这里写自定义目录标题
- 异构蜂窝网络:用户关联和信道分配
- a stochastic game
- Multi-Agent Q-Learning Method
- Multi-Agent dueling double DQN Algorithm
- 分布式动态下行链路波束成形
- Limited-Information Exchange Protocol
- DistributedDRL-Based DTDE Scheme for DDBC
- DistributedDRL-Based DTDE Scheme for DDBC
- 空基网络中的分布式多用户接入控制:BS和UE关联
- 基于分布式DRL的用户驱动接入控制算法
- 基于分布式DRL的用户驱动接入控制算法
- 仿真和基准算法
- 天基网络中的LEO卫星多用户信道分配:RB分配
- 基于协作DRL的 LEO 卫星多用户信道分配
- 协作DRL算法:LEO卫星端和地面UE端
- 仿真和基准算法
- 天基网络中的LEO地球固定小区设计:波束角度、RB分配、RB预配置子集
- 基于多时间尺度DRL的协作资源优化算法
- LEO 卫星侧MDP 模型
- UE 侧MDP 模型
- 多时间尺度多智能体DRL算法
- 仿真
- 基准算法
- 天空融合网络中的多维资源优化:卫星的频谱分配、UAV轨迹、UAV和UE关联
- 多层网络节点的 MDP 模型设计
- UE 侧MDP 模型
- UAV 中继侧MDP 模型
- GEO 卫星侧MDP 模型
- 场景适配的多层DRL决策算法设计
- 联合式多层算法
- 独立式多层算法
- 层次式多层算法
- 联邦式多层算法
- 多层DRL决策算法流程图
- 仿真
面向非地面网络的智能无线资源管理机制与算法研究
[1]曹阳. 面向非地面网络的智能无线资源管理机制与算法研究[D]. 电子科技大学, 2023. DOI: 10.27005/d.cnki.gdzku.2023.000168.
异构蜂窝网络:用户关联和信道分配
N. Zhao, Y. -C. Liang, D. Niyato, Y. Pei, M. Wu and Y. Jiang, “Deep Reinforcement Learning for User Association and Resource Allocation in Heterogeneous Cellular Networks,” in IEEE Transactions on Wireless Communications, vol. 18, no. 11, pp. 5141-5152, Nov. 2019, doi: 10.1109/TWC.2019.2933417.
L BSs → N UEs
K orthogonal channels
the Joint user association and resource allocation Optimization Problem
variables: discrete
1.bli(t)=1: the
i
i
ith UE chooses to associate with the BS
l
l
l at time
t
t
t
2.cik(t)=1: the
i
i
ith UE utilizes the channel
C
k
Ck
Ck at time
t
t
t
constraints
1.each UE can only choose at most one BS at any time
2.each UE can only choose at most one channel at any time
3.the SINR of the
i
t
h
ith
ith UE ≥
a stochastic game
state
si(t) ∈{0, 1}
si(t)=0 means that the ith UE cannot meet its the minimum QoS requirement, that is, Γi(t) < Ωi
the number of possible states is
2
N
2^N
2N
action
alki(t)={bli(t),cik(t)},
1.bli(t)=1: the
i
i
ith UE chooses to associate with the BS
l
l
l at time
t
t
t
2.cik(t)=1: the
i
i
ith UE utilizes the channel
C
k
Ck
Ck at time
t
t
t
The number of possible actions of each UE is
L
K
LK
LK = L种选择方式 * K种选择方式
reward
the long-term reward Φi = the weighted sum of the instantaneous rewards over a finite period T
the reward of the ith UE = the ith UE’s utility - the action-selection cost Ψi
Ψi > 0. Note that the negative reward (−Ψi) acts as a punishment.
to guarantee the minimum QoS of all UEs, this negative reward should be set big enough.
the ith UE’s utility = \rho_i * the total transmission capacity of the ith UE - the total transmission cost associated with the ith UE
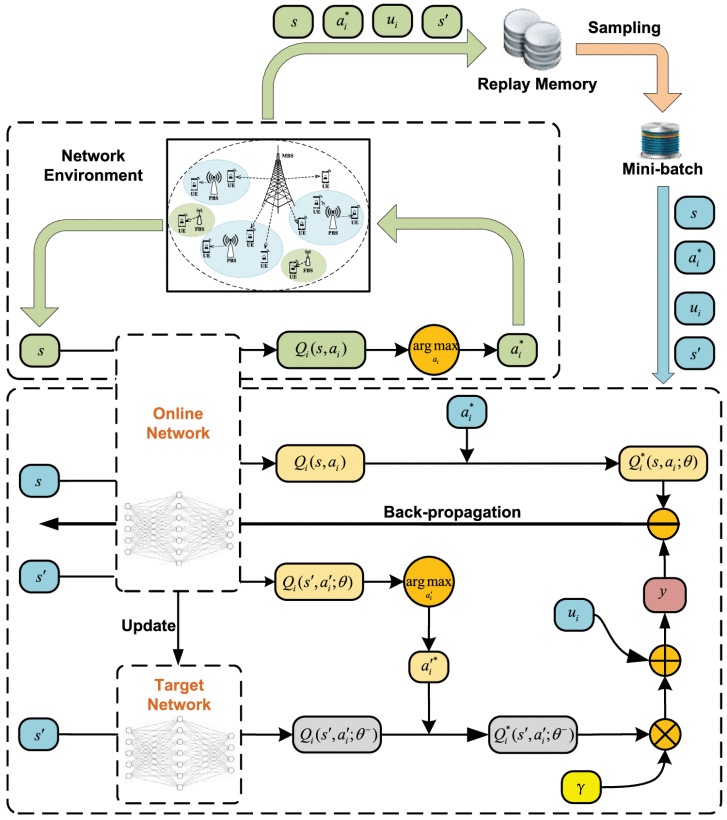
Multi-Agent Q-Learning Method
At the beginning of each training episode, the network state is initialized through message passing.
- Each UE is connected to the neighboring BS with the maximum received signal power.
By using a pilot signal, each UE can measure the received power from the associated BS and the randomly-selected channel. - Then, each UE reports its own current state to its current associated BS.
By the message passing among the BSs through the backhaul communication link, the global state information of all UEs is obtained. - Then, the BSs send this global state informations to all UEs.
Each episode ends when the QoS of all UEs is satisfied or when the maximum step T is reached.
The total episode reward is the accumulation of instantaneous rewards of all steps within an episode.

Q i ( s , a i ) = Q i ( s , a i ) + δ [ u i ( s , a i , π − i ) + γ max a i ′ ∈ A i Q i ( s ′ , a i ′ ) − Q i ( s , a i ) [ u i ( s , a i , π − i ) + γ max a i ′ ∈ A i Q i ( s ′ , a i ′ ) ] , {Q_{i}}(s,a_{i})={Q_{i}}(s,a_{i})+ \delta \left[{ {u_{i}}(s,a_{i},{\mathcal{ \pi }}_{-i}) + \gamma \max \limits _{a_{i}' \in {\mathcal{ A}}_{i}} {Q_{i}}({s'},{a_{i}'})} {- {Q_{i}}(s,a_{i})\vphantom {\left [{ {u_{i}}(s,a_{i},{\mathcal{ \pi }}_{-i}) + \gamma \max \limits _{a_{i}' \in {\mathcal{ A}}_{i}} {Q_{i}}({s'},{a_{i}'})}\right.} }\right], Qi(s,ai)=Qi(s,ai)+δ[ui(s,ai,π−i)+γai′∈AimaxQi(s′,ai′)−Qi(s,ai)[ui(s,ai,π−i)+γai′∈AimaxQi(s′,ai′)],
Multi-Agent dueling double DQN Algorithm
dueling double deep Q-network (D3QN)
A NN function approximator
Q
i
(
s
,
a
i
;
θ
)
≈
Q
i
∗
(
s
,
a
i
)
Q_{i}(s,a_{i};{\theta }) \approx {Q_{i}^{*}}(s,a_{i})
Qi(s,ai;θ)≈Qi∗(s,ai) with weights θ is used as an online network.
