线程其实对于操作系统来说是宝贵的资源,java层面的线程其实本质还是依赖于操作系统内核的线程进行处理任务,如果频繁的创建、使用、销毁线程,那么势必会非常浪费资源以及性能不高,所以池化技术(数据库连接池、线程池)在性能优化的时候是重中之重。
我们来猜想以下线程池的功能,因为如果是一个线程一个线程执行任务,那么我们需要进行对线程的管理、以及对于任务的分配,在执行过程中,本质还是利用多个线程通过从任务队列中获取任务,进行执行。通过这种方式,当任务来临时可以直接使用线程,达到复用。
demo
ThreadPoolExecutor pool = new ThreadPoolExecutor(5, 10, 1000, TimeUnit.MILLISECONDS, new LinkedBlockingDeque<>(15),
new ThreadFactory() {
private final AtomicInteger atomicInteger = new AtomicInteger(1);
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "pool-" + atomicInteger.getAndIncrement());
}
}, new ThreadPoolExecutor.DiscardPolicy());
//执行
pool.execute(new Runnable() {
@Override
public void run() {
System.out.println("qxlxi");
}
});
//关闭
pool.shutdown();
boolean terminated = false;
while (!terminated) {
pool.awaitTermination(100,TimeUnit.SECONDS);
}
System.out.println("pool is shutdowm.");
线程池的创建
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
corePoolSize :线程池中的常驻核心线程数 < core: >core : 缓冲队列,超过缓冲队列,就直接新建。核心线程不回销毁,而非核心线程超过一定时间没有使用,就会销毁。
maxmumPoolSize : 整个线程池的核心线程和非核心线程数, maxmumPoolSize - corePoolSize 就是非核心线程数。
keepAliveTime & unit : 非核心线程数销毁的时间,可以自定义
workQueue :当有新的任务请求线程时,超过核心线程数,那么就会将任务先存储到任务队列中,等待线程处理。是一个阻塞队列。
有Array、Linked、Priority、Synchron等。
handler : 当没有空闲线程进行处理任务的时候,超过来最大线程数,那么就需要执行线程池的拒绝策略。可以通过hanlder进行设置。只针对有届阻塞队列 可以看到通过一个抽象的接口,然后实现不同的策略来进行执行拒绝策略,当然我们也可以实现自己的策略拒绝类。
public interface RejectedExecutionHandler {
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}
DiscardPolicy 什么也不做。
public static class DiscardPolicy implements RejectedExecutionHandler {
public DiscardPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}
AbortPolicy 直接返回异常。不执行
public static class AbortPolicy implements RejectedExecutionHandler {
public AbortPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}
CallerRunsPolicy 策略是 任务提交者来执行这个任务。
public static class CallerRunsPolicy implements RejectedExecutionHandler {
public CallerRunsPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
}
DiscardOldestPolicy 策略是:判断线程是否关闭状态,没有关闭的化,直接删除workQueue中的一个任务,然后将其加入其中。
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
public DiscardOldestPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
}
threadFactory
线程创建ThreadPoolExecutor对象时,传入ThreadFactory工厂类对象,那么线程池中的对象均会通过工厂类的new Thread()方法来实现。可以通过定义new Thread()对象来创建,添加一些信息。当然,我们还可以通过 newFixedThreadPool、newCachedThreadPool、newSingleThreadExecutor等方式。
线程池的执行
线程池执行任务的时候,只需要将执行的任务封装成Runnable对象,然后将Runnable对象传递给execute()函数,线程池在创建的时候,并不会提前创建,而是当有任务的时候才会创建。
1.核心线程是否已满,没有满 直接创建
2.核心线程已满,则检查等待队列是否已满,未满,将任务放入队列中
3.等待队列已满,检查非核心线程,非核心线程未满,常见非核心线程
4.核心线程、等待队列、非核心线程都满了,执行对应的拒绝策略
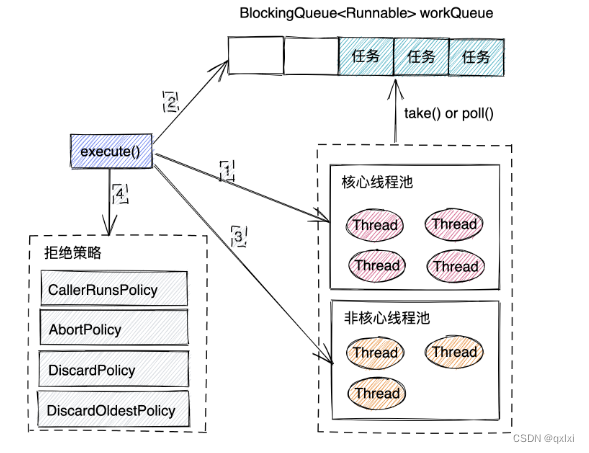
