一、介绍
在当今世界,机器学习和人工智能几乎被广泛应用于每个领域,以提高绩效和结果。但如果没有数据,它们还有用吗?答案是否定的。机器学习算法严重依赖我们提供给它们的数据。我们提供给算法的数据质量在很大程度上决定了机器学习模型的结果和性能。问题是可用的数据很少是完美的。因此,我们必须修改数据集以充分利用它。

学习目标
在本文中,我们将使用机器学习讨论一个这样有趣的数据集,并了解如何修改它以使其接近完美。我们将了解
1. python 中一些有趣的库用于修改数据集、创建模型并对其进行评估。
2. 如何进行探索性数据分析和特征工程?
3.如何处理异常值?
4. 什么是采样?它是如何执行的?
本文作为数据科学博客马拉松的一部分发表。
目录
- 该项目是关于什么的?
- 问题陈述
- 在进一步之前,请了解一些先决条件!
- 了解更多关于数据集的信息
- EDA 和目标数据分析
- 查找数据集中的异常值
- 通过特征工程转换特征
- 是冷的!热图在哪里?
- 造型
- 数据足够好吗?
- 消除数据集中的不平衡
- 理解数据采样
12.1 欠采样
12.2 过采样 - 结论
二、该项目是关于什么的?
对于任何希望保护家人和资产免受财务风险和损失的人来说,保险单是一个很好的方式。这些计划可帮助您支付任何医疗护理和紧急情况的费用。就车辆保险而言,它有助于支付任何车辆损坏或由车辆造成的损坏。法律规定每个机动车车主都必须拥有汽车保险。为了保证对这些损失进行赔偿,保险公司会要求客户支付少量保费。虽然风险很高,但发生这些损害的概率非常低,比如百分之二。这样,每个人都分担了其他人的风险。
提供这些医疗和车辆保险的保险公司高度依赖机器学习来改善客户服务、运营效率和欺诈检测。该公司利用用户的经验来预测是否会出现由该客户或该客户造成的事故。在签发任何保单之前,公司可能会收集年龄、性别、健康状况、病史等详细信息。
三、问题陈述
在本文中,我们将使用车辆保险数据来预测客户是否有兴趣购买车辆的保险单。理想情况下,我们在机器学习中使用的数据集应该具有平衡的目标变量比例,以便模型给出无偏差的结果。但正如我们之前讨论的,样本群体中发生任何事故的概率非常罕见。同样,一个人有兴趣从样本中购买保险单的机会也相当低。因此,我们在本文中使用的数据集是高度不平衡的,我们将看到按原样使用该数据集将如何导致不良且有偏差的结果。因此,在进入建模部分之前,我们必须首先应用技术来平衡数据。
