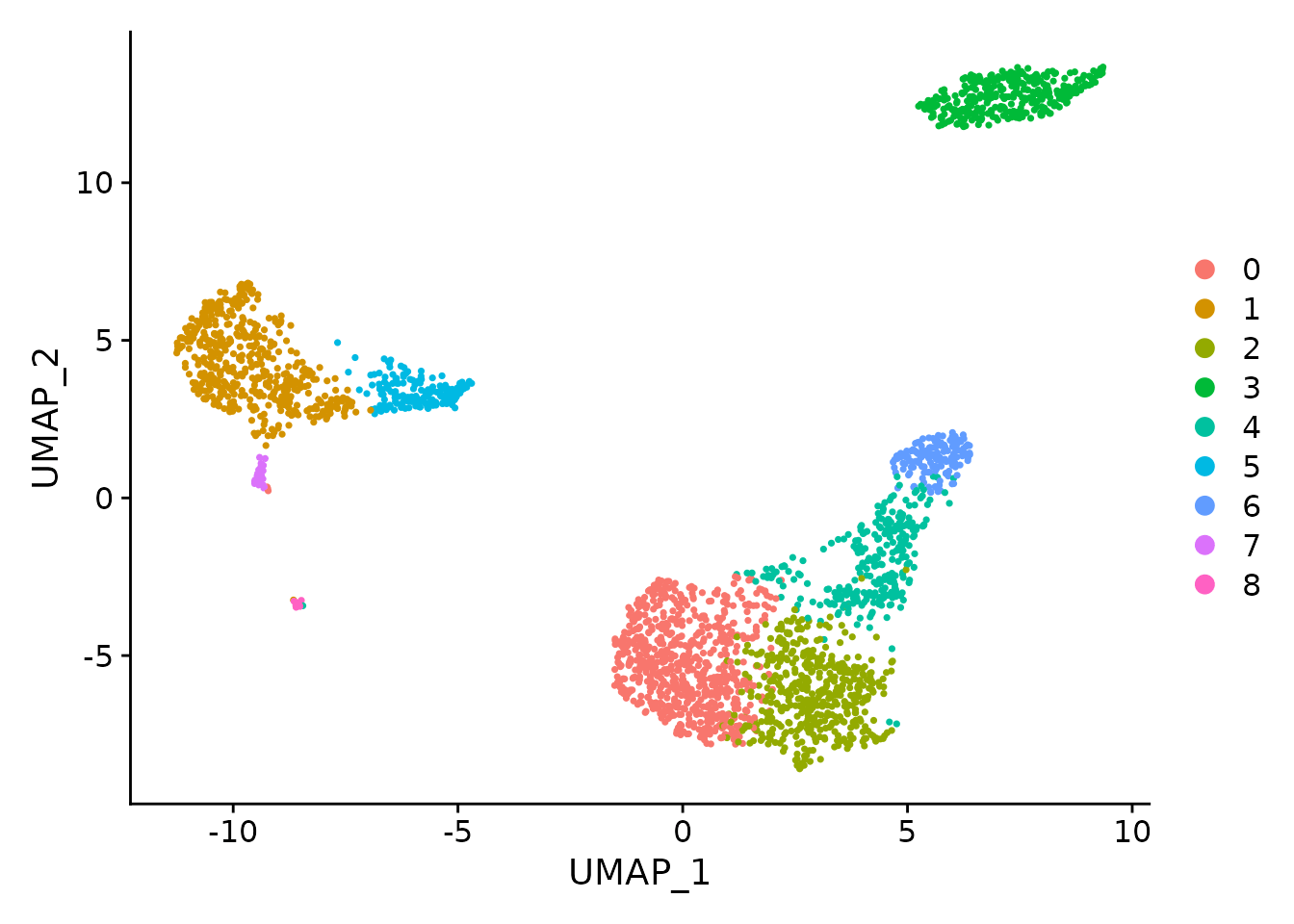
您可以在此时保存该对象,以便可以轻松地将其加载回去,而无需重新运行上面执行的计算密集型步骤,或者可以轻松地与协作者共享。
saveRDS(pbmc, file = "pbmc_tutorial.rds")
10 寻找差异表达特征(cluster biomarkers)
Seurat 可以帮助您找到通过差异表达定义 clusters 的 markers。默认情况下,与所有其他细胞相比,它识别单个 cluster(specified in ident.1)的阳性和阴性标记。FindAllMarkers() 会针对所有 clusters 自动执行此过程,但您也可以测试 clusters 组之间的对比,或针对所有细胞进行测试。
min.pct 参数要求在两组细胞中以最小百分比检测到一个特征,而 thresh.test 参数要求一个特征在两组之间以一定数量差异表达(平均)。您可以将这两个设置为 0,但时间会急剧增加 - 因为这将测试大量不太可能具有高度差异性的功能。作为加速这些计算的另一种选择,可以设置 max.cells.per.ident。这将对每个身份类别进行下采样,使其中的细胞数量不超过设置的数量。虽然通常会出现功率损失,但速度可能会显着提高,并且差异表达最高的特征可能仍会上升到顶部。
# 寻找 cluster 2 的所有 markers
cluster2.markers <- FindMarkers(pbmc, ident.1 = 2, min.pct = 0.25)
head(cluster2.markers, n = 5)
## p_val avg_log2FC pct.1 pct.2 p_val_adj
## IL32 2.892340e-90 1.2013522 0.947 0.465 3.966555e-86
## LTB 1.060121e-86 1.2695776 0.981 0.643 1.453850e-82
## CD3D 8.794641e-71 0.9389621 0.922 0.432 1.206097e-66
## IL7R 3.516098e-68 1.1873213 0.750 0.326 4.821977e-64
## LDHB 1.642480e-67 0.8969774 0.954 0.614 2.252497e-63
# 寻找区分 cluster 5 与 cluster 0 和 3 的所有 markers
cluster5.markers <- FindMarkers(pbmc, ident.1 = 5, ident.2 = c(0, 3), min.pct = 0.25)
head(cluster5.markers, n = 5)
## p_val avg_log2FC pct.1 pct.2 p_val_adj
## FCGR3A 8.246578e-205 4.261495 0.975 0.040 1.130936e-200
## IFITM3 1.677613e-195 3.879339 0.975 0.049 2.300678e-191
## CFD 2.401156e-193 3.405492 0.938 0.038 3.292945e-189
## CD68 2.900384e-191 3.020484 