目录
一、前言
二、标记阶段:引用计数算法
三、标记阶段:可达性分析算法
(一)基本思路
(二)GC Roots对象
四、对象的finalization机制
五、MAT与JProfiler的GC Roots溯源
六、清除阶段:标记-清除算法Mark-Sweep
七、清除阶段:复制算法Copying
八、清除阶段:标记-整理算法Mark-Compact
九、对比三种算法
十、分代收集算法
十一、增量收集算法、分区算法
一、前言
对于Java开发人员而言,自动内存管理就像是一个黑匣子,如果过度依赖于“自动”,那么将会是一场灾难,最严重的莫过于弱化Java人员在程序出现内存溢出时定位问题和解决问题的能力。
所以了解JVM的自动内存分配和内存回收原理显得非常重要,在遇见OOM的时候才能快速的根据错误异常日志定位问题和解决问题。
当需要排查各种内存溢出,内存泄漏问题时,当垃圾收集成为系统达到更高并发量的瓶颈时,我们必须对这些“自动化”的技术实施必要的监控和调节。
垃圾回收器可以对年轻代和老年代进行回收,甚至是全堆和方法区的回收,其中,Java堆时垃圾收集器的工作重点
从次数上讲:频繁手机Young区,较少收集Old区,基本不动方法区
那么什么是垃圾?
垃圾是指运行程序中没有任何指针指向的对象,这个对象就是需要被回收的垃圾
二、标记阶段:引用计数算法
对每个对象保存一个整型的引用计数器属性,用于记录被对象引用的情况。被对象引用了就+1,引用失效就-1,0表示不可能再被使用,可进行回收
优点:实现简单,垃圾便于辨识,判断效率高,回收没有延迟性
缺点:
- 需要单独的字段存储计数器,增加了存储空间的开销
- 每次赋值需要更新计数器,伴随加减法操作,增加了时间开销
- 无法处理循环引用的情况,致命缺陷,导致JAVA的垃圾回收器中没有使用这类算法
引用计数算法,是很多语言的资源回收选择,例如python,它更是同时支持引用计数和垃圾回收机制,python如何解决循环引用
- 手动解除
- 使用弱引用,weakref,python提供的标准库,旨在解决循环引用
三、标记阶段:可达性分析算法
(一)基本思路
可达性分析算法是以根对象(GCRoots)为起始点,按照从上到下的方式搜索被根对象集合所连接的目标对象是否可达
使用可达性分析算法后,内存中存活的对象都被被根对象集合直接或间接连接着,搜索所走过的路径称为引用链。如果目标对象没有任何引用链相连,则是不可达的,意味着该对象已经死亡,可以标记为垃圾对象。
在可达性分析算法中,只有能够被根对象集合直接或者间接连接的对象才是存活的对象
(二)GC Roots对象
根对象(GC Roots)包括以下几种:
- 虚拟机栈中引用的对象,比如:各个线程被调用的方法中使用到的参数、局部变量
- 本地方法栈内JNI,引用的对象
- 方法区中静态属性引用的对象,比如:java类的引用类型静态变量
- 方法区中常量引用的对象,比如:字符串常量池里的引用
- 所有被同步锁synchronized持有的对象
- Java虚拟机内部的引用,比如:基本数据类型对应的class对象,一些常驻的异常对象,如nullpointerException,OOMerror,系统类加载器
- 反映java虚拟机内部情况的JMXBean,JVMTI中注册的回调,本地代码缓存等
- 除了固定的GC Roots集合之外,根据用户选择的垃圾收集器以及当前回收的内存区域不同,还可以有其他对象临时性的加入,共同构成完整GCRoots集合,比如分代收集和局部回收(比如专门针对新生代的回收,那么其他非新生代 对象比如老年代也应该考虑作为root对象。因为新生代中的某些对象有可能被老年代的对象引用。)
如果需要使用可达性分析算法来判断内存是否可回收,那么分析工作必须在一个能保障一致性的快照中进行。这点不满足的话,分析结果的准确性就无法保证。
这也是GC进行时必须STW的一个重要原因,即使是号称几乎不会发生停顿的CMS收集器中,枚举根节点也是必须要停顿的。
四、对象的finalization机制
Java语言提供了对象终止finaliztion机制来允许开发人员提供对象被销毁之前的自定义处理逻辑。当垃圾回收器发现没有引用指向一个对象,即垃圾回收此对象之前,总会先调用这个对象的finalize()方法。
