目录
前言
题目详解
AC代码
结尾
前言
NOIP的第一题我终于终于过了!
还是很激动的,所以想把自己的思路和想法写下来供大家参考。
题目详解
首先还没看过题的小伙伴,请看题:
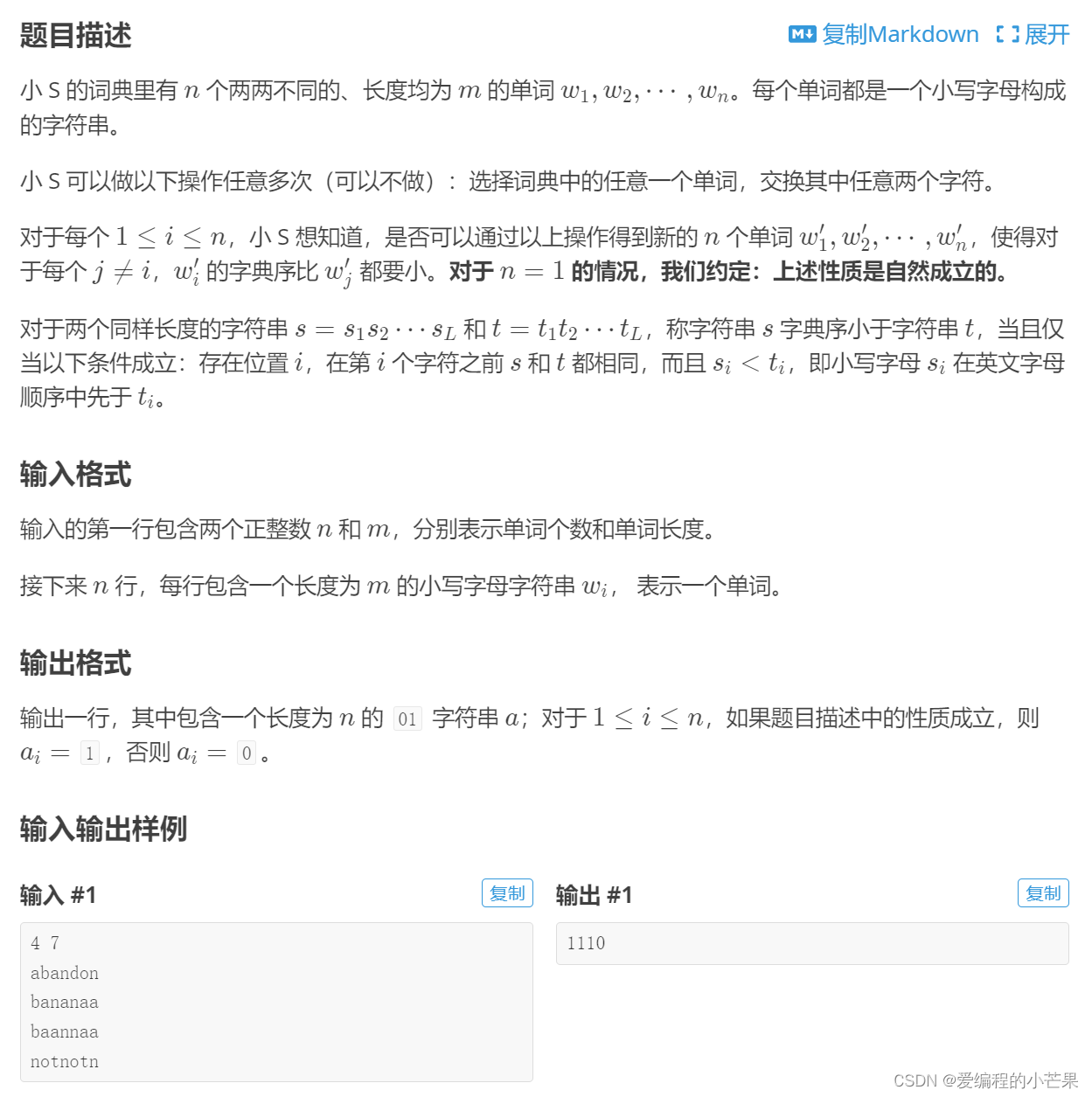
一道题拿来还是得先理解题目。而这道题简单来说就是能否通过若干次交换字母后,使得目标单词i的字典序最小。如果可能,输出1,否则输出0。
因为每个单词里的字母都可以任意交换若干次,其实相当于只要包含这几个字母,怎么排列都行。
比如我们对hello这个单词进行若干次交换:
helol
hleol
lheol
lhoel
lhleo
……
知道了这个性质,我们再仔细想想,要想目标单词i的字典序最小,那么其他单词的字典序就要尽可能的大。那我们直接预处理每个字符串的最小字典序和最大字典序,然后依次比较不就OK了吗?但是,仔细想想,时间不允许啊,如果按这种做法只能拿80分。
那是不是就没办法了呢?我们很容易想到的就是利用桶排序。怎么做呢?我们可以把每个单词里26个英文字母出现的次数,放入一个桶里,然后从前往后便利目标单词,从后往前便利对比单词,如果目标单词一但有比对比单词大的字母,直接输出0,break一下。比如下面的栗子:
目标单词:hello 对比单词:world
hello的桶: 0 0 0 0 1 0 0 1 0 0 0 2 0 0 1 0 0 0 0 0 0 0 0 0 0 0
world的桶: 0 0 0 1 0 0 0 0 0 0 0 1 0 0 1 0 0 1 0 0 0 0 1 0 0 0
hello从前往后的第一个为真的位置:第5个
wolrd从后往前的第一个为真的位置:第23个
因为5<23,所以可以完成,输出1。
哇塞!这种方法真的很巧妙,但是算一算复杂度,也只能拿90分,呜呜呜。
于是作者绞尽脑汁,想了半天,总算想到了一个AC解法。
因为要想目标单词的字典序尽量的小,那么目标单词中最小的一个字母必定排在最前面。
而要想对比单词的字典序尽量的大,那么对比单词中最大的一个字母必定排在最前面。
这样只需比较最前面的两个字母就OK了,两个字母不一样很好比较,难点就在于万一开头两个字母一样那该怎么办呢?
大家不要着急,静下心来仔细想想,因为目标单词是递增排列的,而对比单词是递减排列的。
我们假设第一个字母为X,那么目标单词的第二个字母一定是>=x,而对比单词的第二个字母一定是<=x。那么目标单词一定是大于对比单词的。这时就会有细心的同学问了,那如果一直等于x,不就没法比较了吗?那请你仔细读读题:

如果你还没有读懂,那请再读一遍: 现在明白了吧,那这题不就轻轻松松了吗?
现在明白了吧,那这题不就轻轻松松了吗?
AC代码
#include<bits/stdc++.h>
using namespace std;
int n,m,minn[3500],maxn[3500];
char s[3500];
int main()
{
cin>>n>>m;
for(int i=1;i<=n;i++)
{
scanf("%s",s);
minn[i]=maxn[i]=s[0]-'a';
for(int j=1;j<m;j++)
{
minn[i]=min(minn[i],s[j]-'a');
maxn[i]=max(maxn[i],s[j]-'a');
}
}
for(int i=1;i<=n;i++)
{
bool flag=1;
for(int j=1;j<=n;j++)
{
if(i!=j&&maxn[j]<=minn[i])
{
flag=0;
cout<<"0";
break;
}
}
if(flag) cout<<"1";
}
return 0;
} 结尾
这篇文章应该不能再详细了吧。哪里还没听懂,欢迎私信。
最后祝大家RP++!