文章目录
- 0 前言
- 1 Package 与环境
- 1.1 module
- 1.2 package
- 1.3 环境
- 2 Conda、Miniconda、Anaconda和Pip & PyPI
- 2.1 Conda
- 2. 2 Miniconda
- 2.3 Anaconda
- 2.3.1 Anaconda Navigator
- 2.3.2 Anaconda PowerShell Prompt & Anaconda Prompt
- 2.3.3 Jupyter notebook
- 2.4 Pip & PyPI
- 2.4.1 pip
- 2.4.2 PyPI
- 3 管理环境以及package
- 3.1 环境管理
- 3.1.1 查看已安装的环境:
- 3.1.2 创建新环境:
- 命令行创建新环境
- ANACONONDA.NAVIGATOR创建
- 新环境的位置
- 3.1.3 进入(激活)环境:
- 3.1.4 退出环境:
- 3.1.5 删除环境:
- 3.2 Package 管理
- 3.2.1 查看已安装的包:
- 3.2.2 安装包:
- 4 Jupyter Notebook
- 4.1 环境
- 4.2 内核
- 4.3 利用环境建立内核
- 5 参考资料
- 写在最后
0 前言
我们先来看几个问题:
-
Conda、MiniConda、Anaconda、Pip分别是什么含义,都有什么作用?
-
如何安装不同的 package,如何配置不同的虚拟环境 env?
-
为什么我明明已经通过 pip 安装了某个 package,编译器还是提示
No module named 'xxx',我的 package 安装到哪了? -
如何定制内核?
熟悉的小伙伴应该猜到了,我们今天要讲的是 Python 项目的配置问题。首先,我们先来理解一下 Package 与环境的概念。
1 Package 与环境
1.1 module
为了编写可维护可重用的代码,通常把代码按功能分类, 分别放在不同的文件里,这样每个文件中的代码就相对较少,且功能统一。 在Python中,一个 .py 脚本源码文件就称之为一个模块 (module)。
使用模块还可以避免函数名和变量名冲突。每一个模块都有自己的全局符号表,包含所有可以被其他模块使用的变量,函数等, 同名函数和变量可以同时存在不同的模块中,因此在编写模块时, 不必考虑名字会与其他模块冲突,这在多人协同编程时至关重要。
1.2 package
在实际的编码环境中,已经存在成千上万的模块,并且新模块还在不停被创建,此外多人协同编码时,不同的人编写的模块名也可能相同。基于这样的事实, 为了避免模块名冲突,Python 又引入了按目录来组织模块的方法,称为包(Package)。
简单说包就是一个文件夹,这个文件夹包含一个 init.py 文件,它可以是一个空文件。
引入了包以后,只要顶层的包名不冲突,那么所有的模块都不会冲突。一些知名的包有 numpy、pandas等等
你也可以将开发中常用的函数封装成库,上传到 PyPI 为 Python 社区贡献自己的力量。
1.3 环境
环境指的是 package 与 python 解释器的集合。不同的项目可能会使用到不同版本的 python 解释器、package。
2 Conda、Miniconda、Anaconda和Pip & PyPI
2.1 Conda
Conda 是一个开源的 package 管理系统和环境管理系统。通过 conda 你可以安装、更新、移除任何你需要的package,还可以创建、保存、加载以及切换运行环境。Conda 的命令可以参考 Cheat sheet。