The DQN utilizes a target network alongside the online network to stabilize the overall network performance.
experience replay
During learning, instead of using only the current experience (s, ai,ui(s, ai),s′), the NN can be trained through sampling mini-batches of experiences from replay memory D uniformly at random.
By reducing the correlation among the training examples, the experience replay strategy ensures that the optimal policy cannot be driven to a local minima.
double DQN
since the same values are used to select and evaluate an action in Q-learning and DQN methods, Q-value function may be over-optimistically estimated.
Thus, double DQN (DDQN) [44] is used to mitigate the above problem
dueling architecture
The advantage function A(s, ai) describes the advantage of the action ai compared with the other possible actions.
This dueling architecture can lead to better policy evaluation.
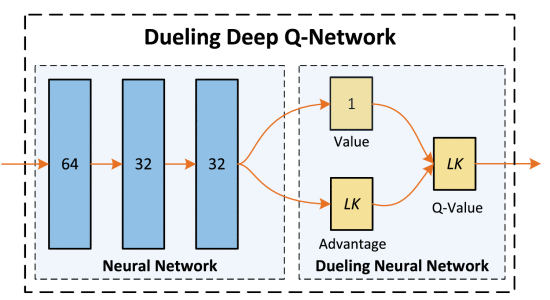
L
i
(
θ
)
=
E
s
,
a
i
,
u
i
(
s
,
a
i
)
,
s
′
[
(
y
i
D
Q
N
−
Q
i
(
s
,
a
i
;
θ
)
)
2
]
,
{L_{i}}({\theta }) = {E_{s,a_{i},u_{i}(s,a_{i}),s'}}[{(y_{i}^{DQN} - Q_{i}(s,a_{i};{\theta }))^{2}}],
Li(θ)=Es,ai,ui(s,ai),s′[(yiDQN−Qi(s,ai;θ))2],
上图里面红色的y为
y
i
D
D
Q
N
=
u
i
(
s
,
a
i
)
+
γ
Q
i
(
s
′
,
arg
max
a
i
′
∈
A
i
Q
i
(
s
′
,
a
i
′
;
θ
)
;
θ
−
)
.
y_{i}^{DDQN} = {u_{i}}(s,a_{i}) + \gamma Q_{i}\left ({s',\mathop {\arg \max }\limits _{a'_{i} \in {\mathcal{ A}}_{i}} Q_{i}(s',a'_{i};{\theta });\theta ^{-} }\right).
yiDDQN=ui(s,ai)+γQi(s′,ai′∈AiargmaxQi(s′,ai′;θ);θ−).

分布式动态下行链路波束成形
J. Ge, Y. -C. Liang, J. Joung and S. Sun, “Deep Reinforcement Learning for Distributed Dynamic MISO Downlink-Beamforming Coordination,” in IEEE Transactions on Communications, vol. 68, no. 10, pp. 6070-6085, Oct. 2020, doi: 10.1109/TCOMM.2020.3004524.
波束成形论文代码
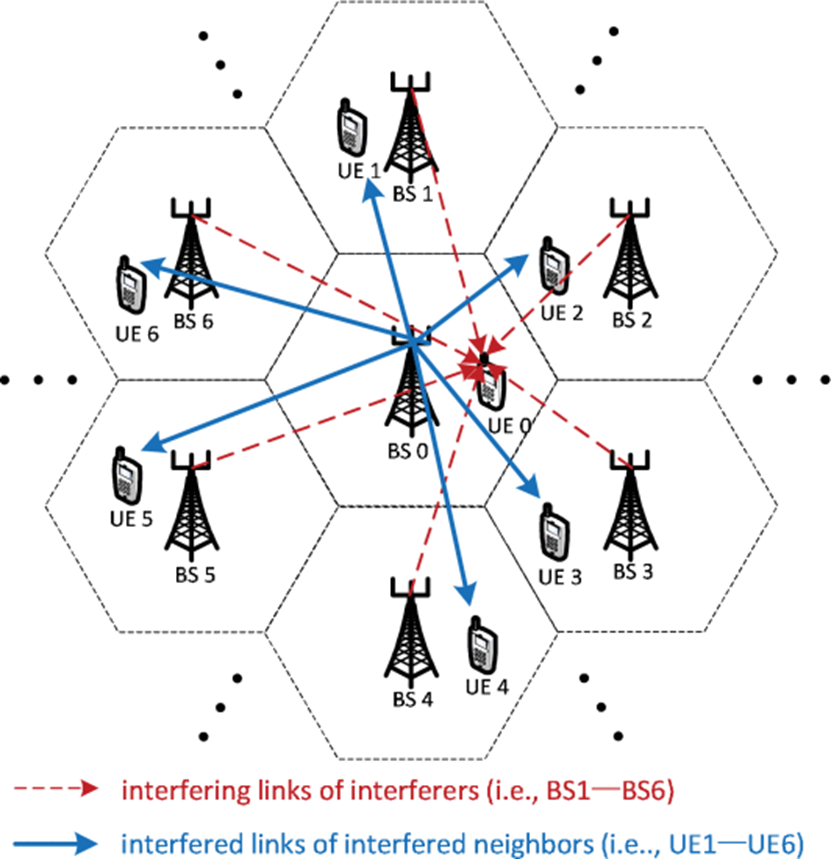
multi-cell MISO-IC model
a downlink cellular network of K cells
no intra-cell interference
all the BSs are equipped with a uniform linear array having
N
N
N (
N
≥
1
N≥1
N≥1) antenna elements.
max
W
(
t
)
∑
k
=
1
K
C
k
(
W
(
t
)
)
8a
s
.
t
.
0
≤
∥
w
k
(
t
)
∥
2
≤
p
m
a
x
,
∀
k
∈
K
,
8b
\max _{\mathbf {W}{(t)}}~\sum _{k=1}^{K}C_{k}(\mathbf {W}{(t)}) \text{8a}\\{\mathrm{ s.t.}}~0\leq \left \|{\mathbf {w}_{k}{(t)}}\right \|^{2} \leq p_{\mathrm{ max}},~\forall k \in \mathcal {K},\text{8b}
maxW(t) ∑k=1KCk(W(t))8as.t. 0≤∥wk(t)∥2≤pmax, ∀k∈K,8b
the beamformer of BS
k
k
k
the available maximum transmit power budget of each BS
Limited-Information Exchange Protocol
a downlink data transmission framework
The first phase (phase 1) is a preparing phase for the subsequent data transmission
the second phase (phase 2) is for the downlink data transmission.
in the centralized approaches, the cascade procedure of collecting global CSI, computing beamformers, and sending beamformers to the corresponding BSs is supposed to be carried out within phase 1.
