常见的数据同步/集成场景多发生于不同的存储系统、不同的存储格式,如从 mysql 同步数据至数仓、excel 或 csv 导入数据库中,但是众多数据同步解决方案很少涉及从 http 接口同步数据。
如淘宝、拼多多等电商平台,平台内部不同团队之间的数据打通,很多的开源数据集成工具可以满足。但是像三方卖家入驻电商平台后,就需要在电商平台注册自研应用,通过开放平台提供的接口打通自研应用与电商平台的数据壁垒,准确及时地获取到商品、订单、物流、售后以及评价等实时变更数据,而无法实现数据库级别的数据同步,让 datax 之类的大部分数据同步工具无法使用。
本系列文章描述笔者在实际工作中对接快手、淘宝等开放平台同步商品、订单、接口售后单等数据的一些个人经验总结和实践方案。
数据同步接口
根据数据量和实时性的不同需求,开放平台数据查询接口总共有 2 种形式:
-
分页接口。比如获取仓库列表,平台类目列表等。
-
支持时间范围查询的分页接口。比如订单列表接口,根据订单修改时间分页查询。
数据同步的难点也在于准确、实时地通过时间范围分页查询接口同步数据。
基本实现:分页请求
根据时间范围进行分页请求的基本实现,请求参数中带有开始结束时间加上分页参数。
请求参数 json 如下:
{
"startTime": "2021-11-11 00:00:00",
"endTime": "2021-11-12 00:00:00",
"pageIndex": 1,
"pageSize": 50
}
响应结果 json 如下:
{
"dataCount": 10000,
"pageIndex": 1,
"pageSize": 50,
"datas": [...]
}
接入方在接入数据的时候可以根据时间范围、分页参数逐时间段逐页同步数据,确保数据不丢失。
时间类型
开放平台往往也会根据业务需求,提供不同类型的时间范围,比如订单场景,有订单创建时间,修改时间,支付时间,出库时间等。对于数据接入者来说来说,最喜欢的时间类型为修改时间,根据修改时间同步可以确保数据发生修改后实时地同步过来。
但是修改时间有个丢数据的陷阱:需要根据修改时间降序同步。
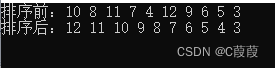
假设有数据在某个时间范围内从左向右按照修改时间升序排序,效果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
在同步这个时间范围内,如果 20 条数据没有发生任何修改,分页拉取第一页 1 ~ 5,第二页 6 ~ 10 等可以确保数据不会漏。
但是在拉取第一页 1 ~ 5 后,数据 5 发生修改,其余数据不变,拉取第二页时再按照修改时间升序排序,此时排序效果如下:
1 2 3 4 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
可以看到数据 6 被归到第一页中,之后拉取第二页时会从数据 7 开始,数据 6 被遗漏。
按照修改时间同步,需要分页请求多次才能同步完成时,中间数据发生修改会导致数据排序顺序发生变动,从而造成数据遗漏。
但是按照订单创建时间、支付时间等时间类型则不会,因为订单一旦创建或支付,对应的创建时间和支付时间不会发生变动。
解决思路就是从最后一页向前拉。
同样是上面的 20 条数据,在同步完最后一页数据 16 ~ 20 条后,数据 5 发生变更,同步倒数第二页时,同步到的数据为 12 ~ 16,逐步推进分页,在最后一次请求中同步到数据 1 ~ 6。
倒着拉不会出现数据遗漏的情况,但是可以看到数据 16 被重复同步,接入方需要做好数据更新的幂等性。
数据接入时需确定时间类型,会不会发生变动,以及排序顺序:
-
开放平台根据修改时间升序排序时,接入方需要从后向前翻页;
-
开放平台根据修改时间降序排序时,接入方需要从前往后翻页。
接口常见限制
开放平台为了保护接口安全,会对接口进行一定限制:
-
开始时间结束时间相差不能过大以避免深翻页。比如不能超过 7 天
-
只允许同步近期数据。比如订单类只允许同步 90 天内订单
-
减少每次请求数据量。比如限制每页数据最多 100 条
-
接口限流。限制接口请求并发和 qps
取消 dataCount 响应字段,改为使用 hasNext
对于关系型数据库的存储,如 mysql,返回结果中的 dataCount 和 datas 两个字段无法在同一条查询语句中获取,需要分别执行一次 count 和分页 select 请求才能获取 dataCount 和 datas。
接口响应包含 dataCount 字段的目的是为了接入方能够计算何时终止分页请求,这是必要的,因为接入方需要能够确定何时终止分页,为此开放平台接口需要多执行一次 count 语句。
为支持接入方分页请求,在接口响应中返回 boolean 类型的 hasNext 字段,表示是否还有下一页,帮助接入方判断是否到达最后一页。
接口响应中不再返回 dataCount 字段,可以避免开放平台进行 count 查询,极大提高接口性能。
那么开放平台该如何确定 hasNext 的值呢?
可以在执行 select 语句时设置 size 为 pageSize + 1,如果查询语句返回数据量为 pageSize + 1,存在下一页,否则不存在。
这种接口设计请求参数不变,响应参数如下:
{
"hasNext": true,
"pageIndex": 1,
"pageSize": 50,
"datas": [...]
}
使用 hasNext 时需要开放平台根据修改时间降序排列,因为接入方无法实现从后向前翻页。
取消 pageIndex 入参,改用 cursor
分页接口普遍惧怕深分页,即 limit 100 offset 1000000,深分页不仅会拖累接口响应时间,还会对数据库造成较大压力,带来潜在的系统崩溃风险。
为了减少深分页,开放平台多会限制时间范围间隔,比如结束时间开始时间不能相差超过 7 天,但是这种方式只能减少深分页而无法彻底杜绝。
cursor 方案可以彻底避免深分页问题。
请求参数 json 如下:
{
"startTime": "2021-11-11 00:00:00",
"endTime": "2021-11-12 00:00:00",
"cursor": "1639487400913_5",
"pageSize": 50
}
响应参数 json 如下:
{
"hasNext": true,
"cursor": "1639487400918_10",
"pageSize": 50,
"datas": [...]
}
交互时第一次请求时 cursor 为空不传入,之后每次请求传入响应中 cursor 值,直到 cursor 返回一个特殊标识,分页结束。
使用 cursor 避免深分页的原理在于 cursor 的构成形式:为 datas 的最后一条数据的 timestamp + id。
开放平台接口对 cursor 进行解析构建 select 语句:
select *
from table
where id > ${id}
and time >= ${timestame}
and time < ${endTime}
order by time, id
limit ${pageSize}