Web指纹识别是一种通过分析Web应用程序的特征和元数据,以确定应用程序所使用的技术栈和配置的技术。这项技术旨在识别Web服务器、Web应用框架、后端数据库、JavaScript库等组件的版本和配置信息。通过分析HTTP响应头、HTML源代码、JavaScript代码、CSS文件等,可以获取关于Web应用程序的信息。指纹识别在信息搜集、渗透测试、安全审计等方面具有重要作用。有许多开源和商业工具可以用于执行Web指纹识别,例如Wappalyzer、WebScarab、Nmap等。
Web指纹识别的主要目的包括:
- 技术识别: 了解Web应用程序所使用的服务器软件、框架、数据库等技术。
- 版本检测: 确定这些技术的具体版本,有助于判断应用程序是否存在已知的漏洞。
- 配置检测: 获取Web应用程序的配置信息,包括安装路径、默认文件、目录结构等。
- 漏洞分析: 通过已知漏洞与特定版本相关联,评估Web应用程序的安全性。
指纹识别是渗透测试中常用的一项技术,用于识别目标Web应用程序所使用的框架、技术和配置。其中,通过计算特定页面的哈希值进行指纹识别是一种常见的方法,主要通过以下步骤实现:
- 1.利用CURL库获取页面内容: 使用LibCURL库可以方便地获取目标网站的页面内容,将其读入到
std::string字符串中,以便后续处理。 - 2.MD5算法计算哈希值: 对获取的页面内容进行MD5哈希计算,得到一个唯一的哈希值。MD5是一种常用的哈希算法,将任意长度的数据映射成128位的哈希值,通常以16进制表示。
- 3.比对预先计算的框架页面哈希值: 预先计算一些特定页面的哈希值,这些页面通常是目标框架中相对独立且不经常变动的页面。将获取到的页面的哈希值与预先计算的哈希值进行比对。
- 4.框架识别: 如果哈希值匹配,则说明目标页面的框架很可能是预先定义的框架,从而实现对框架的识别。比对的过程可以使用简单的相等比对,也可以设置一定的相似度阈值。
通过计算页面哈希值进行指纹识别是一种有效的方式,特别是针对那些相对稳定的页面。首先我们利用LibCURL库将目标页面读入到std::string字符串中,然后调用MD5算法计算出该页面的HASH值并比对,由于特定框架中总是有些页面不会变动,我们则去校验这些页面的HASH值,即可实现对框架的识别。
LibCURL读入页面
当我们需要获取远程服务器上的网页内容时,使用C++编写一个简单的程序来实现这个目标是非常有用的。在这个例子中,我们使用了libcurl库,在程序中引入libcurl库的头文件,并使用#pragma comment指令引入相关的库文件。接下来,我们定义了一个回调函数WriteCallback,该函数将获取的数据追加到一个std::string对象中。
主要的功能实现在GetUrlPageOfString函数中。该函数接受一个URL作为参数,并使用libcurl库来执行HTTP GET请求。我们通过设置CURLOPT_URL选项来指定URL路径,同时关闭了SSL证书验证以及启用了重定向。我们还设置了一些超时选项,以确保在连接或接收数据时不会花费太长时间。通过调用curl_easy_perform执行请求,并通过回调函数将获取到的数据存储在read_buffer中。最后,我们输出接收到的数据的长度。
#define CURL_STATICLIB
#define BUILDING_LIBCURL
#include <iostream>
#include <string>
#include "curl/curl.h"
#pragma comment (lib,"libcurl_a.lib")
#pragma comment (lib,"wldap32.lib")
#pragma comment (lib,"ws2_32.lib")
#pragma comment (lib,"Crypt32.lib")
using namespace std;
// 存储回调函数
size_t WriteCallback(char *contents, size_t size, size_t nmemb, void *userp)
{
((std::string*)userp)->append((char*)contents, size * nmemb);
return size * nmemb;
}
// 获取数据并放入string中.
