尼恩说在前面
在40岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、shein 希音、百度、网易的面试资格,遇到很多很重要的面试题:
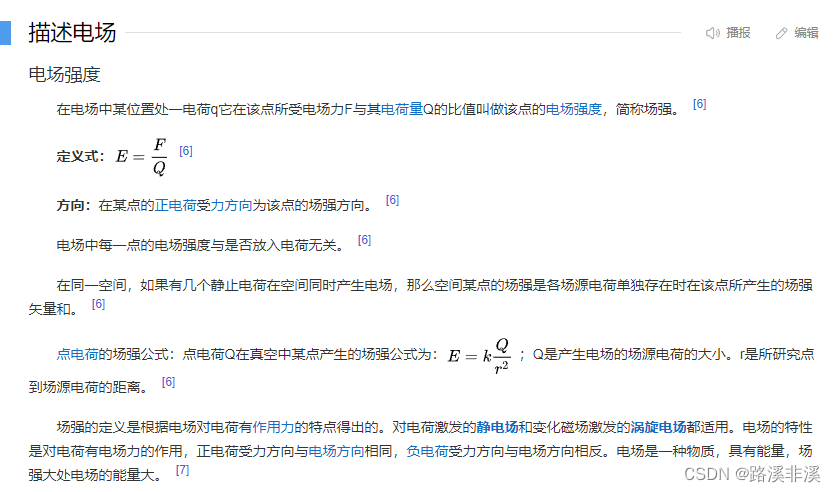
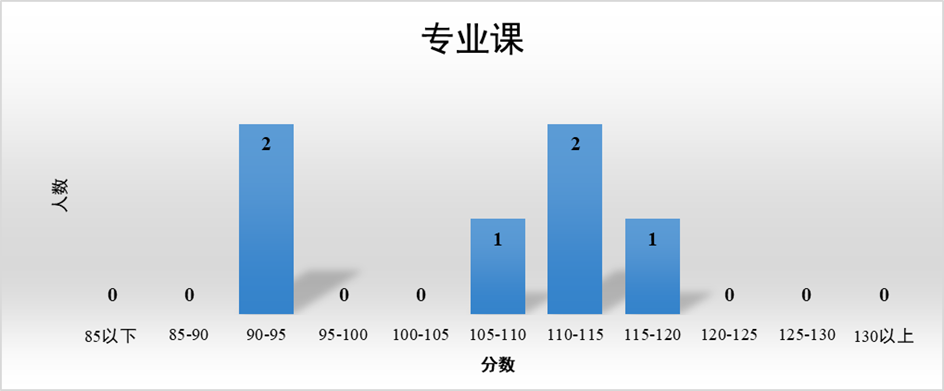
MySQL为何需要4M来双写?为什么redo不双写?
说说MySQL双写缓冲区?
小伙伴 没有回答好,导致面试挂了,来求助尼恩,如何才能回答得很漂亮, 让面试官刮目相看、口水直流。
MySQL双写, 尼恩在自己的社群里边问了一下, 很多小伙伴都没有听过说。
所以,尼恩给大家做一下系统化、体系化的梳理,使得大家内力猛增,可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提”。
当然,这道面试题,以及参考答案,也会收入咱们的 《尼恩Java面试宝典》V131版本PDF集群,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》的PDF,请到文末公号【技术自由圈】获取
文章目录
- 尼恩说在前面
- InnoDB 存储引擎
- InnoDB 存储结构
- 1、磁盘结构
- 1.1 表空间 Tablespaces
- 系统表空间 System Tablespace
- 独立表空间
- 其他类型的表空间
- 表空间结构
- 1.2 重写日志 redo log 文件
- 1.3 Double Write Files 双写缓冲文件
- 2、内存结构
- 2.1 缓存池 Buffer Pool
- 2.2 写缓冲 Change Buffer
- 2.3 自适应散列索引 Adaptive Hash Index
- 2.4 重做日志缓冲区 rodo Log Buffer
- 回到问题:为什么需要redo log
- 为什么写数据需要Double write Buffer
- Doublewrite Buffer原理
- Doublewrite Buffer相关参数
- Doublewrite Buffer和redo log
- 总结
- 说在最后
- 尼恩技术圣经系列PDF
InnoDB 存储引擎
InnoDB 存储引擎最早由 Innobase Oy 公司开发(属第三方存储引擎)。
从 MySQL 5.5 版本开始作为表的默认存储引擎。该存储引擎是第一个完整支持 ACID 事务的 MySQL 存储引擎,特点是行锁设计、支持 MVCC、支持外键、提供一致性非锁定读,非常适合 OLTP 场景的应用使用。
目前也是应用最广泛的存储引擎。
InnoDB 存储引擎架构包含内存结构和磁盘结构两大部分
MySQL 8.0 版本,总体架构图如下:

