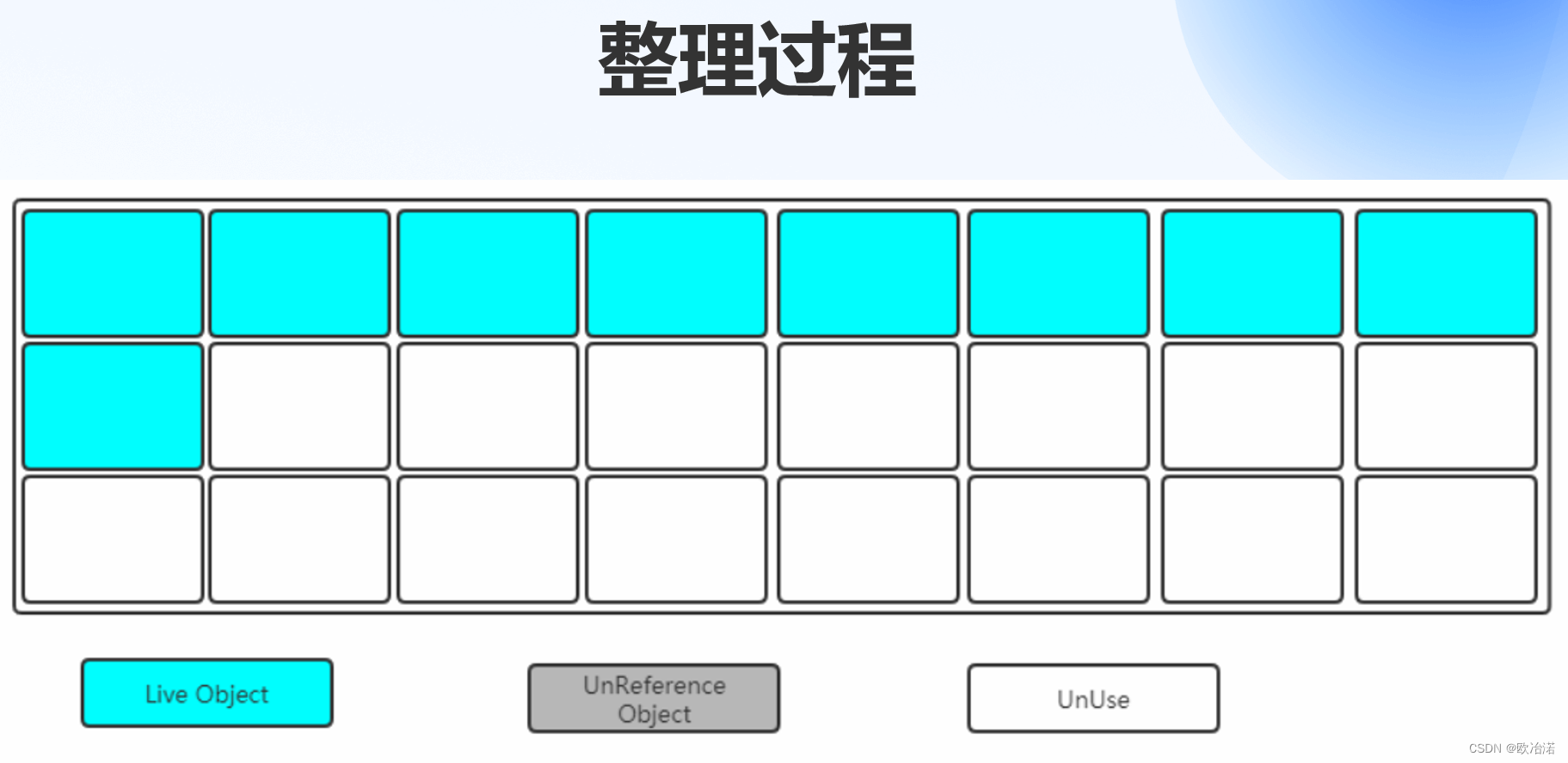
1.算法的分类
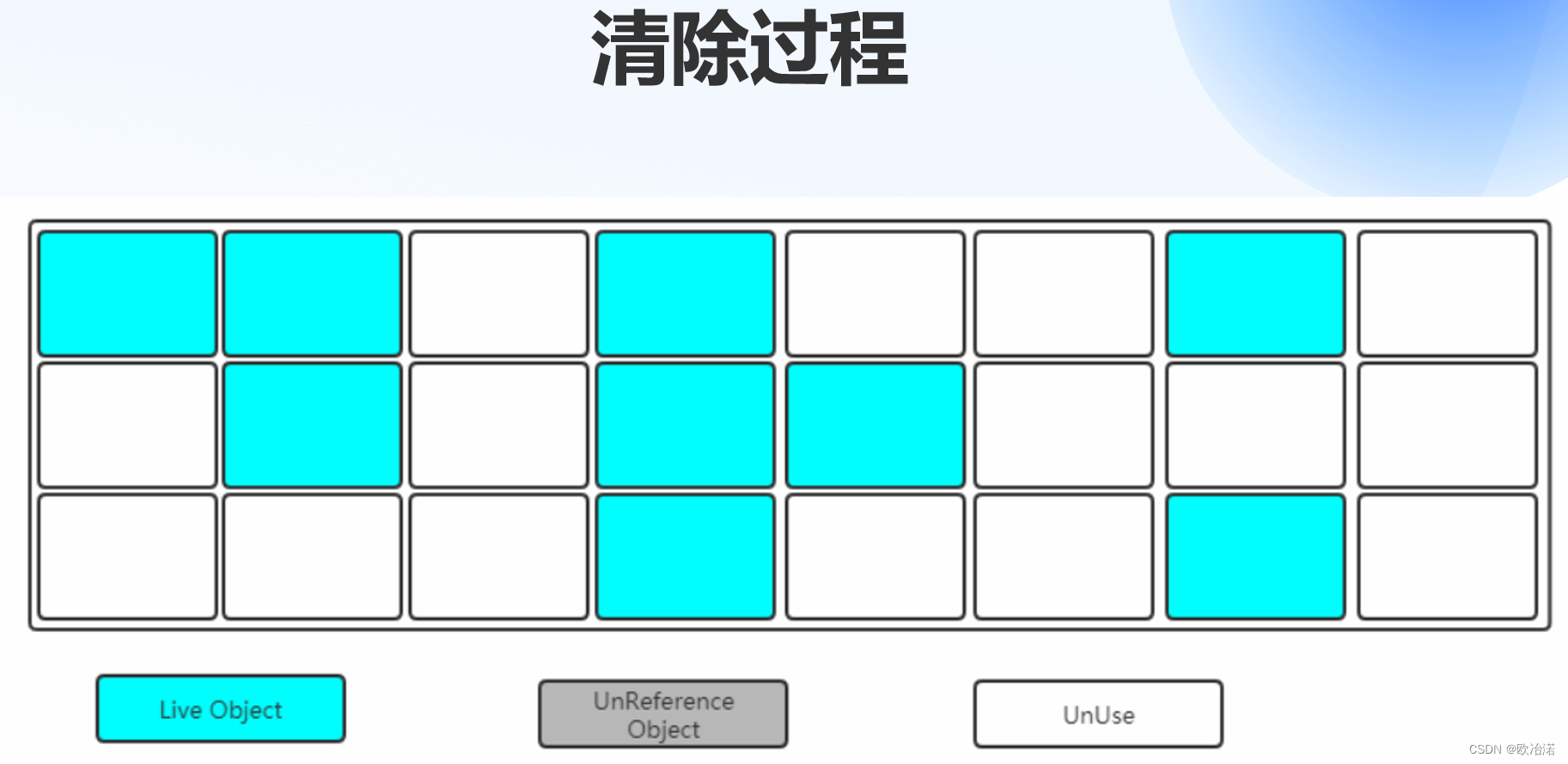
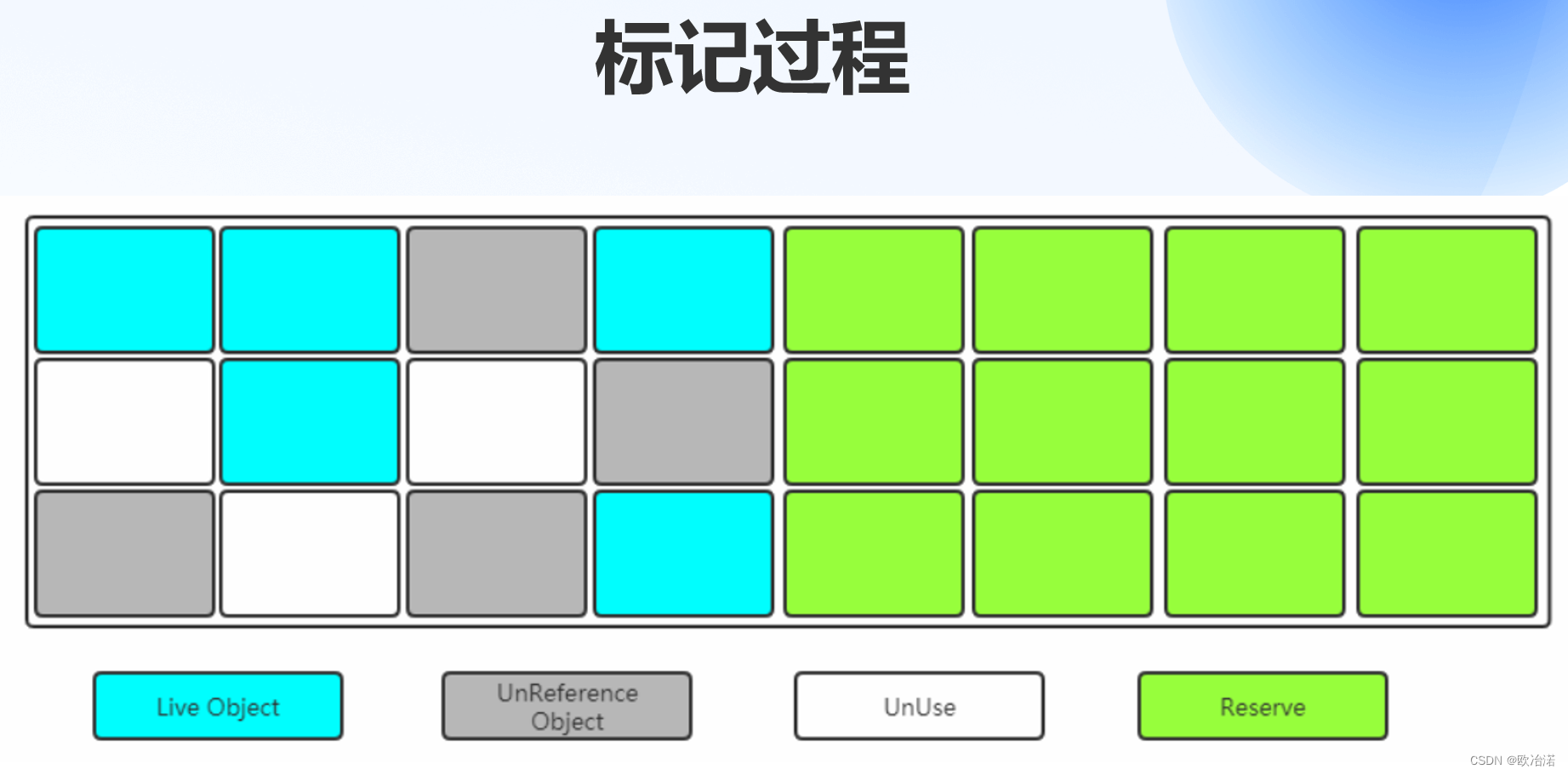
1.1标记清除算法
第一步:标记(找出内存中需要回收的对象,并且把它们标记出来)
根据可达性算法,标记的是存活的对象,然后将其他的空间进行回收
第二步:清除(清除掉被标记需要回收的对象,释放出对应的内存空间)
1.1.2缺点:
标记清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致以后在程序运行过程中需要分配较大对象时,无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。
(1)标记和清除两个过程都比较耗时,效率不高
