在数据采集的过程中,需要从不同渠道获取数据并汇集在数仓中,采集的原始数据首先需要进行解析,然后对不准确、不完整、不合理、格式、字符等不规范数据进行过滤清洗,清洗过的数据才能更加符合需求,从而使后续的数据分析应用更为准确。因此在数据分析、挖掘、可视化实现以及统计报表之前,做好相关的数据清洗工作意义重大。
一、数据清洗概述
数据清洗是指对数据进行重新审查和校验的过程中,发现并纠正数据文件中可识别的错误,按照一定的规则把错误或冲突的数据洗掉,包括检查数据一致性,处理无效值和缺失值等,数据清理一般是由计算机而不是人工完成。
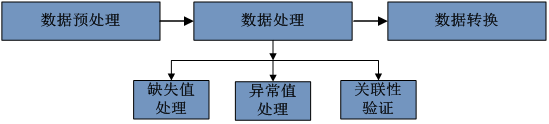
二、数据清洗原理
利用数理统计、数据挖掘和预定义清理规则等有关技术将“脏数据”处理掉,从数据源中检测并消除错误、不一致、不完整和重复等数据,为满足要求提供高质量的数据。数据清理的标准模型是将数据输入到数据清理处理器,通过一系列步骤清理数据,然后以期望的格式输出清理过的数据。
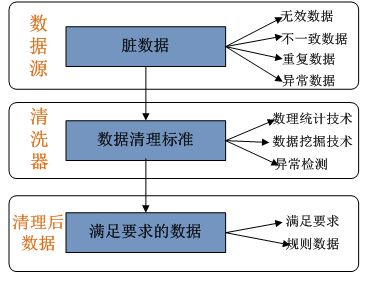
三、数据清洗的方法
数据清洗的方法包括:
-
处理缺失值;
-
删除重复项;
-
处理离群值;
-
格式和类型转换;
-
数据归一化;
-
数据集成;
-
数据转换;
-
数据简化。
以下分别对这8类方法进行介绍。
1. 处理缺失值
处理缺失值:指的是在数据分析过程中处理缺失值(即数据集中缺少的数据)的方法。常通过以下几种方式完成(选择哪种方法取决于缺少的数据量和手头的具体问题),包括:
删除:删除行/列中缺失的值
归纳:用统计数据(均值,中位数,模态)或预测(回归,kNN)填充缺失值
插值:根据其他样本的值估计缺失值
外推:根据趋势预测缺失值
匿名化:掩盖或扰乱缺失的值以保持隐私。
2.删除重复项
删除重复项:指的是识别并消除数据集中重复或冗余的条目。这是数据清理和预处理中的一个重要步骤,可以确保对唯一且准确的数据执行分析。重复可能是由于人为错误、数据输入错误或数据源中的不一致造成的。有几种方法可以删除重复项(方法的选择将取决于数据的具体要求和正在执行的分析),包括:
删除:删除所有重复的行
保留首行:保留重复行的首行数据,并删除其余的行
保留末行:保留重复行的末尾数据,并删除其余的行
自定义:定义一个自定义方法来确定要保留或删除哪些副本。
3.处理异常值
处理异常值:是指识别和处理数据集中与其余数据显著不同的极端值的过程。异常值可能会对数据分析的结果产生重大影响,如果处理不当,可能会使结果发生偏差。处理异常值有几种方法,包括:
移除:移除离群数据点
修剪:只保留指定百分比的数据,丢弃极端值
替换:用更接近其他数据点的指定值替换极端值
归纳:将异常值替换为统计值,例如平均值或中位数
转换:转换数据以减少异常值的影响,例如log-transformation。
方法的选择将取决于数据的具体要求和正在执行的分析。重要的是要考虑异常值对结果的潜在影响,并仔细选择适当的方法来处理它们。
4.格式和类型转换
格式和类型转换:是指将一种数据格式转换为另一种格式或数据类型的过程。例如,将字符串转换为数字,或将数字格式化为特定的字符串形式。
5.数据归一化
数据归一化:是指将数据标准化为具有相同量纲和相对大小关系的数据集。这有助于防止特定数据特征在模型中具有过多影响力,并且提高了模型的稳健性和准确性。常见的数据标准化方法包括Min-Max,Z-Score等。
6.数据集成
数据集成:是指将来自多个来源的数据组合到单个统一视图中的过程。目标是协调数据源之间的差异,消除冗余信息,并提供一致、准确的数据表示。这使组织能够更全面地了解他们的数据,并更好地将其用于决策和分析。
7.数据转换
数据转换:是指将数据从一种格式或结构转换为另一种格式或结构,以使其更适合分析或满足特定要求的过程。此过程涉及到将数据从源格式映射到目标格式,并且通常涉及到操作聚合或在该过程中过滤数据。数据转换的目标是确保数据的一致性、准确性和可用性,并且可以轻松地与其他数据源集成。
8.数据简化
数据简化:是指对数据进行简化或汇总,以减少数据的大小或复杂性,使其更易于管理、分析和可视化的过程。数据缩减的目标是保留最重要和最相关的信息,同时消除冗余或不相关的数据。这可以通过数据压缩、聚合或降维等技术来实现。通过减少数据的大小,组织可以缩短处理时间,使其更容易处理大型数据集。