注意:请点击图像以查看清晰的视图!
MySQL 5.5 版本,总体架构图如下:

注意:请点击图像以查看清晰的视图!
InnoDB 存储结构
1、磁盘结构
1.1 表空间 Tablespaces
InnoDB 存储引擎的逻辑存储结构是将所有的数据都被逻辑地放在了一个空间中,这个空间中的文件就是实际存在的物理文件(.ibd 文件),即表空间。
默认情况下,一个数据库表占用一个表空间,表空间可以看做是 InnoDB 存储引擎逻辑结构的最高层,所以的数据都存放在表空间中,例如:表对应的数据、索引、insert buffer bitmap undo 信息、insert buffer 索引页、double write buffer files 等都是放在共享表空间中的。
表空间分为:
- 系统表空间 (ibdata1 文件)(共享表空间)
- 临时表空间
- 常规表空间
- Undo 表空间
- file-per-table 表空间 (独立表空间)。
系统表空间又包括双写缓冲区 (Doublewrite buffer)、Change Buffer 等
系统表空间 System Tablespace
系统表空间可以对应文件系统上一个或多个实际的文件,
默认情况下, InnoDB 会在数据目录下创建一个名为.ibdata1的文件,大小为 12M
这个.ibdata1文件就是对应的系统表空间在文件系统上的表示。
.ibdata1这个文件是可以自扩展的,当不够用的时候它会自己增加文件大小。
需要注意的一点是,在一个 MySQL 服务器中,系统表空间只有一份。
从 MySQL5.5.7 到 MySQL5.6.6 之间的各个版本中,我们表中的数据都会被默认存储到这个系统表空间。
show variables like '%innodb_data_file_path%'

独立表空间
在 MySQL5.6.6 以及之后的版本中, InnoDB 并不会默认的把各个表的数据存储到系统表空间中,而是为每一个表建立一个独立表空间,也就是说我们创建了多少个表,就有多少个独立表空间。
使用独立表空间来存储表数据的话,会在该表所属数据库对应的子目录下创建一个表示该独立表空间的文件,文件名和表名相同,只不过添加了一个.ibd 的扩展名而已。
show variables like '%innodb_file_per_table%'

独立表空间只是存放数据、索引和插入缓冲 Bitmap 页,其他类的数据如回滚(undo)信息、插入缓冲索引页、系统事务信息、二次写缓冲等还是存放在原来的系统表空间。
其他类型的表空间
随着 MySQL 的发展,除了上述两种表空间之外,现在还新提出了一些不同类型的表空间,比如通用表空间 (general tablespace)、undo 表空间 (undo tablespace)、临时表空间 (temporary tablespace) 等
表空间结构
表空间又由段 (segment)、区 ( extent)、页 (page) 组成,页是 InnoDB 磁盘管理的最小单位。
在我们执行 sql 时,不论是查询还是修改,mysql 总会把数据从磁盘读取内内存中,而且在读取数据时,不会单独加在一条数据,而是直接加载数据所在的数据页到内存中。
表空间本质上就是一个存放各种页的页面池。