finalize()方法允许在子类中被重写,用于在对象被回收时进行资源释放,通常在这个方法中进行一些资源释放和清理的工作,比如关闭文件,套接字和数据库链接等
对象的三种状态:
- 可触及的:从根节点开始,可以到达这个对象
- 可复活的:对象的所有引用都被释放了,但是对象有可能在finalize()中复活
- 不可触及的:对象的finalize()被调用,并且没有复活,那么就会进入不可触及状态。不可触及的对象不可能被复活,因为finalize()只会被调用一次
- 只有对象再不可触及时才可以被回收
判断一个对象ObjA是否可以被回收,至少需要经历两次标记过程
- 1、如果对象到GCRoots没有引用链,则进行第一次标记
- 2、进行筛选,判断此对象是否有必要执行finalize()方法
- 如果对象A没有重写finalize方法,或者finalize方法已经被虚拟机调用过,则虚拟机视为没有必要执行,对象A被判定为不可触及的
- 如果对象A重写finalize()方法,且还未执行过,那么A会被插入到F-queue队列中,有一个虚拟机自动创建的,低优先级的Finalizer线程触发其finalize()方法执行
- finalize方法是对象逃脱死亡的最后机会,稍后GC会对F-queue队列中的对象进行第二次标记,如果A在finalize方法中与引用链上的任何一个对象建立了联系,那么在第二次标记时,A会被移除即将回收集合。之后,对象会再次出现没有引用存在的情况下,finalize方法不会再被调用,对象直接变为不可触及状态
public class CanRelliveObj {
public static CanRelliveObj obj;
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("调用当前类重写 finalize 方法");
obj = this;
}
public static void main(String[] args) {
try {
// 先创建一个对象,分配下内存,不然重来没出现过何来回收一说
obj = new CanRelliveObj();
obj = null;
System.gc(); // 回收时会调用对象的finalize方法,第一次调用成功拯救自己
System.out.println("第一次 gc");
// 因为Finalizer线程优先级很低,暂停2s,等待它
Thread.sleep(2000);
if(obj == null) {
System.out.println("obj dead");
} else {
System.out.println("obj is still alive");
}
System.out.println("第二次 gc");
obj = null;
System.gc(); // 此时回收对象发现finalize方法已经被调用,所以直接进行回收
if(obj == null) {
System.out.println("obj dead");
} else {
System.out.println("obj is still alive");
}
} catch (Exception e) {
}
}
}五、MAT与JProfiler的GC Roots溯源
MAT是Memory Analyzer的简称,是一款功能强大的Java堆内存分析器。用于查找内存泄露以及查看内存消耗情况,基于Eclipse开发的一款免费性能分析工具
可以用于分析GC Roots对象
六、清除阶段:标记-清除算法Mark-Sweep
标记:从引用根节点开始遍历,标记所有被引用的对象,一般是在对象Header中记录为可达对象
注意标记引用对象,不是垃圾对象
清除:对堆内存从头到尾进行线性的遍历,如果发现某个对象在其Header中没有标记为可达对象,则将其回收
缺点
- 效率不算高
- 在GC的时候,需要停止整个应用程序,导致用户体验差。
- 这种方式清理出来的空闲内存不连续,产生内存碎片,需要维护一个空闲列表
何为清除?
