Laf 已成功上架 Sealos 模板市场,可通过 Laf 应用模板来一键部署!
这意味着 Laf 在私有化部署上的扩展性得到了极大的提升。
Sealos 作为一个功能强大的云操作系统,能够秒级创建多种高可用数据库,如 MySQL、PostgreSQL、MongoDB 和 Redis 等,也可以一键运行各种消息队列和微服务,甚至 GPU 集群上线后还可以跑各种 AI 大模型。
将 Laf 一键部署到 Sealos 中,我们就可以在 Laf 中直接通过内网调用 Sealos 提供的所有这些能力。无论用户需要什么样的后端支持,只需在 Sealos 上运行相应的服务即可。这种集成模式不仅提高了资源的利用效率,而且还提供了无缝的技术集成,使得 Laf 成为一个更加强大和多功能的 Serverless 平台,弥补了传统 Serverless 平台在后端能力方面的不足。
Sealos 强大的模板市场提供了丰富的应用生态,用户可以在模板市场中一键部署各种应用。本文以 Elasticsearch 为例,展示如何在 Laf 中调用 Sealos 模板市场中部署的 Elasticsearch 来搭建一个向量数据库,提供定制化知识库搜索能力。
背景知识
如果我们想往大模型里边注入知识,最先能想到的就是对大模型进行微调,大模型有很好的根据上文来回答问题的能力。
假设一个场景,我有个问题是:“请给我介绍一下万能青年旅店这支乐队 “(假设模型内部并没有存储万青的相关信息),然后我有个 100w 字的文档,里边包含了世界上所有乐队的介绍。如果模型对无限长的输入都有很好的理解能力,那么我可以设计这样一个输入 “以下是世界上所有乐队的介绍:[插入 100w 字的乐队简介文档],请根据上文给我介绍一下万青这支乐队”,让模型来回答我的问题。但模型支持的输入长度是很有限的,比如 ChatGPT 只支持 32K Token 长度的输入 (大约 50 页文本)。