注意:请点击图像以查看清晰的视图!
「page页」是 InnoDB 管理存储空间的基本单位,也是内存和磁盘交互的基本单位。
也就是说,哪怕你需要 1 字节的数据,InnoDB 也会读取整个页的数据,
InnoDB 有很多类型的页,它们的用处也各不相同。
比如:有存放 undo 日志的页、有存放 INODE 信息的页、有存放 Change Buffer 信息的页、存放用户记录数据的页(索引页)等等。
InnoDB 默认的页大小是 16KB,在初始化表空间之前可以在配置文件中进行配置,一旦数据库初始化完成就不可再变更了。
SHOW VARIABLES LIKE 'innodb_page_size'

1.2 重写日志 redo log 文件
redo log 记录数据库的变更,数据库崩溃后,会从 redo log 获取事务信息,进行系统恢复。
redo log 在磁盘上表现为 ib_logfile0 和 ib_logfile1 两个文件。
MySQL 会在事务的提交前将 redo 日志刷新回磁盘。
在同一时间提交的事务,会采用组提交(group commit)的方式一次性刷新回磁盘。从而避免一个事务刷新一次磁盘,提高性能。
1.3 Double Write Files 双写缓冲文件
double write 是保障 InnoDB 存储引擎操作数据页的可靠性。
double write 分为两部分组成,一部分在内存中的 double write buffer, 大小为 2MB,另一部分是物理磁盘上共享表空间中连续的 128 个数据页,即 2 个区大小(同样是 2MB)。

InnoDB存储引擎doublewrite架构
注意:请点击图像以查看清晰的视图!
2、内存结构
InnoDB 存储引擎是基于磁盘存储的,并将其中的记录按照页的方式进行管理,因此可将其视为基于磁盘的数据库系统(Disk-base Database)。
在数据库中 CPU 速度与磁盘速度是有很大差距的,所以,基于磁盘的数据库系统通常使用缓冲池技术来提高数据库的整体性能。结构如图所示:

注意:请点击图像以查看清晰的视图!
2.1 缓存池 Buffer Pool
Buffer Pool 是 InnoDB 内存中的一块占比较大的区域,通过内存的速度来弥补磁盘速度慢对数据库性能的影响。
在数据库中进行读取页的操作,首先将从磁盘读到的页放在缓冲池中,这个过程称为将页”FIX” 在缓冲池中,
下次再读到相同的页时,首先判断该页是否在缓冲池中,若在缓冲池中,直接读取该页,否则读取磁盘上的页。
对于数据库中的页的修改操作,首先修改在缓冲池中的页,然后再以一定频率刷新到磁盘上,
这里需要注意的是,页从缓冲池刷新回磁盘的操作并不是在每次页发生更新时触发,而是通过一种称为 Checkpoint 的机制刷新回磁盘。
缓存区缓存的数据页类型有:索引页,数据页,undo 页,插入缓冲(change buffer),自适应哈希索引(adaptive hash index),InnoDB 存储锁信息(lock info),数据字典信息(data dictionary)。数据页和索引页占据了缓冲池很大部分。
2.2 写缓冲 Change Buffer
在 MySQL5.5 之前,叫插入缓冲(Insert Buffer),只针对 INSERT 做了优化;
现在对 DELETE 和 UPDATE 也有效,叫做写缓冲(Change Buffer)。
它是一种应用在非唯一普通索引页(non-unique secondary index page)不在缓冲池中,对页进行了写操作,并不会立刻将磁盘页加载到缓冲池,而仅仅记录缓冲变更(Buffer Changes),等未来数据被读取时,再将数据合并(Merge)恢复到缓冲池中的技术。写缓冲的目的是降低写操作的磁盘 IO,提升数据库性能。
2.3 自适应散列索引 Adaptive Hash Index
自适应哈希索引用于优化对 BP 数据的查询。
InnoDB 存储引擎会监控对二级索引数据的查找,如果观察到建立哈希索引可以带来速度的提升 (最近连续被访问三次的数据),则建立哈希索引,自适应哈希索引通过缓冲池的 B + 树构造而来,因此建立的速度很快。
InnoDB 存储引擎会自动根据访问的频率和模式来为某些页建立哈希索引。(在高负载系统下 AHI 容易产生资源的争用,进而引起一些 bug 导致系统受影响甚至崩溃,故建议关闭该功能)
2.4 重做日志缓冲区 rodo Log Buffer
重做日志缓冲区,当在 MySQL 中对 InnoDB 表进行数据更改时,这些更改首先存储在 InnoDB 日志缓冲区的内存中,然后再写入重做日志(redo logs)的 InnoDB 日志磁盘文件中。
rodo Log Buffer让 MySQL 在崩溃的时候具有了恢复数据的能力,即在数据库发生意外的时候,可以进行数据恢复;
日志缓冲区 log buffer 是内存存储区域,用于保存要写入磁盘上的日志文件的数据。
日志缓冲区大小由 innodb_log_buffer_size 变量定义,默认大小为 16MB。
日志缓冲区的内容定期刷新到磁盘。
较大的日志缓冲区可以运行大型事务,而无需在事务提交之前将重做日志数据写入磁盘。
因此,如果有更新,插入或删除许多行的事务,则增加日志缓冲区的大小可以节省磁盘 I/O。
回到问题:为什么需要redo log
先用一个表对redo log 、undo log、binlog三种日志进行对比 介绍,方便大家理解, 下表涉及到redo log 、undo log、binlog三种日志使用场景和文件等