(2)会产生大量不连续的内存碎片,空间碎片太多可能会导致以后在程序运行过程中需要分配较大对象时,无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。
1.1.3算法过程:

1.1.4标记清除算法的衍生规则之分配(动态分区分配策略)
首次适应算法(Fisrt-fit)
就是在遍历空闲链表的时候,一旦发现有大小等于需要的大小之后,就立即把该块分配给对象,并立即返回。
缺点:
首次GC后,找到了一个大小合适的空闲空间,直接将该对象放入,导致后面的没有遍历,后面的碎片化和空闲极大
最佳适应算法(Best-fit)
就是在遍历空闲链表的时候,返回刚好等于需要大小的块
缺点:
需要遍历全表
最差适应算法(Worst-fit)
就是在遍历空闲链表的时候,找出空闲链表中最大的分块,将其分割给申请的对象,其目的就是使得分割后分块的最大化,以便下次好分配,不过这种分配算法很容易产生很多很小的分块,这些分块也不能被使用
缺点:
找到最大的直接放入,如果找到的空闲块有5个,但是申请的对象只有4个空间块,那就会空出来一个,导致内存碎片化严重,如果找到的空闲块有5个,但是申请的对象却有6个空间块,那就会报内存溢出
1.2标记复制算法
1.2.1标记复制算法过程
将内存划分为两块相等的区域,每次只使用其中一块。 当其中一块内存使用完了,就将还存活的对象复制到另外一块上面,然后把已经使用过的内存空间一次清除掉。
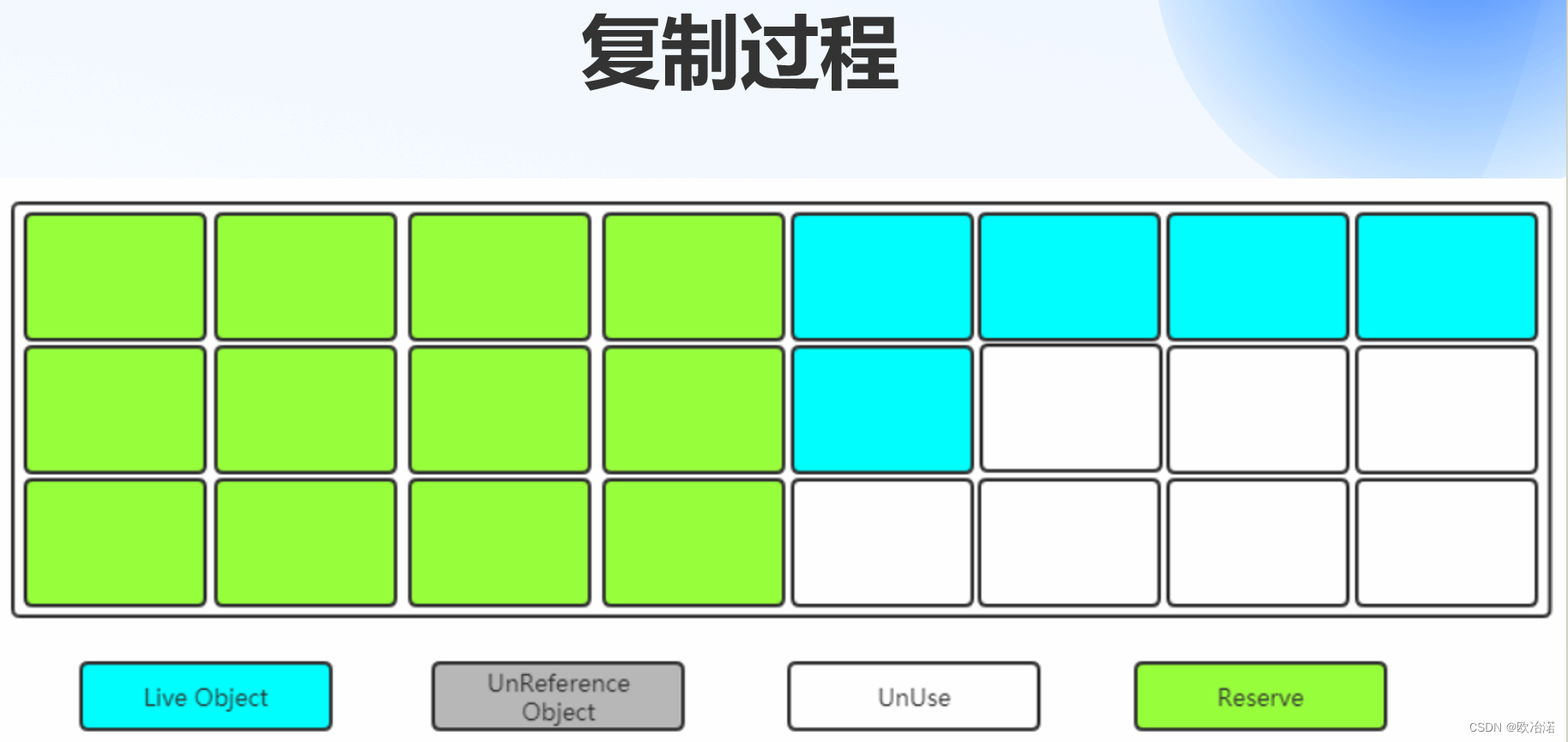
1.2.2缺点
内存的利用只有一半
1.3标记整理(压缩)算法
标记整理算法严格意义应该叫做标记清除整理算法或者标记清除压缩算法
因为他的本质就是在标记清除的基础在进行再整理
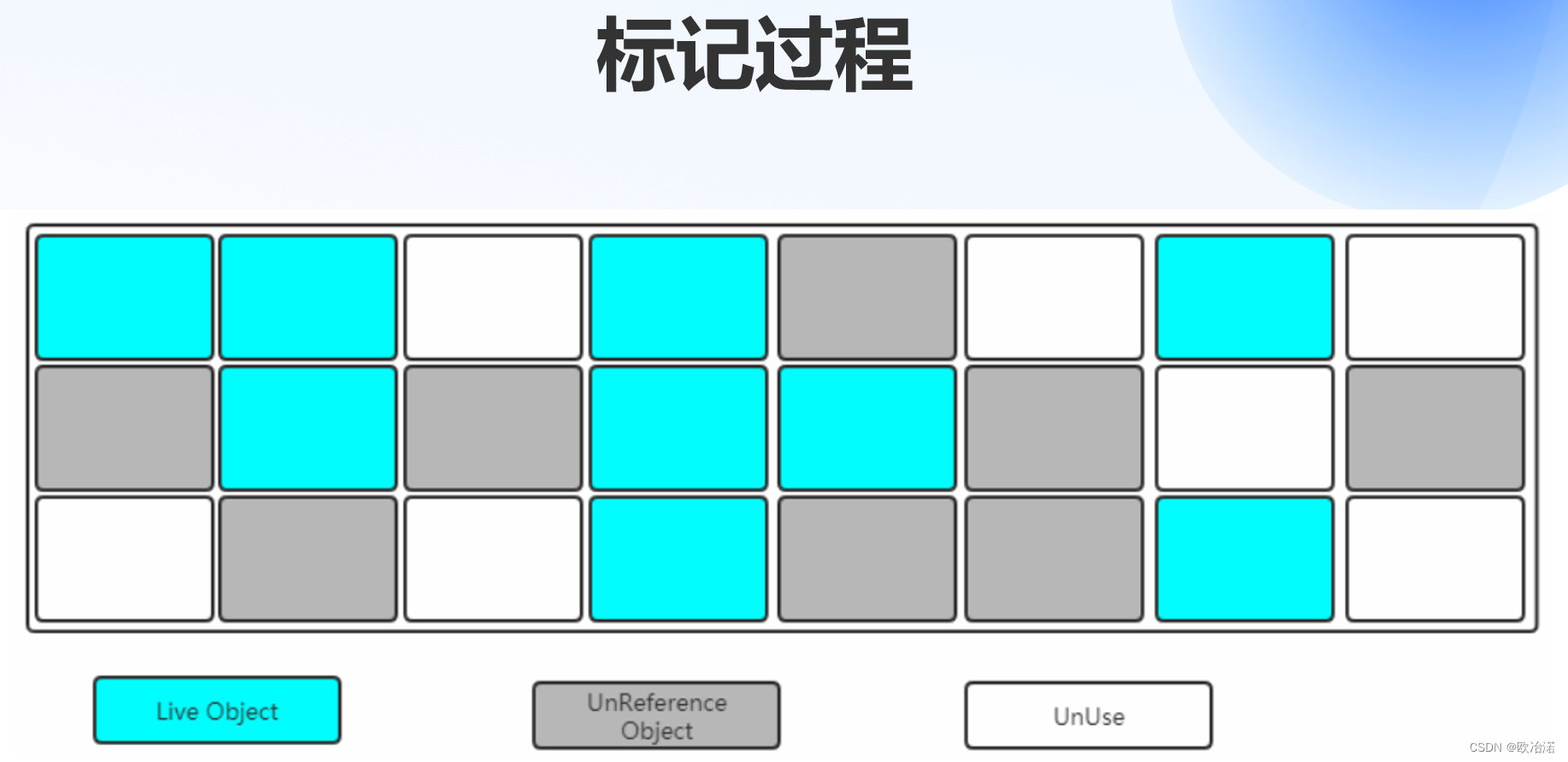
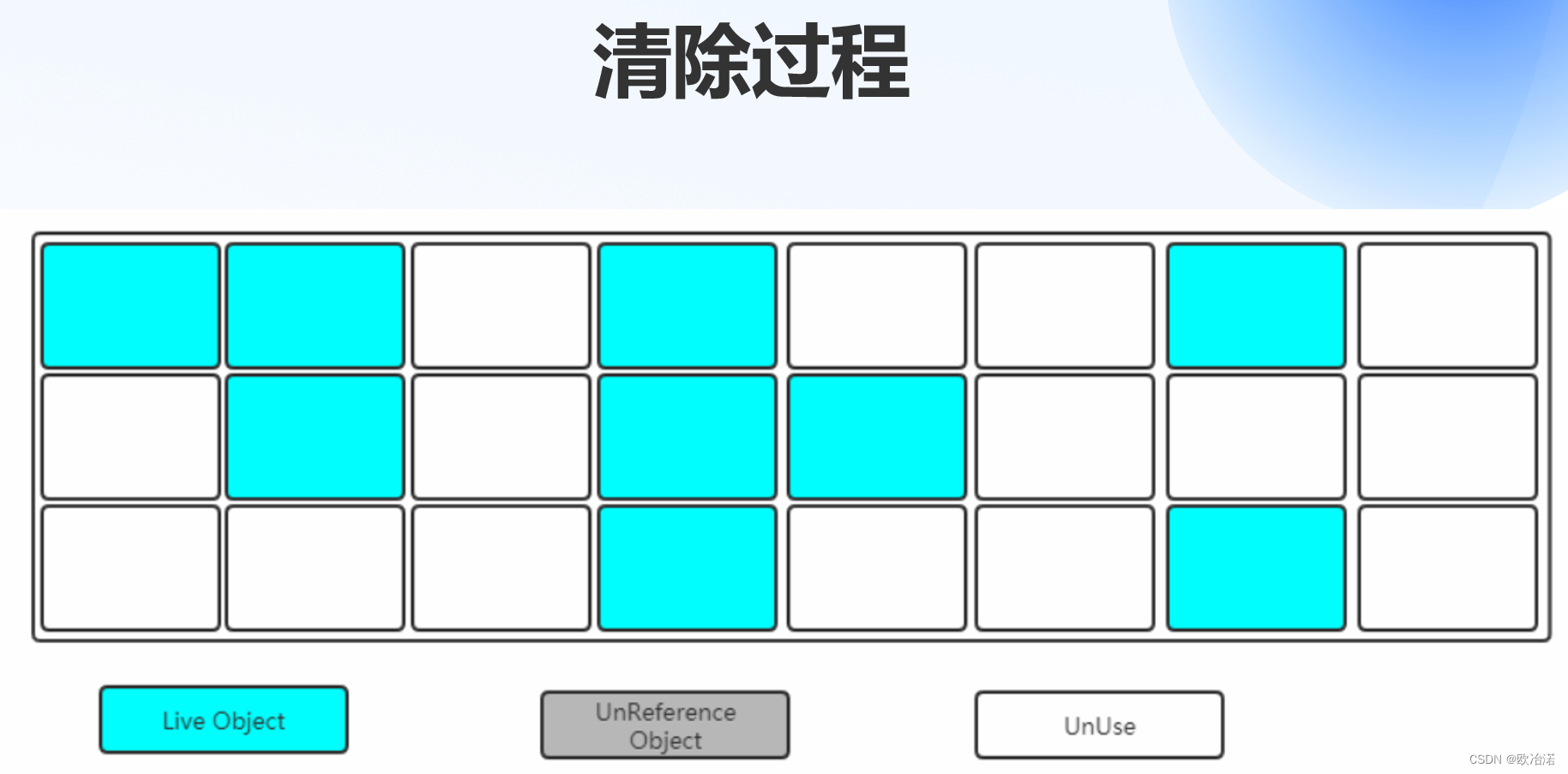
1.3.1标记整理(压缩)算法衍生算法
1.3.1.1随机整理
对象的移动方式和它们初始的对象排列及引用关系无关
原本的内存布局3-4是连续的

整理后由于1已经没有了4补上来导致内存不连续
