引言
SRGAN是第一个将GAN用在图像超分辨率上的模型。在这之前,超分辨率常用的损失是L1、L2这种像素损失,这使得模型倾向于学习到平均的结果,也就是给低分辨率图像增加“模糊的细节”。SRGAN引入GAN来解决这个问题。GAN可以生成“真实”的图像, 那么当“真实的图像”是清晰的图像时,也意味着GAN可以生成清晰的图像。但是,如果只用GAN损失,没有其他约束,并不能生成与低分辨率图像对应的高分辨率图像。所以,将像素损失和对抗损失相结合。此外,SRGAN还使用了感知损失,计算图像在特征空间的损失。
准备
import numpy as np
import matplotlib.pyplot as plt
import os
from PIL import Image
import paddle
import paddle as P
import paddle.nn as nn
import paddle.nn.functional as F
from paddle import ParamAttr
from paddle.nn import Conv2D, BatchNorm, Linear, Dropout, AdaptiveAvgPool2D, MaxPool2D, AvgPool2D
nn.initializer.set_global_initializer(nn.initializer.Normal(mean=0.0,std=0.01), nn.initializer.Constant())加载数据
使用CelebA数据集,实现人脸图像超分辨率。
为了不OOM,切块大小为44×44(而且CelebA也只能切这么大了),与原文96×96不同。
SCALE = 4
PATH = '/path/to/data/celeba/img_align_celeba/'
DIRS = os.listdir(PATH)
PATCH_SIZE = [44, 44, 3]
def reader_patch(batchsize,scale=SCALE,patchsize=PATCH_SIZE):
np.random.shuffle(DIRS)
for filename in DIRS:
LRs = np.zeros((batchsize,patchsize[2],patchsize[0],patchsize[1])).astype("float32")
HRs = np.zeros((batchsize,patchsize[2],patchsize[0]*scale,patchsize[1]*scale)).astype("float32")
image = Image.open(PATH+filename)
sz = image.size
sz_row = sz[1]//(patchsize[0]*scale)*patchsize[0]*scale
diff_row = sz[1] - sz_row
sz_col = sz[0]//(patchsize[1]*scale)*patchsize[1]*scale
diff_col = sz[0] - sz_col
row_min = np.random.randint(diff_row+1)
col_min = np.random.randint(diff_col+1)
HR = image.crop((col_min,row_min,col_min+sz_col,row_min+sz_row))
LR = HR.resize((sz[0]//(patchsize[1]*scale)*patchsize[1],sz[1]//(patchsize[0]*scale)*patchsize[0]), Image.BICUBIC)
LR = np.array(LR).astype("float32") / 255 * 2 - 1
HR = np.array(HR).astype("float32") / 255 * 2 - 1
for batch in range(batchsize):
rowMin, colMin = np.random.randint(0,LR.shape[0]-patchsize[0]+1), np.random.randint(0,LR.shape[1]-patchsize[1]+1)
LRs[batch,:,:,:] = LR[rowMin:rowMin+patchsize[0], colMin:colMin+patchsize[1],:].transpose([2,0,1])
HRs[batch,:,:,:] = HR[scale*rowMin:scale*(rowMin+patchsize[0]), scale*colMin:scale*(colMin+patchsize[1])].transpose([2,0,1])
yield LRs, HRs
def data_augmentation(LR, HR): #数据增强:随机翻转、旋转
if np.random.randint(2) == 1:
LR = LR[:,:,:,::-1]
HR = HR[:,:,:,::-1]
n = np.random.randint(4)
if n == 1:
LR = LR[:,:,::-1,:].transpose([0,1,3,2])
HR = HR[:,:,::-1,:].transpose([0,1,3,2])
if n == 2:
LR = LR[:,:,::-1,::-1]
HR = HR[:,:,::-1,::-1]
if n == 3:
LR = LR[:,:,:,::-1].transpose([0,1,3,2])
HR = HR[:,:,:,::-1].transpose([0,1,3,2])
return LR, HR
data = reader_patch(1)
for i in range(2):
LR, HR = next(data)
LR = LR.transpose([2,3,1,0]).reshape(PATCH_SIZE[0],PATCH_SIZE[1],PATCH_SIZE[2])
LR = Image.fromarray(np.uint8((LR+1)/2*255))
HR = HR.transpose([2,3,1,0]).reshape(PATCH_SIZE[0]*SCALE,PATCH_SIZE[1]*SCALE,PATCH_SIZE[2])
HR = Image.fromarray(np.uint8((HR+1)/2*255))