3.1 在进一步之前,请了解一些先决条件!
对于这个项目,您应该对 python 和Pandas、Numpy和Sklearn 等库有基本的了解。您应该了解机器学习中使用的基本术语,例如训练和测试数据、模型拟合、分类、回归、混淆度量以及逻辑回归、K 最近邻等基本机器学习算法。此外,探索性的粗略想法像 Matplotlib 和 seaborn 这样的数据分析和绘图库将会很有帮助。
3.2 了解更多关于数据集的信息
我 们将在本文中使用的数据集是不平衡保险数据。该数据集可以通过此链接下载。使用此数据集的目的是预测客户是否有兴趣购买车辆保险。为了预测这种客户行为,数据集中有几个特征。该数据集包括客户的年龄、性别、区号、车龄、车辆损坏等人口统计信息,还包含客户之前是否购买过保险、客户支付的保费以及保单等信息销售渠道。该数据集中的目标变量是响应变量,表示客户是否购买了车辆保险。
该数据集包含 3,82,154 行和 12 列,包括响应变量。为了了解有关数据集的更多信息,我们将使用 pandas 中的一些基本函数。
python代码:
import numpy as np
import pandas as pd
data = pd.read_csv("aug_train.csv")
print(data.head())在上面的代码片段中,我们使用 pandas.DataFrame.head() 函数来获取数据集中的前 5 个观测值。这将帮助我们了解我们将处理什么样的价值观。与 head 函数类似,您可以使用 pandas.DataFrame.tail() 函数获取数据集中的最后 5 个值。如果您想获取更多或更少的几行,您可以在函数中给出一个数字作为参数。
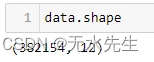
pandas.DataFrame.shape 允许我们获取数据集的结构。我们现在知道数据集包含 12 列和 3,82,154 条记录。
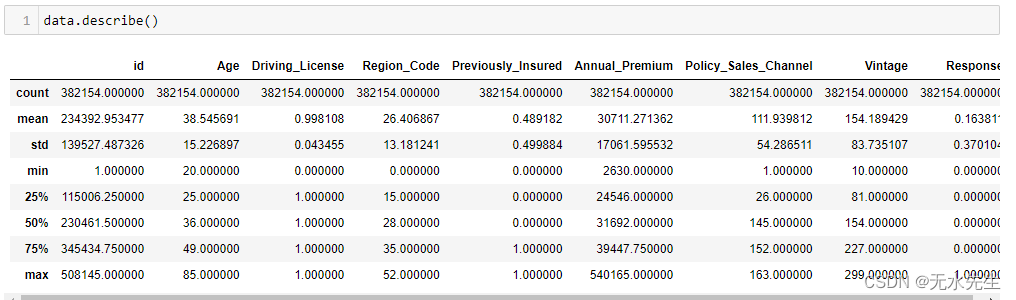
P pandas.dataFrame.describe() 函数提供了有关数据集的许多见解。此功能返回数据集的描述性统计数据,让我们了解分布的频率、集中趋势和离散度。此函数非常有用,但应小心一些,因为某些值可能没有意义。例如,在数据集中,区域代码是一个名义变量(可以分类但不能排名的数据),它的平均值没有意义。但是describe函数将其假定为整数值并返回平均区域码和区域码的标准差,这本身听起来很荒谬。
