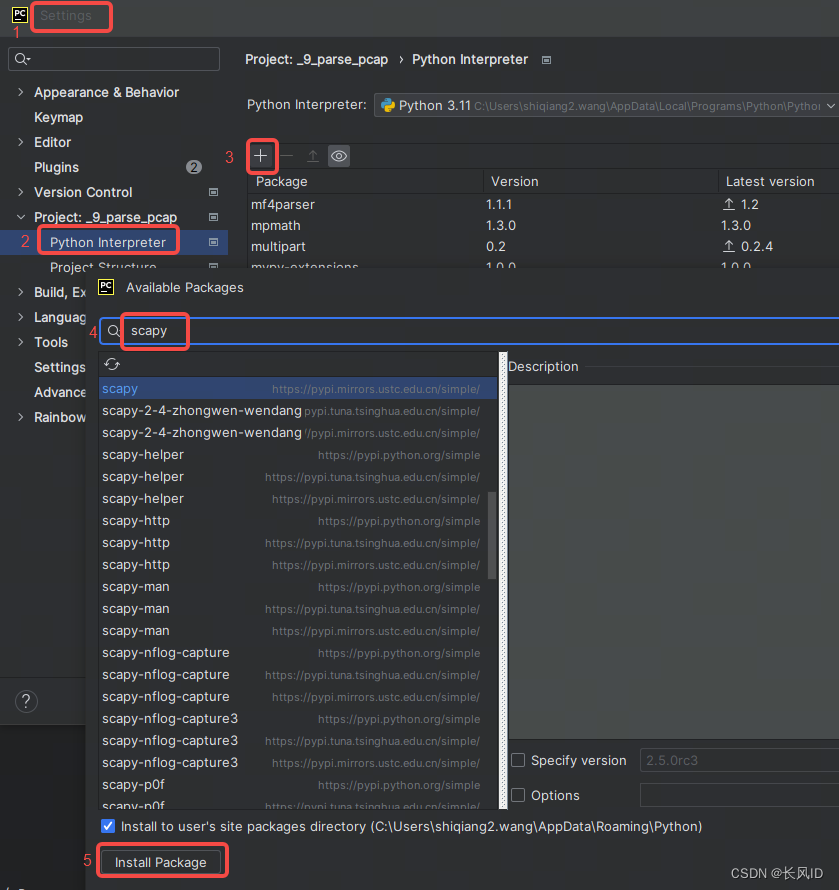
MindSpore基础教程:使用 MindCV和 Gradio 创建一个图像分类应用
官方文档教程使用已经弃用的MindVision模块,本文是对官方文档的更新
在这篇博客中,我们将探索如何使用 MindSpore 框架和 Gradio 库来创建一个基于深度学习的图像分类应用。我们将使用预训练的 ResNet50 模型,以 CIFAR-10 数据集为例进行训练,并通过 Gradio 接口进行图像分类预测。下面是一个简单、直观的指南,适用于希望将深度学习模型转换为交互式应用的开发者。
训练模型
环境设置
首先,我们需要设置 GPU 作为训练的目标设备。MindSpore 提供了一个便捷的方式来配置环境。
from mindspore import context
context.set_context(device_target="GPU")
解析参数
我们使用 argparse 来解析命令行参数。这样可以方便地在训练时调整参数,例如数据集路径、学习率和训练周期数。
import argparse
def parse_args():
"""
解析命令行参数。
返回:
argparse.Namespace: 包含命令行参数的命名空间。
"""
parser = argparse.ArgumentParser(description="训练 ResNet 模型",
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('--pretrain_path', type=str, default='',
help='预训练文件的路径')
parser.add_argument('--data_path', type=str, default='datasets/drizzlezyk/cifar10/',
help='训练数据的路径')
parser.add_argument('--output_path', default='train/resnet/', type=str,
help='模型保存路径')
parser.add_argument('--epochs', default=10, type=int, help='训练周期数')
parser.add_argument('--lr', default=0.0001, type=int, help='学习率')
return parser.parse_args()
创建数据集
使用 MindSpore 的 create_dataset 方法,我们可以轻松创建和预处理 CIFAR-10 训练数据集。
from mindcv.data import create_dataset, create_transforms, create_loader
def create_training_dataset(data_path, batch_size):
"""
创建训练数据集。
参数:
data_path (str): 数据集的路径。
batch_size (int): 批量大小。
返回:
Tuple[DataLoader, int]: 数据加载器和每个 epoch 的批次数量。
"""
dataset_train = create_dataset(name='cifar10', root=data_path, split='train', shuffle=True)
transform_train = create_transforms(dataset_name='cifar10', image_resize=224)
train_loader = create_loader(dataset=dataset_train, batch_size=batch_size, is_training=True,
num_classes=10, transform=transform_train)
num_batches = train_loader.get_dataset_size()
return train_loader, num_batches
模型训练
接下来,我们定义 train_model 函数来实现模型的训练逻辑。这包括模型的初始化、损失函数、优化器的设置,以及训练过程的启动。
from mindcv import create_model, create_loss, create_scheduler, create_optimizer
from mindspore.train import Model
from mindspore import load_checkpoint, load_param_into_net
def train_model(args):
"""
训练模型。
参数:
args (argparse.Namespace): 包含命令行参数的命名空间。
"""
train_loader, num_batches = create_training_dataset(args.data_path, batch_size=32)
net = create_model(model_name='resnet50', num_classes=10)
if args.pretrain_path:
param_dict = load_checkpoint(args.pretrain_path)
load_param_into_net(net, param_dict)
loss_fn = create_loss(name='CE', reduction='mean')
