混合测试自动化框架(关键字+数据驱动)
关键字驱动或表驱动的测试框架
这个框架需要开发数据表和关键字。这些数据表和关键字独立于执行它们的测试自动化工具,并可以用来“驱动"待测应用程序和数据的测试脚本代码,关键字驱动测试看上去与手工测试用例很类似。在一个关键字驱动测试中,把待测应用程序的功能和每个测试的执行步骤一起写到一个表中。
这个测试框架可以通过很少的代码来产生大量的测试用例。同样的代码在用数据表来产生各个测试用例的同时被复用。
混合测试自动化框架
最普遍的执行框架是上面介绍的所有技术的一个结合,取其长处,弥补其不足。这个混合测试框架是由大部分框架随着时间并经过若干项目演化而来的。
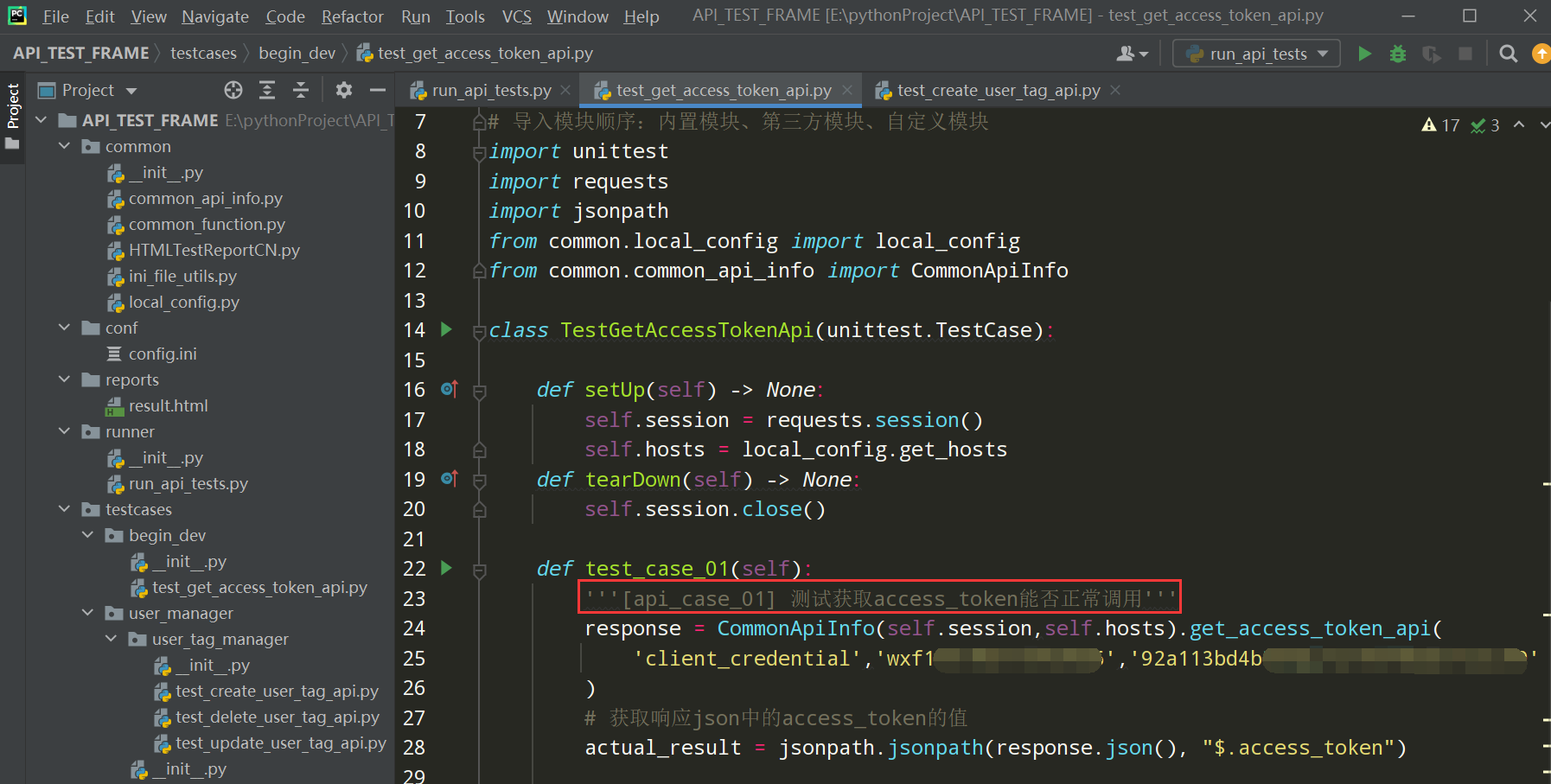
unittest关于测试报告展示用例名称的细节:
在unittest有两个内置属性,可以自定义用例名称
之前的效果:

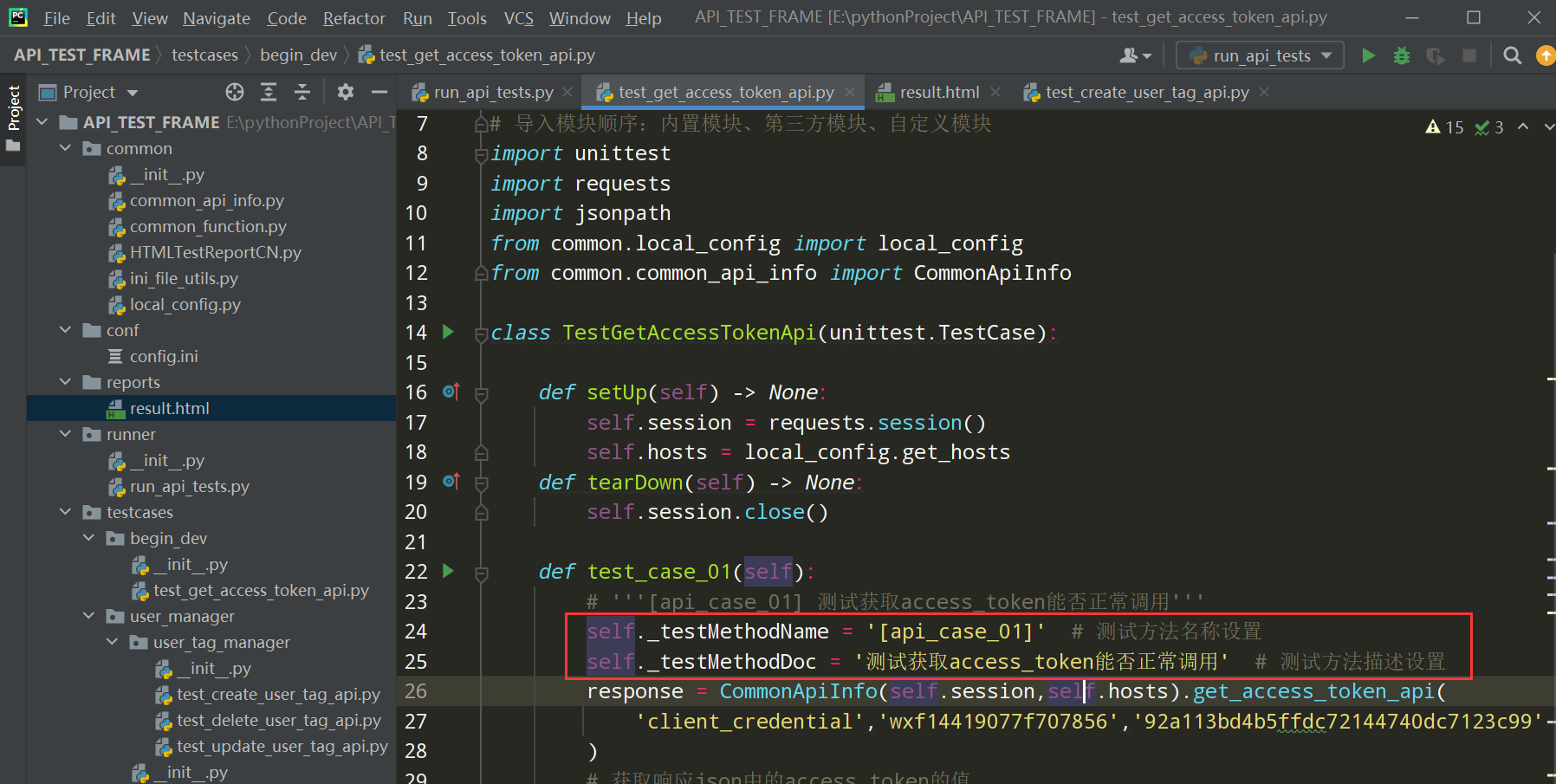
使用内置属性效果:
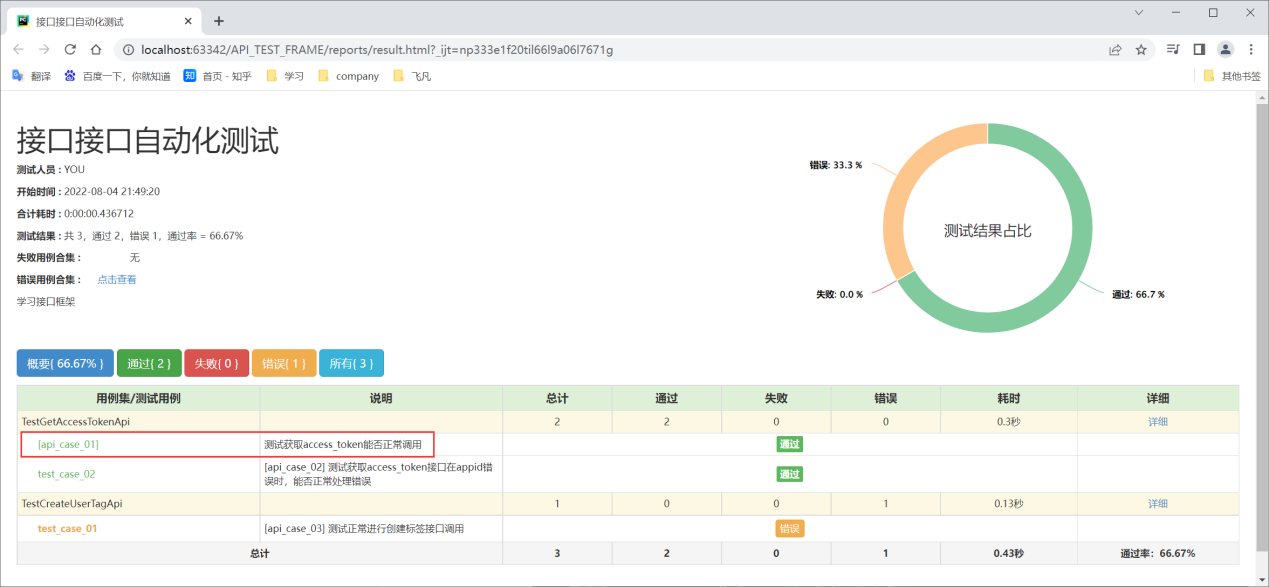
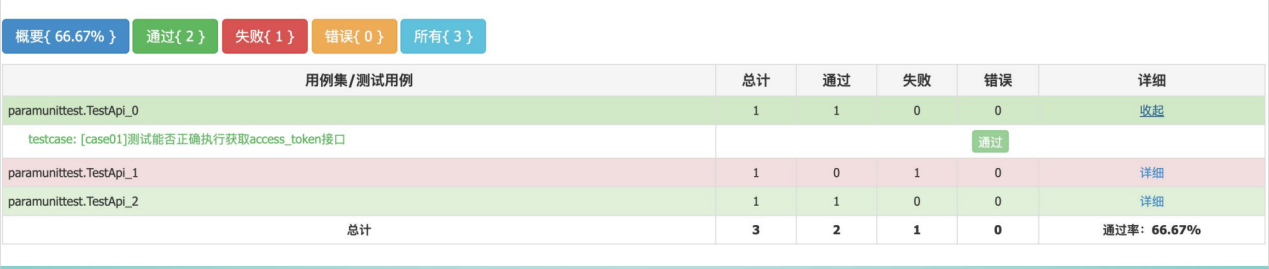
框架设计目标
设计出来的框架是直接给测试人员,而且其他的测试人员只需要简单的向里面不断的补充测试用例即可;所以我们的框架设计必须三简化即操作简单,维护简单,扩展简单。
设计框架的同时一定要结合业务流程,而不仅仅靠技术实现,其实技术实现不难,难点对业务流程的理解和把握。
设计框架时要将基础的封装成公用的,如:get请求、post请求和断言封装成同基础通用类。
测试用例要与代码分开,这样便于用例管理,采用数据驱动框架实现。
如下图所示:
通过在excel录入测试用例,框架运行后自动进行用例执行,产生html网页版本的测试报告。

报告结果:
框架用到的技术点
1、语言:python
2、测试框架:unittest(assertEqual)或pytest
3、接口调用:requests(API非常简洁)
4、数据驱动:paramunittest (组装一定的格式数据就可以参数化)
5、数据管理:xlrd(读取excel文件数据)、configparser(读取配置文件)
6、数据格式的转换:ast,json
7、日志处理:logging ---清晰的执行过程,快速定位问题