所谓的清除并不是真的置空,而是把需要清除的对象地址保存在空闲的地址列表里,下次有新对象需要加载时,判断垃圾的位置空间是否够,如果够就存放。
总结:第一次遍历标记可达对象,第二次遍历清除未标记对象。清除实际上是将未标记对象加入空闲列表,下次有新对象产生,判断空闲列表中垃圾的位置放不放的下,放得下就覆盖。
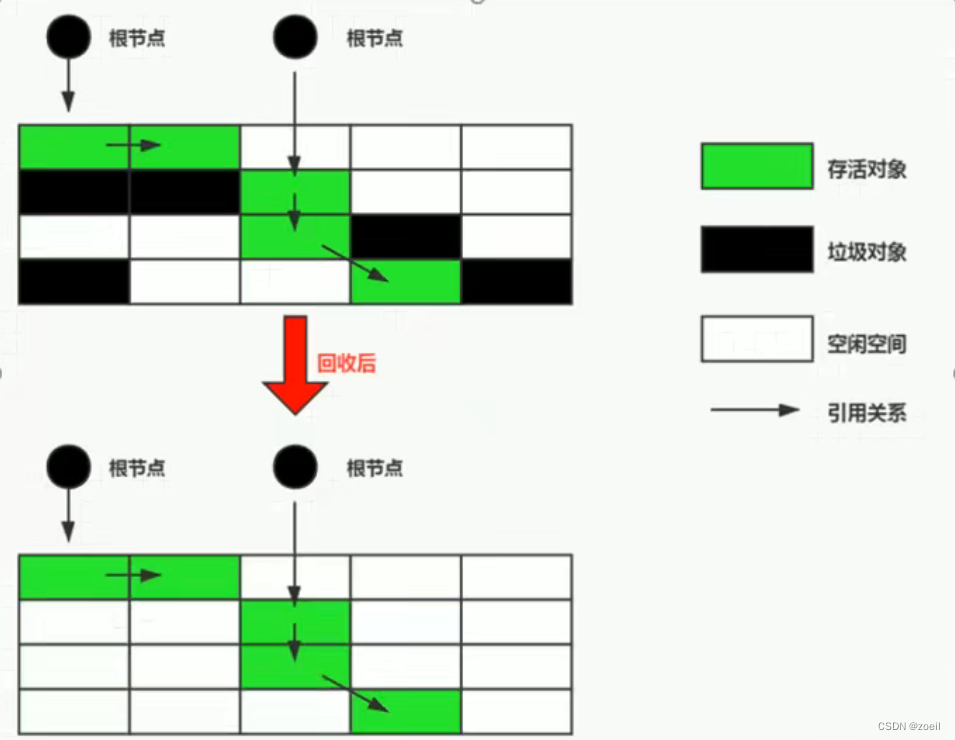
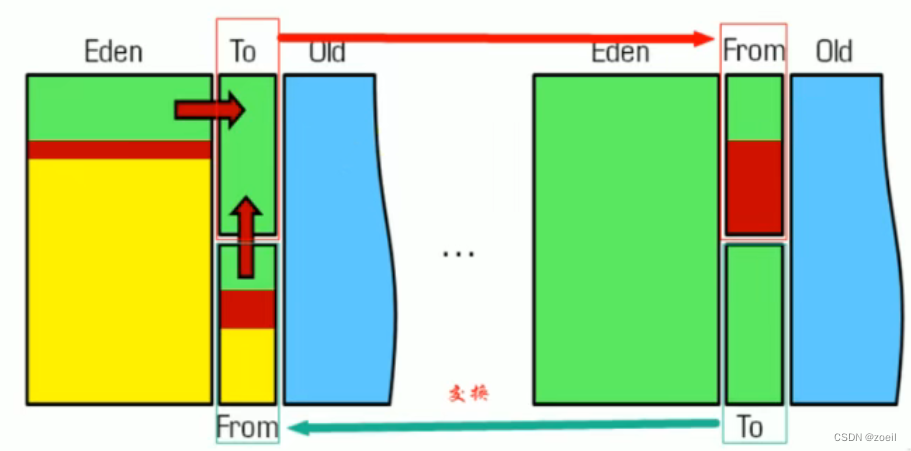
七、清除阶段:复制算法Copying
为了解决标记-清除算法在垃圾收集效率方面的缺陷——产生内存碎片。1963年出现了复制(Copying)算法
原理:将或者的内存空间分为两块,每次使用其中一块。在垃圾回收时,将正在使用的内存中的存活的对象复制到未被使用的内存块中,之后清除正在使用的内存块中的所有的对象,交换两个内存的角色,最后完成垃圾回收
优点
- 没有标记和清除的过程,实现简单高效
- 复制过去以后的保证空间的连续性,不会出现碎片的问题
缺点
- 需要两倍的内存空间
- 对于G1这种拆分为大量region的GC,复制而不是移动,意味着GC需要维护region之间的引用关系(就像对象的两种),不管是内存占用或者时间开销也不小。
注意:如果系统中的垃圾对象很多,需要复制的存活对象数量并不会太大,或者非常低使用复制算法效率才会高。想一想,如果每次复制都发现垃圾对象很少,基本每次复制都是全部移动,那效率肯定很低。
应用场景:
在新生代,对常规应用的垃圾回收,一次通常可以回收70%-90%的内存空间。回收性价比很高,所以现在的商业虚拟机都是用这种手机算法回收新生代。 (记得from区和to区吗,为什么总有一个区是空的,现在联系起来了。使用的就是是复制算法)
八、清除阶段:标记-整理算法Mark-Compact
标记-整理又叫标记-压缩算法。
背景:复制算法的高效性是建议在存活对象少,垃圾对象多的前提下的。适用于新生代,而老年代大部分对象都是存活对象,所以并不适用,否则复制成本较高。因此,基于老年代垃圾回收的特性,需要使用其他算法。
标记-清除算法可以应用在老年代中,但是该算法不仅执行效率低下,而且执行完内存回收后还会产生内存碎片。所以JVM的设计者在此基础之上进行改进,标记-整理垃圾收集算法诞生了。
执行过程
- 第一个阶段和标记清除算法一样,从根节点开始标记所有被引用的对象
- 第二阶段将所有的存货对象压缩在内存的一端,按照顺序排放,之后清理边界外所有的空间