plt.subplot(1,2,1), plt.imshow(LR),plt.title('LRx'+str(SCALE))
plt.subplot(1,2,2), plt.imshow(HR),plt.title('HR')
plt.show()

网络结构
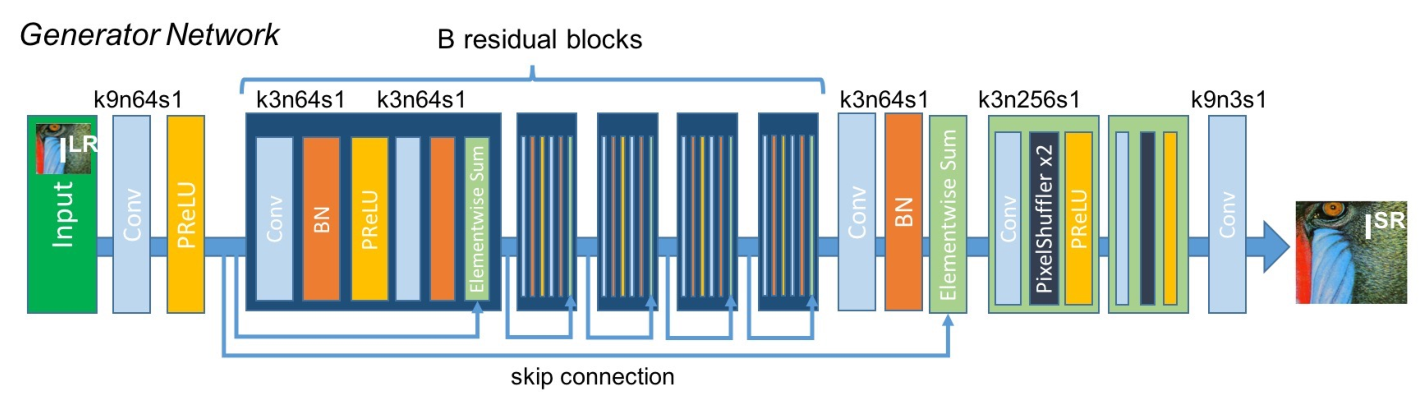
生成器整体结构:
这是一个残差网络,名为SRResNet。首先用一个卷积提取浅层特征,然后经过一个残差层提取深层特征,最后是一个上采样层重建出高分辨率图像。
其中残差层包括16个残差块、一个卷积和跳级连接。
上采样层有两个上采样块和一个卷积。
除了第一个卷积和上采样层中的卷积,每个卷积后面都有BN(其实,BN在SR中没有效果甚至略差,SR输入和输出有相似的空间分布,而BN白化中间的特征的方式完全破坏了原始空间的表征,因此需要部分参数来恢复这种表征,所以同样多的参数,有BN的还要拿出一部分参数做恢复,效果就差了点)。
激活函数都为PReLU,由于我不知道怎么实现PReLU,所以用ReLU代替。。。
class G(nn.Layer): # 生成器SRResNet
def __init__(self, channel=64, num_rb=16):
super(G, self).__init__()
self.conv1 = nn.Conv2D(3, channel, 9, 1, 4)
# self.prelu = nn.PReLU('all')
self.prelu = nn.ReLU()
self.rb_list = []
for i in range(num_rb):
self.rb_list += [self.add_sublayer('rb_%d' % i, RB(channel))]
self.conv2 = nn.Conv2D(channel, channel, 3, 1, 1)
self.bn = nn.BatchNorm2D(channel)
self.us1 = US(channel, channel*4)
self.us2 = US(channel, channel*4)
self.conv3 = nn.Conv2D(channel, 3, 9, 1, 4)
def forward(self, x):
x = self.conv1(x)
x = self.prelu(x)
y = x
for rb in self.rb_list:
y = rb(y)
y = self.conv2(y)
y = self.bn(y)
y = x + y
y = self.us1(y)
y = self.us2(y)
y = self.conv3(y)
return y残差块:
这是一个经典的残差块:conv、bn、relu(prelu)、conv、bn加跳过连接。
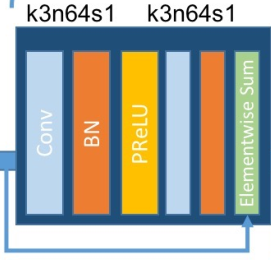
class RB(nn.Layer): # 残差块
def __init__(self, channel=64):
super(RB, self).__init__()
self.conv1 = nn.Conv2D(channel, channel, 3, 1, 1)
self.bn1 = nn.BatchNorm2D(channel)
# self.prelu = nn.PReLU('all')
self.prelu = nn.ReLU()
self.conv2 = nn.Conv2D(channel, channel, 3, 1, 1)
self.bn2 = nn.BatchNorm2D(channel)
def forward(self, x):
y = self.conv1(x)
y = self.bn1(y)
y = self.prelu(y)
y = self.conv2(y)
y = self.bn2(y)
return x + y上采样块:
包括conv、upscale_factor为2的pixelshuffle和prelu。
网络里用了两个上采样块,所以总的upscale_factor为4。

class US(nn.Layer): # 上采样块
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1):
super(US, self).__init__()
self.conv = nn.Conv2D(in_channels, out_channels, kernel_size, stride, padding)
self.ps = nn.PixelShuffle (2)
# self.prelu = nn.PReLU('all')
self.prelu = nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.ps(x)
x = self.prelu(x)
return x判别器整体结构:
这是一个经典的结构,包括一系列的conv-bn-leakyrelu和两个全连接。
第一个conv后没有bn;除了最后的激活函数为sigmoid,其他都为leakyrelu。
由于有全连接的存在,不同的输入尺寸会有不同的全连接参数数量,这里的参数数量与论文中不同。

class D(nn.Layer): # 判别器
def __init__(self, channel=64):
super(D, self).__init__()
self.layer_list = []
self.layer_list += [self.add_sublayer('conv', nn.Conv2D(3, channel, 3, 1, 1))]
self.layer_list += [self.add_sublayer('lrelu1', nn.LeakyReLU())]
self.layer_list += [self.add_sublayer('cna1', CNA(channel, channel, 3, 2, [1,0,1,0]))]
self.layer_list += [self.add_sublayer('cna2', CNA(channel, channel*2))]
self.layer_list += [self.add_sublayer('cna3', CNA(channel*2, channel*2, 3, 2, [1,0,1,0]))]