注意:请点击图像以查看清晰的视图!
undolog、redolog都是InnoDB引擎中的日志,都是在Buffer Pool中,而binlog在Server层中,位于每条线程中,
redo log 、undo log、binlog三大日志在磁盘中的的归档方式和文件都是不一样的,之间的区别如下图。

注意:请点击图像以查看清晰的视图!
在InnoDB存储引擎中,大部分redo log记录的是物理日志,具体来说,就是记录某个数据页做了什么修改。
前面讲到, 所有数据页的读写操作都要通过buffer pool进行
- innodb的读操作:先从buffer pool中查看数据的数据页是否存在,如果不存在,则将数据页先从磁盘读到buffer pool中然后在读
- innodb的写操作:先把数据和日志写入buffer pool和log buffer,再由后台线程以一定的频率将buffer中的内存刷到磁盘。
buffer pool是一块内存区域,是一种“降低磁盘访问机制”,buffer pool缓存数据表和索引数据,吧磁盘上的数据加载到缓冲池,避免每次访问都进行磁盘IO,起到加速访问的作用。
buffer pool也是以页为存储单位(与磁盘中数据页索引页单位一样,默认大小16K),buffer pool底层采用链表的数据结构管理page。
写操作的事务持久性由redo log落盘保证,buffer pool只是为了提高读写效率。
当buffer pool中某页的数据更改后,这个页就变成了脏页(因为mysql为了提升性能,避免频繁的随机IO,每次更改数据不是第一时间去更改磁盘数据,这就导致了buffer pool中的数据和磁盘数据不一致)
实际上, redo log日志主要包括两部分:
- 一是在内存中重做日志缓冲(redo log Buffer)易丢失,在内存中,
- 二是重做日志文件(redo log file),保存在磁盘中。
为了保证脏页落盘的安全性,防止断电丢失等,会 WAL 预写redo log Buffer 中的日志到磁盘中。
WAL机制是什么?
WAL,全称是Write-Ahead Logging, 预写日志系统。指的是 MySQL 的写操作并不是立刻更新到磁盘上,而是先记录在日志上,然后在合适的时间再更新到磁盘上。
MySQL真正使用WAL的原因是:磁盘的写操作是随机IO,比较耗性能,所以如果把每一次的更新操作都先写入log中,那么就成了顺序写操作,实际更新操作由后台线程再根据log异步写入。
通过WAL,这样对于client端,延迟就降低了。
并且,由于顺序写入大概率是在一个磁盘块内,这样产生的IO次数也大大降低。
所以WAL的核心在于将随机写转变为了顺序写,降低了客户端的延迟,提升了吞吐量。
使用redo log的好处主要2点:
- 降低刷盘频率:变更日志先行存入
redo log buffer,脏页刷盘和redo log buffer刷盘时机可控; - 日志占用空间小:存储表空间
ID、页号、偏移量和需要更新的值。