实际上,如果想让大模型根据文档来回答问题,必须要精简在输入中文档内容的长度。一种做法是,我们可以把文档切成若干段,只将少量的和问题有关的文档片段拿出来,放到大模型的输入里。至此,”大模型外挂数据库 “的问题转换成了 “文本检索的问题” 了,目标是根据问题找出文档中和问题最相关的片段,这已经和大模型本身完全无关了。
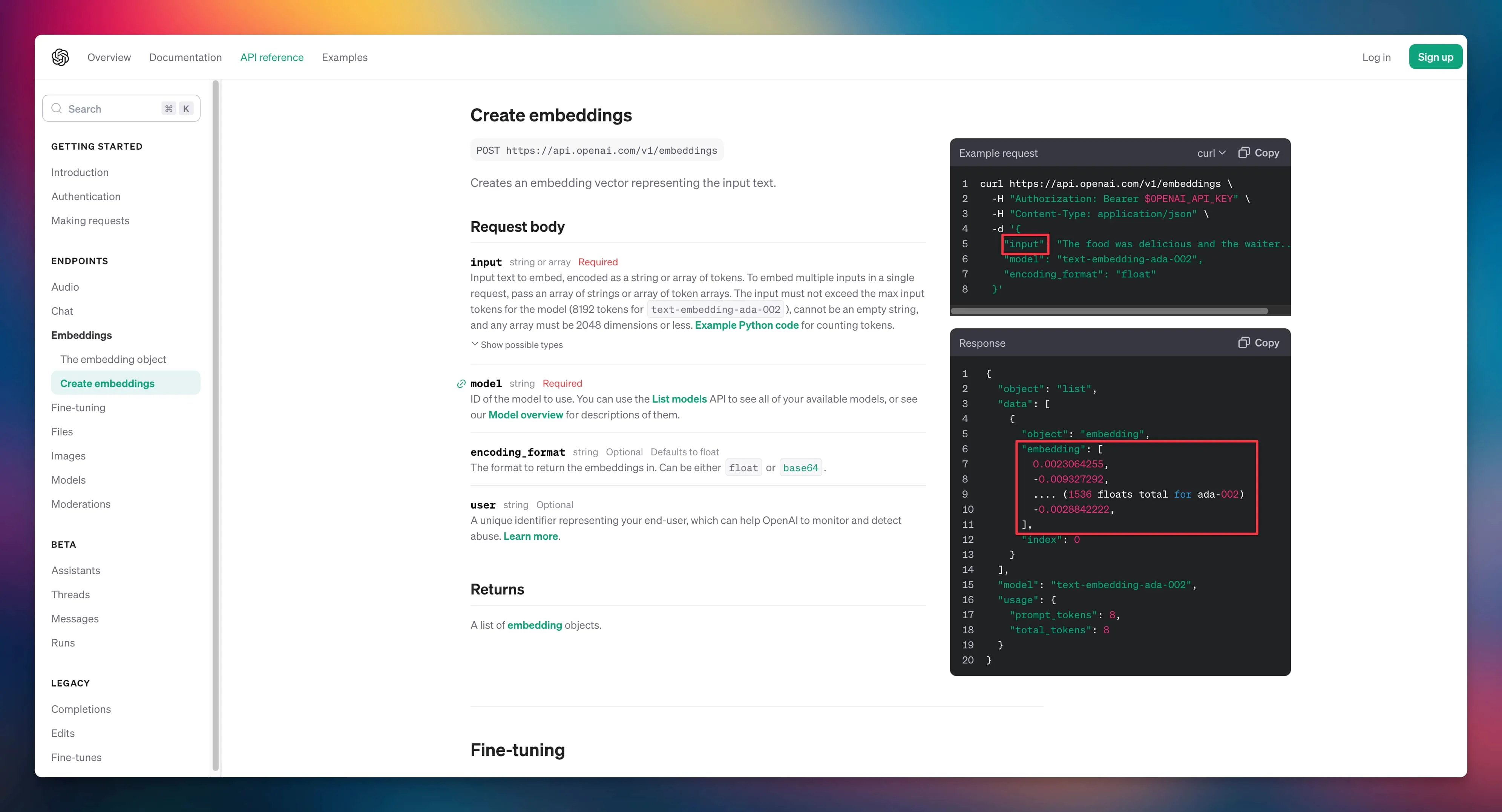
文本检索里边比较常用的是利用向量进行检索,我们可以把文档片段全部向量化 (通过语言模型,如 bert 等),然后存到向量数据库 (如 Annoy、FAISS、hnswlib 等) 里边,来了一个问题之后,也对问题语句进行向量话,以余弦相似度或点积等指标,计算在向量数据库中和问题向量最相似的 top k 个文档片段,作为上文输入到大模型中。
向量数据库都支持近似搜索功能,在牺牲向量检索准确度的情况下,提高检索速度。完整流程图如下所示:
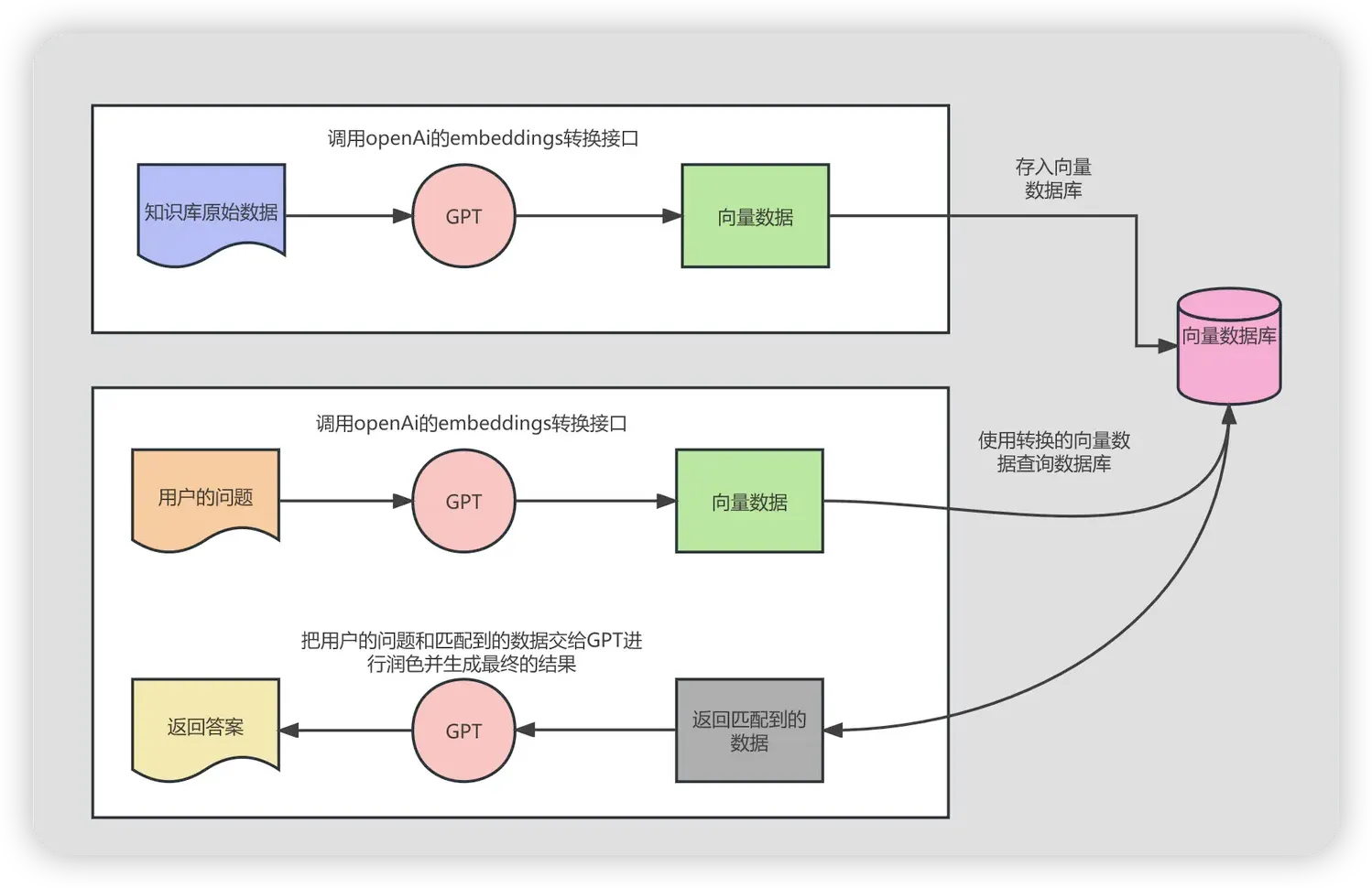
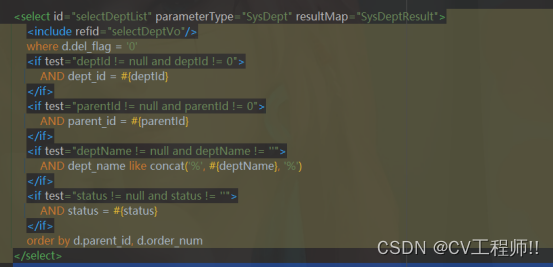
按照这个思路我们需要做的事情有两个,一个是把文档向量化,另一个是搭建一个向量数据库。文档向量化最简单的方法可以使用 openai 提供的转化接口将文档转化成向量数组,除此之外还可以通过 bert 模型。OpenAI 还给出了向量数据库参考选项,建议我们使用 cosin 相似度公式来求向量相似度:
$$\cos (\theta) = \frac {A.B} {|A| |B|} = \frac {\sum {i=1}^{n} A_i B_i} {\sqrt {\sum {i=1}^{n} A_i^2} \sqrt {\sum_ {i=1}^{n} B_i^2}}$$
如何在 Sealos 上快速部署向量数据库呢?从 OpenAI 的推荐上我们看到了里面有个 Elasticsearch 选项,那我们就用它了。
部署 Laf 与 Elasticsearch
首先我们需要打开 Sealos 公有云桌面:https://cloud.sealos.top
Sealos 是完全开源的,您也可以通过 Sealos 构建自己的私有云:https://sealos.run/self-hosting
然后进入 “模板市场”,通过 Laf 模板与 Elasticsearch 模板分别部署 Laf 和 Elasticsearch。
然后在 Laf 中新建一个应用,安装依赖 elastic/elasticsearch:
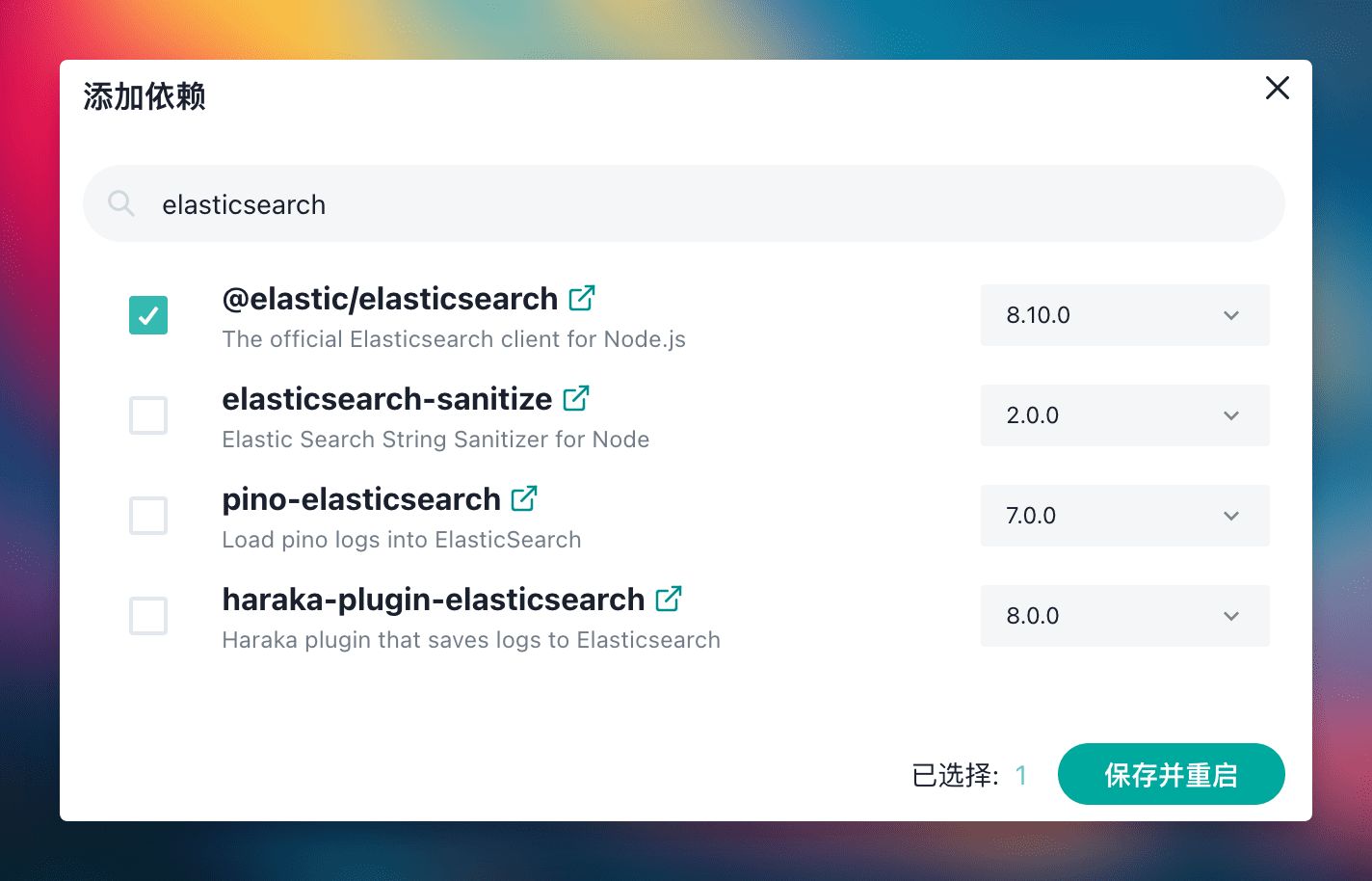
一旦应用创建完毕,您可以使用云函数代码来连接 Elasticsearch。在此示例中,我们直接插入了 10 条测试数据 (为了简化演示过程,我们直接使用了测试数据,并没有用 OpenAI 的接口去生成文档的向量数据)。
import cloud from '@lafjs/cloud'
const { Client } = require('@elastic/elasticsearch')
const ca = `-----BEGIN CERTIFICATE-----
