文章目录
- Java集合
- 1.2 流程图关系
- 1.3 底层实现
- 1.4 集合与数组的区别
- 1.4.1 元素类型
- 1.4.2 元素个数
- 1.5 集合的好处
- 1.6 List集合我们以ArrayList集合为例
- 1.7 迭代器的常用方法
- 1.8 ArrayList、LinkedList和Vector的区别
- 1.8.1 说出ArrayList,Vector, LinkedList的存储性能和特性
- 1.8.2 多线程场景下如何使用 ArrayList?
- 1.8.3 为什么 ArrayList 的 elementData 加上 transient 修饰?
- 1.9 Set集合的特点:
- 1.9.1 说一下 HashSet 的实现原理?
- 1.9.2 HashSet如何检查重复?HashSet是如何保证数据不可重复的?
- 1.10 TreeSet对元素进行排序的方式:
- 1.11 List,Set,Map集合的特点 & 区别
- 1.12 HashMap和Hashtable的区别
- 1.3 HashSet 与 HashMap的区别
Java集合
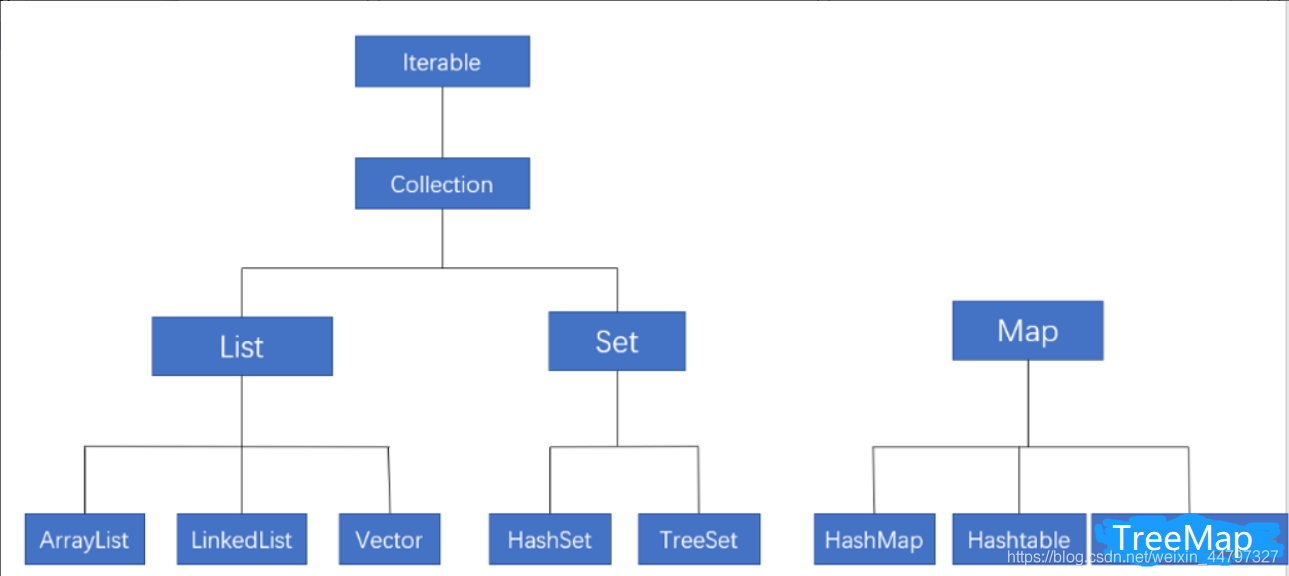
1.2 流程图关系
1.3 底层实现
ArrayList:底层是数组 ,默认长度为0,调用add以后看情况,不指定长度默认长度为10
ArrayList的扩容机制_arraylist扩容-CSDN博客
LinkedList:底层是链表
Vector:底层是数组
HashSet:底层是哈希表
TreeSet:红黑树
HashMap:数组+链表
Hashtable:数组+链表
LinkedHashMap:数组+链表+红黑树
1.4 集合与数组的区别
1.4.1 元素类型
集合:引用类型(存储基本类型是自动装箱)
数组:基本类型、引用类型
1.4.2 元素个数
集合:不固定、可任意扩展
数组:固定,不能改变容量
1.5 集合的好处
不受容器大小限制,可以随时添加、删除元素,提供了大量操作元素的方法(判断、获取等)
List集合
List集合的特点:
可重复性(可以添加相同的元素)、有序(存取顺序相同)
List的主要方法有:
add、get、remove、set、iterator、contains、addAll、removeAll、indexOf、toArray、clear、isEmpty
1.6 List集合我们以ArrayList集合为例
ArrayList集合