lr_scheduler = create_scheduler(steps_per_epoch=num_batches, scheduler='constant', lr=args.lr)
optimizer = create_optimizer(net.trainable_params(), opt='adam', lr=lr_scheduler)
model = Model(net, loss_fn=loss_fn, optimizer=optimizer, metrics={'accuracy'})
checkpoint_config = CheckpointConfig(save_checkpoint_steps=num_batches, keep_checkpoint_max=10)
checkpoint_callback = ModelCheckpoint(prefix='checkpoint_resnet', directory=args.output_path,
config=checkpoint_config)
model.train(args.epochs, train_loader,
callbacks=[checkpoint_callback, LossMonitor(), TimeMonitor(data_size=num_batches)])
构建 Gradio 接口
预测函数
在 Gradio 接口中,我们定义一个 predict_image 函数来处理图像输入并返回预测结果。
import gradio as gr
import numpy as np
from mindspore import Tensor
import cv2
def predict_image(img):
# 创建模型实例
net = create_model(model_name='resnet50', num_classes=NUM_CLASS)
param_dict = load_checkpoint('/root/MyCode/pycharm/ResNet50/train/resnet/checkpoint_resnet-5_1563.ckpt')
load_param_into_net(net, param_dict)
# 封装模型为 Model 类实例
model = Model(net)
# 调整图像格式和大小
img = cv2.resize(img, (224, 224))
img = np.array(img, dtype=np.float32) / 255.0 # 归一化并确保数据类型为 Float32
# 如果图像是 BGR 格式,转换为 RGB 格式
# img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 标准化处理
img = (img - np.array([0.485, 0.456, 0.406], dtype=np.float32)) / np.array([0.229, 0.224, 0.225], dtype=np.float32)
# 转换维度 - 通道优先格式 (C, H, W)
img = np.transpose(img, (2, 0, 1))
# 添加批次维度 (N, C, H, W)
img = np.expand_dims(img, axis=0)
# 将图像数据转换为 MindSpore 张量
img_tensor = Tensor(img, dtype=mindspore.float32) # 显式指定数据类型
# 预测图像
output = model.predict(img_tensor)
# 应用 Softmax 获取概率
softmax = Softmax(axis=1)
predict_probability = softmax(output).asnumpy()
predict_probability = predict_probability[0] # 获取批量中的第一个元素
# 将预测概率映射到类别名称
return {class_names[i]: float(predict_probability[i]) for i in range(NUM_CLASS)}
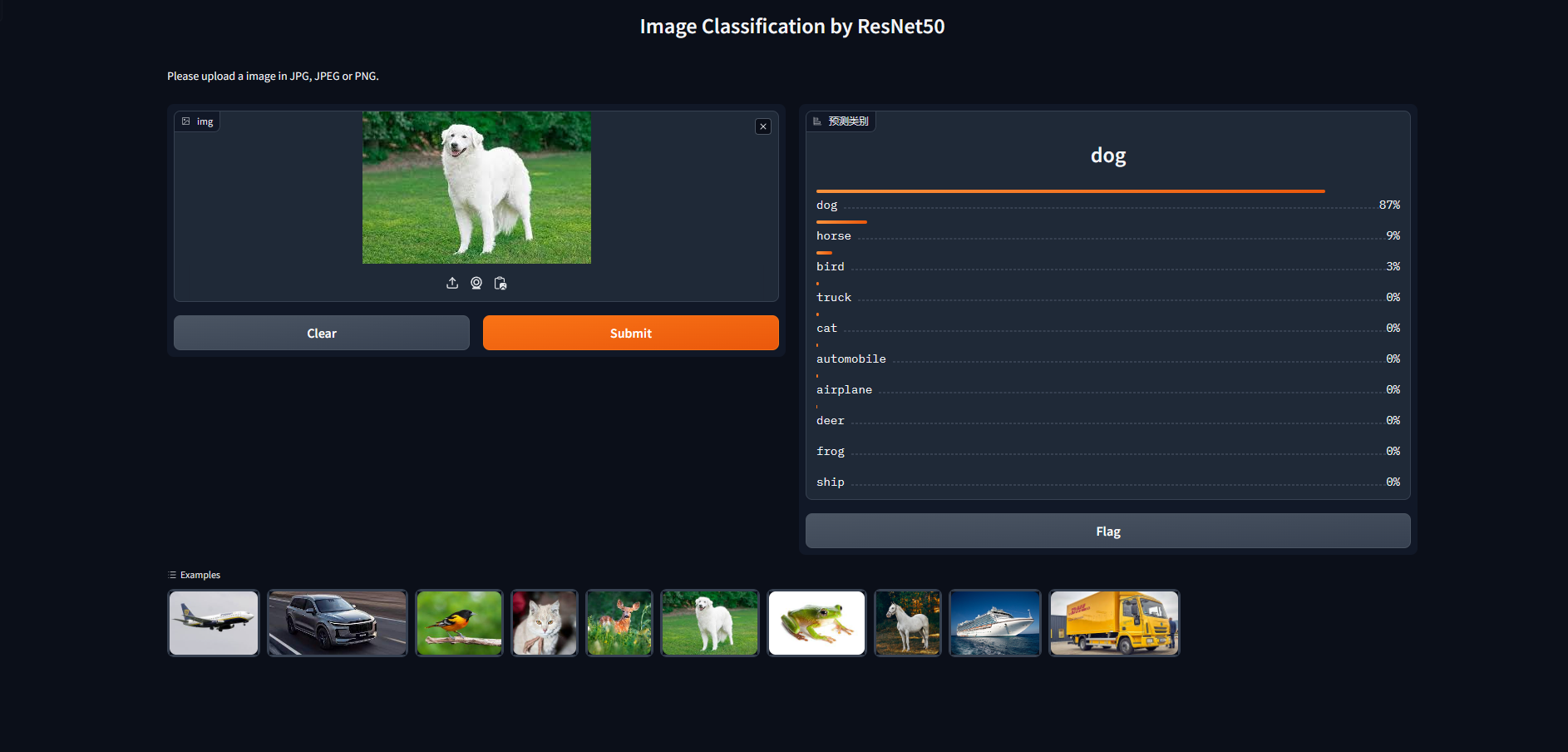
Gradio 界面
使用 Gradio,我们可以快速构建一个交互式界面。用户可以上传图片,模型将返回图像分类的预测结果。
image = gr.Image()
label = gr.Label(num_top_classes=NUM_CLASS)
gr.Interface(css=".footer {display:none !important}",
fn=predict_image,
inputs=image,
live=False,
description="Please upload a image in JPG, JPEG or PNG.",
title='Image Classification by ResNet50',
outputs=gr.Label(num_top_classes=NUM_CLASS, label="预测类别"),
examples=['./example_img/airplane.jpg', './example_img/automobile.jpg', './example_img/bird.jpg',
'./example_img/cat.jpg', './example_img/deer.jpg', './example_img/dog.jpg',
'./example_img/frog.jpg', './example_img/horse.JPG', './example_img/ship.jpg',