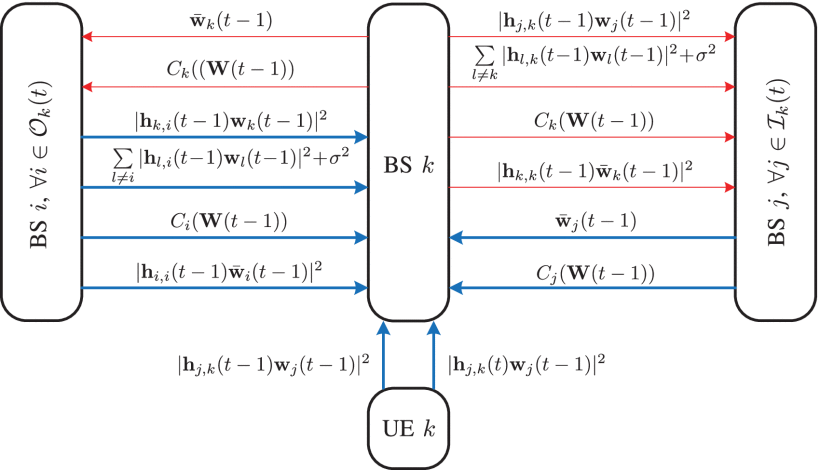
Designed limited-information exchange protocol in time slot t.
BSs are able to share their historical measurements and other information with their interferers and interfered neighbors.
- The received interference power from interferer
j
∈
I
k
(
t
)
j∈Ik(t)
j∈Ik(t) in time slot
t
−
1
t−1
t−1
, i.e., ∣ ∣ h † j , k ( t − 1 ) w j ( t − 1 ) ∣ ∣ 2 ∣∣h†j,k(t−1)wj(t−1)∣∣2 ∣∣h†j,k(t−1)wj(t−1)∣∣2 . - The total interference-plus-noise power of UE
k
k
k in time slot
t
−
1
t−1
t−1
, i.e., ∑ l ≠ k ∣ ∣ h † l , k ( t − 1 ) w l ( t − 1 ) ∣ ∣ 2 + σ 2 ∑l≠k∣∣h†l,k(t−1)wl(t−1)∣∣2+σ2 ∑l=k∣∣h†l,k(t−1)wl(t−1)∣∣2+σ2 . - The achievable rate of direct link
k
k
k in time slot
t
−
1
t−1
t−1
, i.e., C k ( W ( t − 1 ) ) Ck(W(t−1)) Ck(W(t−1)) . - The equivalent channel gain of direct link
k
k
k in time slot
t
−
1
t−1
t−1
, i.e., ∣ ∣ h † k , k ( t − 1 ) w ¯ k ( t − 1 ) ∣ ∣ 2 ∣∣h†k,k(t−1)w¯k(t−1)∣∣2 ∣∣h†k,k(t−1)w¯k(t−1)∣∣2 .
DistributedDRL-Based DTDE Scheme for DDBC
distributed-training-distributed-executing (DTDE)
distributed dynamic downlink-beamforming coordination (DDBC)
each BS is an independent agent
a multi-agent reinforcement learning problem
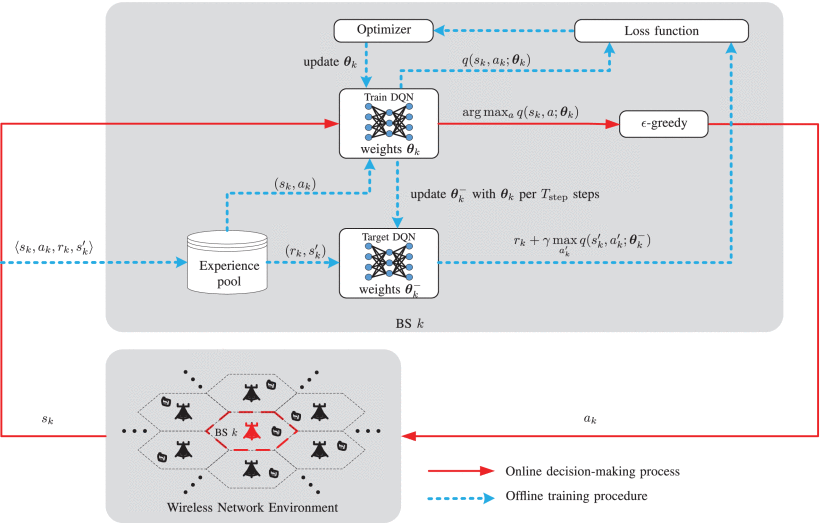
Illustration of the proposed distributedDRL-based DTDE scheme in the considered multi-agent system.
- Actions
A = { ( p , c ) , p ∈ P , c ∈ C } , \mathcal {A} = \{(p, {\mathbf{c}}),~p\in \mathcal {P},~{\mathbf{c}}\in \mathcal {C}\}, A={(p,c), p∈P, c∈C},
P = { 0 , 1 Q p o w − 1 p m a x , 2 Q p o w − 1 p m a x , ⋯ , p m a x } \mathcal {P}=\left \{{0, \tfrac {1}{Q_{\mathrm{ pow}}-1}p_{\mathrm{ max}},\,\,\tfrac {2}{Q_{\mathrm{ pow}}-1}p_{\mathrm{ max}},\,\,\cdots,\,\,p_{\mathrm{ max}}}\right \} P={0,Qpow−11pmax,Qpow−12pmax,⋯,pmax}
C = { c 0 , c 1 , ⋯ , c Q c o d e − 1 } \mathcal {C}=\left \{{\mathbf {c}_{0},\,\,\mathbf {c}_{1},\,\,\cdots,\,\,\mathbf {c}_{Q_{\mathrm{ code}}-1}}\right \} C={c0,c1,⋯,cQcode−1}
1.the transmit power of BS k in time slot t
2.code c k ( t ) ck(t) ck(t)
the total number of available actions is Q = Q p o w Q c o d e Q=QpowQcode Q=QpowQcode - States
1.Local Information
2.Interferers’ Information
3.Interfered Neighbors’ Information - Reward
the achievable rate of agent k k k
the penalty on BS k is defined as the sum of the achievable rate losses of the interfered neighbors j∈Ok(t+1) , which are interfered by BS k , as follows:
DistributedDRL-Based DTDE Scheme for DDBC

In training step t , the prediction error
L
(
θ
)
=
1
2
M
b
∑
⟨
s
,
a
,
r
,
s
′
⟩
∈
D
(
r
′
−
q
(
s
,
a
;
θ
)
)
2
L(\boldsymbol {\theta })= \frac {1}{2M_{b}}\sum \limits _{\langle s,a,r,s'\rangle \in \mathcal {D}}\left ({r'-q(s,a; \boldsymbol {\theta })}\right)^{2}
L(θ)=2Mb1⟨s,a,r,s′⟩∈D∑(r′−q(s,a;θ))2
the target value of reward
r
′
=
r
+
γ
max
a
′
q
(
s
′
,
a
′
;
θ
−
)
r'= r + \gamma \max \limits _{a'}q(s',a'; \boldsymbol {\theta }^{-})
r′=r+γa′maxq(s′,a′;θ−)
the optimizer returns a set of gradients shown in (22) to update the weights of the trained DQN through the back-propagation (BP) technique
∂
L
(
θ
)
∂
θ
=
1
M
b
∑
⟨
s
,
a
,
r
,
s
′
⟩
∈
D
(
r
′
−
q
(
s
,
a
;
θ
)
)
∇
q
(
s
,
a
;
θ
)
.
