prioritized experience replay 思路
优先经验回放出自ICLR 2016的论文《prioritized experience replay》。
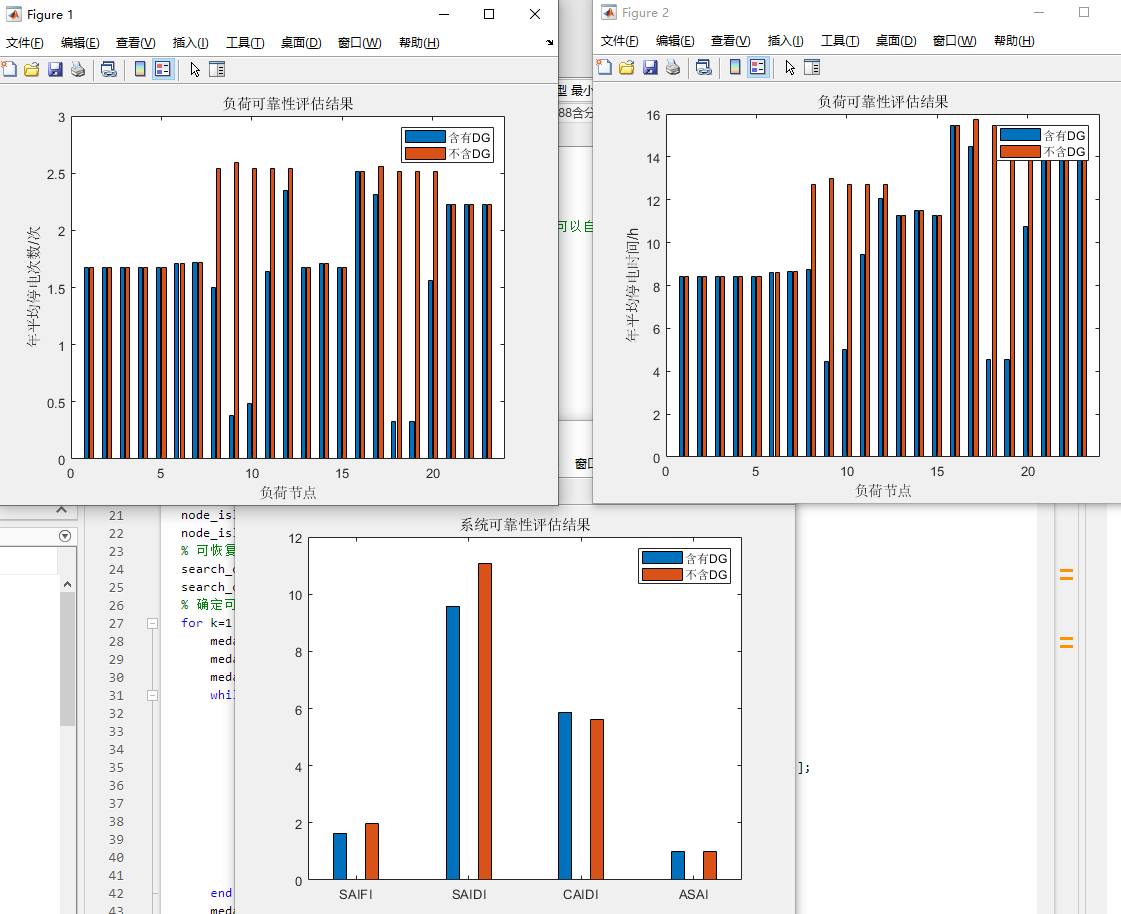
prioritized experience replay的作者们认为,按照一定的优先级来对经验回放池中的样本采样,相比于随机均匀的从经验回放池中采样的效率更高,可以让模型更快的收敛。其基本思想是RL agent在一些转移样本上可以更有效的学习,也可以解释成“更多地训练会让你意外的数据”。
那优先级如何定义呢?作者们使用的是样本的TD error
δ
\delta
δ 的幅值。对于新生成的样本,TD error未知时,将样本赋值为最大优先级,以保证样本至少将会被采样一次。每个采样样本的概率被定义为
P
(
i
)
=
p
i
α
∑
k
p
k
α
P(i) = \frac {p_i^{\alpha}} {\sum_k p_k^{\alpha}}
P(i)=∑kpkαpiα
上式中的
p
i
>
0
p_i >0
pi>0是回放池中的第i个样本的优先级,
α
\alpha
α则强调有多重视该优先级,如果
α
=
0
\alpha=0
α=0,采样就退化成和基础DQN一样的均匀采样了。
而 p i p_i pi如何取值,论文中提供了如下两种方法,两种方法都是关于TD error δ \delta δ 单调的:
- 基于比例的优先级: p i = ∣ δ i ∣ + ϵ p_i = |\delta_i| + \epsilon pi=∣δi∣+ϵ, ϵ \epsilon ϵ是一个很小的正数常量,防止当TD error为0时样本就不会被访问到的情形。(目前大部分实现都是使用的这个形式的优先级)
- 基于排序的优先级: p i = 1 r a n k ( i ) p_i = \frac {1}{rank(i)} pi=rank(i)1, 式中的 r a n k ( i ) rank(i) rank(i)是样本根据 ∣ δ i ∣ |\delta_i| ∣δi∣ 在经验回放池中的排序号,此时P就变成了带有指数 α \alpha α的幂率分布了。
作者们定义的概率调整了样本的优先级,因此也就在数据分布中引入了偏差,为了弥补偏差,使用了重要性采样权重(importance-sampling (IS) weights):
w
i
=
(
1
N
⋅
1
P
(
i
)
)
β
w_i = \left( \frac{1}{N} \cdot \frac{1}{P(i)} \right)^{\beta}
wi=(N1⋅P(i)1)β
上式权重中,当
β
=
1
\beta=1
β=1时就完全补偿了非均匀概率采样引入的偏差,作者们提到为了收敛性考虑,最后让
β
\beta
β从0到1中的某个值开始,并逐渐增加到1。在Q-learning更新时使用这些权重乘以TD error,也就是使用
w
i
δ
i
w_i \delta_i
wiδi而不是原来的
δ
i
\delta_i
δi。此外,为了使训练更稳定,总是对权重乘以
1
/
m
a
x
i
w
i
1/\mathcal{max}_i{w_i}
1/maxiwi进行归一化。
以Double DQN为例,使用优先经验回放的算法(论文算法1)如下图:

prioritized experience replay 实现
直接实现优先经验回放池如下代码(修改自代码 )
class PrioReplayBufferNaive:
def __init__(self, buf_size, prob_alpha=0.6, epsilon=1e-5, beta=0.4, beta_increment_per_sampling=0.001):
self.prob_alpha = prob_alpha
self.capacity = buf_size
self.pos = 0
self.buffer = []
self.priorities = np.zeros((buf_size, ), dtype=np.float32)
self.beta = beta
self.beta_increment_per_sampling = beta_increment_per_sampling
self.epsilon = epsilon
def __len__(self):
return len(self.buffer)