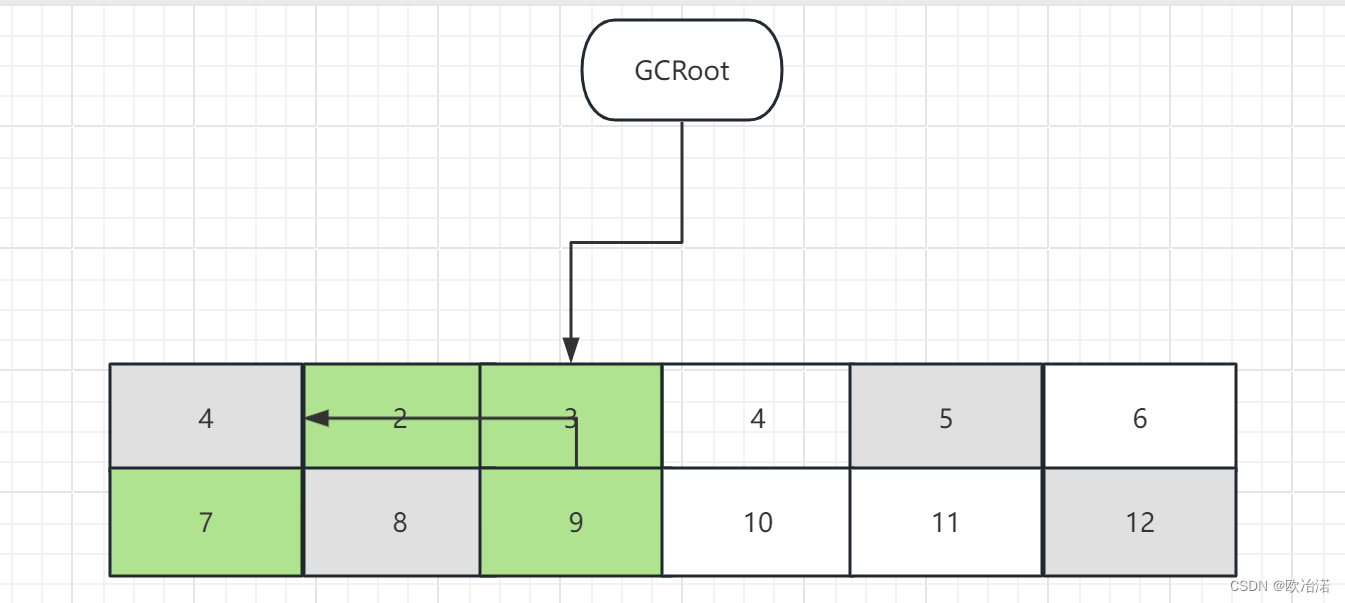
任意顺序整理实现简单,且执行速度快,但任意顺序可能会将原本相邻的对象打乱到不同的高速缓存行或者是虚拟内存页中(理解为打乱到内存各个地方),会降低赋值器的局部性。 包括他只能处理固定大小的对象,一旦对象大小不固定,就会增加其他的逻辑。
1.3.1.2线性整理
将具有关联关系的对象排列在一起
相关的对象会进行整理,整理成一块块小区域,无法避免内存碎片
将7、9有关联得对象放在一起,只会整理一个块有关联得对象,不会将所有有用的对象整理到一起,导致内存碎片很多

1.3.1.3滑动整理
将对象“滑动”到堆的一端,从而“挤出”垃圾,可以保持对象在堆中原有的顺序
1.3.2几种典型的整理算法
1.3.2.1双指针回收算法:
实现简单且速度快,但会打乱对象的原有布局,属于随机整理
整理流程:
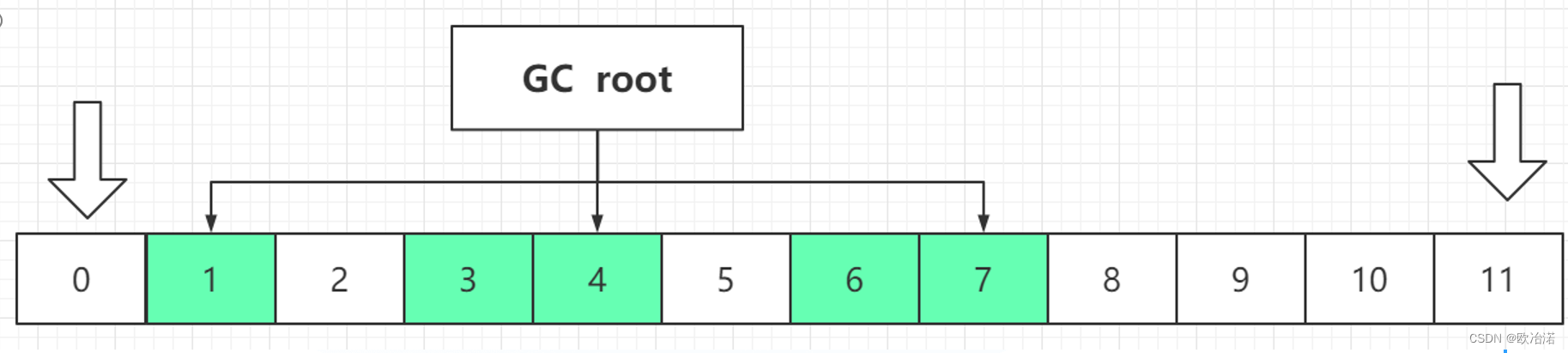
第一次遍历:移动位置但是并不更新标记