整体的流程,其实是创建核心线程之后,就会从wrokQueue中获取任务通过take()函数进行执行,如果没有任务的化就会阻塞等待,非核心线程创建之后,会调用workQueue()的poll(),不同从workQueue()获取任务,poll()函数是阻塞函数,根take()函数不同的时,poll()函数可以设置阻塞的超时时间,poll()的超时时间超过非核心线程的等待时间,那么就会超时返回,执行线程销毁。
关闭
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
advanceRunState(SHUTDOWN);
interruptIdleWorkers();
onShutdown(); // hook for ScheduledThreadPoolExecutor
} finally {
mainLock.unlock();
}
tryTerminate();
}
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
advanceRunState(STOP);
interruptWorkers();
tasks = drainQueue();
} finally {
mainLock.unlock();
}
tryTerminate();
return tasks;
}
线程池关闭有两个方法,一种是shutdown() 以及shutdownNow()。前者是通过优雅的方式,会执行完正在执行以及等待队列中的任务,后者则是通过直接将处理中,以及清空等待队列,并向所有线程发送中断请求。shutdownNow的返回值是等得队列中未被执行的任务。需要注意的是返回时,有可能线程池内还有线程在执行任务,需要等所有线程都执行完毕之后,调用awaitTermination函数阻塞等待。
配置
在实际的应用开发中,我们如何进行合理配置线程池的大小呢,一般通俗来说的化,IO密集型和计算密集型,计算密集型设置未CPU核心相当就可以,IO密集型因为大部分时间都在IO阻塞上,所以将线程池适当开大点。除此之外就是IO+计算相结合的方式。
具体的方式其实就需要统计花在IO和计算上的占比,pool_size * 核数 = (cpu_time + io_time) / cpu_time。
比如cpu_time 占用 1/3 io占用 2/3 那么就是3.
当然在实际的层面来说,还需要考虑别的地方有没有瓶颈,比如数据库连接池,文件句柄等。也就是木桶效应。根据最短的进行合理评估,在实际中,就遇到DB 连接池配置失效,当时吞吐量上不去,最后发现后才解决。
小结
参数说明:
corePoolSize:指定了线程池中的线程数量。
maximumPoolSize:指定了线程池中的最大线程数量。
keepAliveTime:当前线程池数量超过corePoolSize时,多余的空闲线程的存活时间,即多次时间内会被销毁。CachedThreadPool是60秒。
unit: keepAliveTime的单位。
workQueue:
blockQueue的配置。新加入任务的时候,当线程池中的可用线程小于第一个参数core线程数量,那么直接new一个线程或者用空闲的可用线程来执行任务。不用进行排队。当线程池中core线程数量都处于执行中,那么就把任务加入到blockqueue中进行排队等待。当排队队列满了,那么新new一个线程,执行最新加入到queue中的任务。如果线程池中的线程数量超过了最大线程数量,那么这个时候将拒绝新加入的任务。如果最大线程数都满了,队列中也满了,这个时候,还有新任务请求进来,那么会报错,默认是抛出RejectedException。
blockqueue有三种策略,
第一种是配置一个SynchronousQueue,这种queue其实不是真正的queue,他根本就不会进行排队,如果core线程数量满了,那么新来一个任务,会直接new一个线程,而不是进入排队!直到池中的线程数量超过最大线程数,开始拒绝新加入的任务,JDK的CacheThreadLocal就是使用的这个工作队列,配置的最大线程数是Integer.MAXVALUE。
第二种是配置一个LinkedBlockingQueue,这种queue本身是没有大小的,也就是说,这种queue永远也满不了,可以无限排,这个时候最大线程数就没有意义了,因为queue永远不满,所以,这种配置就相当于是一个固定的大小为core线程数的线程池,JDK的FixedThreadPool就是采用的这个
第三种策略是用ArrayBlockingQueue,我们可以给这个queue指定大小。比如200啊,300啊,那么,只要queue大小满了,就会产生新的线程来处理queue的头部任务。如果池中超过了最大线程数,那么会拒绝任务的加入。
threadFactory:线程工厂,用于创建线程,一般用默认的即可。如果默认的不能满足我们的要求,我们可以使用自定义的线程工厂。
RejectedExceptionHandler:拒绝策略,当BlockQueue都满了无法接收新的任务了,就会触发RejectedExceptionHandler的方法了,这是一个策略模式的很好的例子。JDK提供了几种现成的拒绝策略,默认的拒绝策略是AbortPolicy,抛出RejectedException,这是一个运行时的异常,但是线程池执行器依旧可以继续工作,再次提交新的任务的时候,可能又会抛出RejectedException。CallerRunsPolicy,这个策略是在调用者的线程中运行被抛弃的任务,相当于在线程池submit任务的时候,在调用者线程中执行runnable,显然,这个策略很糟糕;DiscardoldestPolicy,这个策略是将队列中最老的挤出去抛弃掉,然后再次提交该任务;DiscardPolicy,直接丢弃无法处理的任务,不做任何处理。一般来说,默认的拒绝策略是最好的,但是如果我们还想要自定义的拒绝策略,我们可以自己实现一个RejectedExceptionHandler策略。