1.概要
很多时候需要用到行专列的方式做数据分析。比如对通讯数据的采集
数据采集结果如下:
| 变量 | 值 | 采集周期 |
| 1 | 3 | 1 |
| 2 | 5 | 1 |
| 1 | 3 | 2 |
| 2 | 7 | 2 |
我想要看的结果
| 变量1 | 变量2 | 采集周期 |
| 3 | 5 | 1 |
| 3 | 7 | 2 |
就是我想看到相关数据的周期变化情况。
2.试验
2.1创建数据如下(表名 tb5)
| ID | 数据1(v1) | 数据2(v2) | 周期(m) |
| 1 | 1 | 11 | 1 |
| 2 | 2 | 22 | 1 |
| 3 | 3 | 33 | 2 |
| 4 | 4 | 44 | 2 |
SELECT GROUP_CONCAT(v1) FROM db1.tb5
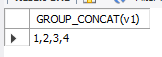
从结果上看,是把所有的数据都变成列了。
SELECT GROUP_CONCAT(v1) FROM db1.tb5 group by m
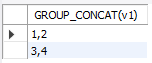
从结果上看,是把分组后的数据都放到了一行。
SELECT GROUP_CONCAT(v1,v2) FROM db1.tb5 group by m
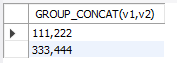
有点蒙 是 111,222 是 1 11,2 22 的意思吗
SELECT GROUP_CONCAT(v1,"-",v2) FROM db1.tb5 group by m
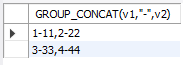
这下明白了,GROUP_CONCAT只是把不同行的数据默认用,连接,只有不同的变量,中间不加任何连接符,你想连接,你可以自己加。
| 数据 | 每组第一行数 | 每组第二行数据 | 分组 | ||
| 数据1 | 数据2 | 数据1 | 数据2 | ||
| 1-11,2-22 | 1 | 11 | 1 | 22 | 第一组(m:1) |
| 3-33,4-44 | 3 | 33 | 4 | 44 | 第一组(m:2) |
3.理解总结
对于GROUP_CONCAT,如果后面没有分组,会把全部行的数据显示成一列,这里的列是用,号隔开的也算列的意思。如果有分组,会把分组后的全部行转换成列。
对于每以行中的不同数据,默认不加分隔符合,需要你自己添加。