def size(self): # 目前buffer中数据的数量
return len(self.buffer)
def add(self, sample):
# 新加入的数据使用最大的优先级,保证数据尽可能的被采样到
max_prio = self.priorities.max() if self.buffer else 1.0
if len(self.buffer) < self.capacity:
self.buffer.append(sample)
else:
self.buffer[self.pos] = sample
self.priorities[self.pos] = max_prio
self.pos = (self.pos + 1) % self.capacity
def sample(self, batch_size):
if len(self.buffer) == self.capacity:
prios = self.priorities
else:
prios = self.priorities[:self.pos]
probs = np.array(prios, dtype=np.float32) ** self.prob_alpha
probs /= probs.sum()
indices = np.random.choice(len(self.buffer), batch_size, p=probs, replace=True)
samples = [self.buffer[idx] for idx in indices]
total = len(self.buffer)
self.beta = np.min([1., self.beta + self.beta_increment_per_sampling])
weights = (total * probs[indices]) ** (-self.beta)
weights /= weights.max()
return samples, indices, np.array(weights, dtype=np.float32)
def update_priorities(self, batch_indices, batch_priorities):
'''
更新样本的优先级'''
for idx, prio in zip(batch_indices, batch_priorities):
self.priorities[idx] = prio + self.epsilon
直接实现的优先经验回放,在样本数很大时的采样效率不够高,作者们通过定义了sumtree的数据结构来存储样本优先级,该数据结构的每一个节点的值为其子节点之和,而样本优先级被放在树的叶子节点上,树的根节点的值为所有优先级之和 p t o t a l p_{total} ptotal,更新和采样时的效率为 O ( l o g N ) O(logN) O(logN)。在采样时,设采样批次大小为k,将 [ 0 , p t o t a l ] [0, p_{total}] [0,ptotal]均分为k等份,然后在每一个区间均匀的采样一个值,再通过该值从树中提取到对应的样本。python 实现如下(代码来源)
class SumTree:
"""
父节点的值是其子节点值之和的二叉树数据结构
"""
write = 0
def __init__(self, capacity):
self.capacity = capacity
self.tree = np.zeros(2 * capacity - 1)
self.data = np.zeros(capacity, dtype=object)
self.n_entries = 0
# update to the root node
def _propagate(self, idx, change):
parent = (idx - 1) // 2
self.tree[parent] += change
if parent != 0:
self._propagate(parent, change)
# find sample on leaf node
def _retrieve(self, idx, s):
left = 2 * idx + 1
right = left + 1
if left >= len(self.tree):
return idx