8、测试报表:HTMLTestReportCN(由网友制作设计,显示清晰美观)
9、测试邮件发送测试报告:smtplib(邮件内容格式设置)、email(收发邮件)
10、持续集成:Jenkins(按策略执行接口测试脚本)
(推荐)混合测试自动化框架(关键字+数据驱动)
数据源实现:
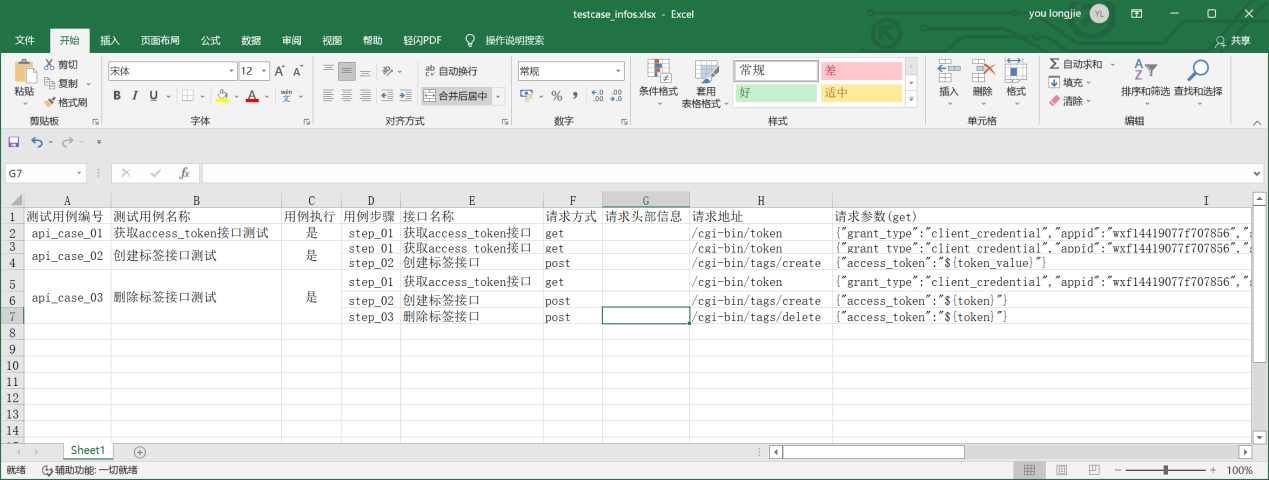
数据源目前使用excel,数据如下:
链接:https://pan.baidu.com/s/1VvvGYRvGbElSlP6ngg0ktw
提取码:ppua
自动化测试相关教程推荐:
2023最新自动化测试自学教程新手小白26天入门最详细教程,目前已有300多人通过学习这套教程入职大厂!!_哔哩哔哩_bilibili
2023最新合集Python自动化测试开发框架【全栈/实战/教程】合集精华,学完年薪40W+_哔哩哔哩_bilibili
测试开发相关教程推荐
2023全网最牛,字节测试开发大佬现场教学,从零开始教你成为年薪百万的测试开发工程师_哔哩哔哩_bilibili
postman/jmeter/fiddler测试工具类教程推荐
讲的最详细JMeter接口测试/接口自动化测试项目实战合集教程,学jmeter接口测试一套教程就够了!!_哔哩哔哩_bilibili
2023自学fiddler抓包,请一定要看完【如何1天学会fiddler抓包】的全网最详细视频教程!!_哔哩哔哩_bilibili
2023全网封神,B站讲的最详细的Postman接口测试实战教学,小白都能学会_哔哩哔哩_bilibili
思路:使用python读取excel数据;使用xlrd3
框架01:新建项目API_KEY_WORD_TEST_FRAME;
步骤1、在项目根目录下新建common的py文件夹和conf的普通文件夹;samples文件夹是用来写测试代码的demo;
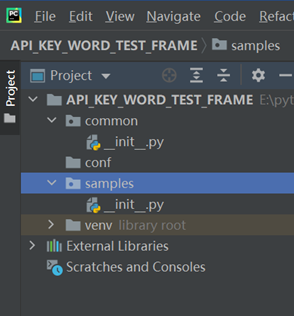
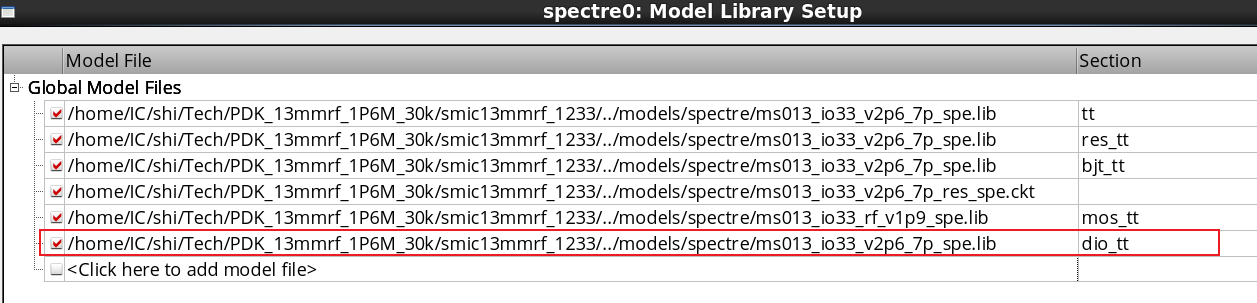
步骤2、在conf下新建config.ini文件

编写代码:
[default] # 主机地址 hosts = api.weixin.qq.com
步骤3、在common下新建ini_file_utils.py文件和config_utils.py文件
ini_file_utils.py文件如下:

总结:
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

如果对你有帮助的话,点个赞收个藏,给作者一个鼓励。也方便你下次能够快速查找。
如有不懂还要咨询下方小卡片,博主也希望和志同道合的测试人员一起学习进步
在适当的年龄,选择适当的岗位,尽量去发挥好自己的优势。
我的自动化测试开发之路,一路走来都离不每个阶段的计划,因为自己喜欢规划和总结,
测试开发视频教程、学习笔记领取传送门!!

编写代码:
![]()
# encoding: utf-8
# @author: Jeffrey
# @file: ini_file_utils.py
# @time: 2022/8/4 22:23
# @desc: 读取、写入ini文件
import os
import configparser
class IniFileUtils: #和框架业务无关的底层代码==》公共底层代码
def __init__(self,file_path):
self.ini_file_path = file_path
self.conf_obj = configparser.ConfigParser()
self.conf_obj.read(self.ini_file_path, encoding='utf-8')
def get_config_value(self,section, key):
value = self.conf_obj.get(section, key)
return value
def set_config_value(self,section, key, value):
'''设置config.ini文件中的值'''
self.conf_obj.set(section, key, value)
config_file_obj = open(self.ini_file_path, 'w')
self.conf_obj.write(config_file_obj)
config_file_obj.close()
if __name__ == '__main__':
current_path = os.path.dirname(__file__)
config_file_path = os.path.join(current_path, '../conf/config.ini')