注意:请点击图像以查看清晰的视图!
为什么写数据需要Double write Buffer
MySQL程序是跑在Linux操作系统上的,理所当然要跟操作系统交互,
一般来说,MySQL中一页数据是16kb,操作系统一个页是 4kb,所以,mysql page 刷到磁盘,要写4个文件系统里的页。
如图所示:

注意:请点击图像以查看清晰的视图!
需要注意的是,这个刷页的操作并非原子操作,比如我操作系统写到第二个页的时候,Linux机器断电了,这时候就会出现问题了。
上面的问题,也叫「Partial Page Write(部分页写入)」问题,或者叫做「页数据损坏」。并且这种页数据损坏靠 redo日志是无法修复的。
为啥 redo日志是无法修复 部分页写入问题呢?
具体来说,和redo 的记录内容有关。 redo log 的内容包括 存储表空间ID、页号、偏移量和需要更新的值。
也就是说,redo log日志中记录的是对页的物理操作,而不是页面的全量记录,当发生「Partial Page Write(部分页写入)」问题时,如果出现问题的数据是未修改过的数据,此时redo日志无能为力
Doublewrite Buffer 就是为了解决「页数据损坏」 问题的。
Doublewrite Buffer 提供了数据页的可靠性,虽然名字带了Buffer,但实际上Doublewrite Buffer是「内存+磁盘」的结构。
Doublewrite Buffer 包括两个部分:
-
内存结构:Doublewrite Buffer内存结构由128个页(Page)构成,大小是2MB。
-
磁盘结构:Doublewrite Buffer磁盘结构在系统表空间上是128个页(2个区,extend1和extend2),大小是2MB。
Doublewrite Buffer的原理是,再把数据页写到数据文件之前,InnoDB先把它们写到一个叫「doublewrite buffer(双写缓冲区)」的共享表空间内,在写doublewrite buffer完成后,InnoDB才会把页写到数据文件适当的位置。
如果在写页的过程中发生意外崩溃,InnoDB会在doublewrite buffer中找到完好的page副本用于恢复。
Doublewrite Buffer原理