std::string GetUrlPageOfString(std::string url)
{
std::string read_buffer;
CURL *curl;
curl_global_init(CURL_GLOBAL_ALL);
curl = curl_easy_init();
if (curl)
{
curl_easy_setopt(curl, CURLOPT_SSL_VERIFYPEER, 0L); // 忽略证书检查
curl_easy_setopt(curl, CURLOPT_FOLLOWLOCATION, 1); // 重定向
curl_easy_setopt(curl, CURLOPT_URL, url); // URL路径
curl_easy_setopt(curl, CURLOPT_MAXREDIRS, 1); // 查找次数,防止查找太深
curl_easy_setopt(curl, CURLOPT_CONNECTTIMEOUT, 3); // 连接超时
curl_easy_setopt(curl, CURLOPT_TIMEOUT, 3); // 接收数据时超时设置
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &read_buffer);
curl_easy_perform(curl);
curl_easy_cleanup(curl);
return read_buffer;
}
return "None";
}
int main(int argc, char *argv[])
{
std::string urls = GetUrlPageOfString("填入URL地址");
std::cout << "接收长度: " << urls.length() << " bytes" << std::endl;
system("pause");
return 0;
}
运行上述代码将会输出访问特定主机所接收到的流量字节数,如下图所示;

LibCURL获取状态码
在这个C++程序中,我们使用了libcurl库来获取指定URL的HTTP状态码。首先,我们引入libcurl库的头文件,并通过#pragma comment指令引入相关的库文件。然后,我们定义了一个静态的回调函数not_output,该函数用于屏蔽libcurl的输出。
接着,我们定义了GetStatus函数,该函数接受一个URL作为参数,并返回该URL对应的HTTP状态码。在函数中,我们使用curl_easy_setopt设置了一些选项,包括URL、写数据的回调函数(这里我们使用not_output屏蔽输出),以及通过curl_easy_getinfo获取状态码。
在main函数中,我们调用GetStatus函数并输出获取到的状态码。这个例子非常简单,但展示了使用libcurl库获取HTTP状态码的基本方法。
#define CURL_STATICLIB
#define BUILDING_LIBCURL
#include <iostream>
#include <string>
#include "curl/curl.h"
#pragma comment (lib,"libcurl_a.lib")
#pragma comment (lib,"wldap32.lib")
#pragma comment (lib,"ws2_32.lib")
#pragma comment (lib,"Crypt32.lib")
using namespace std;
// 屏蔽输出
static size_t not_output(char *d, size_t n, size_t l, void *p){ return 0; }
// 获取状态码
long GetStatus(std::string url)
{
CURLcode return_code;
long retcode = 0;
return_code = curl_global_init(CURL_GLOBAL_WIN32);
if (CURLE_OK != return_code)
return 0;
CURL *easy_handle = curl_easy_init();
if (NULL != easy_handle)
{
curl_easy_setopt(easy_handle, CURLOPT_URL, url); // 请求的网站
curl_easy_setopt(easy_handle, CURLOPT_WRITEFUNCTION, not_output); // 设置回调函数,屏蔽输出
return_code = curl_easy_perform(easy_handle); // 执行CURL
return_code = curl_easy_getinfo(easy_handle, CURLINFO_RESPONSE_CODE, &retcode);
if ((CURLE_OK == return_code) && retcode)
{
return retcode;
}
}
curl_easy_cleanup(easy_handle);
curl_global_cleanup();
return retcode;
}
int main(int argc, char *argv[])
{
long ref = GetStatus("填入URL地址/");
std::cout << "返回状态码: " << ref << std::endl;