MIIDITCCAgmgAwIBAgIQQKs5V2terYVNUrHt9K0CzTANBgkqhkiG9w0BAQsFADAb
MRkwFwYDVQQDExBlbGFzdGljc2VhcmNoLWNhMB4XDTIzMTEyMjA3MDcxOFoXDTI0
MTEyMTA3MDcxOFowGzEZMBcGA1UEAxMQZWxhc3RpY3NlYXJjaC1jYTCCASIwDQYJ
KoZIhvcNAQEBBQADggEPADCCAQoCggEBAPYyHrFgyoD3Pkkc/ekXhHGKi+qKPBbp
afPuGImQfTtkGlzhaHJ7Iy3MZojP/iyt3FTY+LvxODsbkgIrQJWwiG2s26rw03Zd
lphf7RULRa9Z/TKt0jxHV9M419ge2zRij6Al3uUHCP2FxjVMgYjuFisKwNalQfUE
spCTq9lWNp4bKP32GieEBQKeNRD8ElNBJkInIA2aTyH2TIhyICK0f5GjH52rxKeV
wrE/BHq8zomHRVtTM67KHoXc9RJgYNICfooeDHvi/f9f+pWrX881rmbNWXGcxu2u
GQLqCAkqpIpUwn5HAoSvUYHmxwgaDC866fjsgxv/6DMDJuGPmfsBqQMCAwEAAaNh
MF8wDgYDVR0PAQH/BAQDAgKkMB0GA1UdJQQWMBQGCCsGAQUFBwMBBggrBgEFBQcD
AjAPBgNVHRMBAf8EBTADAQH/MB0GA1UdDgQWBBQaGk9O4hQFjJPU6ay8qqU8CNug
uzANBgkqhkiG9w0BAQsFAAOCAQEAfZUesinfp1jeSqfHBSPHOgZ1q/v8xoClEPRl