ini_file = IniFileUtils(config_file_path)
print(ini_file.get_config_value('default', 'HOSTS'))
![]()
config_utils.py文件如下:
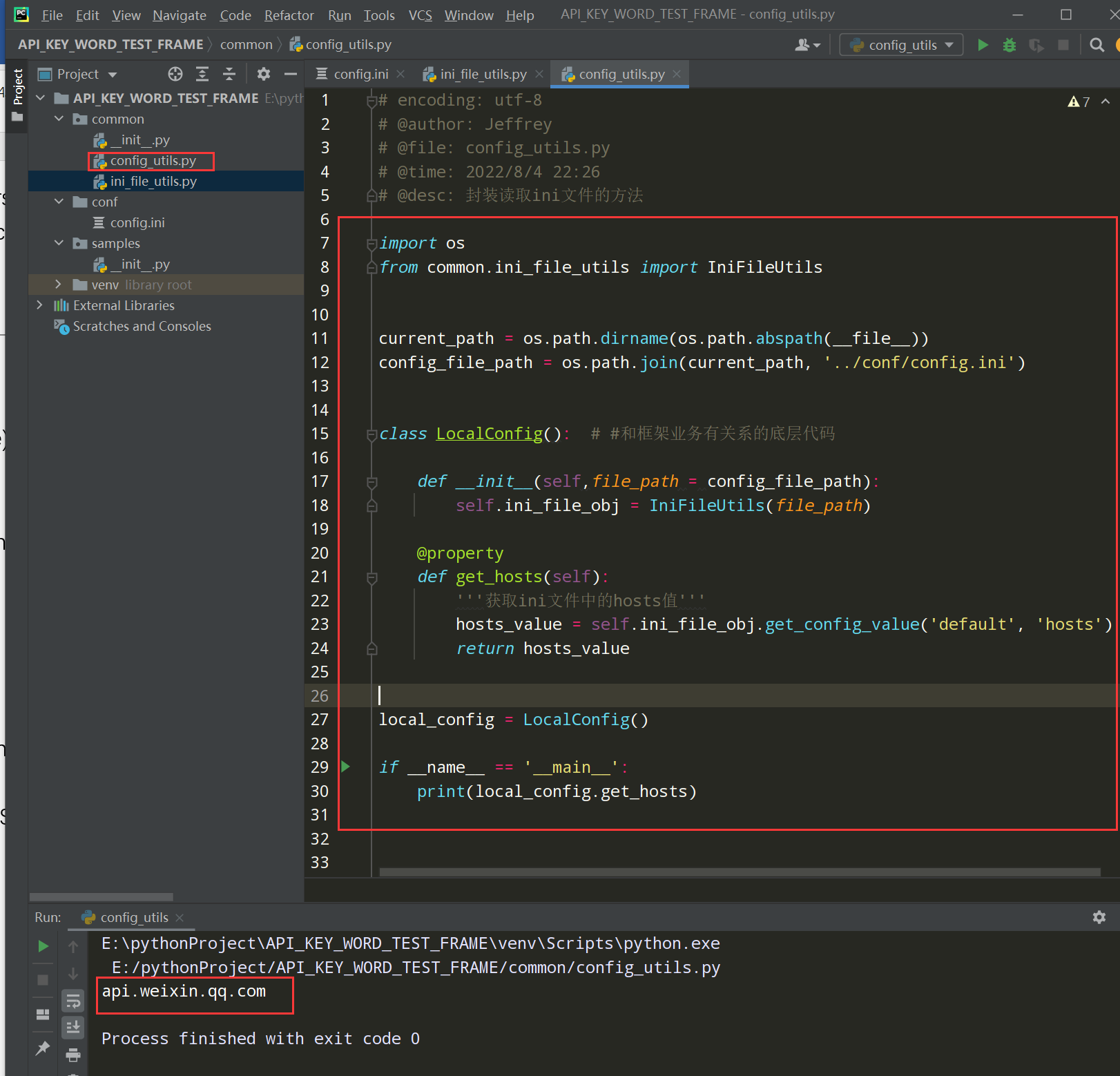
编写代码:
![]()
# encoding: utf-8
# @author: Jeffrey
# @file: config_utils.py
# @time: 2022/8/4 22:26
# @desc: 封装读取ini文件的方法
import os
from common.ini_file_utils import IniFileUtils
current_path = os.path.dirname(os.path.abspath(__file__))
config_file_path = os.path.join(current_path, '../conf/config.ini')
class LocalConfig(): # #和框架业务有关系的底层代码
def __init__(self,file_path = config_file_path):
self.ini_file_obj = IniFileUtils(file_path)
@property
def get_hosts(self):
'''获取ini文件中的hosts值'''
hosts_value = self.ini_file_obj.get_config_value('default', 'hosts')
return hosts_value
local_config = LocalConfig()
if __name__ == '__main__':
print(local_config.get_hosts)
![]()
步骤4、在samples文件下编写线性脚本,读取excel中的合并单元格
Excel表格如下:
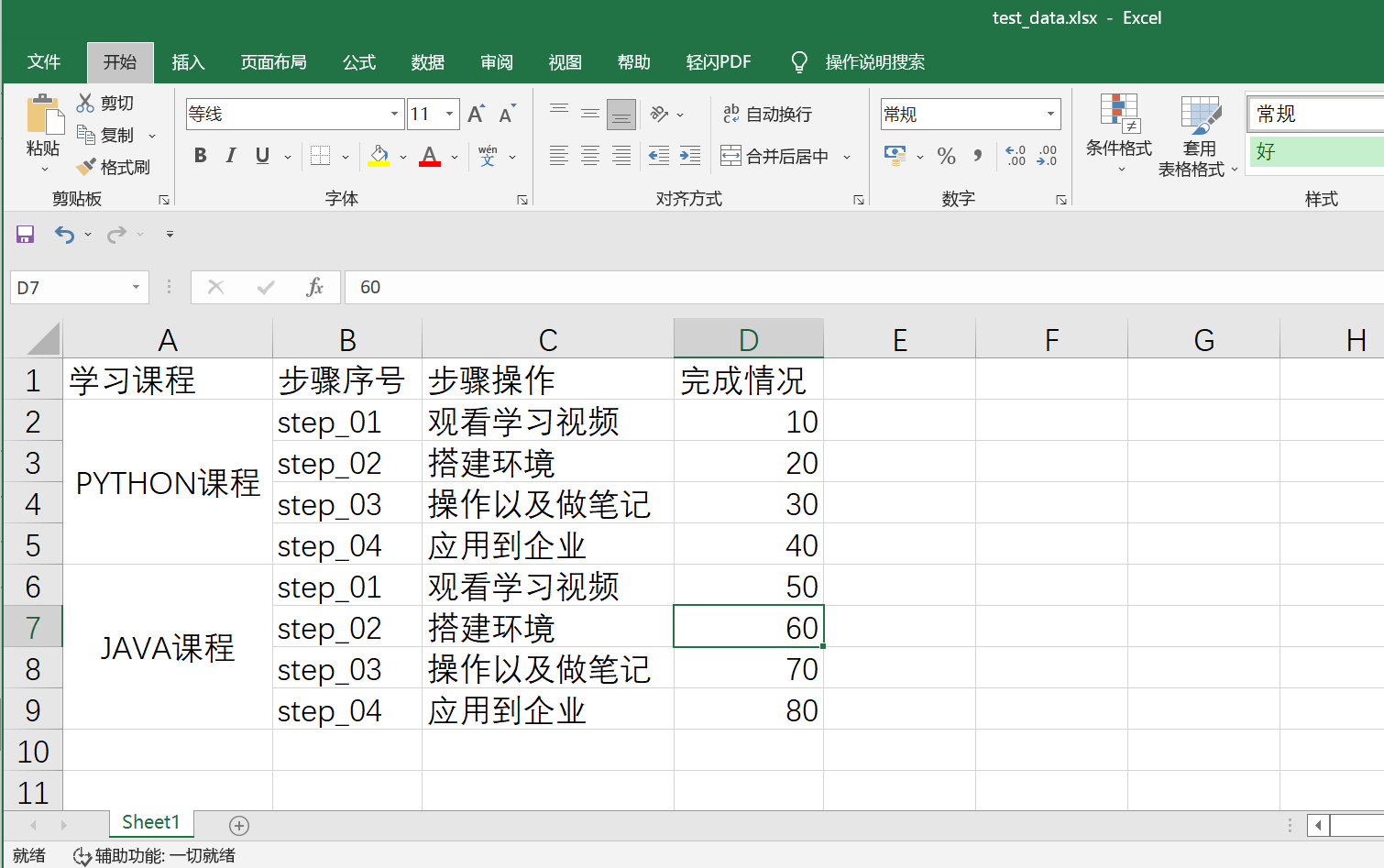
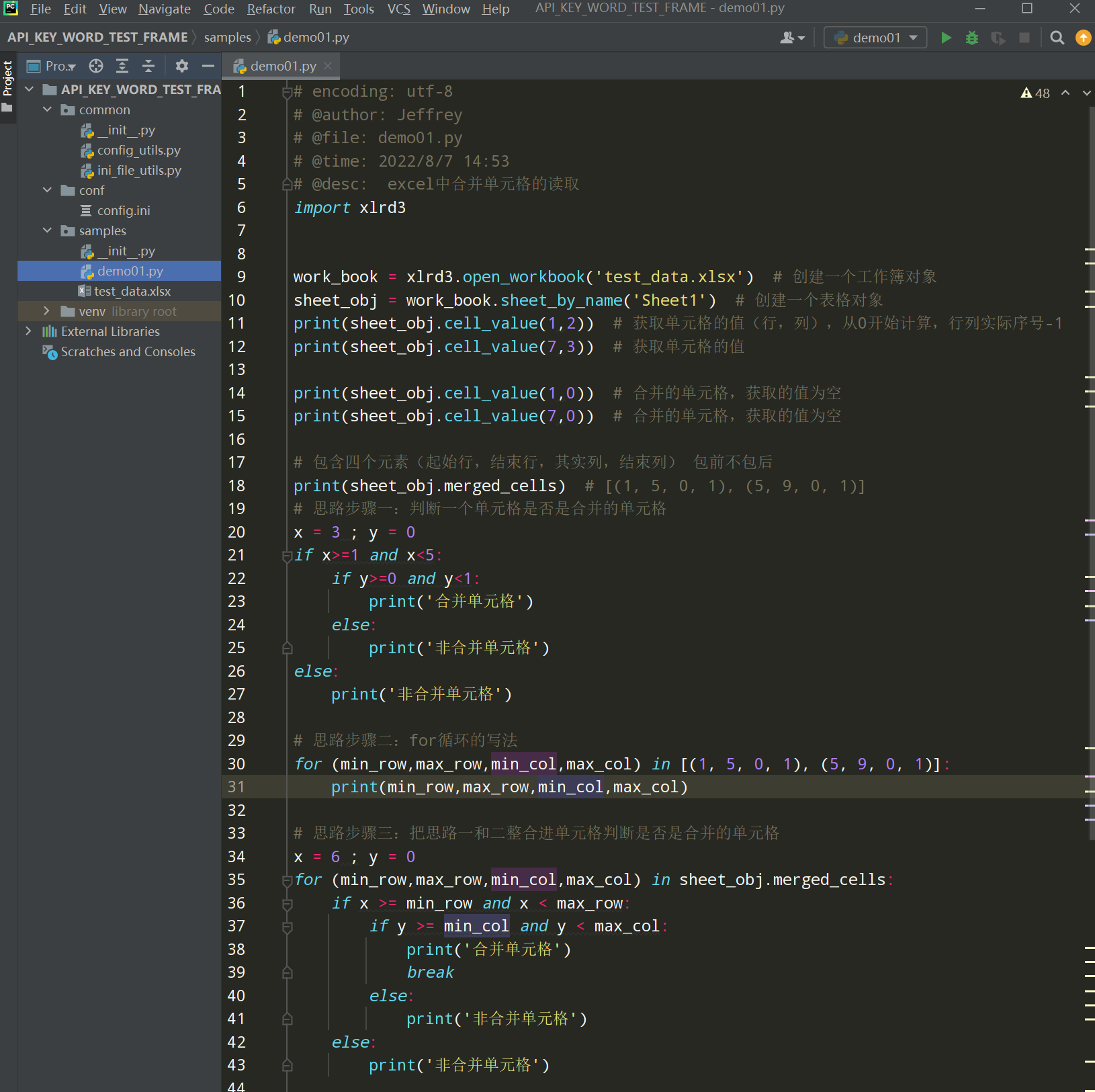
编写代码:
![]()
# encoding: utf-8
# @author: Jeffrey
# @file: demo01.py
# @time: 2022/8/7 14:53
# @desc: excel中合并单元格的读取
import xlrd3