0.926 0.035 3.977587e-187
## RP11-290F20.3 2.513244e-186 2.720057 0.840 0.017 3.446663e-182
# 与所有剩余细胞相比,找到每个 cluster 的 markers,仅报告阳性的那些
pbmc.markers <- FindAllMarkers(pbmc, only.pos = TRUE, min.pct = 0.25, logfc.threshold = 0.25)
pbmc.markers %>%
group_by(cluster) %>%
slice_max(n = 2, order_by = avg_log2FC)
## # A tibble: 18 × 7
## # Groups: cluster [9]
## p_val avg_log2FC pct.1 pct.2 p_val_adj cluster gene
## <dbl> <dbl> <dbl> <dbl> <dbl> <fct> <chr>
## 1 9.57e- 88 1.36 0.447 0.108 1.31e- 83 0 CCR7
## 2 3.75e-112 1.09 0.912 0.592 5.14e-108 0 LDHB
## 3 0 5.57 0.996 0.215 0 1 S100A9
## 4 0 5.48 0.975 0.121 0 1 S100A8
## 5 1.06e- 86 1.27 0.981 0.643 1.45e- 82 2 LTB
## 6 2.97e- 58 1.23 0.42 0.111 4.07e- 54 2 AQP3
## 7 0 4.31 0.936 0.041 0 3 CD79A
## 8 9.48e-271 3.59 0.622 0.022 1.30e-266 3 TCL1A
## 9 5.61e-202 3.10 0.983 0.234 7.70e-198 4 CCL5
## 10 7.25e-165 3.00 0.577 0.055 9.95e-161 4 GZMK
## 11 3.51e-184 3.31 0.975 0.134 4.82e-180 5 FCGR3A
## 12 2.03e-125 3.09 1 0.315 2.78e-121 5 LST1
## 13 3.13e-191 5.32 0.961 0.131 4.30e-187 6 GNLY
## 14 7.95e-269 4.83 0.961 0.068 1.09e-264 6 GZMB
## 15 1.48e-220 3.87 0.812 0.011 2.03e-216 7 FCER1A
## 16 1.67e- 21 2.87 1 0.513 2.28e- 17 7 HLA-DPB1
## 17 1.92e-102 8.59 1 0.024 2.63e- 98 8 PPBP
## 18 9.25e-186 7.29 1 0.011 1.27e-181 8 PF4
Seurat 有几个差异表达测试,可以使用 test.use 参数设置(有关详细信息,请参阅我们的 DE vignette)。例如,ROC 测试返回任何单个标记的“分类能力”(范围从 0-random 到 1-perfect)。