四、EDA 和目标数据分析
我们现在已经理解了问题陈述并对数据集有所了解。我们有了一个良好的开端,但关于该数据集还有很多东西需要了解。我们首先检查数据集是否包含任何空值。

从 上面的代码片段可以清楚地看出,数据集不包含任何空值。但是,如果您的数据集确实包含空值,那么您应该访问此链接。
接 下来,我们将分析目标变量,即响应变量。我们将看到响应变量如何分布在数据集中。
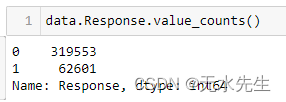
从上面的代码片段中,我们可以看到 Response 变量的值计数。我们看到响应变量高度不平衡,0 表示无响应是大多数类别。0 类表示客户对购买保险不感兴趣,而 1 类表示客户有兴趣。让我们使用饼图查看此分布的比率。这是我们使用绘图库 matplotlib 的地方。
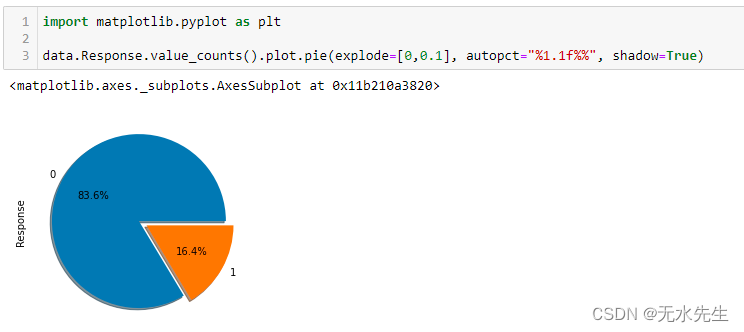
要了解有关 matplotlib 饼图参数的更多信息,请参阅此链接。从上面的饼图我们可以看到,Response类的分布比例几乎是84:16。事实上,数据集可能更加不平衡。因此,为了使其更有趣,我们将从正类中删除一些值。
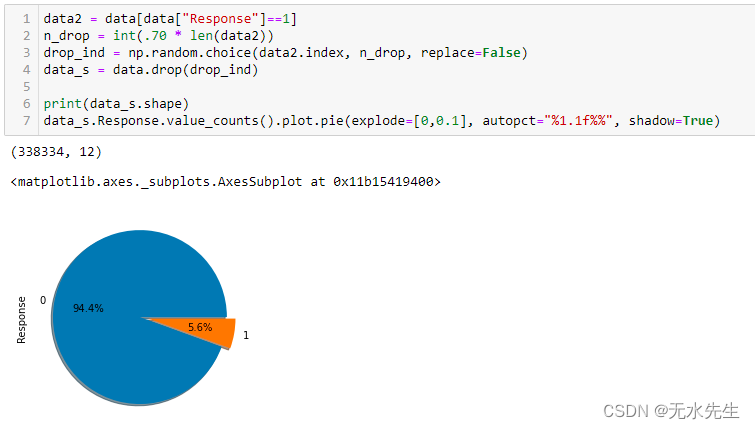
我们从正类中随机选择并丢弃 70% 的值,现在如您所见,不平衡比率为 95:5。
五、查找数据集中的异常值
在此步骤中,我们将在数据集中查找异常值。离群值是与总体中的其他值相比似乎异常的观察结果。异常值的原因可能是数据输入错误、抽样问题和异常情况。处理异常值很重要,因为它会降低统计功效并增加数据集中的变异性。
通常,最好不要为了得到更好的拟合模型而删除异常值,因为这可能会导致重要的合法信息丢失。然而,在本文中,我们的主要目的是学习如何处理不平衡数据,并且数据点很多。因此,我们可以考虑删除异常值。您可以参考此链接了解如何处理异常值。
我们将使用四分位数范围方法来查找数据集中的异常值。四分位数范围包含数据集第二和第三季度值所在的值。任何位于 (q1-1.5*IQR) 和 (q3+1.5*IQR) 之外的值都被视为异常值。
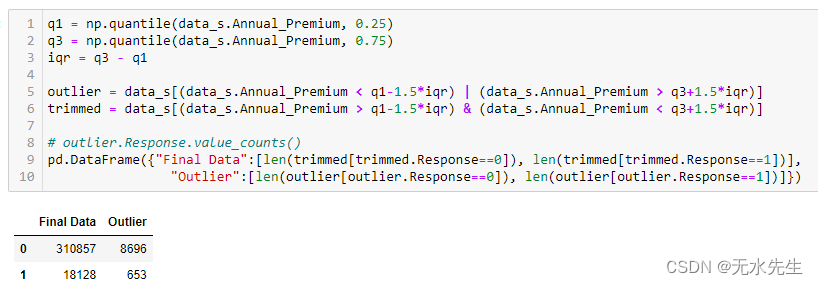