self.layer_list += [self.add_sublayer('cna4', CNA(channel*2, channel*4))]
self.layer_list += [self.add_sublayer('cna5', CNA(channel*4, channel*4, 3, 2, [1,0,1,0]))]
self.layer_list += [self.add_sublayer('cna6', CNA(channel*4, channel*8))]
self.layer_list += [self.add_sublayer('cna7', CNA(channel*8, channel*8, 3, 2, [1,0,1,0]))]
self.layer_list += [self.add_sublayer('flatten', nn.Flatten(start_axis=1, stop_axis=3))]
self.layer_list += [self.add_sublayer('fc1', nn.Linear(PATCH_SIZE[0]*4//16*PATCH_SIZE[1]*4//16*channel*8, channel*16))]
self.layer_list += [self.add_sublayer('lrelu2', nn.LeakyReLU())]
self.layer_list += [self.add_sublayer('fc1', nn.Linear(channel*16, 1))]
self.layer_list += [self.add_sublayer('sigmoid', nn.Sigmoid())]
def forward(self, x):
for layer in self.layer_list:
x = layer(x)
return xconv + norm + act:

class CNA(nn.Layer): # conv-norm-act
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1):
super(CNA, self).__init__()
self.conv = nn.Conv2D(in_channels, out_channels, kernel_size, stride, padding)
self.bn = nn.BatchNorm(out_channels)
self.lrelu = nn.LeakyReLU()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.lrelu(x)
return x预训练网络VGG19。
代码链接:
https://github.com/PaddlePaddle/PaddleClas/blob/dygraph/ppcls/modeling/architectures/vgg.py
参数下载链接:
https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/VGG19_pretrained.pdparams
这里使用conv5_4后激活层的输出。
class ConvBlock(nn.Layer):
def __init__(self, input_channels, output_channels, groups, name=None):
super(ConvBlock, self).__init__()
self.groups = groups
self._conv_1 = Conv2D(
in_channels=input_channels,
out_channels=output_channels,
kernel_size=3,
stride=1,
padding=1,
weight_attr=ParamAttr(name=name + "1_weights"),
bias_attr=False)
if groups == 2 or groups == 3 or groups == 4:
self._conv_2 = Conv2D(
in_channels=output_channels,
out_channels=output_channels,
kernel_size=3,
stride=1,
padding=1,
weight_attr=ParamAttr(name=name + "2_weights"),
bias_attr=False)
if groups == 3 or groups == 4:
self._conv_3 = Conv2D(
in_channels=output_channels,
out_channels=output_channels,
kernel_size=3,
stride=1,
padding=1,
weight_attr=ParamAttr(name=name + "3_weights"),
bias_attr=False)
if groups == 4:
self._conv_4 = Conv2D(
in_channels=output_channels,
out_channels=output_channels,
kernel_size=3,
stride=1,
padding=1,
weight_attr=ParamAttr(name=name + "4_weights"),
bias_attr=False)
self._pool = MaxPool2D(kernel_size=2, stride=2, padding=0)
def forward(self, inputs):
x = self._conv_1(inputs)
x = F.relu(x)
if self.groups == 2 or self.groups == 3 or self.groups == 4:
x = self._conv_2(x)
x = F.relu(x)
if self.groups == 3 or self.groups == 4:
x = self._conv_3(x)
x = F.relu(x)
if self.groups == 4:
x = self._conv_4(x)
x = F.relu(x)
y = x
x = self._pool(x)
return x, y
class VGGNet(nn.Layer):
def __init__(self):
super(VGGNet, self).__init__()