work_book = xlrd3.open_workbook('test_data.xlsx') # 创建一个工作簿对象
sheet_obj = work_book.sheet_by_name('Sheet1') # 创建一个表格对象
print(sheet_obj.cell_value(1,2)) # 获取单元格的值(行,列),从0开始计算,行列实际序号-1
print(sheet_obj.cell_value(7,3)) # 获取单元格的值
print(sheet_obj.cell_value(1,0)) # 合并的单元格,获取的值为空
print(sheet_obj.cell_value(7,0)) # 合并的单元格,获取的值为空
# 包含四个元素(起始行,结束行,其实列,结束列) 包前不包后
print(sheet_obj.merged_cells) # [(1, 5, 0, 1), (5, 9, 0, 1)]
# 思路步骤一:判断一个单元格是否是合并的单元格
x = 3 ; y = 0
if x>=1 and x<5:
if y>=0 and y<1:
print('合并单元格')
else:
print('非合并单元格')
else:
print('非合并单元格')
# 思路步骤二:for循环的写法
for (min_row,max_row,min_col,max_col) in [(1, 5, 0, 1), (5, 9, 0, 1)]:
print(min_row,max_row,min_col,max_col)
# 思路步骤三:把思路一和二整合进单元格判断是否是合并的单元格
x = 6 ; y = 0
for (min_row,max_row,min_col,max_col) in sheet_obj.merged_cells:
if x >= min_row and x < max_row:
if y >= min_col and y < max_col:
print('合并单元格')
break
else:
print('非合并单元格')
else:
print('非合并单元格')
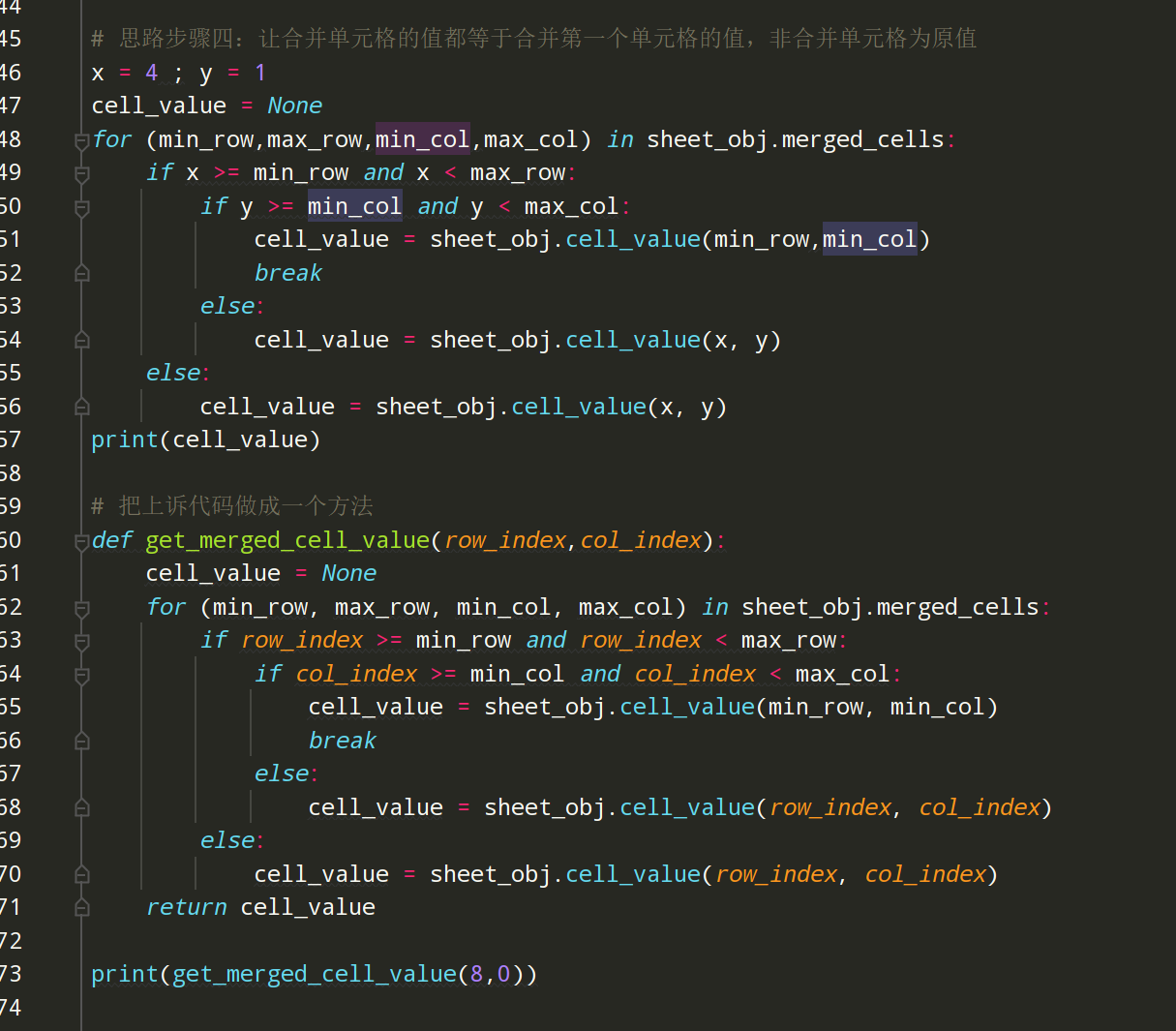
# 思路步骤四:让合并单元格的值都等于合并第一个单元格的值,非合并单元格为原值
x = 4 ; y = 1