java.util.ArrayList是大小可变的数组的实现,存储在内的数据称为元素。此类提供一些方法来操作内部存储的元素。ArrayList中可以不断添加元素,其大小也自动增长。
java.util.ArrayList集合数据存储的结构是数组结构。元素增删慢,查找快,由于日常开发中使用最多的功能为查询数据、遍历数据,所以ArrayList集合是最常用的集合。
泛型:即泛指任意类型,幼教参数化类型,对具体类型的使用起到辅助作用,类似于方法的参数
1.7 迭代器的常用方法
next():返回迭代的下一个元素
hasNext():如果仍有元素可以迭代,则返回true
注意:列表迭代器是List体系独有的遍历方式,可以在对集合遍历的同时进行添加、删除等操作
但是必须通过调用列表迭代器的方法来实现
1.8 ArrayList、LinkedList和Vector的区别
-
线程同步,Vector线程安全,ArrayList线程不安全,因为Vector的实现有synchronized锁
-
效率问题,Vector效率低,ArrayList效率高
-
增长数量,Vector以2倍增长,ArrayList以1.5倍增长
1.8.1 说出ArrayList,Vector, LinkedList的存储性能和特性
(1) ArrayList和Vector使用数组存储元素;LinkedList使用链表存储元素
(2) ArrayList和Vector插入删除数据时,需要搬运数据,效率较差;LinkedList使用链表,不需要搬运数据,效率高。
(3) ArrayList和Vectory查询时,按数组下标查询,不需要遍历,效率高;LinkedList需要遍历,查询效率底。
1.8.2 多线程场景下如何使用 ArrayList?
ArrayList 不是线程安全的,如果遇到多线程场景,可以通过 Collections 的 synchronizedList 方法将其转换成线程安全的容器后再使用。例如像下面这样:
List<String> synchronizedList = Collections.synchronizedList(list);
synchronizedList.add("aaa");
synchronizedList.add("bbb");
for (int i = 0; i < synchronizedList.size(); i++) {
System.out.println(synchronizedList.get(i));
}
1.8.3 为什么 ArrayList 的 elementData 加上 transient 修饰?