wzh8sbL14iuuSb190J8zQefvzxC7ip4kVCVTW52fBZNyoMpvj0cXKWRGFmz3yHIs
TNdwOy15mQRQGbOTDBkQ528SbrmrWF4W7kDMoWs0t02UIlSfBWDjJrVharRR9QuF
cGjoS59TCAFcHHUsPO3lcUT1TCq/W4xnds3zBxJiGeIdmDqE6DbS78YfwP9rhTx0
oxcQwpKaOj8vxQNQxNbJRmWgffx0PgUzFPni/N5FgFQQXDPG4i0gMciekHWz8VRM
pp2z1uD1lVdDa/83w/IZCQOqDU7cRjDosg+gaAefFGNMHVbPBw==
-----END CERTIFICATE-----
`
export default async function (ctx: FunctionContext) {
const client = new Client({
node: 'https://elasticsearch-master.ns-wz9g09tc.svc.cluster.local:9200',
auth: {
username: 'elastic',
password: 'zhtvadgdinhkyirozeznxlxd'
},
tls: {
ca: ca,
rejectUnauthorized: false
}
})
const health = await client.cluster.health()
console.log(health)
// 删除已存在的索引(如果有)
await client.indices.delete({
index: 'vectors',
ignore_unavailable: true
})
// 创建一个新的向量索引
await client.indices.create({
index: 'vectors',
body: {
mappings: {
properties: {
embedding: {
type: 'dense_vector',
// 向量列表的长度
dims: 3,
index:true,
// 字段索引,consin函数求相似度
similarity:'cosine'
},
text: {
type: 'text'
}
}
}
}
})
// 测试数据
const documents = [
{ embedding: [0.5, 10, 6], text: 'text1' },
{ embedding: [-0.5, 10, 10], text: 'text2' },
{ embedding: [1.0, 5, 8], text: 'text3' },
{ embedding: [-0.2, 8, 12], text: 'text4' },
{ embedding: [0.8, 12, 4], text: 'text5' },
{ embedding: [-0.7, 6, 14], text: 'text6' },
{ embedding: [0.3, 14, 2], text: 'text7' },
{ embedding: [-0.4, 16, 8], text: 'text8' },
{ embedding: [0.6, 8, 10], text: 'text9' },
{ embedding: [-0.6, 12, 6], text: 'text10' }