system("pause");
return 0;
}
运行上述代码可得到特定网址的状态码信息,图中200表示访问正常;

计算字符串Hash值
我们使用Boost库中的boost/crc.hpp和boost/uuid/detail/md5.hpp来计算CRC32和MD5值。首先,定义GetCrc32函数,该函数接受一个字符串作为输入,使用Boost库中的crc_32_type计算字符串的CRC32值。
接着,我们定义了GetMd5函数,该函数接受一个字符数组和其大小作为输入,使用Boost库中的boost::uuids::detail::md5计算字符串的MD5值。在这个例子中,我们使用了Boost的md5实现。
在main函数中,我们创建了一个测试字符串"hello lyshark",并分别调用GetMd5和GetCrc32函数来计算其MD5和CRC32值。最后,我们输出计算得到的MD5和CRC32值。
#define CURL_STATICLIB
#define BUILDING_LIBCURL
#include <iostream>
#include <string>
#include <boost/crc.hpp>
#include <boost/uuid/detail/md5.hpp>
#include <boost/algorithm/hex.hpp>
using namespace std;
using namespace boost;
// 应用于crc32
long GetCrc32(std::string sz_string)
{
long ref;
crc_32_type crc32;
cout << hex;
crc32.process_bytes(sz_string.c_str(), sz_string.length());
return crc32.checksum();
}
// 应用于md5
std::string GetMd5(const char * const buffer, size_t buffer_size)
{
if (buffer == nullptr)
return false;
std::string str_md5;
boost::uuids::detail::md5 boost_md5;
boost_md5.process_bytes(buffer, buffer_size);
boost::uuids::detail::md5::digest_type digest;
boost_md5.get_digest(digest);
const auto char_digest = reinterpret_cast<const char*>(&digest);
str_md5.clear();
boost::algorithm::hex(char_digest, char_digest + sizeof(boost::uuids::detail::md5::digest_type), std::back_inserter(str_md5));
return str_md5;
}
int main(int argc, char *argv[])
{
std::string urls = "hello lyshark";
std::cout << "计算Hash: " << urls << std::endl;
// 计算MD5
std::string str = GetMd5(urls.c_str(), urls.length());
std::cout << "计算 MD5: " << str << std::endl;
// 计算CRC32
long crc = GetCrc32(urls.c_str());
std::cout << "计算 CRC32: " << crc << std::endl;
system("pause");
return 0;
}
通过计算可得到hello lyshark字符串的CRC32与MD5特征码,如下图;

当具备了hash值的计算后,我们只需要将上述两个功能组合起来就可以实现提取特定页面的特征码,首先通过libcurl库完成对页面的访问,接着就是计算特征码即可。
#define CURL_STATICLIB
#define BUILDING_LIBCURL
#include <iostream>
#include <string>
#include "curl/curl.h"
#include <boost/crc.hpp>
#include <boost/uuid/detail/md5.hpp>
#include <boost/algorithm/hex.hpp>
#pragma comment (lib,"libcurl_a.lib")
#pragma comment (lib,"wldap32.lib")
#pragma comment (lib,"ws2_32.lib")
#pragma comment (lib,"Crypt32.lib")
using namespace std;
// 存储回调函数
size_t WriteCallback(char *contents, size_t size, size_t nmemb, void *userp)
{
((std::string*)userp)->append((char*)contents, size * nmemb);
return size * nmemb;
}
// 获取数据并放入string中.