self.groups = [2, 2, 4, 4, 4]
self._conv_block_1 = ConvBlock(3, 64, self.groups[0], name="conv1_")
self._conv_block_2 = ConvBlock(64, 128, self.groups[1], name="conv2_")
self._conv_block_3 = ConvBlock(128, 256, self.groups[2], name="conv3_")
self._conv_block_4 = ConvBlock(256, 512, self.groups[3], name="conv4_")
self._conv_block_5 = ConvBlock(512, 512, self.groups[4], name="conv5_")
def forward(self, inputs):
x, y = self._conv_block_1(inputs)
x, y = self._conv_block_2(x)
x, y = self._conv_block_3(x)
x, y = self._conv_block_4(x)
_, y = self._conv_block_5(x)
return yvgg19 = VGGNet()
vgg19.set_state_dict(P.load('/home/aistudio/work/vgg19_ww.pdparams'))
vgg19.eval()辅助函数
在训练迭代中显示图像,以观察效果。
def show_image(srresnet=None, srgan=None, path=None):
if srresnet == None:
srresnet = G()
srresnet.eval()
if srgan == None:
srgan = G()
srgan.eval()
fig = plt.figure(figsize=(25, 25))
gs = plt.GridSpec(1, 4)
gs.update(wspace=0.1, hspace=0.1)
if path == None:
image = Image.open(PATH+DIRS[np.random.randint(len(DIRS))])
else:
image = Image.open(path)
image = image.crop([0,0,image.size[0]//SCALE*SCALE,image.size[1]//SCALE*SCALE])
# image = image.crop([0,0,40,40])
LR0 = image.resize((image.size[0]//SCALE,image.size[1]//SCALE),Image.BICUBIC)
LR = np.array(LR0).astype('float32').reshape([LR0.size[1],LR0.size[0],3,1]).transpose([3,2,0,1]) / 255 * 2 - 1
LSR_srresnet = srresnet(P.to_tensor(LR)).numpy()
LSR_srresnet = LSR_srresnet.reshape([3,LR0.size[1]*SCALE,LR0.size[0]*SCALE]).transpose([1,2,0])
# LSR_srresnet = Image.fromarray(np.uint8((LSR_srresnet+1)/2*255)) ### 亮斑的罪魁祸首
LSR_srresnet = (LSR_srresnet+1)/2
LSR_srgan = srgan(P.to_tensor(LR)).numpy()
print(np.max(LSR_srgan), np.min(LSR_srgan))
LSR_srgan = LSR_srgan.reshape([3,LR0.size[1]*SCALE,LR0.size[0]*SCALE]).transpose([1,2,0])
# LSR_srgan = Image.fromarray(np.uint8((LSR_srgan+1)/2*255)) ### 亮斑的罪魁祸首
LSR_srgan = (LSR_srgan+1)/2
ax = plt.subplot(gs[0])
plt.imshow(LR0)
plt.title('LR')
ax = plt.subplot(gs[1])
plt.imshow(LSR_srresnet)
plt.title('SRResNet')
ax = plt.subplot(gs[2])
plt.imshow(LSR_srgan)
plt.title('SRGAN')
ax = plt.subplot(gs[3])
plt.imshow(image)
plt.title('HR')
plt.show()
show_image()
训练
为了与SRGAN作比较,同时训练一个SRResNet,也就是只使用了生成器,并只用L2损失来训练的网络。
SRGAN生成器的损失 = 图像L2损失 + λ1×感知损失 + λ2×对抗损失, 其中λ1=1e-2, λ2=1e-2。
SRResNet和SRGAN的生成器相同初始化。
由于Celeba比DIV2K图像数量多很多,epoch可以相对少一些。
def srresnet_trainer(lr, hr, srresnet, optimizer_srresnet):
sr = srresnet(lr)
loss = P.mean((sr-hr)**2)
srresnet.clear_gradients()
loss.backward()
optimizer_srresnet.minimize(loss)
def srgan_trainer(lr, hr, srgan_g, srgan_d, vgg, optimizer_srgan_g, optimizer_srgan_d, λ1=1e-2, λ2=1e-2):
sr = srgan_g(lr)
f = vgg(P.concat([sr,hr],axis=0))
loss_content = P.mean((sr-hr)**2) + λ1*P.mean((f[:f.shape[0]//2,:,:,:]-f[f.shape[0]//2:,:,:,:])**2)
d = srgan_d(P.concat([sr,hr],axis=0))
