目录
一、C++运行过程
1、C++编译过程
2、代码运行示例
单文件
多文件
a、编译所有cpp文件,但是不链接
b、链接所有的.o文件
c、运行程序
CMake编译
代码
使用方法
编译过程
代码运行
二、C++和cuda混合编程
cuda 单文件
cuda和C++多文件
手动分步编译
CMake编译
上一篇博客CUDA编程一、基本概念和cuda向量加法,介绍了GPU结构和cuda编程的一些基础知识,最后用cuda实现了向量加法。这一篇博客中主要是学习C++和cuda混合编程的一些知识点,一是C++代码执行的过程,二是C++和cuda混合编程的实现。
一、C++运行过程
一直以来都是写python这种解释性语言,中间偶尔写过go语言,并没有对代码运行过程进行深入的研究,主要原因是python解释器会自动的编译代码;go语言在Goland这个IDE上也有可视化的按钮直接编译,就忽视了其中的一些细节。在学习C++编程的过程中,对于多文件怎么运行起来很不顺手。因此很有必要对C++代码运行过程进行一个比较详细的梳理。
1、C++编译过程
和python解释性语言(运行过程中解释器逐行的把代码翻译为机器码)不同,C++语言代码需要在运行之前,自己手动的进行编译,完成代码到机器码转换的过程,得到最终可执行文件后,再执行代码实现逻辑。手动编译的过程中,主要是如下流程GCC Compilation Process:

如上图所示,整个流程分为4个步骤,针对一个cpp文件进行如下示意图过程:

预处理
对.cpp文件中的头文件、宏定义等做处理,展开这部分代码;清理注释;对条件编译做判定等。生成以.i文件
编译
把预处理的结果作为输入,生成和平台相关的汇编代码,输出.s文件,这是文本格式的。
汇编
就是汇编代码到机器码的过程,生成.o文件,这是一个二进制文件。
链接
将多个.o文件以及所需要的库文件还有.h文件链接到一起,形成最终的可执行文件。
2、代码运行示例
单文件
当一个C++程序比较简单,只有一个CPP文件的时候,直接使用g++ 对单个文件进行编译即可,具体代码,简单的hello world,single_main.cpp。
#include<iostream>
int main(){
std::cout<<"single_main hello world!"<<std::endl;
return 0;
}直接使用g++进行编译 一步到位
g++ single_main.cpp -o single_main -o 指定编译后的文件名
运行结果如下:

多文件
这个才是常见的场景,就拿我学习C++的class示例来说,项目结果如下:

具体代码,
person.h
#ifndef PERSON_H
#define PERSON_H
#include<iostream>
using namespace std;
class Person
{
private:
/* data */
public:
string name;
string ID;
int age;
string sex;
float height;
Person();
Person(string name, string ID, int age, string sex, float height);
~Person();
void showInfo();
void updateInfo(string name, string ID, int age, string sex, float height);
void speak(string sentence);
};
#endif定义了一个person类,类里定义了公有变量和构造函数、析构函数、成员函数。
person.cpp
#include"person.h"
Person::Person(){
std::cout<<"Person class object is being created by original class constructor without any paramters!"<<std::endl;
}
Person::Person(string name, string ID, int age, string sex, float height){
cout<<"Person class object is being created by original class constructor with paramters!"<<endl;
this->age = age;
this->height = height;
this->ID = ID;
this->name = name;
this->sex = sex;
}
Person::~Person(){
cout<<"Person 析构函数"<<endl;
}
void Person::showInfo(){
cout<<"I am a person!" <<endl;
cout<<"name:"<< this->name <<endl;
cout<<"ID:"<< this->ID <<endl;
cout<<"age:"<< this->age <<endl;
cout<<"sex:"<< this->sex <<endl;
cout<<"height:"<< this->height <<endl;
}
void Person::updateInfo(string name, string ID, int age, string sex, float height){
this->age = age;
this->height = height;
this->ID = ID;
this->name = name;
this->sex = sex;
}
void Person::speak(string sentence){
cout<<sentence<<endl;
}实现具体的函数逻辑
student.h
#ifndef STUDENT_H
#define STUDENT_H
#include<iostream>
# include"person.h"
using namespace std;
class Student:public Person
{
private:
/* data */
string address;
string levlel;
public:
Student();
Student(string name, string ID, int age, string sex, float height, string address, string levlel);
~Student();
void showInfo();
void updateInfo(string name, string ID, int age, string sex, float height, string address, string levlel);
};
#endifStudent类继承Person类
student.cpp
#include <iostream>
#include"student.h"
Student::Student(){
std::cout<<"class object is being created by original class constructor without any paramters!"<<std::endl;
}
Student::Student(string name, string ID, int age, string sex, float height, string address, string levlel){
cout<<"class object is being created by original class constructor with paramters!"<<endl;
this->address = address;
this->age = age;
this->height = height;
this->ID = ID;
this->name = name;
this->sex = sex;
this->levlel = levlel;
}
Student::~Student(){
cout<<"student 析构函数"<<endl;
}
void Student::updateInfo(string name, string ID, int age, string sex, float height, string address, string levlel){
this->address = address;
this->age = age;
this->height = height;
this->ID = ID;
this->name = name;
this->sex = sex;
this->levlel = levlel;
}
void Student::showInfo(){
cout<<"I am a student and also a student!" <<endl;
cout<<"name:"<< this->name <<endl;
cout<<"ID:"<< this->ID <<endl;
cout<<"age:"<< this->age <<endl;
cout<<"sex:"<< this->sex <<endl;
cout<<"height:"<< this->height <<endl;
cout<<"address:"<< this->address <<endl;
cout<<"levlel:"<< this->levlel <<endl;
}成员函数进行重写
main.cpp
#include "person.h"
#include "student.h"
int main(void){
string name = "黄洋";
string ID = "0001";
int age = 1;
string sex = "男";
float height = 172.5;
Person *person = new Person(name, ID, age, sex, height);
person->showInfo();
person->speak("哈哈哈我会说话,我是黄洋!");
string address = "湖北省武汉市洪山区";
string level = "Level_0";
cout<<address<<endl;
Student * stu = new Student(name, ID, age, sex, height, address, level);
stu->showInfo();
height = 188.6;
level = "Level_1";
stu->updateInfo(name, ID, age, sex, height, address, level);
stu->showInfo();
stu->speak("我是学生,我也会说话!");
delete person;
delete stu;
return 0;
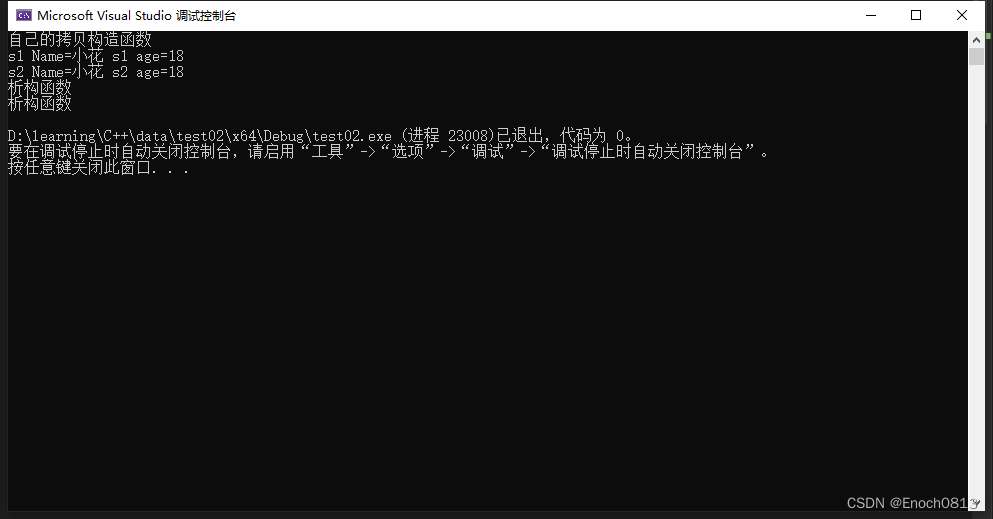
}调用这两个类完成任务。
编译的时候,就需要把所有的cpp都编译好,然后再链接在一起。
a、编译所有cpp文件,但是不链接
g++ main.cpp -c main.o 使用-c参数来进行编译
编译后得到3个.o文件,如下图

b、链接所有的.o文件
g++ main.o person.o student.o -o main
结果如下:

c、运行程序
./main
结果如下:

CMake编译
当然在开发C++项目的时候,不可避免有很多CPP文件,我们不可能一个一个的手动编译,可以使用cmake来生成makefile,然后使用make自动编译,这里就不做更多的说明了,给个示例
代码
cmake_minimum_required(VERSION 3.9)
project(class_study VERSION 1.0)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_CXX_STANDARD_REQUIRED True)
set(EXECUTABLE_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/bin)
aux_source_directory(. src_list)
add_executable(${PROJECT_NAME} ${src_list})使用方法
1、mkdir build
2、cd ./build
3、 cmake .. 得到makefile makefile在build目录中
4、make 编译得到最终可执行文件在./bin目录下编译过程

代码运行

和上述结果一模一样!
二、C++和cuda混合编程
C++和cuda一般都是混合在一起的,cuda代码.cu文件必须使用nvcc编译器来编译,C++的.cpp则必须使用g++等编译器来编译,混合的时候就需要手动的进行混合编译。
cuda 单文件
这个比较简单,C++代码和cuda代码全部写在一个.cu文件直接使用nvcc来编译就好了。引用CUDA编程一、基本概念和cuda向量加法中的向量加法示例来说明nvcc_vector_add.cu:
#include<stdio.h>
#include<assert.h>
#include<cstdio>
#include<sys/time.h>
#include<iostream>
// 编译加链接
// nvcc -o nvcc_vector_add.cu nvcc_vector_add.o
// 直接运行即可
// 向量加法核函数
__global__ void addVectorskernel(float *result, float *a, float *b, int N){
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for (int i=index; i<N; i+=stride){
result[i] = a[i] + b[i]; // 元素a[i] + 元素 b[i]
}
}
// 初始化数组 a
void initWith(float num, float *a, int N) {
for(int i = 0; i < N; ++i) {
a[i] = num;
}
};
int main(){
const int N = 102400000;
const int M = 10;
size_t Mem = N * sizeof(float);
float *a;
float *b;
float *c;
cudaMallocManaged(&a, Mem);
cudaMallocManaged(&b, Mem);
cudaMallocManaged(&c, Mem);
initWith(3.0, a, N); // 将数组a中所有的元素初始化为3
initWith(4.0, b, N); // 将数组b中所有的元素初始化为4
initWith(0.0, c, N); // 将数组c中所有的元素初始化为0,数组c是结果向量
for(int i=0;i<M;i++){
printf("%f ",a[i]);
}
printf("\n");
printf("******************\n");
for(int i=0;i<M;i++){
printf("%f ",b[i]);
}
printf("\n");
printf("******************\n");
for(int i=0;i<M;i++){
printf("%f ",c[i]);
}
printf("\n");
printf("******************\n");
// 配置参数
size_t threadsPerBlock = 512;
// size_t numberOfBlocks = (N + threadsPerBlock - 1) / threadsPerBlock;
// numberOfBlocks 不小于GPU的SM梳理 4090有128个SM
size_t numberOfBlocks = 10;
struct timeval start;
struct timeval end;
gettimeofday(&start,NULL);
addVectorskernel <<< numberOfBlocks, threadsPerBlock >>> (c, a, b, N); // 执行核函数
cudaDeviceSynchronize(); // 同步,且检查执行期间发生的错误
gettimeofday(&end,NULL);
float time_use;
time_use=(end.tv_sec-start.tv_sec)*1000000+(end.tv_usec-start.tv_usec);//微秒
std::cout <<"vector_add gpu time cost is "<<time_use/1000/100<< " ms"<< std::endl;
for(int i=0;i<M;i++){
printf("%f ",a[i]);
}
printf("\n");
printf("******************\n");
for(int i=0;i<M;i++){
printf("%f ",b[i]);
}
printf("\n");
printf("******************\n");
for(int i=0;i<M;i++){
printf("%f ",c[i]);
}
printf("\n");
printf("******************\n");
return 0;
}核函数以及核函数的调用逻辑都写在一个.cu文件里面,直接使用nvcc编译
//编译和链接
nvcc nvcc_vector_add.cu -o nvcc_vector_add
//运行
./nvcc_vector_add运行结果