std::string GetUrlPageOfString(std::string url)
{
std::string read_buffer;
CURL *curl;
curl_global_init(CURL_GLOBAL_ALL);
curl = curl_easy_init();
if (curl)
{
curl_easy_setopt(curl, CURLOPT_SSL_VERIFYPEER, 0L); // 忽略证书检查
curl_easy_setopt(curl, CURLOPT_FOLLOWLOCATION, 1); // 重定向
curl_easy_setopt(curl, CURLOPT_URL, url); // URL路径
curl_easy_setopt(curl, CURLOPT_MAXREDIRS, 1); // 查找次数,防止查找太深
curl_easy_setopt(curl, CURLOPT_CONNECTTIMEOUT, 3); // 连接超时
curl_easy_setopt(curl, CURLOPT_TIMEOUT, 3); // 接收数据时超时设置
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &read_buffer);
curl_easy_perform(curl);
curl_easy_cleanup(curl);
return read_buffer;
}
return "None";
}
// 应用于md5
std::string GetMd5(const char * const buffer, size_t buffer_size)
{
if (buffer == nullptr)
return false;
std::string str_md5;
boost::uuids::detail::md5 boost_md5;
boost_md5.process_bytes(buffer, buffer_size);
boost::uuids::detail::md5::digest_type digest;
boost_md5.get_digest(digest);
const auto char_digest = reinterpret_cast<const char*>(&digest);
str_md5.clear();
boost::algorithm::hex(char_digest, char_digest + sizeof(boost::uuids::detail::md5::digest_type), std::back_inserter(str_md5));
return str_md5;
}
// 计算特定页面MD5
std::string CalculationMD5(std::string url)
{
std::string page_string = GetUrlPageOfString(url);
if (page_string != "None")
{
std::string page_md5 = GetMd5(page_string.c_str(), page_string.length());
std::cout << "[+] 计算页面: " << url << std::endl;
std::cout << "[+] 压缩数据: " << page_md5 << std::endl;
return page_md5;
}
return "None";
}
int main(int argc, char *argv[])
{
std::string md5 = CalculationMD5("填入URL地址");
system("pause");
return 0;
}
上述代码运行后,则可以计算出特定网站的MD5值,如下图;

解析对比Hash值
指纹识别依赖于特征库,如果需要实现自己的指纹识别工具则需要我么能自行去收集各类框架的特征库,有了这些特征库就可以定义一个如下所示的JSON文本,该文本中container用于存储框架类型,其次hash则用于存放特征码,最后的sub_url则是识别路径。
{
"data_base":
[
{ "container": "typecho", "hash": "04A40072CDB70B1BF54C96C6438678CB" ,"sub_url":"/index.php/about.html" },
{ "container": "wordpress", "hash": "04A40072CBB70B1BF54C96C6438678CB" ,"sub_url":"/admin.php" },
{ "container": "baidu", "hash": "EF3F1F8FBB7D1F545A75A83640FF0E9F" ,"sub_url":"/index.php" }
]
}
接着就是解析这段JSON文本,我们利用BOOST提供的JSON解析库,首先解析出所有的键值对,将其全部读入到定义的结构体映射中,然后尝试输出看看,注意压缩和解包格式必须对应。
#include <iostream>
#include <string>
#include <boost/property_tree/ptree.hpp>
#include <boost/property_tree/json_parser.hpp>
using namespace std;
using namespace boost;
using namespace boost::property_tree;
// 定义映射字段
typedef struct
{
std::vector<std::string> container;
std::vector<std::string> hash;
std::vector<std::string> sub_url;
}database_map;
// 获取文本中的JSON,放入自定义database_map
std::vector<database_map> GetDataBase()
{
std::vector<database_map> ref;
boost::property_tree::ptree ptr;
boost::property_tree::read_json("database.json", ptr);
if (ptr.count("data_base") == 1)
{
boost::property_tree::ptree p1, p2;
p1 = ptr.get_child("data_base");
// 定义映射类型
std::vector<std::string> x, y, z;
database_map maps;
for (ptree::iterator it = p1.begin(); it != p1.end(); ++it)
{
// 读取出json中的数据
p2 = it->second;
std::string container = p2.get<std::string>("container");
std::string hash = p2.get<std::string>("hash");
std::string sub_url = p2.get<std::string>("sub_url");
// 临时存储数据
x.push_back(container);
y.push_back(hash);
z.push_back(sub_url);
}
// 打包结构压入ref中
maps.container = x;
maps.hash = y;
maps.sub_url = z;
ref.push_back(maps);
}
return ref;
}
int main(int argc, char *argv[])
{
std::vector<database_map> db_map = GetDataBase();
for (int x = 0; x < db_map.size(); x++)
{
// 依次将字典读入内存容器.