if s <= self.tree[left]:
return self._retrieve(left, s)
else:
return self._retrieve(right, s - self.tree[left])
def total(self):
return self.tree[0]
# store priority and sample
def add(self, p, data):
idx = self.write + self.capacity - 1
self.data[self.write] = data
self.update(idx, p)
self.write += 1
if self.write >= self.capacity:
self.write = 0
if self.n_entries < self.capacity:
self.n_entries += 1
# update priority
def update(self, idx, p):
change = p - self.tree[idx]
self.tree[idx] = p
self._propagate(idx, change)
# get priority and sample
def get(self, s):
idx = self._retrieve(0, s)
dataIdx = idx - self.capacity + 1
return (idx, self.tree[idx], self.data[dataIdx])
class PrioReplayBuffer: # stored as ( s, a, r, s_ ) in SumTree
epsilon = 0.01
alpha = 0.6
beta = 0.4
beta_increment_per_sampling = 0.001
def __init__(self, capacity):
self.tree = SumTree(capacity)
self.capacity = capacity
def _get_priority(self, error):
return (np.abs(error) + self.epsilon) ** self.alpha
def add(self, error, sample):
p = self._get_priority(error)
self.tree.add(p, sample)
def sample(self, n):
batch = []
idxs = []
segment = self.tree.total() / n
priorities = []
self.beta = np.min([1., self.beta + self.beta_increment_per_sampling])
for i in range(n):
a = segment * i
b = segment * (i + 1)
s = random.uniform(a, b)
(idx, p, data) = self.tree.get(s)
priorities.append(p)
batch.append(data)
idxs.append(idx)
sampling_probabilities = priorities / self.tree.total()
is_weight = np.power(self.tree.n_entries * sampling_probabilities, -self.beta)
is_weight /= is_weight.max()
return batch, idxs, is_weight
def update(self, idx, error):
'''
这里是一次更新一个样本,所以在调用时,写for循环依次更次样本的优先级
'''
p = self._get_priority(error)
self.tree.update(idx, p)
参考资料
-
Schaul, Tom, John Quan, Ioannis Antonoglou, and David Silver. 2015. “Prioritized Experience Replay.” arXiv: Learning,arXiv: Learning, November.
-
sum_tree的实现代码
-
相关blog: 1 (对应的代码), 2, 3