'./example_img/truck.jpg']
).launch(share=True)
完整代码
import argparse
from mindcv import create_model, create_loss, create_scheduler, create_optimizer
from mindspore.train import Model
from mindspore import load_checkpoint, load_param_into_net
from mindcv.data import create_dataset, create_transforms, create_loader
from mindspore import LossMonitor, TimeMonitor, CheckpointConfig, ModelCheckpoint
# 设置GPU
from mindspore import context
context.set_context(device_target="GPU")
def parse_args():
"""
解析命令行参数。
返回:
argparse.Namespace: 包含命令行参数的命名空间。
"""
parser = argparse.ArgumentParser(description="训练 ResNet 模型",
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('--pretrain_path', type=str, default='',
help='预训练文件的路径')
parser.add_argument('--data_path', type=str, default='datasets/drizzlezyk/cifar10/',
help='训练数据的路径')
parser.add_argument('--output_path', default='train/resnet/', type=str,
help='模型保存路径')
parser.add_argument('--epochs', default=10, type=int, help='训练周期数')
parser.add_argument('--lr', default=0.0001, type=int, help='学习率')
return parser.parse_args()
def create_training_dataset(data_path, batch_size):
"""
创建训练数据集。
参数:
data_path (str): 数据集的路径。
batch_size (int): 批量大小。
返回:
Tuple[DataLoader, int]: 数据加载器和每个 epoch 的批次数量。
"""
dataset_train = create_dataset(name='cifar10', root=data_path, split='train', shuffle=True)
transform_train = create_transforms(dataset_name='cifar10', image_resize=224)
train_loader = create_loader(dataset=dataset_train, batch_size=batch_size, is_training=True,
num_classes=10, transform=transform_train)
num_batches = train_loader.get_dataset_size()
return train_loader, num_batches
def train_model(args):
"""
训练模型。
参数:
args (argparse.Namespace): 包含命令行参数的命名空间。
"""
train_loader, num_batches = create_training_dataset(args.data_path, batch_size=32)
net = create_model(model_name='resnet50', num_classes=10)
if args.pretrain_path:
param_dict = load_checkpoint(args.pretrain_path)
load_param_into_net(net, param_dict)
loss_fn = create_loss(name='CE', reduction='mean')
lr_scheduler = create_scheduler(steps_per_epoch=num_batches, scheduler='constant', lr=args.lr)
optimizer = create_optimizer(net.trainable_params(), opt='adam', lr=lr_scheduler)
model = Model(net, loss_fn=loss_fn, optimizer=optimizer, metrics={'accuracy'})
checkpoint_config = CheckpointConfig(save_checkpoint_steps=num_batches, keep_checkpoint_max=10)
checkpoint_callback = ModelCheckpoint(prefix='checkpoint_resnet', directory=args.output_path,
