这篇文章写得很冗余,但是我相信你如果真的看完,并且按照我的代码和逻辑进行分析,对您以后的数据预处理和命名实体识别都有帮助,只有真正对这些复杂的文本进行NLP处理后,您才能适应更多的真实环境,坚持!毕竟我写的时候也看了20多小时的视频,又写了20多个小时,别抱怨,加油~
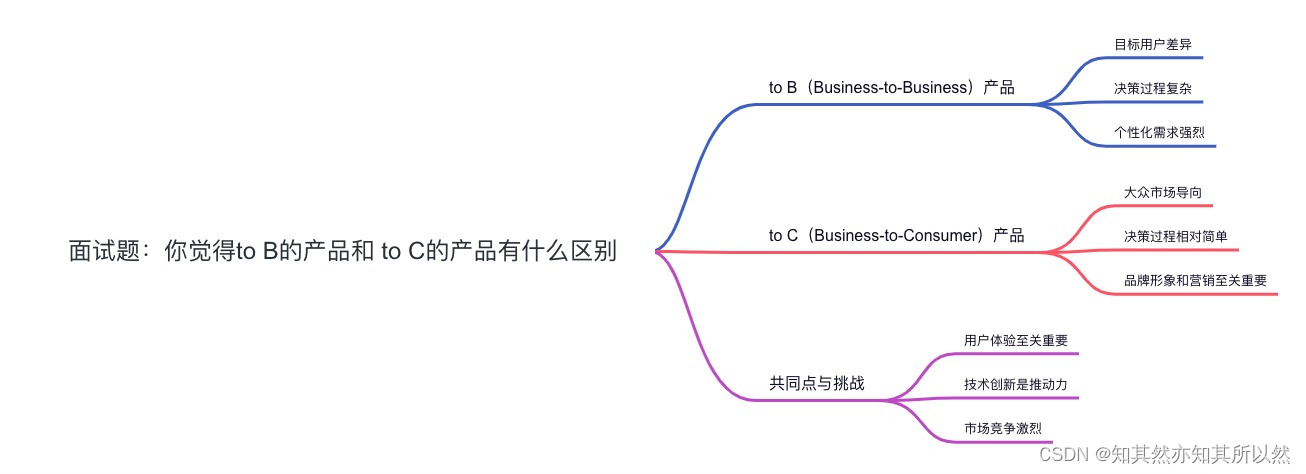
上一篇文章处理后的数据格式如下图所示,将一个个句子处理成了包含六元组的CSV文件,这篇文章将介绍BiLSTM-CRF模型搭建及训练、预测,最终实现医学命名实体识别。

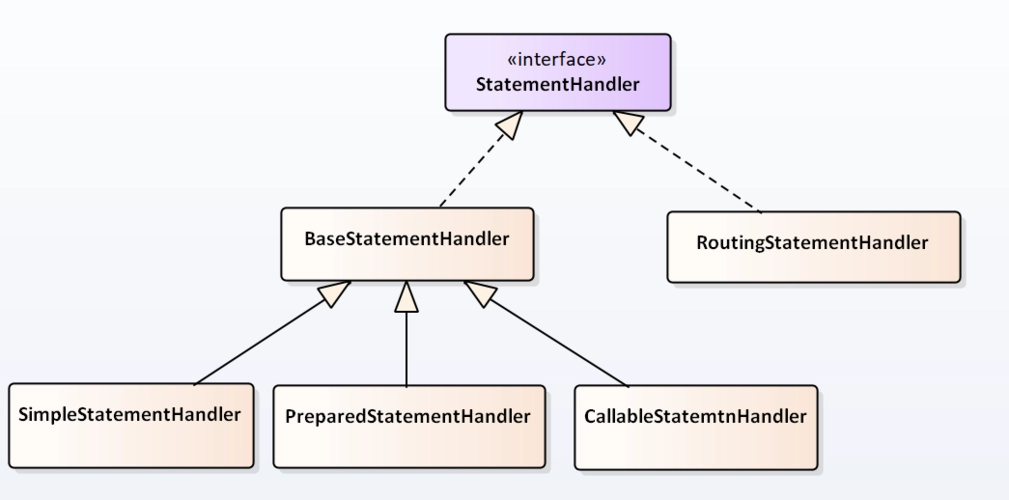
整个项目工程如下图所示:
这篇文章写得很冗余,但是我相信你如果真的看完,并且按照我的代码和逻辑进行分析,对您以后的数据预处理和命名实体识别都有帮助,只有真正对这些复杂的文本进行NLP处理后,您才能适应更多的真实环境,坚持!毕竟我写的时候也看了20多小时的视频,又写了20多个小时,别抱怨,加油~
上一篇文章处理后的数据格式如下图所示,将一个个句子处理成了包含六元组的CSV文件,这篇文章将介绍BiLSTM-CRF模型搭建及训练、预测,最终实现医学命名实体识别。
整个项目工程如下图所示:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1246171.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!