头指针找空闲的单元(可达的对象时非空的单元),尾指针向前找可达的,直到找到头指针的找到的空闲单元,也就是两个指针走到同一个单元上
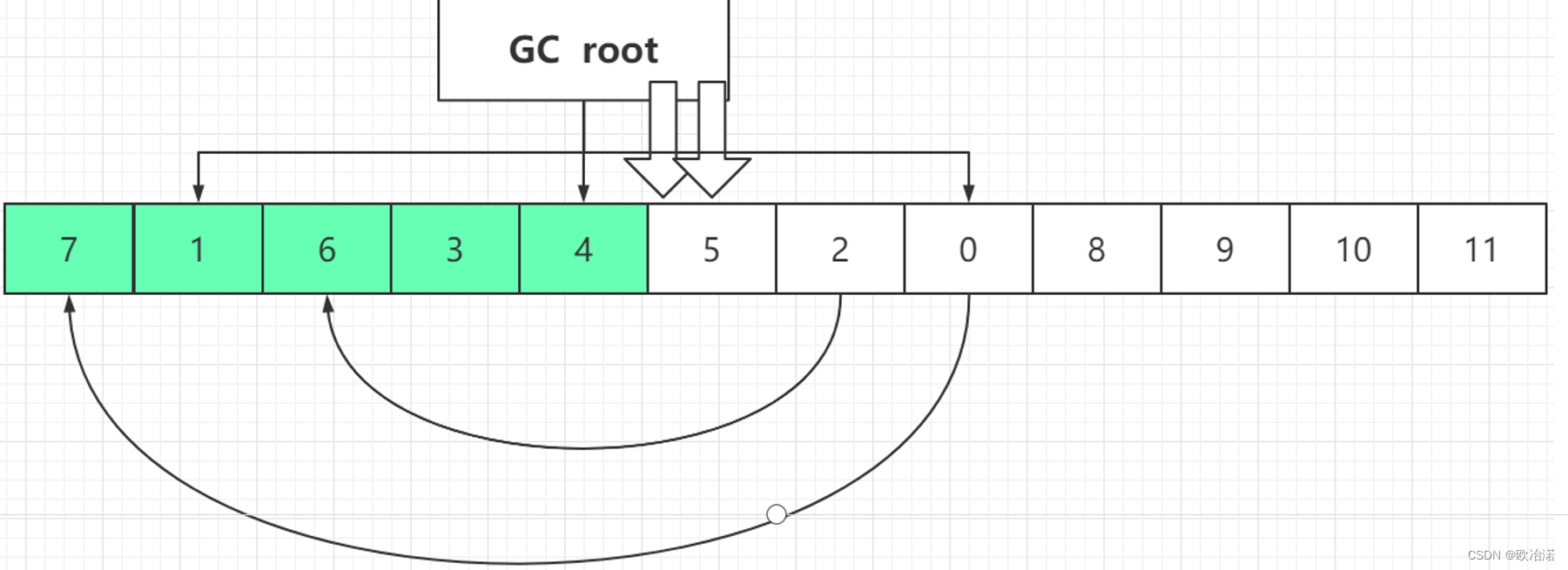 第二次遍历:更新标记
第二次遍历:更新标记
一个指针向前移动,找大于下标4的对象,并更新GCroot的引用关系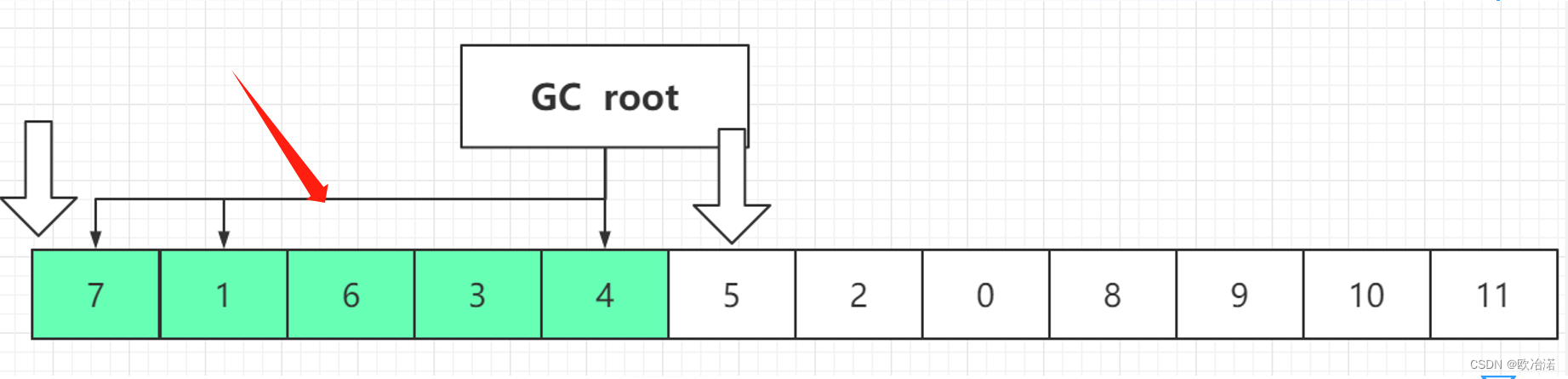
缺点:
这种算法遇到内存大小不一的情况,就无法将尾端的对象直接拿到前面(假设后面的对象是前面对象大小的2倍,前面只空出来一个格子,这时就放不进去了)
解决这个问题:
头指针记算一下当前空闲对象的空间,在往后走,直到找到可以放下后面要移动的对象
1.3.2.2Lisp2算法(滑动整理算法):
需要在对象头用一个额外的槽来保存迁移完的地址
整理前:他是一个三指针算法,并且可以处理不同大小的对象。但是需要三次遍历,并且由于对象大小不一样,所以需要额外的空间存储,而不是直接移动