cuda和C++多文件
一般大型一点的项目都会是多个文件的,.cu、.cuh和.cpp多个类型多个文件。这里我们人向量加法为例:
vector_add.cu文件实现核函数和核函数的调用函数(C++和cuda代码混合)
#include<stdio.h>
#include<assert.h>
#include<cstdio>
#include"vector_add.cuh"
// 向量加法核函数
__global__ void addVectorskernel(float *result, float *a, float *b, int N){
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i=index; i<N; i+=stride){
result[i] = a[i] + b[i]; // 元素a[i] + 元素 b[i]
}
}
void addVectors(float *result, float *a, float *b, int N, size_t Mem){
float *dev_a, *dev_b, *dev_c;
//分类GPU内存
cudaMalloc(&dev_a, Mem);
cudaMalloc(&dev_b, Mem);
cudaMalloc(&dev_c, Mem);
//将数据传给GPU
cudaMemcpy(dev_a, a, Mem, cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, Mem, cudaMemcpyHostToDevice);
addVectorskernel <<< 256, 1024 >>> (dev_c, dev_a, dev_b, N); // 执行核函数
// 计算结果GPU到cpu
cudaMemcpy(result, dev_c, Mem, cudaMemcpyDeviceToHost);
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
}addVectors该调用函数需要在vector_add.cuh中给出函数声明,同时还要使用extern "C"关键字,这样纯C++代码中就能调用addVectors函数,进而调用cuda核函数,进行向量加法运算。
#ifdef __cplusplus
extern "C" {
#endif
void addVectors(float *result, float *a, float *b, int N, size_t Mem);
#ifdef __cplusplus
}
#endif最后就是vector_add_gpu.cpp执行整个逻辑调用
#include<stdio.h>
#include<assert.h>
#include<cstdio>
#include<iostream>
#include"vector_add.cuh"
#include<sys/time.h>
// 混合编译步骤 -c不链接仅仅编译
// 1、nvcc -c vector_add.cu ——得到vector_add.o
// 2、g++ -c vector_add_gpu.cpp ——得到vector_add_gpu.o
// 3、链接lcudart
// g++ vector_add_main vector_add_gpu.o vector_add.o -lcudart -L/usr/local/cuda-11.2/lib64
void initWith(float num, float *a, int N);
int main(){
struct timeval start;
struct timeval end;
gettimeofday(&start,NULL);
for (int i = 0;i < 100; i++){
const int N = 10000000;
size_t Mem = N * sizeof(float);
float *a = new float[N];
float *b = new float[N];
float *c = new float[N];
initWith(3.0, a, N); // 将数组a中所有的元素初始化为3
initWith(4.0, b, N); // 将数组b中所有的元素初始化为4
initWith(0.0, c, N); // 将数组c中所有的元素初始化为0,数组c是结果向量
// 计算
addVectors(c, a, b, N, Mem);
if (i==99){
printf("%f \n",c[0]);
}
}
gettimeofday(&end,NULL);
float time_use;
time_use=(end.tv_sec-start.tv_sec)*1000000+(end.tv_usec-start.tv_usec);//微秒
std::cout <<"vector_add gpu time cost is "<<time_use/1000/100<< " ms"<< std::endl;
return 0;
}
// 初始化数组 a
void initWith(float num, float *a, int N) {
for(int i = 0; i < N; ++i) {
a[i] = num;
}
};
手动分步编译
// 混合编译步骤 -c不链接仅仅编译
// 1、nvcc -c vector_add.cu ——得到vector_add.o
// 2、g++ -c vector_add_gpu.cpp ——得到vector_add_gpu.o
// 3、链接cuda cudart
// g++ vector_add_gpu.o vector_add.o -lcudart -L/usr/local/cuda-11.8/lib64 -o vector_add_main编译过程和代码运行结果

CMake编译
当文件数多了以后,手动分步分文件编译,显然是个麻烦事儿不可靠,同样得使用cmake来编译,和上文cpp的cmake编译时CMakeList的语法有一点点差异,CMakeLists.txt代码如下:
cmake_minimum_required(VERSION 3.9)#Cmake最低版本
#project(demo LANGUAGES CXX CUDA) #这个写法也是可以的
project(demo)
enable_language(CUDA)#激活CUDA语言支持,使用第一个写法时要进行注释
#设置语言标准
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_CUDA_STANDARD 11)
set(EXECUTABLE_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/bin)#设置编译后的程序存放位置
aux_source_directory(. SRC_LIST)#添加当前目录下的所有源文件
#编译列表
add_executable(${PROJECT_NAME} ${SRC_LIST})编译过程和运行结果如下图:

编译过程完全自动化,不用自己手动的去分步编译。

和上述手动分步编译后,运行结果一样,耗时差不多。
参考文章
C/C++程序编译过程为什么要分为四个步骤?
详解C/C++代码的预处理、编译、汇编、链接全过程