cell_value = None
for (min_row,max_row,min_col,max_col) in sheet_obj.merged_cells:
if x >= min_row and x < max_row:
if y >= min_col and y < max_col:
cell_value = sheet_obj.cell_value(min_row,min_col)
break
else:
cell_value = sheet_obj.cell_value(x, y)
else:
cell_value = sheet_obj.cell_value(x, y)
print(cell_value)
# 把上诉代码做成一个方法
def get_merged_cell_value(row_index,col_index):
cell_value = None
for (min_row, max_row, min_col, max_col) in sheet_obj.merged_cells:
if row_index >= min_row and row_index < max_row:
if col_index >= min_col and col_index < max_col:
cell_value = sheet_obj.cell_value(min_row, min_col)
break
else:
cell_value = sheet_obj.cell_value(row_index, col_index)
else:
cell_value = sheet_obj.cell_value(row_index, col_index)
return cell_value
print(get_merged_cell_value(8,0))
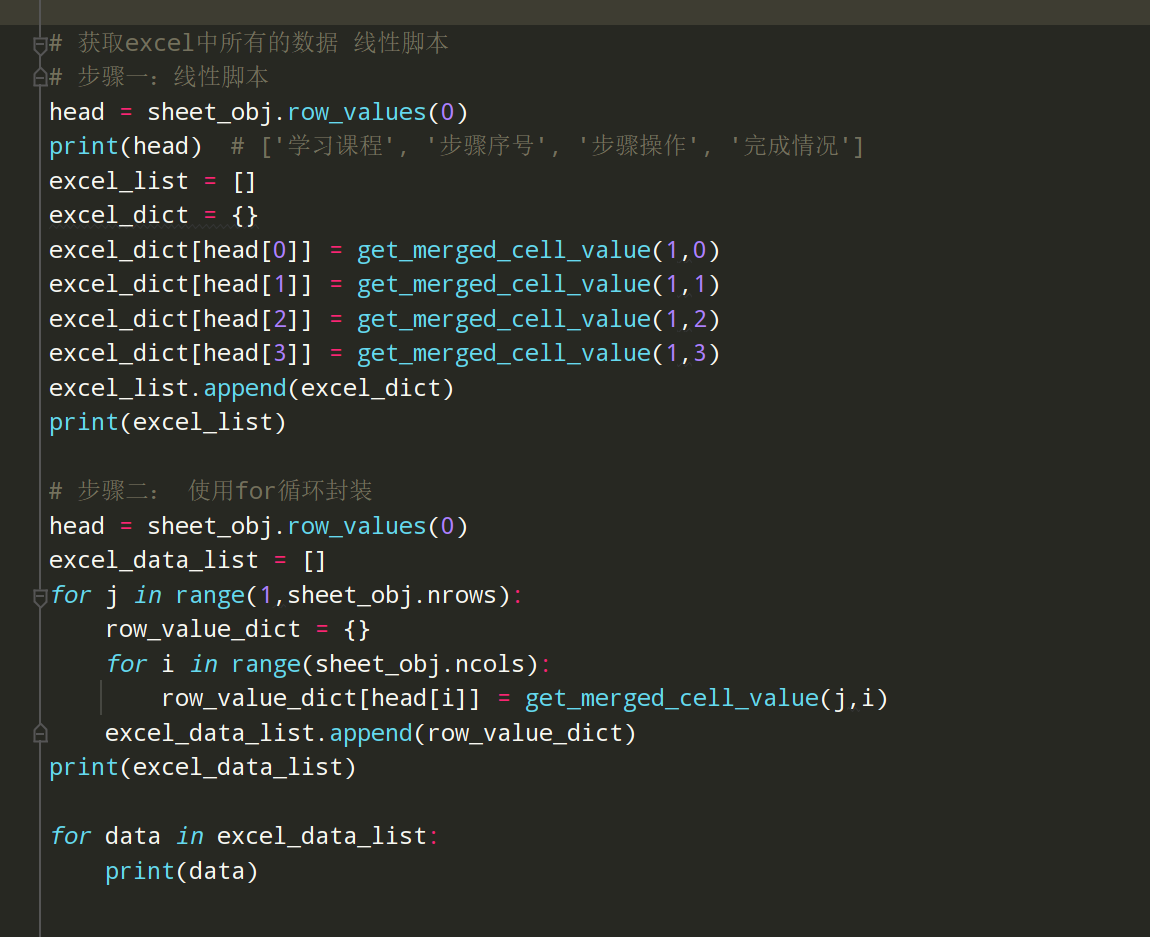
# 获取excel中所有的数据 线性脚本
# 步骤一:线性脚本
head = sheet_obj.row_values(0)
print(head) # ['学习课程', '步骤序号', '步骤操作', '完成情况']
excel_list = []
excel_dict = {}
excel_dict[head[0]] = get_merged_cell_value(1,0)