- 最终效果等同于标记清除算法执行完成后,再进行一次内存碎片整理。
与标记清除算法本质区别,标记清除算法是非移动式的算法,标记压缩是移动式的
优点
- 消除了标记-清除算法内存区域分散的缺点,
- 消除了复制算法中,内存减半的高额代价
缺点
- 从效率上来讲,标记整理算法要低于复制算法
- 移动对象的同时,如果对象被其他对象引用,则还需要调整引用的地址
- 移动的过程中,需要全程暂停用户应用程序,即STW

九、对比三种算法

效率上来说,复制算法是最快的(因为不像标记-清除和标记整理那样需要标记,还有整理),但是浪费了太多的内存。
而标记-整理算法相对来说更加平滑一些,但是效率上不太行,比复制算法多了一个标记的阶段,比标记-清除多了一个整理内存的阶段。
想到了一个问题:复制算法不标记怎么知道一个对象是否存活,是否需要进行复制?
即:复制算法不用进行标记吗?
查阅相关资料后,明白了。复制算法没有像标记-清除和标记-整理两个方法一样有单独的标记过程。因为复制gc只需要把“活”的对象拷贝到survivor,还要mark什么呢?至于怎么判断是“活”的,gc roots以下的不都是“活”的?复制算法是从gc roots开始,遇到活对象就复制走了。gc roots找可达对象的过程结束就复制完了。不像标记算法那样,对于一个对象是否需要回收要满足两个条件:① 对象不可达;②没必要执行finalize方法。
java gc中为什么复制算法比标记整理算法快? - 简书
十、分代收集算法
不同生命周期的对象可以采取不同额收集方式,以便提高回收效率
几乎所有的GC都采用分代收集算法执行垃圾回收的
HotSpot中
- 年轻代:生命周期短,存活率低,回收频繁
- 老年代:区域较大,生命周期长,存活率高,回收不及年轻代频繁
十一、增量收集算法、分区算法
(一)增量收集算法思想
每次垃圾收集线程只收集一小片区域的内存空间,接着切换到应用程序线程,依次反复,直到垃圾收集完成
通过对线程间冲突的妥善管理,允许垃圾收集线程以分阶段的方式完成标记、清理或复制工作
缺点:线程和上下文切换导致系统吞吐量的下降
(二)分区算法
为了控制GC产生的停顿时间,将一块大的内存区域分割成多个小块,根据目标的停顿时间,每次合理的回收若干个小区间,而不是整个堆空间,从而减少一次GC所产生的时间
分代算法是将对象按照生命周期长短划分为两个部分,分区算法是将整个堆划分为连续的不同的小区间
每一个小区间都独立使用,独立回收,这种算法的好处是可以控制一次回收多少个小区间