database_map maps = db_map[x];
std::vector<std::string> container = maps.container;
std::vector<std::string> hash = maps.hash;
std::vector<std::string> sub_url = maps.sub_url;
// 必须保证记录数完全一致
if (container.size() != 0 && hash.size() != 0 && sub_url.size() != 0)
{
for (int x = 0; x < container.size(); x++)
{
std::cout << "容器类型: " << container[x] << std::endl;
std::cout << "指纹: " << hash[x] << std::endl;
std::cout << "根路径: " << sub_url[x] << std::endl;
std::cout << std::endl;
}
}
}
std::system("pause");
return 0;
}
运行后则可以实现正常的json文档解析,如下图;

最后增加循环对比流程,这里我们以百度为例测试一下提取字段是否可以被解析。
#define CURL_STATICLIB
#define BUILDING_LIBCURL
#include <iostream>
#include <string>
#include "curl/curl.h"
#include <boost/format.hpp>
#include <boost/property_tree/ptree.hpp>
#include <boost/property_tree/json_parser.hpp>
#include <boost/crc.hpp>
#include <boost/uuid/detail/md5.hpp>
#include <boost/algorithm/hex.hpp>
#pragma comment (lib,"libcurl_a.lib")
#pragma comment (lib,"wldap32.lib")
#pragma comment (lib,"ws2_32.lib")
#pragma comment (lib,"Crypt32.lib")
using namespace std;
using namespace boost;
using namespace boost::property_tree;
// 定义映射字段
typedef struct
{
std::vector<std::string> container;
std::vector<std::string> hash;
std::vector<std::string> sub_url;
}database_map;
// 存储回调函数
size_t WriteCallback(char *contents, size_t size, size_t nmemb, void *userp)
{
((std::string*)userp)->append((char*)contents, size * nmemb);
return size * nmemb;
}
// 屏蔽输出
static size_t not_output(char *d, size_t n, size_t l, void *p){ return 0; }
// 获取数据并放入string中.
std::string GetUrlPageOfString(std::string url)
{
std::string read_buffer;
CURL *curl;
curl_global_init(CURL_GLOBAL_ALL);
curl = curl_easy_init();
if (curl)
{
curl_easy_setopt(curl, CURLOPT_SSL_VERIFYPEER, 0L); // 忽略证书检查
curl_easy_setopt(curl, CURLOPT_FOLLOWLOCATION, 1); // 重定向
curl_easy_setopt(curl, CURLOPT_URL, url); // URL路径
curl_easy_setopt(curl, CURLOPT_MAXREDIRS, 1); // 查找次数,防止查找太深
curl_easy_setopt(curl, CURLOPT_CONNECTTIMEOUT, 3); // 连接超时
curl_easy_setopt(curl, CURLOPT_TIMEOUT, 3); // 接收数据时超时设置
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &read_buffer);
curl_easy_perform(curl);
curl_easy_cleanup(curl);
return read_buffer;
}
return "None";
}
// 获取状态码
long GetStatus(std::string url)
{
CURLcode return_code;
long retcode = 0;
return_code = curl_global_init(CURL_GLOBAL_WIN32);
if (CURLE_OK != return_code)
return 0;
CURL *easy_handle = curl_easy_init();
if (NULL != easy_handle)
{
curl_easy_setopt(easy_handle, CURLOPT_URL, url); // 请求的网站
curl_easy_setopt(easy_handle, CURLOPT_WRITEFUNCTION, not_output); // 设置回调函数,屏蔽输出
return_code = curl_easy_perform(easy_handle); // 执行CURL
return_code = curl_easy_getinfo(easy_handle, CURLINFO_RESPONSE_CODE, &retcode);
if ((CURLE_OK == return_code) && retcode)
{
return retcode;
}
}
curl_easy_cleanup(easy_handle);
curl_global_cleanup();
return retcode;
}
// 应用于md5