cluster0.markers <- FindMarkers(pbmc, ident.1 = 0, logfc.threshold = 0.25, test.use = "roc", only.pos = TRUE)
我们包括几个用于可视化标记表达的工具。VlnPlot()(显示跨 clusters 的表达概率分布)和 FeaturePlot()(在 tSNE 或 PCA 图上可视化特征表达)是我们最常用的可视化。我们还建议探索 RidgePlot()、CellScatter() 和 DotPlot() 作为查看数据集的其他方法。
VlnPlot(pbmc, features = c("MS4A1", "CD79A"))

# you can plot raw counts as well
VlnPlot(pbmc, features = c("NKG7", "PF4"), slot = "counts", log = TRUE)

FeaturePlot(pbmc, features = c("MS4A1", "GNLY", "CD3E", "CD14", "FCER1A", "FCGR3A", "LYZ", "PPBP", "CD8A"))

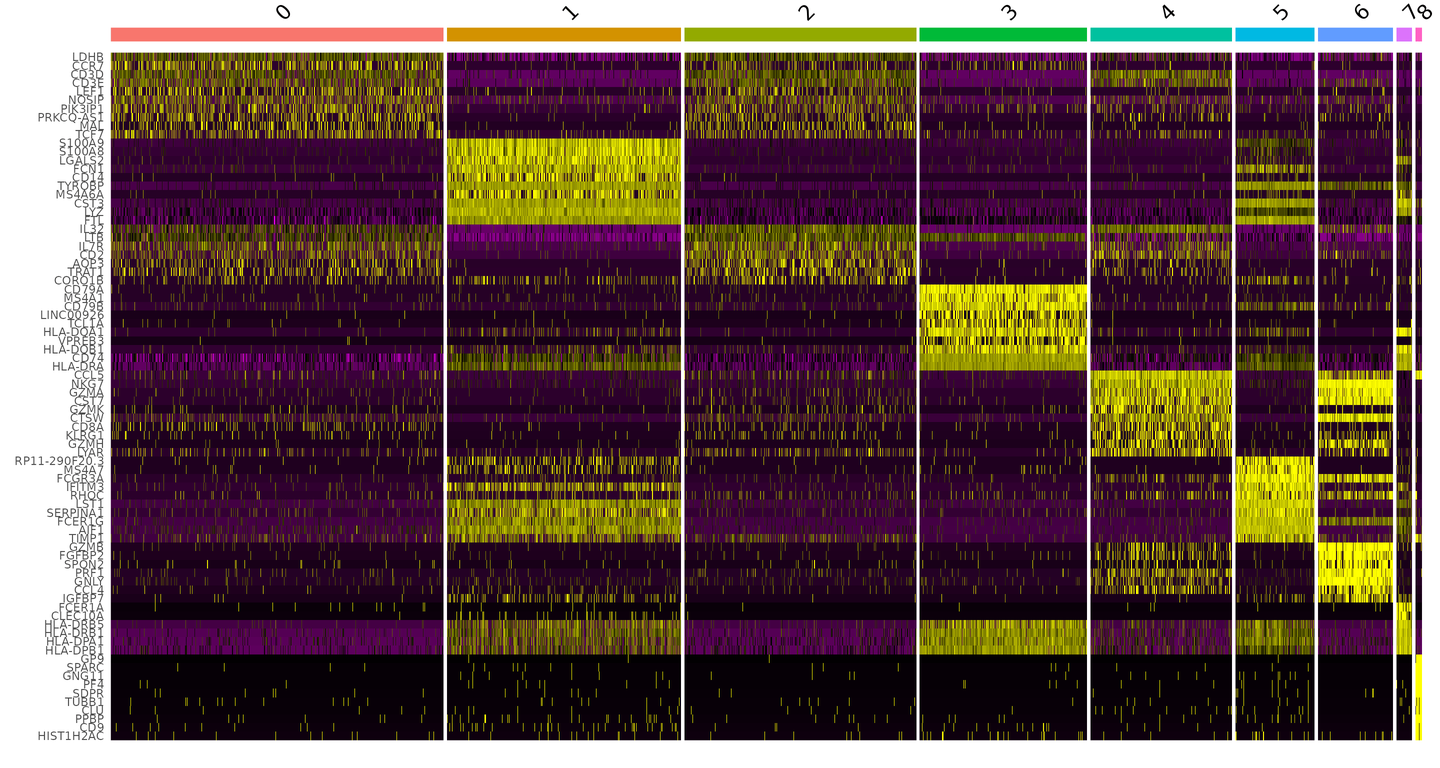
DoHeatmap() 为给定的细胞和特征生成一个表达式热图。在这种情况下,我们为每个 cluster 绘制前 20 个 markers(或所有 markers,如果少于 20 个)。
pbmc.markers %>%
group_by(cluster) %>%
top_n(n = 10, wt = avg_log2FC) -> top10
DoHeatmap(pbmc, features = top10$gene) + NoLegend()
11 将细胞类型标识分配给类群
幸运的是,对于这个数据集,我们可以使用规范标记轻松地将无偏聚类与已知细胞类型相匹配:
| Cluster ID | Markers | Cell Type |
|---|---|---|
| 0 | IL7R, CCR7 | Naive CD4+ T |
| 1 | CD14, LYZ | CD14+ Mono |
| 2 | IL7R, S100A4 | Memory CD4+ |
| 3 | MS4A1 | B |
| 4 | CD8A | CD8+ T |
| 5 | FCGR3A, MS4A7 | FCGR3A+ Mono |
| 6 | GNLY, NKG7 | NK |
| 7 | FCER1A, CST3 | DC |
| 8 | PPBP | Platelet |
new.cluster.ids <- c("Naive CD4 T", "CD14+ Mono", "Memory CD4 T", "B", "CD8 T", "FCGR3A+ Mono", "NK", "DC", "Platelet")
names(new.cluster.ids) <- levels(pbmc)
pbmc <- RenameIdents(pbmc, new.cluster.ids)
DimPlot(pbmc, reduction = "umap", label = TRUE, pt.size = 0.5) + NoLegend()

saveRDS(pbmc, file = "pbmc3k_final.rds")
结束