ArrayList 中的数组定义如下:
private transient Object[] elementData;
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
可以看到 ArrayList 实现了 Serializable 接口,这意味着 ArrayList 支持序列化。transient 的作用是说不希望 elementData 数组被序列化,重写了 writeObject 实现:
private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException{
*// Write out element count, and any hidden stuff*
int expectedModCount = modCount;
s.defaultWriteObject();
*// Write out array length*
s.writeInt(elementData.length);
*// Write out all elements in the proper order.*
for (int i=0; i<size; i++)
s.writeObject(elementData[i]);
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
每次序列化时,先调用 defaultWriteObject() 方法序列化 ArrayList 中的非 transient 元素,然后遍历 elementData,只序列化已存入的元素,这样既加快了序列化的速度,又减小了序列化之后的文件大小。
1.9 Set集合的特点:
不可重复(元素具有唯一性)、无序(元素的存取顺序是不固定的)
Set的主要方法有:
add、remove、iterator、contains、addAll、removeAll、toArray、clear、isEmpty
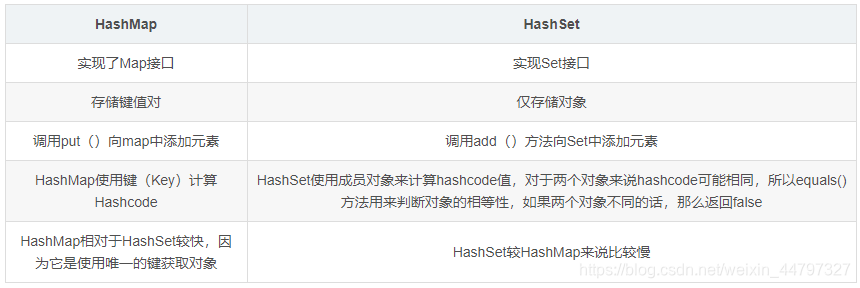
HashSet:内部的数据结构是哈希表,是线程不安全的。
HashSet中保证集合中元素是唯一的方法:通过对象的hashCode和equals方法来完成对象唯一性的判断。
如果对象的hashCode值不同,则不用判断equals方法,就直接存到HashSet中。
如果对象的hashCode值相同,需要用equals方法进行比较,如果结果为true,则视为相同元素,不存,如果结果为false,视为不同元素,进行存储。
注意:如果元素要存储到HashCode中,必须覆盖hashCode方法和equals方法。
TreeSet:可以对Set集合中的元素进行排序,是线程不安全的。
**TreeSet:**中判断元素唯一性的方法是:根据比较方法的返回结果是否为0,如果是0,则是相同元素,不存,如果不是0,则是不同元素,存储。
1.9.1 说一下 HashSet 的实现原理?
HashSet 是基于 HashMap 实现的,HashSet的值存放于HashMap的key上,HashMap的value统一为PRESENT,因此 HashSet 的实现比较简单,相关 HashSet 的操作,基本上都是直接调用底层 HashMap 的相关方法来完成,HashSet 不允许重复的值。
1.9.2 HashSet如何检查重复?HashSet是如何保证数据不可重复的?
向HashSet 中add ()元素时,判断元素是否存在的依据,不仅要比较hash值,同时还要结合equles 方法比较。
HashSet 中的add ()方法会使用HashMap 的put()方法。
HashMap 的 key 是唯一的,由源码可以看出 HashSet 添加进去的值就是作为HashMap 的key,并且在HashMap中如果K/V相同时,会用新的V覆盖掉旧的V,然后返回旧的V。所以不会重复( HashMap 比较key是否相等是先比较hashcode 再比较equals )。
以下是HashSet 部分源码:
private static final Object PRESENT = new Object();
private transient HashMap<E,Object> map;
public HashSet() {
map = new HashMap<>();
}
public boolean add(E e) {
// 调用HashMap的put方法,PRESENT是一个至始至终都相同的虚值
return map.put(e, PRESENT)==null;
}
1.10 TreeSet对元素进行排序的方式:
元素自身具备比较功能,即自然排序,需要实现Comparable接口,并覆盖其compareTo方法。
元素自身不具备比较功能,则需要实现Comparator接口,并覆盖其compare方法。
注意:LinkedHashSet是一种有序的Set集合,即其元素的存入和输出的顺序是相同的。
1.11 List,Set,Map集合的特点 & 区别
List、Set、Map 是否继承自 Collection 接口?List、Map、Set 三个接口存取元素时,各有什么特点?