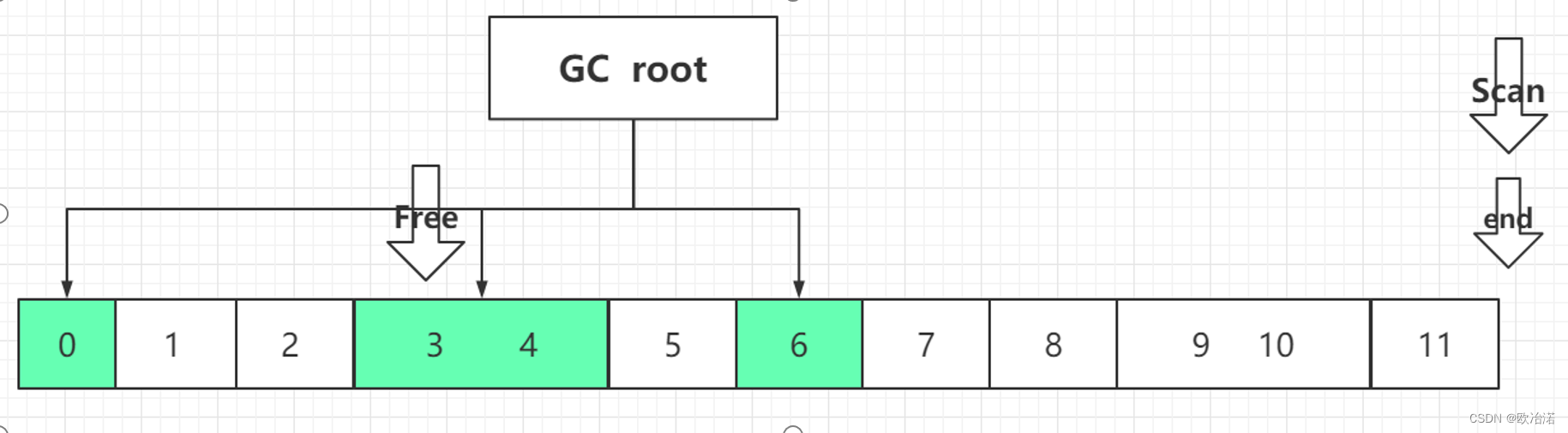
第一次遍历:Free指针是为了留位置,而Scan对象是为了找存活对象
free的位置:free在第一个可达对象后进行移动
Scan找可达的对象,找到后进行标记,并记下使用的空间,并将这个值给到free指针,free在进行移动
如,Scan在0的位置记录空间是1,走到3的位置记录下空间是2,走到6的位置时记录下空间是1,那么Free指针的位置就是4,。也就是3的位置
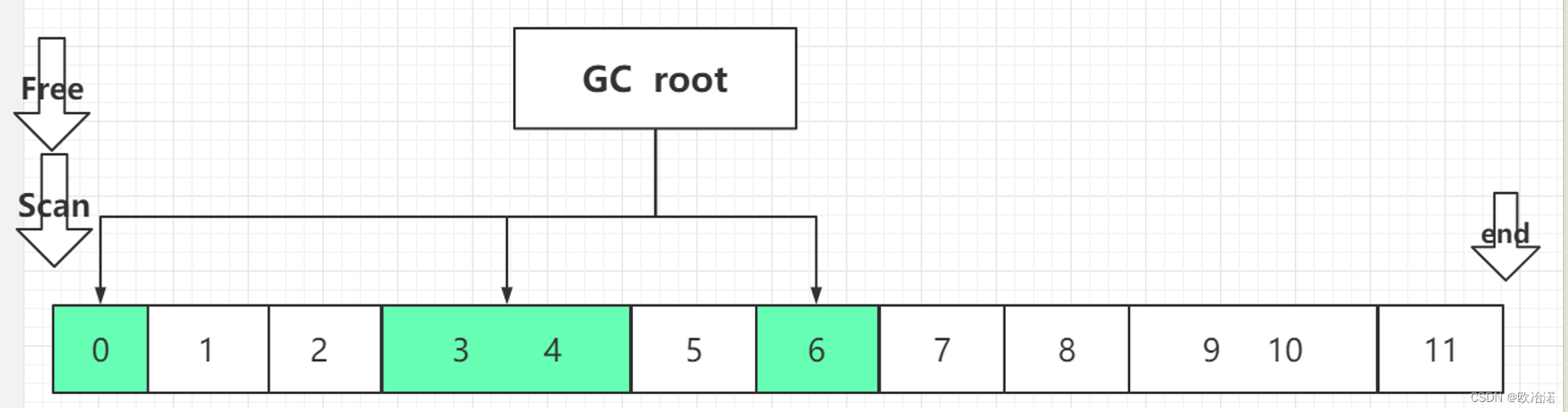
 第二次遍历:更新对象地址
第二次遍历:更新对象地址
end指针只是为了标记尾端,让Scan指针直到走到尾了
第三次遍历:移动对象
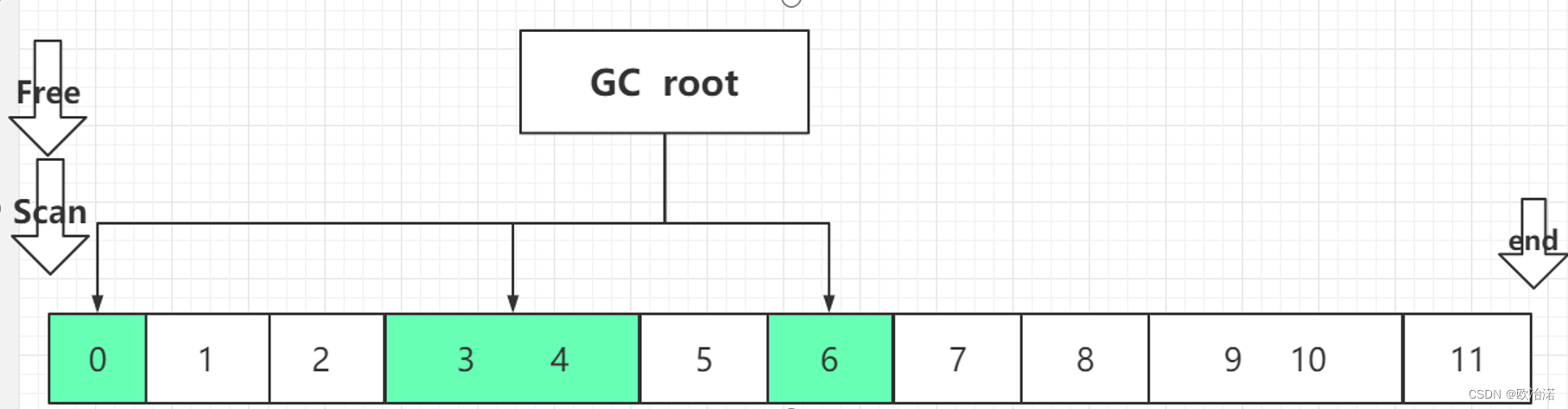 为什么要先修改对象地址,在移动对象
为什么要先修改对象地址,在移动对象
假设先移动对象,将6直接移动到3的位置这时就会发生对象覆盖的情况,由于指针信息是存在对象中的,备覆盖了这个对象就无法再更改引用关系了