\frac {\partial L(\boldsymbol {\theta })}{\partial \boldsymbol {\theta }}= \frac {1}{M_{b}}\sum _{\langle s,a,r,s'\rangle \in \mathcal {D}}\left ({r'-q(s,a; \boldsymbol {\theta })}\right)\nabla q(s,a; \boldsymbol {\theta }).
∂θ∂L(θ)=Mb1∑⟨s,a,r,s′⟩∈D(r′−q(s,a;θ))∇q(s,a;θ).
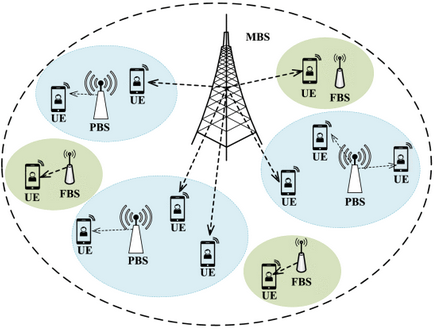
空基网络中的分布式多用户接入控制:BS和UE关联
Y. Cao, S. -Y. Lien and Y. -C. Liang, “Deep Reinforcement Learning For Multi-User Access Control in Non-Terrestrial Networks,” in IEEE Transactions on Communications, vol. 69, no. 3, pp. 1605-1619, March 2021, doi: 10.1109/TCOMM.2020.3041347.
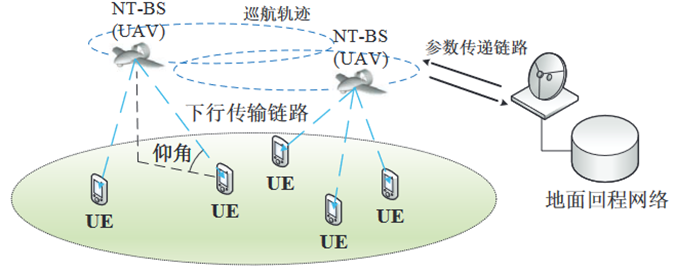
K架固定翼式UAV作为NT-BS,为特定区域内的M个移动UE提供下行传输服务
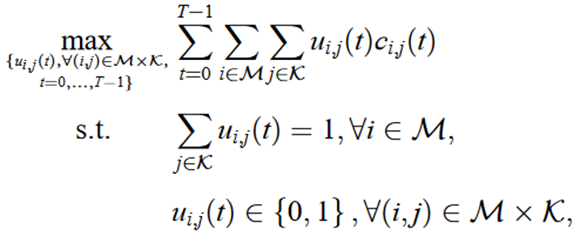
ci,j(t)表示第j个NT-BS对第i个UE在时隙t的传输速率
变量:ui,j(t)表示第i个UE在时隙t是否接入第j个NT-BS
约束:每个UE在单个时隙只能接入一个NT-BS
基于分布式DRL的用户驱动接入控制算法
每个用户均作为独立的智能体,利用DQN在UE侧建立本地接入决策模块,并且每个UE仅采用本地观测量自主地完成NT-BS选择。
状态空间
si(t)表示第i个UE在时隙t的状态(4K+1个元素)
1.第i个用户在时隙t−1所接入的NT-BS标号(K个元素)
2.第i个用户处在时隙t−1和时隙t来自各NT-BS的RSS(2K个元素)
3.每个NT-BS在时隙t−1的接入用户数目(K个元素)
4.第i个UE在时隙t−1实现的传输速率(1个元素)
动作空间
ai(t)表示第i个UE在时隙t的动作(K个元素)
ui,j(t)表示第i个UE在时隙t是否接入第j个NT-BS
奖励函数
第i个UE在第t个时隙内的奖励函数
ri(t)=ri−(t)−ηφi(t)
UE获得的本地奖励
该UE对接入相同NT-BS的其他UE和速率所造成的影响
第i个UE的本地奖励:由第i个UE在当前时隙的传输速率和对应的切换代价所决定
ri−(t)=ωi(t),ai(t)=ai(t−1),
ri−(t)=ωi(t)−C,ai(t) ̸=ai(t−1).
第i个UE采用特定接入决策对集合Oj(t)中其他UE造成的影响φi(t)=
在假定第i个UE没有接入第j个NT-BS的情况下第k个UE的传输速率ωk−i(t)-第k个UE的真实传输速率ωk(t)
对k求和
UE端采用DQN
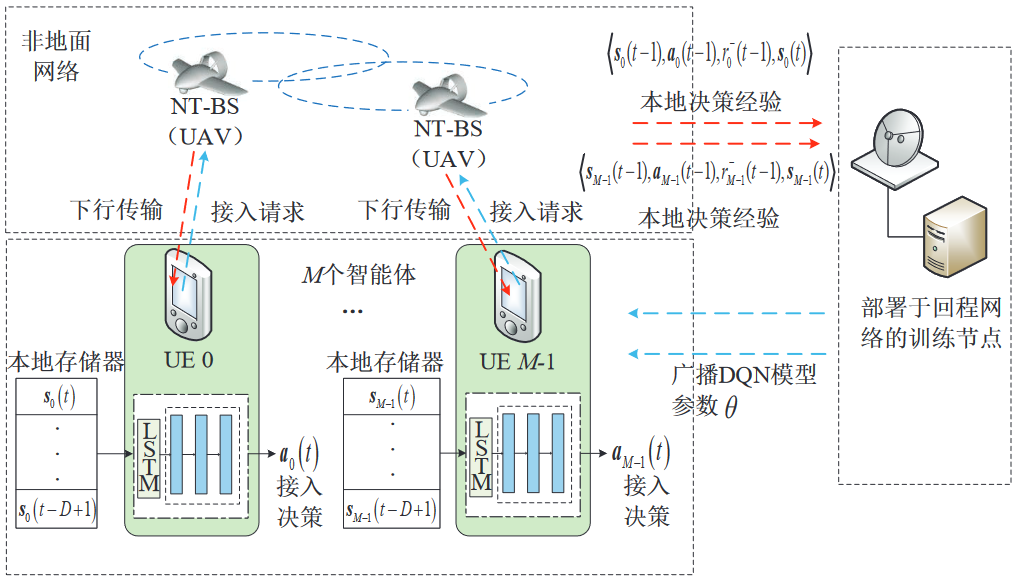
用户驱动的智能接入控制方案
基于分布式DRL的用户驱动接入控制算法

仿真和基准算法
- RSS 算法:在每个时隙,每个UE 选择可以提供最强RSS 的NT-BS 接入。
- Q 学习算法 [122]:在该算法中,每个UE 采用表格形式函数(即 Q 表格) 来估计每个状态-动作对的 Q 值。在每个时隙,每个UE 根据所建立的 Q 表格做 出NT-BS 选择。
- 置信区间上界 (Upper Confidence Bound, UCB) 算法 [123]:在UCB 算法中,UE 在每个时隙根据下列公式确定其NT-BS 选择
- 随机算法:在该算法中,每个UE 在每个时隙随机选择一个NT-BS 接入。
- 搜索算法(最优结果):为了获得最优结果,该算法假定存在一个集中决 策节点实时收集全局网络信息。
M = 40 个UE 和 K = 6 个NT-BS
天基网络中的LEO卫星多用户信道分配:RB分配
Y. Cao, S. -Y. Lien and Y. -C. Liang, “Multi-tier Collaborative Deep Reinforcement Learning for Non-terrestrial Network Empowered Vehicular Connections,” 2021 IEEE 29th International Conference on Network Protocols (ICNP), Dallas, TX, USA, 2021, pp. 1-6, doi: 10.1109/ICNP52444.2021.9651962.