std::string GetMd5(const char * const buffer, size_t buffer_size)
{
if (buffer == nullptr)
return false;
std::string str_md5;
boost::uuids::detail::md5 boost_md5;
boost_md5.process_bytes(buffer, buffer_size);
boost::uuids::detail::md5::digest_type digest;
boost_md5.get_digest(digest);
const auto char_digest = reinterpret_cast<const char*>(&digest);
str_md5.clear();
boost::algorithm::hex(char_digest, char_digest + sizeof(boost::uuids::detail::md5::digest_type), std::back_inserter(str_md5));
return str_md5;
}
// 获取文本中的JSON,放入自定义database_map
std::vector<database_map> GetDataBase()
{
std::vector<database_map> ref;
boost::property_tree::ptree ptr;
boost::property_tree::read_json("database.json", ptr);
if (ptr.count("data_base") == 1)
{
boost::property_tree::ptree p1, p2;
p1 = ptr.get_child("data_base");
// 定义映射类型
std::vector<std::string> x, y, z;
database_map maps;
for (ptree::iterator it = p1.begin(); it != p1.end(); ++it)
{
// 读取出json中的数据
p2 = it->second;
std::string container = p2.get<std::string>("container");
std::string hash = p2.get<std::string>("hash");
std::string sub_url = p2.get<std::string>("sub_url");
// 临时存储数据
x.push_back(container);
y.push_back(hash);
z.push_back(sub_url);
}
// 打包结构压入ref中
maps.container = x;
maps.hash = y;
maps.sub_url = z;
ref.push_back(maps);
}
return ref;
}
int main(int argc, char *argv[])
{
std::vector<database_map> db_map = GetDataBase();
for (int x = 0; x < db_map.size(); x++)
{
// 依次将字典读入内存容器.
database_map maps = db_map[x];
std::vector<std::string> container = maps.container;
std::vector<std::string> hash = maps.hash;
std::vector<std::string> sub_url = maps.sub_url;
// 必须保证记录数完全一致
if (container.size() != 0 && hash.size() != 0 && sub_url.size() != 0)
{
for (int x = 0; x < container.size(); x++)
{
// 开始编写扫描函数
// 1.拼接字符串
std::string ur = "填入URL地址";
std::string this_url = boost::str(boost::format("%s%s") %ur %sub_url[x]);
// 2.判断页面是否存在
long ref_status = GetStatus(this_url);
if (ref_status != 0 && ref_status == 200)
{
// 3.读入页面字符串,判断是否成功
std::string read_page = GetUrlPageOfString(this_url);
if (read_page != "None")
{
std::string check_md5 = GetMd5(read_page.c_str(),read_page.length());
std::cout << "[+] 页面MD5: " << check_md5 << std::endl;
std::cout << "[+] 数据库: " << hash[x] << std::endl;
// 4.比对MD5值是否相同
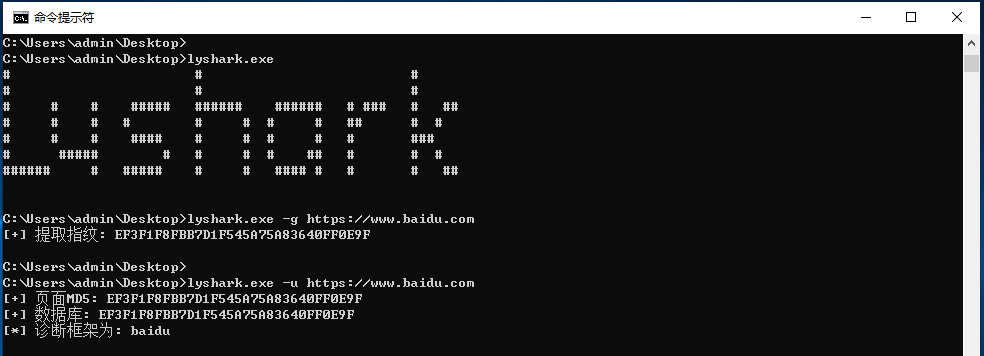
if (check_md5 == std::string(hash[x]))
{
std::cout << "[*] 诊断框架为: " << container[x] << std::endl;
break;
}
}
}
}
}
}
std::system("pause");
return 0;
}
如下图所示,说明对比通过,接着就可以增加命令行参数并使用了。

完整代码总结
C++指纹识别助手程序,它使用了libcurl库进行HTTP请求,通过比对页面的MD5值与预先存储在数据库中的MD5值,从而识别目标网站所使用的容器框架。
通过参数-u用于识别一个网站是什么框架,使用-g则是获取当前页面指纹特征,如下图;
#define CURL_STATICLIB
#define BUILDING_LIBCURL
#include <iostream>
#include <string>
#include "curl/curl.h"
#include <boost/format.hpp>
#include <boost/property_tree/ptree.hpp>
#include <boost/property_tree/json_parser.hpp>
#include <boost/crc.hpp>