正如您在上面的代码片段中看到的,数据集中大约有 9000 个异常值。与原始数据集的大小相比,异常值的大小相当小。因此,我们可以从数据集中删除这些异常值。我们发现近 8500 个异常值属于负类,而大约 600 个异常值属于正类。因此,在删除这些异常值后,数据集的最终大小包含 3,10,857 个正响应类值和 18,147 个负响应类值。
六、 通过特征工程转换特征
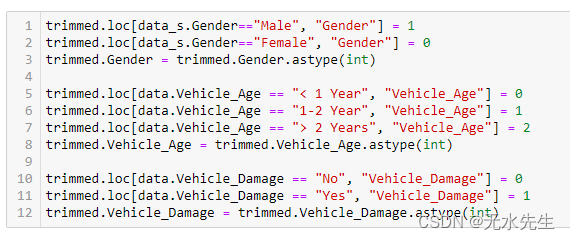
在此步骤中,我们将处理数据集中的分类数据。数据集的性别和车辆损坏特征具有二进制数据;也就是说,只有两个可能的值。因此,就性别而言,我们将男性指定为 1,女性指定为 0。同样,如果车辆损坏,我们将“是”指定为 1,将“否”指定为 0。然后,我们将特征的数据类型从字符串更改为整数。
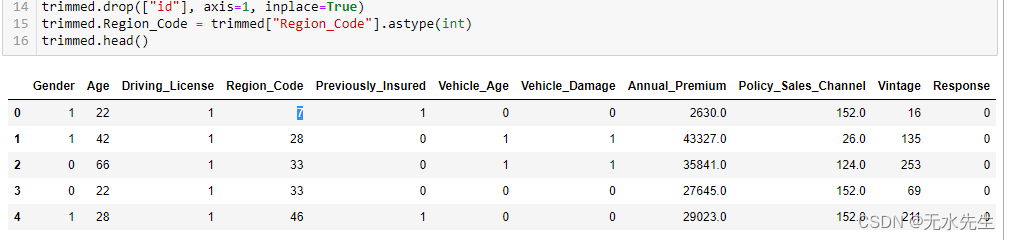
如果我们仔细观察数据集,我们会发现区域代码包含浮点值。由于区域代码是名义上的(意味着我们无法对区域代码进行排名,并且无法对区域代码进行比较或取平均值),因此浮点值没有意义。因此,我们将其数据类型更改为int。
数据集中的 id 变量包含用户的唯一键。因此,它对预测响应没有太大帮助。因此,我们将从数据集中删除 id 列。
七、热图在哪里?
在这一部分中,我们将了解这些特征如何相互关联以及它们如何影响响应变量。为此,我们将使用 python 中的 matplotlib 和 seaborn 库创建热图。热图是数据的二维图形表示,其中各个值包含在矩阵中并以颜色的形式表示。较浅的阴影表示彼此正相关的值,而较暗的阴影表示彼此负相关的值。热图是查找数据集中最重要元素的好方法,可用于查找数据中有趣的趋势。
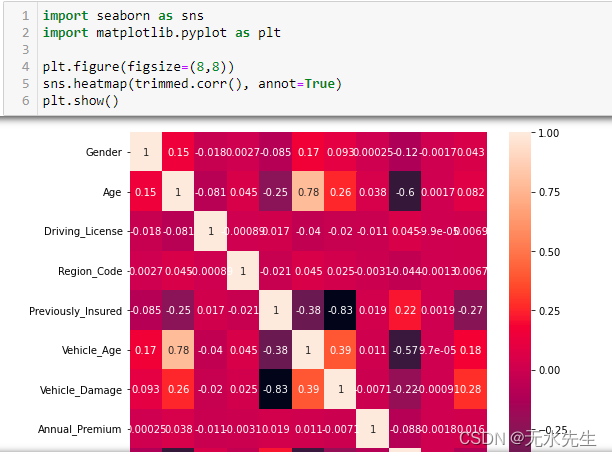
在上图中,您可以观察到每个值都与其自身完全相关,因此值为 1。您可以观察到先前保险的特征和车辆损坏与响应变量显示出相对较高的相关性。其他值几乎没有相关性,但我们仍然可以将它们用于建模部分。
八、 造型
在这一部分中,我们将把数据集分为训练数据和测试数据。我们将使用训练数据进行机器学习和模型,然后测试它在测试数据上的表现。我们将使用 70% 的数据进行训练,并保留 30% 的数据用于测试目的。我们将使用 sklearn 库的训练测试分割函数来执行此操作。

8.1 数据足够好吗?