1.3.2.3引线整理算法:(基本不用)
可以在不引入额外空间开销的情况下实现滑动整理,但需要2次遍历堆, 且遍历成本较高
1.3.2.4单次遍历算法:
滑动回收,实时计算出对象的转发地址而不需要额外的开销
单次遍历算法的重点在于提前记录我们需要转移的位置 关键词:偏移向量,标记向量以及内存索引号
开辟一块额外的空间并将内存划分成一块一块的,用于记录偏移向量(要移动的对象从哪到哪),标记向量(移动到什么位置)以及内存索引号(现在的位置)
第一次遍历将这些信息记录下来,第二次遍历进行位置移动

1.3.3总结:
所有现代的标记-整理回收器均使用滑动整理,它不会改变对象的相对顺序,也就不会影响赋值器的空间局部性。复制式回收器甚至可以通过改变对象布局的方式,将对象与其父节点或者兄弟节点排列的更近以提高赋值器的空间局部性
1.3.3.4限制:
整理算法的限制,如任意顺序算法只能处理单一大小的对象,或者针对大小不同的对象需要分批处理;整理过程需要2次或者3次遍历堆空间;对象头部可能需要一个额外的槽来保存迁移的信息。
2.分代收集理论
当前主流商业 JVM 的垃圾收集器,大多数都遵循了 分代收集(Generational Collection)的理论进行设计,这里需要解释下,很多博客都会把分代收集当成一种具体的垃圾收集算法,其实并不是,分代收集只是一种理论,一套指导方针,一套符合大多数程序运行实际情况的经验法则,它建立在几个分代假说之上
2.1分代回收三大假说:

2.1.1弱分代假说:
绝大多数对象朝生夕死
这个对应Eden区,通过一次局部GC就可以回收绝大部分对象
2.1.2强分代假说:
活得越久的对象,也就是熬过很多次垃圾回收的对象是越来越难以消亡的
这个对于old区当对象年龄大于15时,就将其放入空间更大的老年区
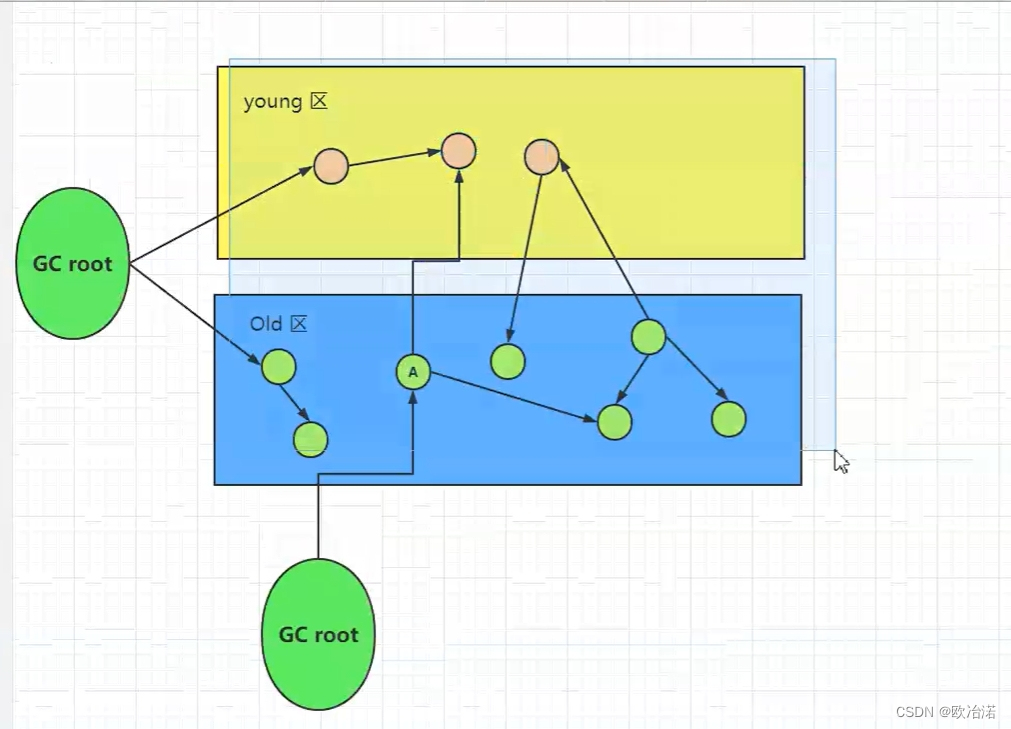
2.1.3跨代引用假说
老年代引用了青年代里面的对象,或者青年代中的对象引用了老年代中的对象。