注意:请点击图像以查看清晰的视图!
如上图所示,当有数据页要刷盘时:
- 页数据先通过
memcpy函数拷贝至内存中的Doublewrite Buffer中。 - Doublewrite Buffer的内存里的数据页,会
fsync刷到Doublewrite Buffer的磁盘上,分两次写入磁盘共享表空间中(连续存储,顺序写,性能很高),每次写1MB。 - Doublewrite Buffer的内存里的数据页,再刷到数据磁盘存储.ibd文件上(离散写)。
所以在正常的情况下,MySQL写数据页时,会写两遍到磁盘上,
- 第一遍是写到doublewrite buffer,
- 第二遍是写到真正的数据文件中,这便是「Doublewrite」的由来。
如果操作系统在将页写入磁盘的过程中发生了崩溃,在恢复过程中,InnoDB存储引擎可以从共享表空间中的Double write中找到该页的一个副本,将其复制到表空间文件,再应用redo日志。
Doublewrite Buffer相关参数
以下是一些与Doublewrite Buffer相关的参数及其含义:
innodb_doublewrite: 这个参数用于启用或禁用双写缓冲区。设置为1时启用,设置为0时禁用, 默认值为1。innodb_doublewrite_files: 这个参数定义了多少个双写文件被使用。默认值为2,有效范围从2到127。innodb_doublewrite_dir: 这个参数指定了存储双写缓冲文件的目录的路径。默认为空字符串,表示将文件存储在数据目录中。innodb_doublewrite_batch_size: 这个参数定义了每次批处理操作写入的字节数。默认值为0,表示InnoDB会选择最佳的批量大小。innodb_doublewrite_pages:这个参数定义了每个双写文件包含多少页面。默认值为128。
Doublewrite Buffer和redo log
在MySQL的InnoDB存储引擎中,Redo log和Doublewrite Buffer共同工作以确保数据的持久性和恢复能力。
-
首先wal架构:当有一个DML(如INSERT、UPDATE)操作发生时, InnoDB会首先将这个操作写入redo log(内存)。这些日志被称为未检查点(uncheckpointed)的redo日志。
-
然后,在修改内存中相应的数据页之后,需要将这些更改记录在磁盘上。
但是直接把这些修改的页写到其真正的位置可能会因发生故障导致页部分更新,从而导致数据不一致。
因此,InnoDB的做法是先将这些修改的页按顺序写入doublewrite buffer。
这就是为什么叫做 “doublewrite” —— 数据实际上被写了两次,先在doublewrite buffer,然后在它们真正的位置。
-
一旦这些页被安全地写入doublewrite buffer,它们就可以按原始的顺序写回到文件系统中。
即使这个过程在写回数据时发生故障,我们仍然可以从doublewrite buffer中恢复数据。
-
最后,当事务提交时,相关联的redo log会被写入磁盘。这样即使系统崩溃,redo log也可以用来重播(replay)事务并恢复数据库。
在系统恢复期间,InnoDB会检查doublewrite buffer,并尝试从中恢复损坏的数据页。
如果doublewrite buffer中的数据是完整的,那么InnoDB就会用doublewrite buffer中的数据来更新损坏的页。
否则,如果doublewrite buffer中的数据不完整,InnoDB也有可能丢弃buffer内容,重新执行那条redo log以尝试恢复数据。
所以,Redo log和Doublewrite Buffer的协作可以确保数据的完整性和持久性。如果在写入过程中发生故障,我们可以从doublewrite buffer中恢复数据,并通过redo log来进行事务的重播。
总结
Doublewrite Buffer是InnoDB的一个重要特性,用于保证MySQL数据的可靠性和一致性。
它的实现原理是通过将要写入磁盘的数据先写入到Doublewrite Buffer中的内存缓存区域,然后再写入到磁盘的两个不同位置,来避免由于磁盘损坏等因素导致数据丢失或不一致的问题。
总的来说,Doublewrite Buffer对于改善数据库性能和数据完整性起着至关重要的作用。尽管其引入了一些开销,但在大多数情况下,这些成本都被其提供的安全性和可靠性所抵消。
说在最后
MySQL双写面试题,是非常常见的面试题。
以上的内容,如果大家能对答如流,如数家珍,基本上 面试官会被你 震惊到、吸引到。
在面试之前,建议大家系统化的刷一波 5000页《尼恩Java面试宝典PDF》,并且在刷题过程中,如果有啥问题,大家可以来 找 40岁老架构师尼恩交流。
最终,让面试官爱到 “不能自已、口水直流”。offer, 也就来了。
尼恩技术圣经系列PDF
- 《NIO圣经:一次穿透NIO、Selector、Epoll底层原理》
- 《Docker圣经:大白话说Docker底层原理,6W字实现Docker自由》
- 《K8S学习圣经:大白话说K8S底层原理,14W字实现K8S自由》
- 《SpringCloud Alibaba 学习圣经,10万字实现SpringCloud 自由》
- 《大数据HBase学习圣经:一本书实现HBase学习自由》
- 《大数据Flink学习圣经:一本书实现大数据Flink自由》
- 《响应式圣经:10W字,实现Spring响应式编程自由》
- 《Go学习圣经:Go语言实现高并发CRUD业务开发》
……完整版尼恩技术圣经PDF集群,请找尼恩领取
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》PDF,请到下面公号【技术自由圈】取↓↓↓