Conda 可以运行在 Windows、MacOS 以及 Linux 系统上。虽然 Conda 一开始是为 Python 语言创造的,但是它也可以为其他程序语言(R, Ruby, Lua, Scala, Java, JavaScript, C/ C++, FORTRAN)解决 package management 以及 environment management 问题。
2. 2 Miniconda
Miniconda 是 conda 的一个免费最小安装程序。它是 Anaconda 的一个小型引导版本,仅包括 conda、Python、它们共同依赖的包以及一小部分其他有用的包(如 pip、zlib 等)。说白了,除了 condaAnaconda (Conda) for Python - What & Why?、Python 和其他一些共同依赖的包以外,不会向 Anaconda 一样预装一些数据科学以及数据分析的 package,相对更加轻量化。
安装 Miniconda 可以参考 Miniconda 官方指导文档,也可以参考视频 Anaconda (Conda) for Python - What & Why?。
2.3 Anaconda
Anaconda 是一家公司也是该公司开发的一款软件,该公司创立于2012年,当时旨在将Python应用于数据分析中。Anaconda 公司发行的 Anaconda 软件预装了一些数据分析领域的 package,是一个强大的 Python 数据科学发行版(这些包存放在base环境中)。Anaconda 中包含了 Conda。Anaconda 中的环境管理都是由 Conda 实现的,package 的管理则是由 Conda 或者 Pip 来实现。
在安装了 Anaconda 之后,在 Anaconda3 统计目录下会出现以下 .exe:
-
Anaconda Navigator
-
Anaconda Powershell Prompt
-
Anaconda Prompt
-
Jupyter notebook
2.3.1 Anaconda Navigator
Anaconda Navigator 是一个 Anaconda 的GUI 即用户图形交互界面,如下图所示:

你可以通过该 GUI 新建虚拟环境,并在相应的环境中导入 package、安装一些编译器等等。
2.3.2 Anaconda PowerShell Prompt & Anaconda Prompt
Anaconda PowerShell Prompt 和 Anaconda Prompt 是 Anaconda 提供的两个命令行工具,主要区别在于使用的命令行解释器。
Anaconda PowerShell Prompt:
- 使用 PowerShell 作为命令行解释器。
- PowerShell 是一种跨平台的脚本语言和命令行工具,具有强大的脚本编写和自动化功能。
- 在 Windows 系统上,Anaconda PowerShell Prompt 默认以管理员身份运行。
Anaconda Prompt:
- 使用传统的命令提示符(Command Prompt)或者终端作为命令行解释器。
- 对于 Windows 系统,可以使用 Command Prompt,对于类 Unix 系统(如 Linux、macOS),可以使用终端。
- 不同于 PowerShell,Anaconda Prompt 使用的是标准的命令行语法。
选择使用哪个取决于用户的偏好和操作系统。一些命令在 PowerShell 中可能略有不同,因此根据具体的需求选择合适的命令行提示符。我通常使用的是 Anaconda Prompt。
2.3.3 Jupyter notebook
Jupyter Notebook 是一个开源的交互式笔记本应用程序,支持多种编程语言。它允许用户创建和共享文档,其中包含实时代码、方程、可视化和叙述文本。
2.4 Pip & PyPI