];
// 插入测试数据
for (const doc of documents) {
await client.index({
index: 'vectors',
document: doc,
refresh: true
});
}
// Define the vector to search for
const query_vector = [0.2, 12, 5]
const body = await client.knnSearch({
index: 'vectors',
knn: {
field: 'embedding',
query_vector: query_vector,
k: 3,
num_candidates: 5
},
_source: ["text"]
});
// 输出搜索结果
console.log(JSON.stringify(body, null, 2))
return { data: 'hi, laf' }
}通过 cosin 相似度搜索,我们找到了与向量 [0.2, 12, 5] 最相似的三条向量数据。这些数据的文本分别是 text8、text5 和 text10。

Elasticsearch 内网调用地址如下:
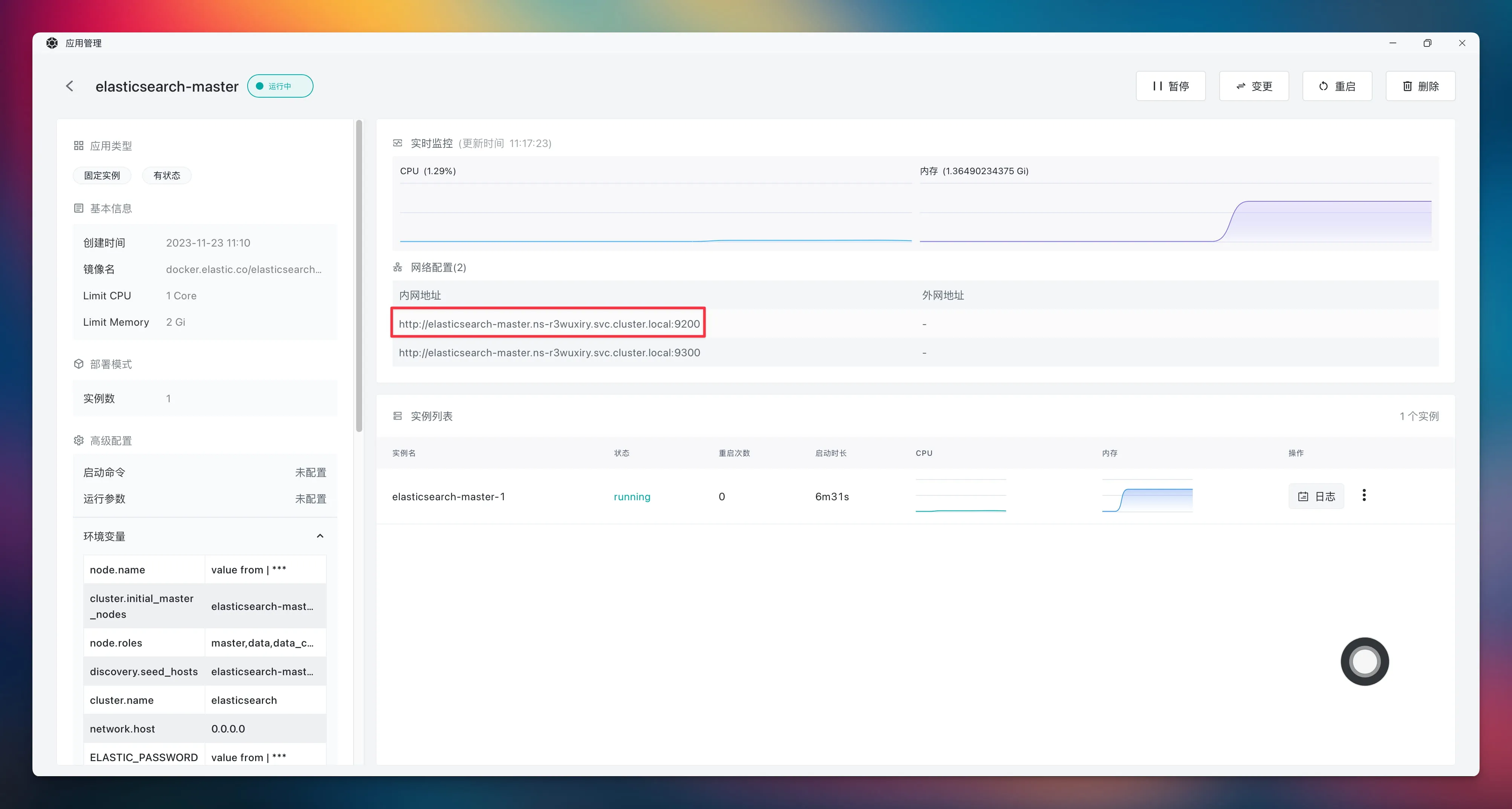
ca 的值就是 Elasticsearch 的证书,Elasticsearch 的证书可以通过命令行来获取,先在 Sealos 桌面中打开 “终端” App,然后执行以下命令获取证书:
kubectl get secret elasticsearch-master-certs -o jsonpath="{.data.ca\.crt}"|base64 -dElasticsearch 的用户名密码可以通过以下命令获取:
$ kubectl get secret elasticsearch-master-credentials -o jsonpath="{.data.username}"|base64 -d && echo
elastic
$ kubectl get secret elasticsearch-master-credentials -o jsonpath="{.data.password}"|base64 -d && echo
xurcwgjxpfztmgjquufyyiml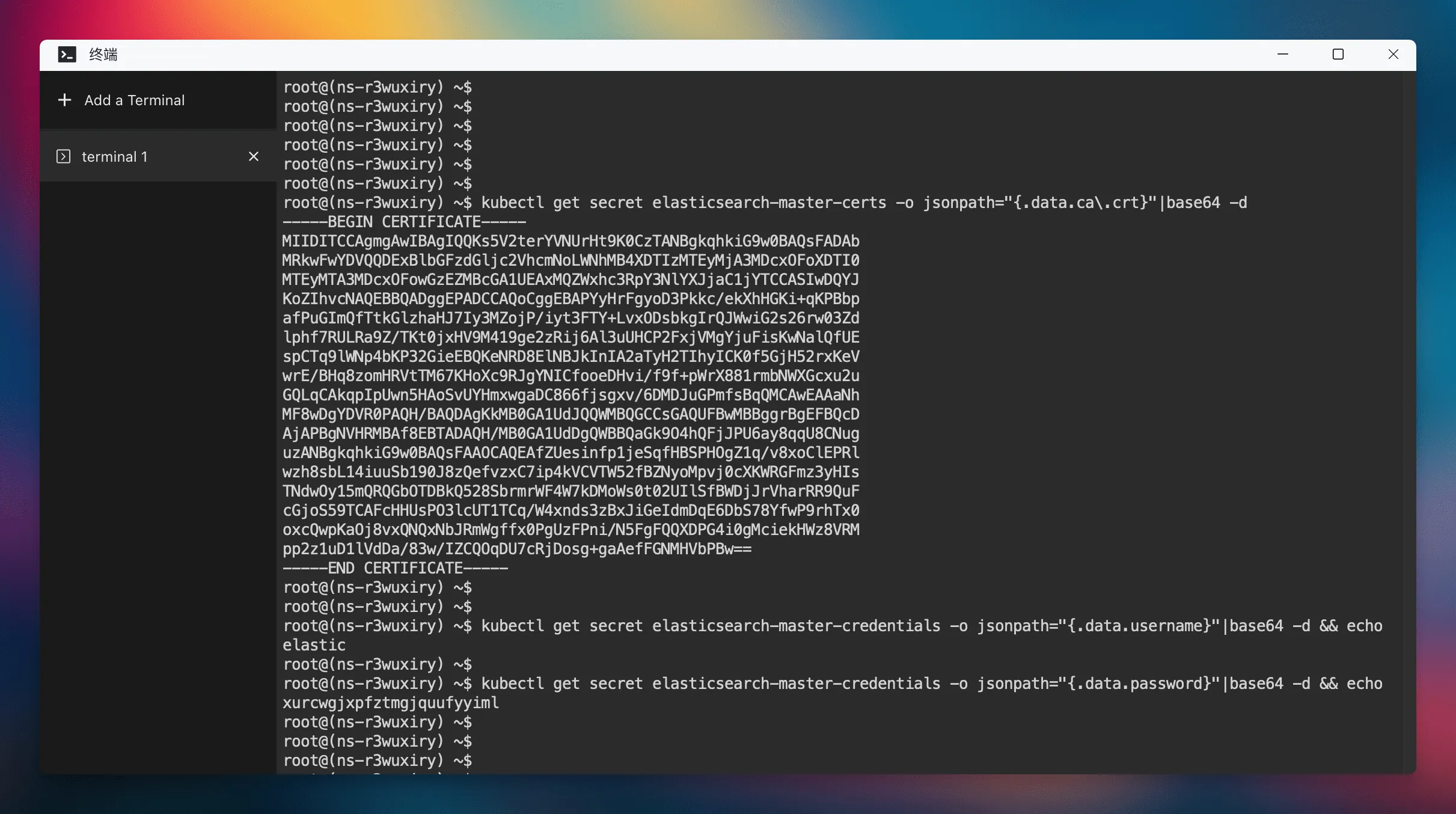
至此简单的 Demo 已经完成了,后续我们需要做的就是持续地向我们的向量数据库中添加更多文档的向量化数据,通过这种方式,我们可以构建起一个功能强大的知识库。当用户提问时,先将用户问题转换成向量数据,然后在向量数据库中找到最相似的文档,将文档作为上文输入到大模型中,最后大模型输出答案。我们的明星项目 FastGPT 就是这样做的哦。另外不难看出 Bing Chat 也是异曲同工。
总结
通过将 Laf 集成到 Sealos 云操作系统中,可以更高效地利用云操作系统的资源。用户可以直接在 Laf 中调用 Sealos 提供的各种数据库和服务,如 MySQL、PostgreSQL、MongoDB 和 Redis 等,以及消息队列和微服务,实现资源的最大化利用。这种集成方式使得 Laf 成为了一个功能更加全面的 Serverless 平台。尤其是在后端能力方面,这种集成提供了一个无缝的解决方案,弥补了传统 Serverless 平台的不足。