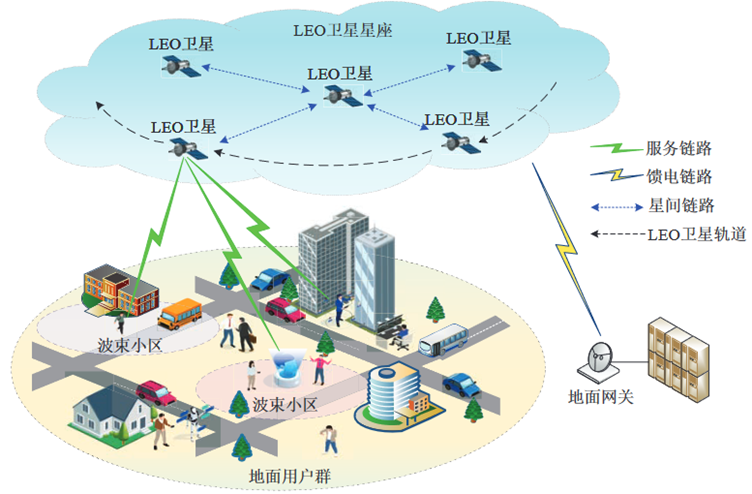
多波束LEO卫星下行传输系统
每颗LEO卫星采用多波束技术在地面形成N个频率复用因子为1的波束小区,并且每个波束小区内有M个移动UE。
在第t个时隙中,第j个小区中第i个UE在第k个RB可以实现的下行传输速率可以表示为ci,j,k(t)
在第t个时隙中,第j个小区中第i个UE可以实现的下行传输速率可以表示为 ci,j(t) 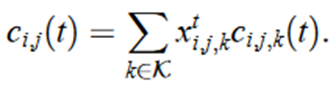
UE满意度αi,j(t):描述LEO卫星为UE分配的RB数目与该UE真实的RB数目需求之间的偏差 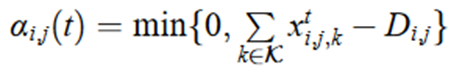
速率-满意度效用函数Ui,j(t) = wr ci,j(t) + ws αi,j(t),其中wr+ws=1。
从时隙0到时隙T−1的平均UE间速率-满意度效用函数最小值为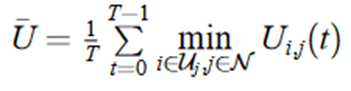
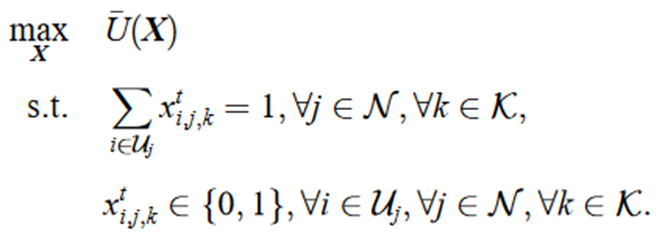
最大化从时隙0到时隙T−1的平均UE间速率-满意度效用函数最小值
变量:如果在时隙t,第j个波束小区中第i个UE接入第k个RB,那么xti,j,k=1。
约束:在单个时隙内,每个RB只能分配给一个UE
基于协作DRL的 LEO 卫星多用户信道分配
状态空间
在每个时隙 t,LEO 卫星的状态向量 s(t)
1.上 一个时隙的RB 分配决策
2.每个UE 在上 一个时隙所分配RB 上经历的干扰强度
3.每个UE 在上一个时隙的满意度
4.上一个时隙多个UE 试图接入相同RB 时发生碰撞的RB 的索引
动作空间
LEO 卫星在每个时隙 t 需要为波束小区内各UE 分配RB
如果在时隙t,第j个波束小区中第i个UE接入第k个RB,那么xti,j,k=1。
将网络实际输出连续变 量ˆ a(t) ∈ [0, 1] 进行离散化处理
奖励函数r(t)
UE 中速率-满意度效用最小值 min i∈Uj,j∈N ci,j(t)
UE 的当前RB 接入决策发生碰撞的惩罚项 Ci,j collision(t)
UE 满意度 不满足的惩罚项 Csatisfactory αi,j(t)
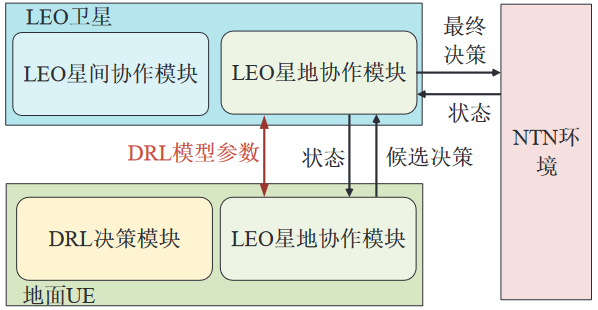
LEO 卫星DRL分层协作架构
UE处的DRL决策模块采用:双延迟深度确定性策略梯度 (Twin Delayed Deep Deterministic Policy Gradient, TD3) 算法
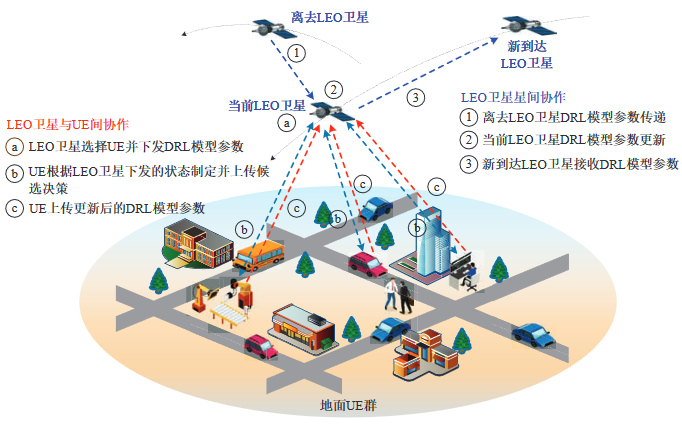
LEO 卫星星间和星地协作关系
协作DRL算法:LEO卫星端和地面UE端
协作DRL算法中LEO卫星端操作流程
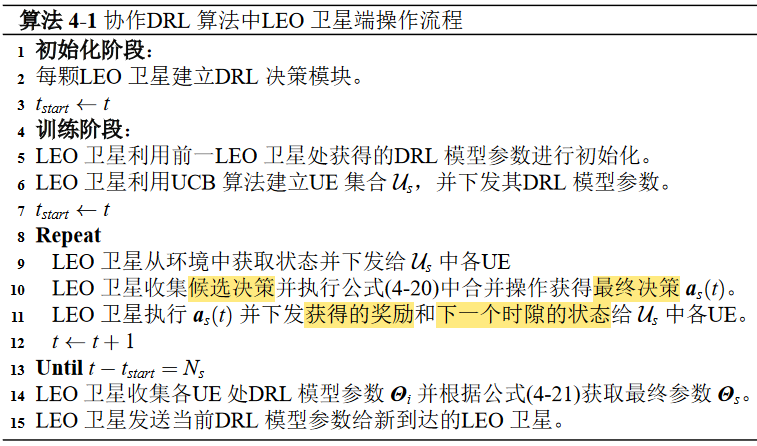
协作DRL算法中地面UE端操作流程

仿真和基准算法
在这两种方案中,多波束LEO卫星在半径为500千米的圆形区域内,形成N=2个相同尺寸的波束小区,并在每个波束小区内,采用K=5个带宽为180kHz的RB,服务M=3个移动的UE。
基准算法
DDPG 算法
无协作TD3 算法
天基网络中的LEO地球固定小区设计:波束角度、RB分配、RB预配置子集
Y. Cao, S. -Y. Lien, Y. -C. Liang, D. Niyato and X. S. Shen, “Collaborative Deep Reinforcement Learning for Resource Optimization in Non-Terrestrial Networks,” 2023 IEEE 34th Annual International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC), Toronto, ON, Canada, 2023, pp. 1-7, doi: 10.1109/PIMRC56721.2023.10294047.