pip 和 PyPI 是与 Python 包管理和分发有关的两个关键组件。
2.4.1 pip
pip 是 Python 的包管理工具,用于安装、升级和卸载 Python 包。它使得在 Python 环境中轻松管理第三方库和工具的安装,让开发者能够方便地获取、安装和管理各种 Python 软件包。
2.4.2 PyPI
PyPI 是 Python 包索引(Python Package Index)的缩写,是一个中央的存储库,用于存储和分发 Python 软件包。PyPI 提供了一个方便的途径,让开发者能够分享和发布他们编写的 Python 代码和软件包。pip 会从 PyPI 上下载并安装软件包。
在 PyPI 网站,开发者可以注册并上传他们的 Python 软件包,同时用户可以通过 pip 从 PyPI 下载这些软件包并在本地安装。这种集中化的存储和分发模型极大地方便了 Python 社区的开发和使用。
3 管理环境以及package
现在基本都是使用 Anaconda 软件来管理环境以及package(就是平常所说的包或者库,比如 numpy 包(库)),而在 Anaconda 中实际上是通过 Conda 来管理环境以及 package 的。现在就来看一下 Anaconda 中的 Conda 是如何通过命令行来管理环境以及 package 的。实际上 pip 也能实现对 package 的管理,命令与 Conda 类似,只需要将 conda 改成了 pip。以下用的是 conda 实现的 package 管理,pip 方法读者可以自行实现。
首先,打开 Anaconda Prompt,接下来的环境管理以及 package 管理都是在该命令行中进行操作的。
3.1 环境管理
3.1.1 查看已安装的环境:
conda env list
这将列出所有已创建的环境,当前激活的环境前面会有一个星号。
3.1.2 创建新环境:
我们在安装好 Aanconda 之后,会有一个预设的 base 环境,该环境中已经安装好了基本在数据科学领域需要的一切 package。在配置相关项目的环境时我们可以直接使用 base 环境,但是一般也推荐自己新建一个环境。关于为什么要自己新建环境,网上也没有过多的解释,我的理解是需要啥 package 增加就可以,自带的 base 环境臃肿,在部署项目的时候可能会占用不必要的空间。
使用 conda 创建的新环境默认存放在安装的 Anaconda 路径下的 envs 中,比如我的 Anaconda 安装在 "D:\software\anaconda3" 中,我新建的环境 myenv 的默认存放路径为"D:\software\anaconda3\envs" 。
创建新环境有两种方法:
- 命令行创建
- ANACONONDA.NAVIGATOR创建
命令行创建新环境
conda create --name myenv
这将创建一个名为 “myenv” 的新环境。你可以通过添加 python 参数指定 Python 版本:
conda create --name myenv python=3.8
你还可以在创建环境时直接安装包:
conda create --name myenv numpy pandas
ANACONONDA.NAVIGATOR创建
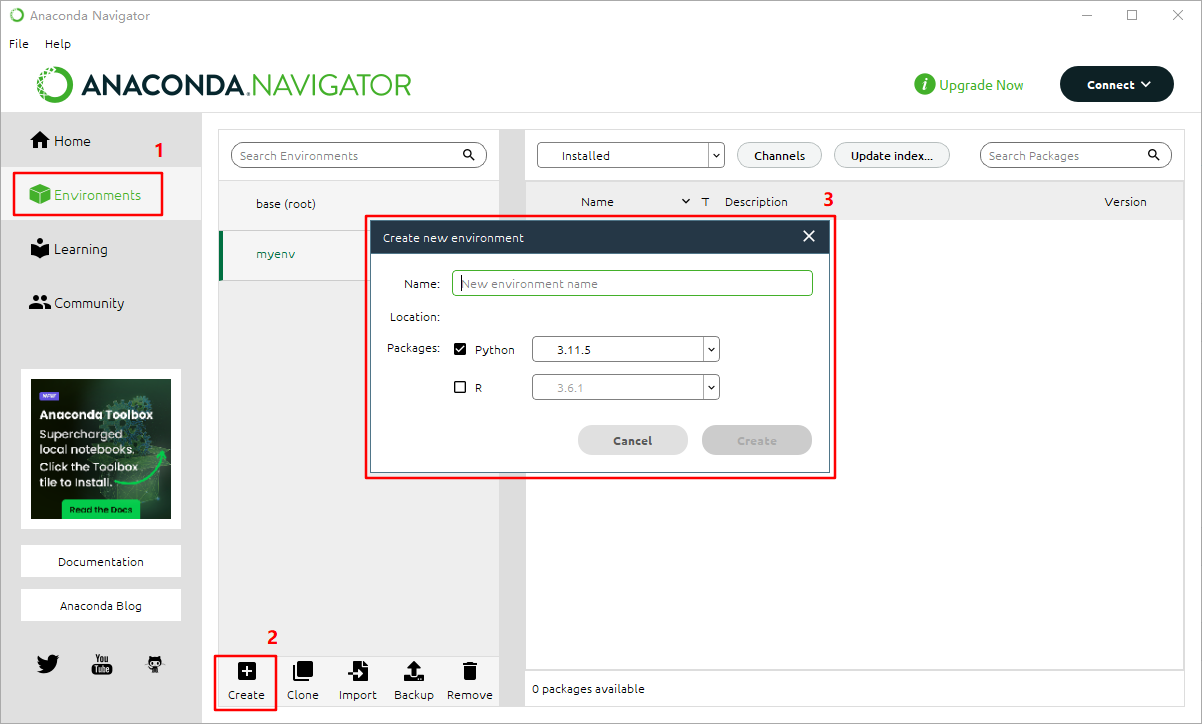
首先打开ANACONONDA.NAVIGATOR
- 点击左侧的
Environments,会看到已经存在的一些环境; - 点击环境下方的
create; - 在弹出的对话框中输入新环境的名字、选择默认安装的包(Python或者R,均可以选择安装版本),输入完成后点击
Creat完成新环境的创建。