#include <boost/uuid/detail/md5.hpp>
#include <boost/algorithm/hex.hpp>
#include <boost/program_options.hpp>
#pragma comment (lib,"libcurl_a.lib")
#pragma comment (lib,"wldap32.lib")
#pragma comment (lib,"ws2_32.lib")
#pragma comment (lib,"Crypt32.lib")
using namespace std;
using namespace boost;
using namespace boost::property_tree;
namespace opt = boost::program_options;
// 定义映射字段
typedef struct
{
std::vector<std::string> container;
std::vector<std::string> hash;
std::vector<std::string> sub_url;
}database_map;
void ShowOpt()
{
fprintf(stderr,
"# # # \n"
"# # # \n"
"# # # ##### ###### ###### # ### # ## \n"
"# # # # # # # # ## # # \n"
"# # # #### # # # # # ### \n"
"# ##### # # # # ## # # # \n"
"###### # ##### # # #### # # # ## \n\n"
);
}
// 存储回调函数
size_t WriteCallback(char *contents, size_t size, size_t nmemb, void *userp)
{
((std::string*)userp)->append((char*)contents, size * nmemb);
return size * nmemb;
}
// 屏蔽输出
static size_t not_output(char *d, size_t n, size_t l, void *p){ return 0; }
// 获取数据并放入string中.
std::string GetUrlPageOfString(std::string url)
{
std::string read_buffer;
CURL *curl;
curl_global_init(CURL_GLOBAL_ALL);
curl = curl_easy_init();
if (curl)
{
curl_easy_setopt(curl, CURLOPT_SSL_VERIFYPEER, 0L); // 忽略证书检查
curl_easy_setopt(curl, CURLOPT_FOLLOWLOCATION, 1); // 重定向
curl_easy_setopt(curl, CURLOPT_URL, url); // URL路径
curl_easy_setopt(curl, CURLOPT_MAXREDIRS, 1); // 查找次数,防止查找太深
curl_easy_setopt(curl, CURLOPT_CONNECTTIMEOUT, 3); // 连接超时
curl_easy_setopt(curl, CURLOPT_TIMEOUT, 3); // 接收数据时超时设置
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &read_buffer);
curl_easy_perform(curl);
curl_easy_cleanup(curl);
return read_buffer;
}
return "None";
}
// 获取状态码
long GetStatus(std::string url)
{
CURLcode return_code;
long retcode = 0;
return_code = curl_global_init(CURL_GLOBAL_WIN32);
if (CURLE_OK != return_code)
return 0;
CURL *easy_handle = curl_easy_init();
if (NULL != easy_handle)
{
curl_easy_setopt(easy_handle, CURLOPT_URL, url); // 请求的网站
curl_easy_setopt(easy_handle, CURLOPT_WRITEFUNCTION, not_output); // 设置回调函数,屏蔽输出
return_code = curl_easy_perform(easy_handle); // 执行CURL
return_code = curl_easy_getinfo(easy_handle, CURLINFO_RESPONSE_CODE, &retcode);
if ((CURLE_OK == return_code) && retcode)
{
return retcode;
}
}
curl_easy_cleanup(easy_handle);
curl_global_cleanup();
return retcode;
}
// 应用于md5
std::string GetMd5(const char * const buffer, size_t buffer_size)
{
if (buffer == nullptr)
return false;
std::string str_md5;
boost::uuids::detail::md5 boost_md5;
boost_md5.process_bytes(buffer, buffer_size);
boost::uuids::detail::md5::digest_type digest;
boost_md5.get_digest(digest);
const auto char_digest = reinterpret_cast<const char*>(&digest);
str_md5.clear();
boost::algorithm::hex(char_digest, char_digest + sizeof(boost::uuids::detail::md5::digest_type), std::back_inserter(str_md5));
return str_md5;
}
// 获取文本中的JSON,放入自定义database_map