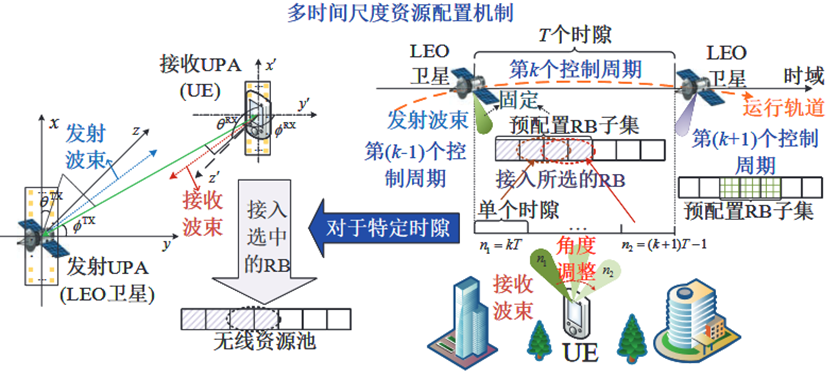
多时间尺度资源配置机制下的LEO卫星地球固定小区方案
LEO 卫星与地面UE 均装 备UPA
UE 在第 n 个时隙中接入第 m 个RB 可实现的接收速率
cn,m(θtn, φtn, θrn, φrn) = B log2(1 + πn,m(θtn, φtn, θrn, φrn)).
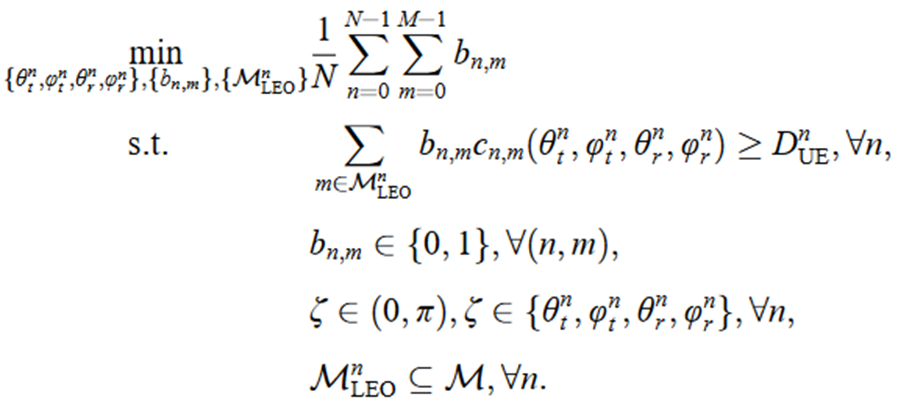
最小化UE从时隙0到时隙N−1利用的RB数目
- LEO发射波束角度
- UE接收波束角度
- RB分配方案:当在第n个时隙中,第m个RB被分配给UE时,bn,m=1
- RB预配置子集:MnLEO表示在时隙n从RB集合M中选取的预配置RB子集。
约束:每个时隙内的速率需求DnUE
基于多时间尺度DRL的协作资源优化算法
LEO 卫星:具有较长控制周期的高层智能体
UE:具有较短控制周期的低层智能体。
在所提出的多时间尺度MDP模型中,工作于不同时间尺度的LEO卫星与UE分别作为高层智能体和低层智能体
LEO 卫星侧MDP 模型
状态空间
- LEO 卫星 的位置信息
- 上一个控制周期内预配置RB 子集中的RB 在每个时隙的平均SNR
动作空间
- LEO发射波束角度
- RB预配置子集:MnLEO表示在时隙n从RB集合M中选取的预配置RB子集。
奖励函数
每个控制周期内满足 约束(5-11b)的时隙内UE 所获得的平均接收速率
UE 侧MDP 模型
状态空间
- 上一个时隙内当前RB 预配置子集 MkLEO 中每一个RB 的SNR
- 上一个时隙内接收天线上当前RB 预配置子集 MkLEO 中所有RB 可实现的平均接收信号强度
动作空间
- UE接收波束角度
- RB分配方案:当在第n个时隙中,第m个RB被分配给UE时,bn,m=1
奖励函数
单个RB 可实现的平均接收速率
UE 接收速率满意度惩罚项。约束(5-11b):每个时隙内的速率需求DnUE
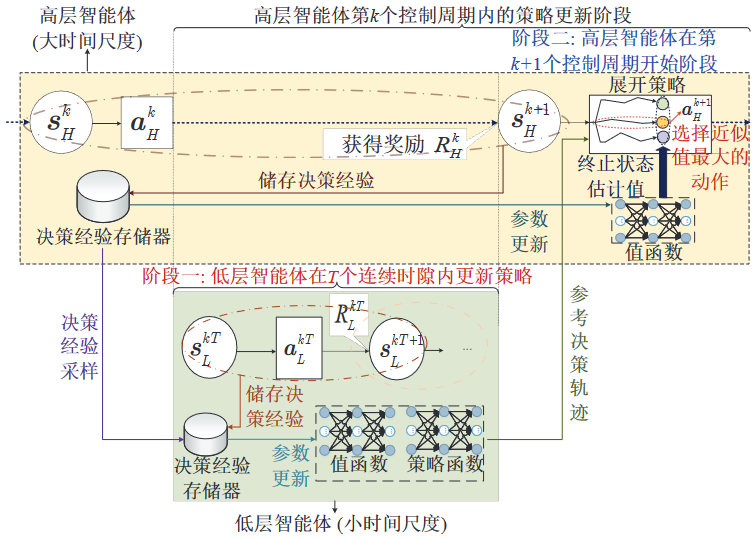
多时间尺度多智能体DRL算法策略更新流程
多时间尺度多智能体DRL算法
采用TRPO 算法来更新低层智能体的策略
所提出的多时间尺度多智能体DRL算法本质上是一种同策略DRL算法,因此是一种在线学习算法。

仿真
采用具有 K = 100 个RB 的LEO 卫星为速 率需求动态变化的地面UE 提供服务。
其中,RB 带宽为 180 kHz,并且所有RB 共 被平均分为 5 组,在优化RB 分配方案时以RB 组为单位。
UE 的速率需求采用数据包设定,速率 需求在每个时隙的到达数目服从均值为 2 的泊松分布,单个速率需求的数据尺寸 为 5 兆比特,因此UE 在每个时隙的整体速率需求为速率需求数目与单位值的乘 积。
基准算法
基于DRL的融合优化算法
- 独立决策方案(记作Independent):UE和LEO卫星独立地制定各自的决策并不进行协同。
- UE独立估计方案(记作Single-estimation):UE仅估计自身的优势函数变化,并不考虑LEO卫星的优势函数变化。
传统的分阶段优化方法
- 计算LEO卫星与UE的波束角度
- 基于搜索的波束扫描方案(记作BFS)
- 基于地理位置信息的周期性波束角度补偿方案(记作PBU)
- RB选择方案
- 贪婪方案(记作Greedy)
- 给定RB接入数目的随机方案(记作Fixed)