loss_adversarial_g = P.mean(-P.log(d[:d.shape[0]//2,:]+1e-8))
loss_adversarial_d = (P.mean(-P.log(d[d.shape[0]//2:,:]+1e-8)) + P.mean(-P.log(1-d[:d.shape[0]//2,:]+1e-8))) / 2
loss_g = loss_content + λ2*loss_adversarial_g
vgg.clear_gradients()
srgan_g.clear_gradients()
srgan_d.clear_gradients()
loss_g.backward(retain_graph=True)
loss_adversarial_d.backward()
optimizer_srgan_g.minimize(loss_g)
optimizer_srgan_d.minimize(loss_adversarial_d)
def train(epoch_num=200, load_model=False, batchsize=1, model_path = './output/'):
srresnet = G()
srgan_g = G()
srgan_g.set_state_dict(srresnet.state_dict())
srgan_d = D()
srgan_d.train()
optimizer_srresnet = P.optimizer.Adam(learning_rate=1e-4, beta1=0.9, parameters=srresnet.parameters())
optimizer_srgan_g = P.optimizer.Adam(learning_rate=1e-4, beta1=0.9, parameters=srgan_g.parameters())
optimizer_srgan_d = P.optimizer.Adam(learning_rate=1e-4, beta1=0.9, parameters=srgan_d.parameters())
if load_model == True:
srresnet.set_state_dict(P.load(model_path+'srresnet.pdparams'))
srgan_g.set_state_dict(P.load(model_path+'srgan_g.pdparams'))
srgan_d.set_state_dict(P.load(model_path+'srgan_d.pdparams'))
srresnet.set_state_dict(P.load(model_path+'备用srresnet.pdparams'))
srgan_g.set_state_dict(P.load(model_path+'备用srgan_g.pdparams'))
srgan_d.set_state_dict(P.load(model_path+'备用srgan_d.pdparams'))
iteration_num = 0
for epoch in range(epoch_num):
reader = reader_patch(batchsize)
for iteration in range(len(DIRS)):
srresnet.train()
srgan_g.train()
iteration_num += 1
LR, HR = next(reader)
LR, HR = data_augmentation(LR, HR)
LR = P.to_tensor(LR)
HR = P.to_tensor(HR)
srresnet_trainer(LR, HR, srresnet, optimizer_srresnet)
srgan_trainer(LR, HR, srgan_g, srgan_d, vgg19, optimizer_srgan_g, optimizer_srgan_d)
if(iteration_num % 100 == 0):
print('Epoch: ', epoch, ', Iteration: ', iteration_num)
P.save(srresnet.state_dict(), model_path+'srresnet.pdparams')
P.save(srgan_g.state_dict(), model_path+'srgan_g.pdparams')
P.save(srgan_d.state_dict(), model_path+'srgan_d.pdparams')
P.save(srresnet.state_dict(), model_path+'备用srresnet.pdparams')
P.save(srgan_g.state_dict(), model_path+'备用srgan_g.pdparams')
P.save(srgan_d.state_dict(), model_path+'备用srgan_d.pdparams')
show_image(srresnet, srgan_g)
# train(epoch_num=1, load_model=False, batchsize=16)
# train(epoch_num=998, load_model=True, batchsize=16)测试
可以看到图中有一些斑点,根据我的猜测,这是训练不充分导致的,总体上SRGAN的斑点更多,说明它比SRResNet需要更多训练,也就是它的上限更高。 老天爷,我之前竟然装模作样瞎分析一番,尴了个大尬。。。不删了,作为我成长的见证。。。出现斑点的原因其实是用了Image.fromarray(np.uint8())!不过说训练不充分也有道理,训练充分的话就不会超出范围,也就没这个幺蛾子啦。。
相对SRResNet来说,SRGAN不那么平滑,但是有些细节并不准确,更像是噪声,而且有时会出现奇怪的东西,例如额头上的亮光。
srresnet = G()
srgan_g = G()
model_path = './output/'
srresnet.set_state_dict(P.load(model_path+'srresnet.pdparams'))
srgan_g.set_state_dict(P.load(model_path+'srgan_g.pdparams'))
show_image(srresnet, srgan_g)