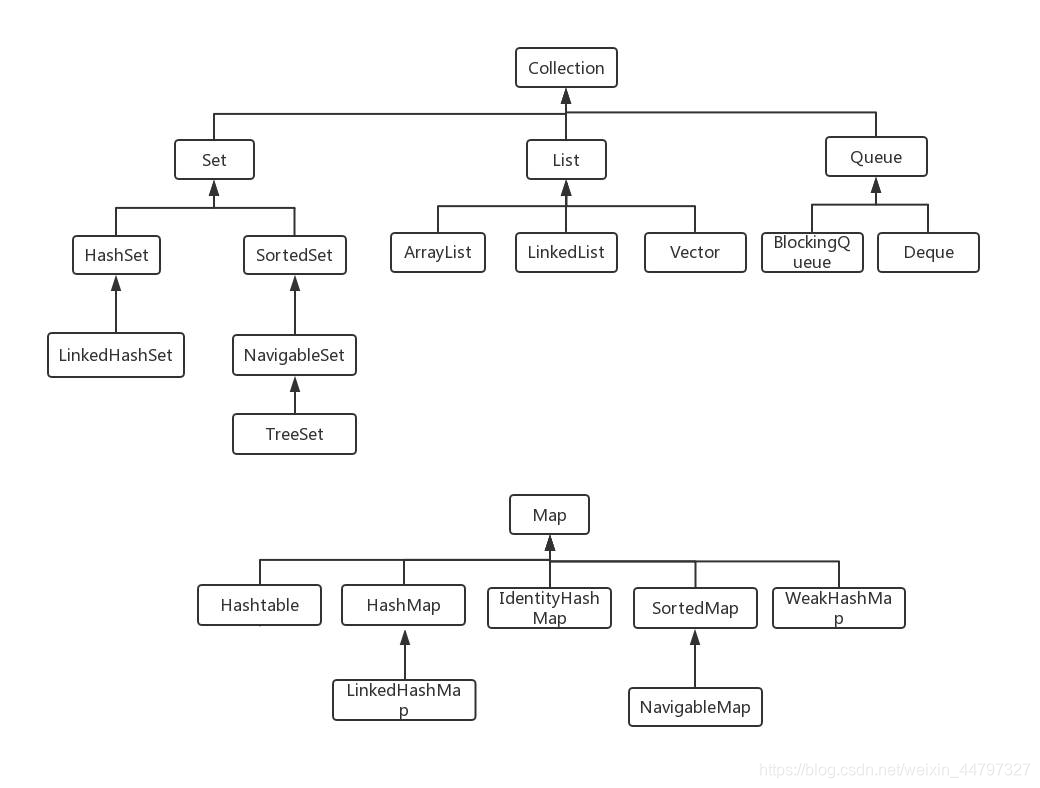
Java 容器分为 Collection 和 Map 两大类,Collection集合的子接口有Set、List、Queue三种子接口。我们比较常用的是Set、List,Map接口不是collection的子接口。
Collection集合主要有List和Set两大接口
List:一个有序(元素存入集合的顺序和取出的顺序一致)容器,元素可以重复,可以插入多个null元素,元素都有索引。常用的实现类有 ArrayList、LinkedList 和 Vector。
Set:一个无序(存入和取出顺序有可能不一致)容器,不可以存储重复元素,只允许存入一个null元素,必须保证元素唯一性。Set 接口常用实现类是 HashSet、LinkedHashSet 以及 TreeSet。
Map是一个键值对集合,存储键、值和之间的映射。 Key无序,唯一;value 不要求有序,允许重复。Map没有继承于Collection接口,从Map集合中检索元素时,只要给出键KEY对象,就会返回对应的值对象。
Map 的常用实现类:HashMap、TreeMap、HashTable、LinkedHashMap、ConcurrentHashMap
关系图如下:
1.12 HashMap和Hashtable的区别
-
线程同步,Hashtable线程安全,HashMap线程不安全
-
效率问题,Hashtable效率低,HashMap效率高
-
HashMap可以使用null作为key,Hashtable不可以使用null为key
-
HashMap使用的是新实现,继承AbstractMap,而Hashtable是继承Dictionary类,实现比较老
-
Hash算法不同,HashMap的hash算法比Hashtable的hash算法效率高
-
HashMap把Hashtable的contains方法去掉了,改成containsValue和containsKey。因为contains方法容易让人引起误解。
-
取值不同,HashMap用的是Iterator接口,而Hashtable中还有使用Enumeration接口
1.3 HashSet 与 HashMap的区别