- 基于UCB算法的多臂机方案(记作MAB)
波束扫描方案与RB 贪婪分配 方案的组合(记作 BFS-Greedy)可以实现最优性能。
天空融合网络中的多维资源优化:卫星的频谱分配、UAV轨迹、UAV和UE关联
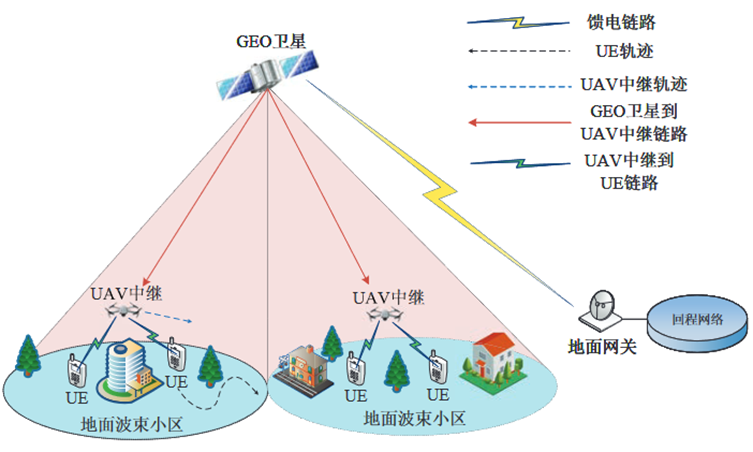
多波束GEO卫星与UAV中继构成的多层NTN
单颗GEO卫星形成C个互不重叠的波束小区,为地面N个UE提供无线覆盖服务。
GEO卫星的频域资源共可分为K个等宽度且互不重叠的频谱块,时域则被划分为等长的时隙。
M个UAV中继
每个波束小区内的UE数目Nj
在时隙t内,GEO卫星到第j个UAV中继的传输速率
在时隙t内,第i个UE从第j个UAV中继获得的接收速率
切换代价Γi,j(t)
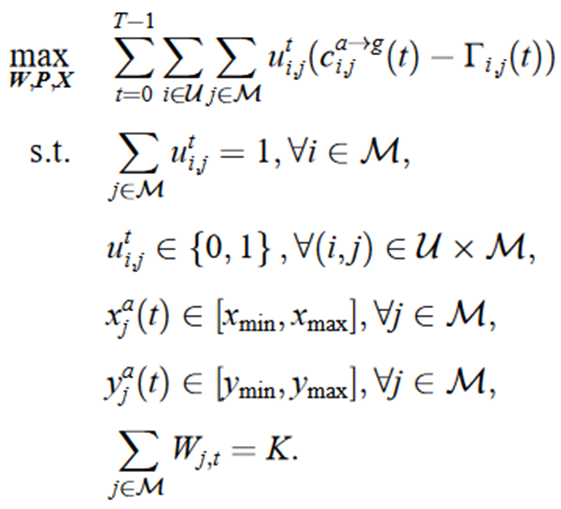
变量:
- GEO卫星的频谱分配方案
Wj,t表示在时隙t,GEO卫星为第j个UAV中继(波束小区)分配的频谱块数目 - UAV的部署轨迹
paj(t)表示第j个UAV中继的三维坐标值 - UE的接入决策
若uti,j=1,则表示在时隙t,第i个UE接入第j个UAV中继。
约束:
- 每个UE在每个时隙只允许接入1个UAV中继
- K个等宽度且互不重叠的频谱块
多层网络节点的 MDP 模型设计
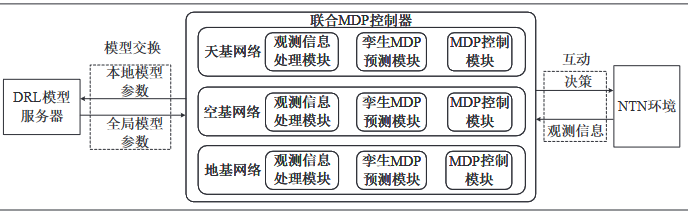
一般化多层DRL决策架构
- 观测信息处理模块
与环 境互动获得本地决策经验
与其他节点互动获得DRL 模型参数 - 孪生MDP 预测模块
预测协作节点的动作选择或策略,并 通过隐式地向协作节点传递改进后的动作选择或策略 - MDP 控制模块
推导出资源 配置最优决策
更新DRL 模型参数
UE 侧MDP 模型
状态空间
1.上一个时隙内接入 的UAV 中继索引
若uti,j=1,则表示在时隙t,第i个UE接入第j个UAV中继。
2.上一个时隙内UAV 中继到UE 的RSS
3.上一个时隙内接入各UAV 中继的UE 数目Nj,t−1= ∑ i∈U ut−1 i,j ,∀j ∈ M
动作空间
{uti,j, ∀j ∈ M}
若uti,j=1,则表示在时隙t,第i个UE接入第j个UAV中继。
奖励函数
每个UE 希望最大化其传输速率并降低 切换次数
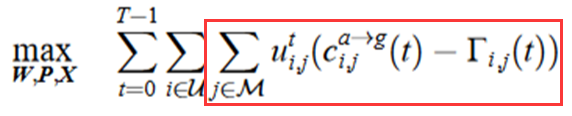
UAV 中继侧MDP 模型
状态空间
1.上一个控制周期的部署位置,即 pja(ta − 1);
2.上一个控制周期内每个UAV 中继的平均接入UE 数目
动作空间
Δx 和 Δy 表示UAV 中继在水平面的部署位置调整量
奖励函数
控制周期内接入UE 的传输速率
GEO 卫星侧MDP 模型
状态空间
上一个控制周期内每个UAV 中继 的平均接入UE 数目
动作空间
GEO卫星的频谱分配方案{Wj,t, ∀j ∈ M}
Wj,t表示在时隙t,GEO卫星为第j个UAV中继(波束小区)分配的频谱块数目
奖励函数
所有用户的总体传输速率
场景适配的多层DRL决策算法设计
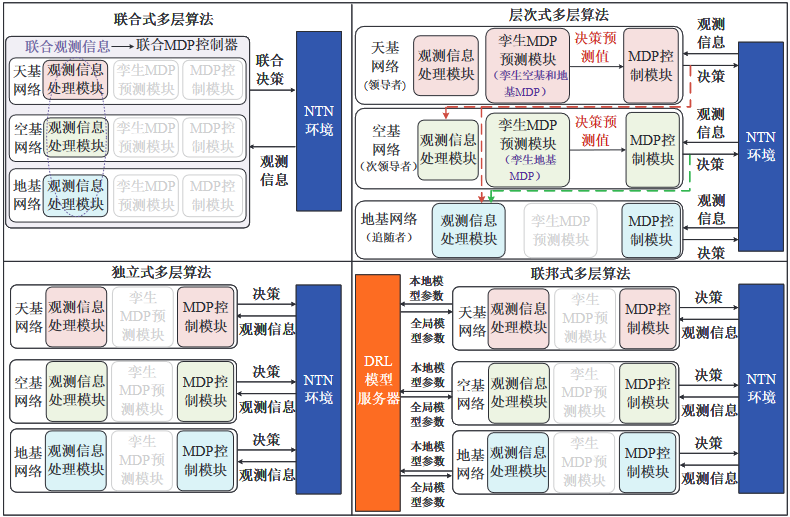
多层DRL决策算法结构图
图6-3中各层网络节点的观测信息是指:公式(6-7)中定义的UE状态向量,公式(6-10)中定义的UAV中继状态向量和(6-13)中定义的GEO卫星状态向量。
联合式多层算法