通过以上两种不同的创建新环境的过程,我们知道可以通过命令行来创建一个完全空的环境,而通过 ANACONONDA.NAVIGATOR 创建新环境必须至少安装一个 Python 或者 R 语言包。
新环境的位置
如果不想在默认路径下新建新环境,如何修改呢?通过以下代码在指定路径中创建新环境:
conda create --prefix="E:\envs\myenv"
其中,"E:\envs\myenv" 是你电脑已经存在的并且你想存放新环境的路径,"myenv" 是你的环境的名称。
3.1.3 进入(激活)环境:
要进入 conda 创建的某个环境,可以使用以下命令:
conda activate 你的环境名
如果你使用的是 conda 的旧版本,可能需要使用 source 命令:
source activate 你的环境名
这将激活指定的环境,使你的命令行提示符前面显示当前环境的名称。在这个环境中,你可以安装、升级和删除包,而这些操作都将影响选定的环境而不是系统 Python。
注意: 如果你使用的是 Windows 操作系统,可能需要使用 activate 命令,而不是 source activate。在新版本的 conda 中,activate 和 source activate 是等效的。
3.1.4 退出环境:
conda deactivate
这将退出当前激活的环境。
3.1.5 删除环境:
要删除一个 Conda 环境,可以使用以下命令:
conda env remove --name your_environment_name
这里,your_environment_name 是你要删除的环境的名称。请确保在删除环境之前你已经退出该环境,因为删除正在使用的环境可能导致问题。
例如,如果你有一个名为 myenv 的环境,你可以使用以下命令删除它:
conda env remove --name myenv
执行这个命令后,Conda 会提示你确认删除。输入 y 确认删除即可。
请注意,删除环境将会删除该环境中安装的所有包和文件,因此请确保你真的想要删除该环境。如果你真的需要删除这个环境,在通过命令行删除相应的环境之后,记得将环境文件夹以及对应的内核文件夹删除,以释放相应的空间。
3.2 Package 管理
3.2.1 查看已安装的包:
conda list
通过以上命令将列出当前激活环境中安装的所有包。在查看已安装的包之前,你要明确你是想查看哪一个环境下的 package,也就是说你要首先选择环境,进入(激活)相应的环境。如何进入(激活)环境,将在后面进行介绍。
3.2.2 安装包:
conda install package_name
这将安装指定的包,例如:
conda install numpy
你还可以通过指定版本号安装特定版本的包:
conda install numpy=1.18.5
如果在安装某个 package 时遇到以下的情况:
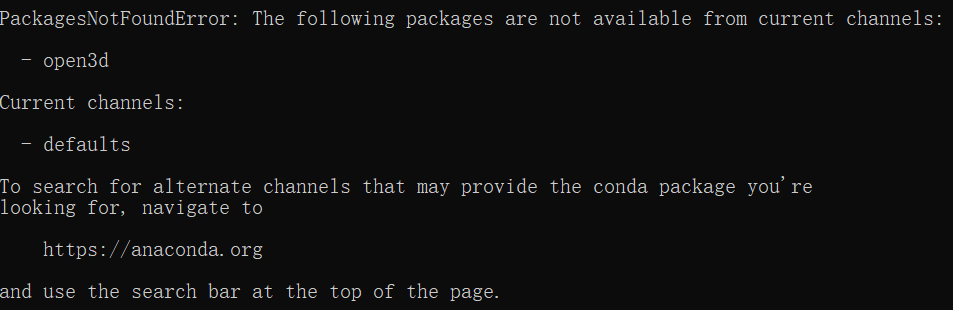
那就说明默认的 channel 无法获取到这个 package 的安装路径,你就需要通过 anaconda.org/ 网站的搜索框来查询安装这个 package 的方法。如果在安装过程中出现错误,可以使用 pip 进行安装。
4 Jupyter Notebook
关于 Jupyter Notebook 的安装与使用,网络上相关的博文有很多,大家可以参考学习。这里我想讲的是我对于环境与内核这两个概念的理解。
4.1 环境
环境通常指的是 Python 虚拟环境,它是一个隔离的 Python 运行环境,用于管理项目的依赖关系。使用 conda 可以创建不同的 Python 环境,每个环境都有自己的包和版本,避免了项目之间的依赖冲突。在 Jupyter Notebook 中,你可以选择不同的环境来运行 notebook。