在处理不平衡数据之前,我们首先创建一个函数来评估数据集。这样,我们就可以轻松评估用于平衡数据的技术。
我们将创建一个评估函数并使用五种机器学习算法在测试数据中进行预测。这些算法是逻辑回归、K 最近邻分类器、决策树分类器、朴素贝叶斯分类器和随机森林分类器。为了检查预测是否正确,我们将使用 f1 分数指标。

为了定义分类算法的执行情况,使用了混淆度量。我们不会详细介绍什么是混淆矩阵。简而言之,混淆矩阵比较模型的预测值和实际值。它可用于查找准确度、精确度、召回率和 f1 分数。您可以参考此链接 了解混淆矩阵。

一般来说,我们使用准确度指标来了解模型的表现如何。但是,如果您浏览上面的链接,您会发现使用 f1 分数是比不平衡数据集中的准确性更好的指标。简而言之,准确度分数无助于了解模型是否适用于这两个类别。相反,f1 分数有助于确定每个响应类的模型性能。
现在我们将使用 sklearn 库导入机器学习算法和用于衡量效率的 f1 分数。
8.2 消除数据集中的不平衡
现在是我们处理数据集中不平衡的部分。但问题来了,如果我们直接使用不平衡数据进行训练会发生什么?
按原样使用数据可能会获得良好的准确性分数,但如前所述,在处理不平衡数据时,准确性并不是正确的指标。
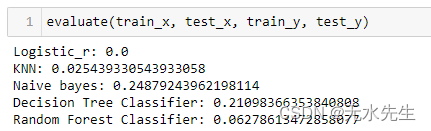
上面的代码片段显示逻辑回归、KNN 和随机森林分类器的 f1 分数几乎为 0。因此,我们可以得出结论,我们不能按原样使用数据,必须处理不平衡的数据。
处理不平衡数据有两种有效的方法:采样和加权。在本文中,我们将讨论采样和采样中的各种技术。
九、了解数据采样
数据采样是一种统计技术,用于操作和分析数据点的子集以识别较大集合中的模式。可以通过减少多数类的样本或增加少数类的样本来实现。采样时要记住的一件重要事情是,它仅应用于训练数据以影响机器学习模型。采样时测试数据保持不变。
9.1 欠采样
欠采样是一种用于平衡不均匀数据集的技术。当数据集包含大量数据点时使用此技术。这里,通过从多数类中删除一些样本来减小多数类的大小,而不对少数类进行任何改变以使其平衡。这是一个非常有用的技术。然而,它会导致信息丢失,因此当数据集已经具有很少的数据点时可以避免。
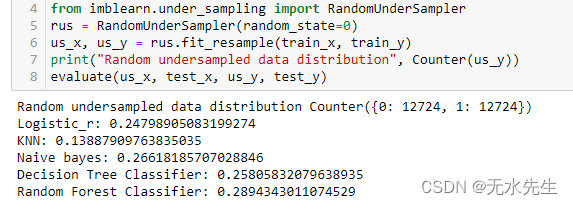
9.2 随机欠采样
欠采样是一种欠采样技术,其中样本是从多数类中随机选择并从训练数据中删除的。它也被称为朴素采样,因为它不对数据进行任何假设。该技术实现起来快速且简单,因此通常选择复杂且大型的数据集。它可用于二元或多类分类,可能具有一个或多个少数或多数类。
如前所述,随机欠采样可能会导致数据集中有用信息的丢失。解决这个问题的一种方法是使用抽样策略。使用抽样策略,我们可以提供少数类与多数类的所需比例。因此,我们可以决定我们可以承受多少数据丢失。
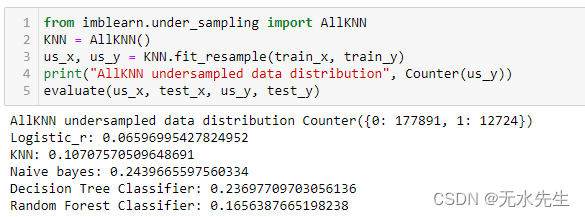
9.3 最近邻重采样
这种重采样使用最近邻算法来删除与其邻域不一致的样本。这包括算法的几种变体,例如编辑的最近邻居、重复编辑的最近邻居和 All KNN。这些算法可以在整个数据集上执行,或者特别是在大多数类上执行。