部分卫星和UAV 由于计算能力受限,因此无法独立承 担DRL 模型的计算,需要把与DRL 模型相关的决策和训练任务卸载到地基网络具 有强大计算能力的集中式控制中心处。
优点:能够基于全局观测量提供最优 的性能
缺点:可扩展性较差。
该算法只适用于联合决策空间维度较小的部 署场景。
独立式多层算法
每个节点独立地利用各自的DRL 决策模型在其控制周期内完 成决策任务。
优点:对各节 点造成的计算开销和信令开销极低
一般适用于优化问题维度极大且节点无法进 行协作的部署场景。
层次式多层算法
填补了联合式算法和独立式算法的中间区域
工作在长控制周期的高层网络节点需要预测工作在短控制周期的低层节点(如地面节点)在之后的控制周期内可能做出的决策。
领导者-追随者博弈
高层网络节点需要预测低层网络节点在给定高层策略情况下将做出的最优决策,然后再去制定自己的长期资源决策,并迫使低层网络节点在观察到高层网络节点的决策后执行其预测的决策。
主要适用于工作在长控制周期的高层网络节点(例如天基网络和空基网络节点)具有较强的计算能力的部署场景。
联邦式多层算法
在一般化多层DRL 决策架构中,控制周期较长的节点 出于与环境互动频率的限制,能够收集的决策经验较为有限,因此无法采用较大 的批尺寸采样训练数据。
多层DRL决策算法流程图
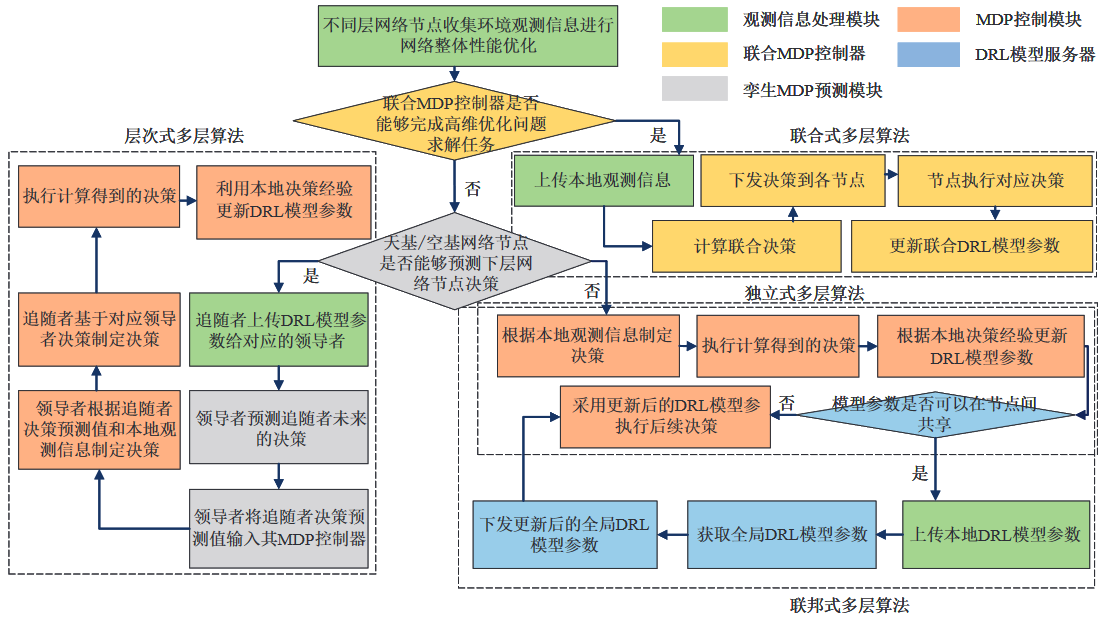
多层DRL决策算法流程图
在多层NTN中资源优化开始时,各节点先对本地资源决策任务的决策空间维度进行估计,并将估计结果上报给联合MDP控制器。
联合MDP控制器将收到的决策空间维度整合,计算相应的计算复杂度并与本地的计算能力进行对比。
如果联合MDP控制器可以负担联合计算开销,则启用联合MDP控制器实现联合式算法。
否则的话,多层NTN资源优化问题将被拆分到各层网络节点,此时各层网络节点根据本地的资源决策任务建立相应的MDP模型。
特别地,当高层网络节点(例如,GEO卫星或空基网络层中的HAP)具有充足的计算能力时,观测信息处理模块、MDP控制模块、特别是孪生MDP预测模块被同时启用来实现层次式算法,并推动空基网络节点和地基网络节点选择天基网络节点预测的“最优”决策。
否则,在各层网络节点计算能力不足时,仅采用观测信息处理模块和MDP控制模块实现独立式算法,但该算法没有收敛性保证,容易造成网络整体性能下降。
此外,在更新本地DRL模型参数之前,各层节点与DRL模型服务器间共享DRL模型参数的信令开销将被估计。
如果DRL模型参数传递过程中的信令开销可以被接受,DRL模型服务器将被激活来实现联邦式算法进而构建全局DRL模型,并能够实现适中的网络性能。
仿真
轨道高度为 35786 千米的GEO 卫星共形成 N = 25 个 面积相同的波束小区覆盖 20 千米乘 20 千米的正方形区域。
GEO 卫星具有 K = 30 个频谱块,其中每个频谱块的带宽为 180 kHz。
UAV 中继的部署高 度和移动速度分别为 5 千米和 10 米每时隙,并且传输功率为 30 dBm。
在仿真开始 时,UE 采用均匀分布,并且噪声功率谱密度为 −110 dBm/Hz。
UE 运动模型采用 高斯-马尔可夫移动模型(Gauss-Markov mobility model),其中平均移动速度和调 整参数分别设为 5 米每时隙和 0.8,并且每个UE 只允许在 6 个相邻的波束小区间移动。
GEO 卫星、UAV 中继和UE 的控制周期分别设为 150 个时隙, 30 个时隙和 1 个时隙。