在使用虚拟环境时,确保在你的虚拟环境中安装了 Jupyter 并且在该环境中启动 Jupyter Notebook,这样你就可以在 notebook 中使用与虚拟环境关联的 Python 版本和包。
4.2 内核
内核是 Jupyter Notebook 与编程语言的交互接口,它负责执行代码、管理变量和输出结果。对于 Python,Jupyter Notebook 使用 IPython 作为默认的内核。IPython 是一个增强版的 Python 解释器,提供了更强大的交互式计算功能。你可以在 Jupyter Notebook 中选择不同的内核,这意味着你可以在同一个 notebook 中使用不同的编程语言。
在 Jupyter Notebook 的右上角,你会看到一个下拉菜单,其中包括当前 notebook 使用的内核。通过这个菜单,你可以切换到其他已安装的内核。
4.3 利用环境建立内核
一个环境其实就是一个内核,我们可以把某个环境 “封装” 成不同名字的内核。
通过 jupyter kernelspec list 命令可以查询目前存在的内核,我们可以在某一个环境下的 jupytet notebook 中切换使用不同的内核。
打开 Anaconda Prompt,通过 conda env list 查看现在有哪些环境;通过 activate xxx 进入/激活某个环境;如果你想用 jupyter notebook 在这个环境中进行交互式写代码,你需要安装 jupyter notebook,两种方式:一是通过 anaconda GUI 安装,另一种是命令行安装;接着要为 jupyter nootbook 定制内核,默认需要安装 ipykernel 内核,在命令行中通过 conda install ipykernel 命令安装内核 ipykernel。
根据自定义的新环境定制你需要的内核,通过以下命令完成内核定制:
python -m ipykernel install --user --name your_environment_name --display-name "Your Display Name"
替换 your_environment_name 为你的环境名称,Your Display Name 为你想要在 Jupyter Notebook 中显示的内核名称。
注意:将某个环境定制为内核的时候,一定要进入到该环境中,再执行上述定制内核命令。比如,我想将环境
ai38定制为 “torch2.1” 内核(“torch2.1” 是内核显示的名字),我需要先通过命令conda activate ai38进入到环境ai38中,然后通过命令python -m ipykernel install --user --name ai38 --display-name "torch2.1"完成内核的定制。
5 参考资料
以下参考资料不分先后。
- Jupyter Notebook增加kernel详细步骤
- Anaconda (Conda) for Python - What & Why?
- import torch 或其他包,但是Jupyter notebook 不显示的原因解决 | 解决Jupyter Notebook:no module named但实际已经pip install问题
写在最后
如果文章内容有任何错误或者您对文章有任何疑问,欢迎私信博主或者在评论区指出 💬💬💬。
如果大家有更优的时间、空间复杂度方法,欢迎评论区交流。
最后,感谢您的阅读,如果感到有所收获的话可以给博主点一个 👍 哦。










![⑦【Redis GEO 】Redis常用数据类型:GEO [使用手册]](https://img-blog.csdnimg.cn/20a7f1b58dfb4660b75d7f021c157d57.png#pic_center)