9.4 过采样
过采样是与欠采样相反的技术。在这种技术中,我们重现了少数类的样本并增加了少数类数据集。这种新的少数数据可以通过随机生成(随机过采样)或数学计算(SMOTE 采样)来添加。过采样非常有用;然而,它使得数据集容易过度拟合。
9.5 随机过采样
随机过采样与随机欠采样类似。它不是从多数类中删除样本,而是从少数类中随机选择样本并创建重复项。因此,增加了少数群体的规模。它快速且易于实施。然而,它可能会导致过度拟合。因此,我们可以使用采样策略来进行欠采样和过采样。
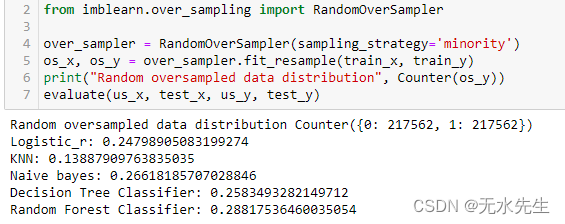
9.6 SMOTE(合成少数过采样技术)
它是最常见的过采样技术之一。它通过少数类的线性插值来复制少数类样本。该技术通过从少数类中随机选择一个或多个 k 个最近邻来生成综合训练记录。这种方法是有效的,因为它添加了来自少数类别的新合成样本,这些样本是合理的并且相对接近现有样本。尽管该算法有一个缺点,但它没有考虑多数类样本。因此,如果类之间存在大量重叠,则可能会出现不明确的记录。

9.7 欠采样后过采样
现在我们知道了欠采样和过采样的优缺点,我们可以结合使用它们来充分利用它们。我们可以手动应用欠采样,然后进行过采样,或者使用 imblearn 库。
首先,我们将 SMOTE 过采样与随机欠采样结合起来。在这里,我们将使用采样策略,因为我们不想同时对整个数据进行重新采样。可以调整该参数来改变数据分布并提高最终分数。
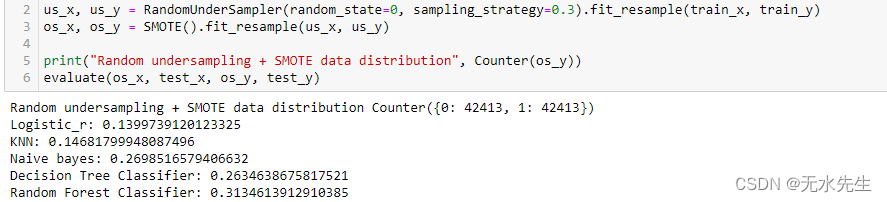
接下来,我们将使用 SMOTE 过采样和最近邻欠采样。这种组合已经在 imblearn 库中实现,并被证明是一种有效的采样方法。编辑的最近邻使用 3 个最近邻来定位数据集中那些错误分类的样本。

现在我们已经看到了几种平衡数据的方法。这取决于您使用哪种技术。但您应该对某种技术保持公正,并首先分析数据集,以了解需求并充分利用所有技术。您可以调整采样策略参数以改进结果以满足您的要求。如果你想学习更多采样技术,可以参考imblearn库的原始文档。
十、结论
来源:freepowerpointtemplates.com
在本文中,我们了解了使用机器学习的有趣的车辆保险数据集。我们看到一类如何主要分布在数据集中,而另一类很少存在于数据中。我们对数据进行了探索性数据分析并应用了特征工程。我们了解了为什么不能将这种不平衡数据视为平衡数据集。甚至用于评估不平衡数据的指标也与平衡数据中使用的指标不同。我们研究了如何处理数据不平衡的问题。
要点
1.你知道几种可以用来平衡这些数据的算法,这些算法只能用于建模。
2. 您看到了当数据集按原样使用时与使用采样技术修改数据集时模型的性能如何变化。
3. 了解每种算法的优缺点;最后,我们测试了结合这些采样算法是否会产生更好的结果。
您可以在此 git hub repo中找到本文的代码。读完本文后,我希望您知道如何处理不平衡的数据集。
您可以在这里查看我的更多文章。
您可以在 Linkedin 上与我联系。