△Hollis, 一个对Coding有着独特追求的人△

这是Hollis的第 435 篇原创分享
作者 l Hollis
来源 l Hollis(ID:hollischuang)

Apache POI,是一个非常流行的文档处理工具,通常大家会选择用它来处理Excel文件。但是在实际使用的时候,经常会遇到内存溢出的情况,那么,为啥他会导致内存溢出呢?
Excel并没看到的那么小
我们通常见到的xlsx文件,其实是一个个压缩文件。它们把若干个XML格式的纯文本文件压缩在一起,Excel就是读取这些压缩文件的信息,最后展现出一个完全图形化的电子表格。
所以,如果我们把xlsx文件的后缀更改为.zip或.rar,再进行解压缩,就能提取出构成Excel的核心源码文件。解压后会发现解压后的文件中有3个文件夹和1个XML格式文件:

_rels 文件夹 看里面数据像是一些基础的配置信息,比如 workbook 文件的位置等信息,一般不会去动它.
docProps 文件夹下重要的文件是一个 app.xml,这里面主要存放了 sheet 的信息,如果想添加或编辑 sheet 需要改这个文件.其他文件都是一些基础信息的数据,比如文件所有者,创建时间等.
xl 文件夹是最重要的一个文件夹,里面存放了 Sheet 中的数据,行和列的格式,单元格的格式,sheet 的配置信息等等信息.
所以,实际上我们处理的xlsx文件实际上是一个经过高度压缩的文件格式,背后是有好多文件支持的。所以,我们看到的一个文件可能只有2M,但是实际上这个文件未压缩情况下可能要比这大得多。
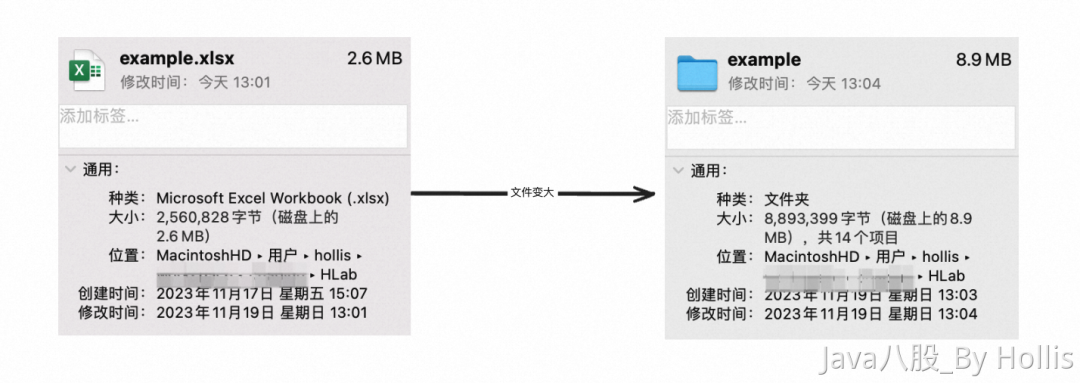
也就是说,POI在处理的时候,处理的实际上并不只是我们看到的文件大小,实际上他的大小大好几倍。(本文节选自我的《java面试宝典》)
这是为什么明明我们处理的文件只有100多兆,但是实际却可能占用1G内存的其中一个原因。当然这只是其中一个原因,还有一个原因,我们就需要深入到POI的源码中来看了。
POI溢出原理
我们拿POI的文件读取来举例,一般来说文件读取出现内存溢出的情况更多一些。以下是一个POI文件导出的代码示例:
import org.apache.poi.ss.usermodel.*;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
public class ExcelReadTest {
public static void main(String[] args) {
// 指定要读取的文件路径
String filename = "example.xlsx";
try (FileInputStream fileInputStream = new FileInputStream(new File(filename))) {
// 创建工作簿对象
Workbook workbook = new XSSFWorkbook(fileInputStream);
// 获取第一个工作表
Sheet sheet = workbook.getSheetAt(0);
// 遍历所有行
for (Row row : sheet) {
// 遍历所有单元格
for (Cell cell : row) {
// 根据不同数据类型处理数据
switch (cell.getCellType()) {
case STRING:
System.out.print(cell.getStringCellValue() + "\t");
break;
case NUMERIC:
if (DateUtil.isCellDateFormatted(cell)) {
System.out.print(cell.getDateCellValue() + "\t");
} else {
System.out.print(cell.getNumericCellValue() + "\t");
}
break;
case BOOLEAN:
System.out.print(cell.getBooleanCellValue() + "\t");
break;
case FORMULA:
System.out.print(cell.getCellFormula() + "\t");
break;
default:
System.out.print(" ");
}
}
System.out.println();
}
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}这里面用到了一个关键的XSSFWorkbook类:
public XSSFWorkbook(InputStream is) throws IOException {
this(PackageHelper.open(is));
}
public static OPCPackage open(InputStream is) throws IOException {
try {
return OPCPackage.open(is);
} catch (InvalidFormatException e){
throw new POIXMLException(e);
}
}最终会调用到OPCPackage.open方法,看看这个方法是咋实现的:
/**
* Open a package.
*
* Note - uses quite a bit more memory than {@link #open(String)}, which
* doesn't need to hold the whole zip file in memory, and can take advantage
* of native methods
*
* @param in
* The InputStream to read the package from
* @return A PackageBase object
*
* @throws InvalidFormatException
* Throws if the specified file exist and is not valid.
* @throws IOException If reading the stream fails
*/
public static OPCPackage open(InputStream in) throws InvalidFormatException,
IOException {
OPCPackage pack = new ZipPackage(in, PackageAccess.READ_WRITE);
try {
if (pack.partList == null) {
pack.getParts();
}
} catch (InvalidFormatException | RuntimeException e) {
IOUtils.closeQuietly(pack);
throw e;
}
return pack;
}这行代码的注释中说了:这个方法会把整个压缩文件都加载到内存中。也就是把整个 Excel 文档加载到内存中,可想而知,这在处理大型文件时是肯定会导致导致内存溢出的。(本文节选自我的《java面试宝典》,里面有800多道面试常考题目)
也就是说我们使用的XSSFWorkbook(包括HSSFWorkbook也同理)在处理Excel的过程中会将整个Excel都加载到内存中,在文件比较大的时候就会导致内存溢出。
如何解决溢出问题?
在POI中,提供了SXSSFWorkbook,通过将部分数据写入磁盘上的临时文件来减少内存占用。但是SXSSFWorkbook只能用于文件写入,但是文件读取还是不行的,就像我们前面分析过的,Excel的文件读取还是会存在内存溢出的问题的。
那如果要解决这个问题,可以考虑使用EasyExcel!(本文节选自我的《java面试宝典》,里面有800多道面试常考题目)
关于使用XSSFWorkbook和EasyExcel的文件读取,我这里也做了个内存占用的对比,读取一个27.3 MB的文件:
package excel.read;
import org.apache.poi.ss.usermodel.*;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
public class XSSFExcelReadTest {
public static void main(String[] args) {
// 指定要读取的文件路径
String filename = "example.xlsx";
try (FileInputStream fileInputStream = new FileInputStream(new File(filename))) {
// 创建工作簿对象
Workbook workbook = new XSSFWorkbook(fileInputStream);
// 获取第一个工作表
Sheet sheet = workbook.getSheetAt(0);
// 遍历所有行
for (Row row : sheet) {
// 遍历所有单元格
for (Cell cell : row) {
// 根据不同数据类型处理数据
switch (cell.getCellType()) {
case STRING:
System.out.print(cell.getStringCellValue() + "\t");
break;
case NUMERIC:
if (DateUtil.isCellDateFormatted(cell)) {
System.out.print(cell.getDateCellValue() + "\t");
} else {
System.out.print(cell.getNumericCellValue() + "\t");
}
break;
case BOOLEAN:
System.out.print(cell.getBooleanCellValue() + "\t");
break;
case FORMULA:
System.out.print(cell.getCellFormula() + "\t");
break;
default:
System.out.print(" ");
}
}
System.out.println();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}使用Arthas查看内存占用情况:

占用内存在1000+M。
改成使用EasyExcel同样读取同一份文件:
package excel.read;
import com.alibaba.excel.EasyExcel;
import com.alibaba.excel.context.AnalysisContext;
import com.alibaba.excel.read.listener.ReadListener;
public class EasyExcelReadTest {
public static void main(String[] args) {
// 指定要读取的文件路径
String filename = "example.xlsx";
EasyExcel.read(filename, new PrintDataListener()).sheet().doRead();
}
}
// 监听器,用于处理读取到的数据
class PrintDataListener implements ReadListener<Object> {
@Override
public void invoke(Object data, AnalysisContext context) {
// 处理每一行的数据
System.out.println(data);
}
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
// 所有数据解析完成后的操作
}
@Override
public void onException(Exception exception, AnalysisContext context) throws Exception {
// 处理读取过程中的异常
}
}同样使用Arthas查看内存占用情况:

内存占用只有不到100M。
以上,可以看出,EasyExcel在文件读取时内存还是比较节省的。关于EasyExcel的实现原理,为啥能更加节省内存,以及为啥POI的SXSSFWorkbook占用内存更小?如何排查POI导致内存溢出的问题,如何实现异步文件下载等内容,在我的《Java面试宝典》中正在连载更新中。目前已经有6篇干货内容了:
本文也是节选自我的《Java面试宝典》,里面的所有讲解都是有原理、源码、代码等。尽量做到让你看完都能理解。而不是硬背面试题。
详情请戳:80W,太炸裂了!