std::vector<database_map> GetDataBase()
{
std::vector<database_map> ref;
boost::property_tree::ptree ptr;
boost::property_tree::read_json("database.json", ptr);
if (ptr.count("data_base") == 1)
{
boost::property_tree::ptree p1, p2;
p1 = ptr.get_child("data_base");
// 定义映射类型
std::vector<std::string> x, y, z;
database_map maps;
for (ptree::iterator it = p1.begin(); it != p1.end(); ++it)
{
// 读取出json中的数据
p2 = it->second;
std::string container = p2.get<std::string>("container");
std::string hash = p2.get<std::string>("hash");
std::string sub_url = p2.get<std::string>("sub_url");
// 临时存储数据
x.push_back(container);
y.push_back(hash);
z.push_back(sub_url);
}
// 打包结构压入ref中
maps.container = x;
maps.hash = y;
maps.sub_url = z;
ref.push_back(maps);
}
return ref;
}
// 扫描判断容器类型
void ScanPage(std::string urls)
{
std::vector<database_map> db_map = GetDataBase();
for (int x = 0; x < db_map.size(); x++)
{
// 依次将字典读入内存容器.
database_map maps = db_map[x];
std::vector<std::string> container = maps.container;
std::vector<std::string> hash = maps.hash;
std::vector<std::string> sub_url = maps.sub_url;
// 必须保证记录数完全一致
if (container.size() != 0 && hash.size() != 0 && sub_url.size() != 0)
{
for (int x = 0; x < container.size(); x++)
{
// 1.拼接字符串
std::string this_url = boost::str(boost::format("%s%s") % urls %sub_url[x]);
// 2.判断页面是否存在
long ref_status = GetStatus(this_url);
if (ref_status != 0 && ref_status == 200)
{
// 3.读入页面字符串,判断是否成功
std::string read_page = GetUrlPageOfString(this_url);
if (read_page != "None")
{
std::string check_md5 = GetMd5(read_page.c_str(), read_page.length());
std::cout << "[+] 页面MD5: " << check_md5 << std::endl;
std::cout << "[+] 数据库: " << hash[x] << std::endl;
// 4.比对MD5值是否相同
if (check_md5 == std::string(hash[x]))
{
std::cout << "[*] 诊断框架为: " << container[x] << std::endl;
break;
}
}
}
}
}
}
}
int main(int argc, char *argv[])
{
opt::options_description des_cmd("\n Usage: 容器识别助手 \n\n Options");
des_cmd.add_options()
("url,u", opt::value<std::string>(), "指定目标URL地址")
("get,g", opt::value<std::string>(), "提取页面指纹")
("help,h", "帮助菜单");
opt::variables_map virtual_map;
try
{
opt::store(opt::parse_command_line(argc, argv, des_cmd), virtual_map);
}
catch (...){ return 0; }
// 定义消息
opt::notify(virtual_map);
// 无参数直接返回
if (virtual_map.empty())
{
ShowOpt();
return 0;
}
// 帮助菜单
else if (virtual_map.count("help") || virtual_map.count("h"))
{
ShowOpt();
std::cout << des_cmd << std::endl;
return 0;
}
else if (virtual_map.count("url"))
{
std::string address = virtual_map["url"].as<std::string>();
ScanPage(address);
}
else if (virtual_map.count("get"))
{
std::string address = virtual_map["get"].as<std::string>();
std::string read_page = GetUrlPageOfString(address);
std::cout << "[+] 提取指纹: " << GetMd5(read_page.c_str(), read_page.length()) << std::endl;
}
else
{
std::cout << "参数错误" << std::endl;
}
return 0;
std::system("pause");
return 0;
}