config=checkpoint_config)
model.train(args.epochs, train_loader,
callbacks=[checkpoint_callback, LossMonitor(), TimeMonitor(data_size=num_batches)])
if __name__ == '__main__':
train_model(parse_args())
import gradio as gr
import numpy as np
from mindspore import Tensor
from mindspore.nn import Softmax
import cv2
from typing import Type, Union, List, Optional
from mindspore import nn
from mindspore import load_checkpoint, load_param_into_net
from mindspore.train import Model
from mindcv.models import create_model
import mindspore
print(mindspore.__version__)
NUM_CLASS = 10
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
def predict_image(img):
# 创建模型实例
net = create_model(model_name='resnet50', num_classes=NUM_CLASS)
param_dict = load_checkpoint('/root/MyCode/pycharm/ResNet50/train/resnet/checkpoint_resnet-5_1563.ckpt')
load_param_into_net(net, param_dict)
# 封装模型为 Model 类实例
model = Model(net)
# 调整图像格式和大小
img = cv2.resize(img, (224, 224))
img = np.array(img, dtype=np.float32) / 255.0 # 归一化并确保数据类型为 Float32
# 如果图像是 BGR 格式,转换为 RGB 格式
# img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 标准化处理
img = (img - np.array([0.485, 0.456, 0.406], dtype=np.float32)) / np.array([0.229, 0.224, 0.225], dtype=np.float32)
# 转换维度 - 通道优先格式 (C, H, W)
img = np.transpose(img, (2, 0, 1))
# 添加批次维度 (N, C, H, W)
img = np.expand_dims(img, axis=0)
# 将图像数据转换为 MindSpore 张量
img_tensor = Tensor(img, dtype=mindspore.float32) # 显式指定数据类型
# 预测图像
output = model.predict(img_tensor)
# 应用 Softmax 获取概率
softmax = Softmax(axis=1)
predict_probability = softmax(output).asnumpy()
predict_probability = predict_probability[0] # 获取批量中的第一个元素
# 将预测概率映射到类别名称
return {class_names[i]: float(predict_probability[i]) for i in range(NUM_CLASS)}
image = gr.Image()
label = gr.Label(num_top_classes=NUM_CLASS)
gr.Interface(css=".footer {display:none !important}",
fn=predict_image,
inputs=image,
live=False,
description="Please upload a image in JPG, JPEG or PNG.",
title='Image Classification by ResNet50',
outputs=gr.Label(num_top_classes=NUM_CLASS, label="预测类别"),
examples=['./example_img/airplane.jpg', './example_img/automobile.jpg', './example_img/bird.jpg',
'./example_img/cat.jpg', './example_img/deer.jpg', './example_img/dog.jpg',
'./example_img/frog.jpg', './example_img/horse.JPG', './example_img/ship.jpg',
'./example_img/truck.jpg']
).launch(share=True)
总结
通过 MindSpore 和 Gradio,我们可以不仅训练强大的深度学习模型,还可以将这些模型转化为交互式应用,使非专业人士也能轻松体验 AI 的魅力。