excel_dict[head[1]] = get_merged_cell_value(1,1)
excel_dict[head[2]] = get_merged_cell_value(1,2)
excel_dict[head[3]] = get_merged_cell_value(1,3)
excel_list.append(excel_dict)
print(excel_list)
# 步骤二: 使用for循环封装
head = sheet_obj.row_values(0)
excel_data_list = []
for j in range(1,sheet_obj.nrows):
row_value_dict = {}
for i in range(sheet_obj.ncols):
row_value_dict[head[i]] = get_merged_cell_value(j,i)
excel_data_list.append(row_value_dict)
print(excel_data_list)
for data in excel_data_list:
print(data)
![]()
步骤5、在common下新建excel_file_utils.py文件


编写代码:
![]()
# encoding: utf-8
# @author: Jeffrey
# @file: excel_file_utils.py
# @time: 2022/8/7 15:52
# @desc: 封装读取excel文件
import os
import xlrd3
class ExcelFileUtils():
def __init__(self,excel_file_path, sheet_name):
self.excel_file_path = excel_file_path
self.sheet_name = sheet_name
self.sheet_obj = self.get_sheet()
def get_sheet(self):
'''根据excel路径已经表名称 创建一个表格对象'''
workbook = xlrd3.open_workbook(self.excel_file_path)
sheet = workbook.sheet_by_name(self.sheet_name)
return sheet
def get_row_count(self):
'''获取表格实际行数'''
row_count = self.sheet_obj.nrows
return row_count
def get_col_count(self):
'''获取表格的实际列数'''
col_count = self.sheet_obj.ncols
return col_count
def get_merged_cell_value(self,row_index, col_index):
'''
:param row_index: 行下标
:param col_index: 列下标
:return: 获取单元格的内容
'''
cell_value = None
for (min_row, max_row, min_col, max_col) in self.sheet_obj.merged_cells:
if row_index >= min_row and row_index < max_row:
if col_index >= min_col and col_index < max_col:
cell_value = self.sheet_obj.cell_value(min_row, min_col)
break
else:
cell_value = self.sheet_obj.cell_value(row_index, col_index)
else:
cell_value = self.sheet_obj.cell_value(row_index, col_index)
return cell_value
def get_all_excel_data_list(self):
'''获取excel中所有的数据,以列表嵌套字典的形式'''
excel_data_list = []
head = self.sheet_obj.row_values(0)
for j in range(1,self.get_row_count()):
row_value_dict = {}
for i in range(self.get_col_count()): # sheet_obj.ncols 动态获取表格多少列
row_value_dict[head[i]] = self.get_merged_cell_value(j,i)
excel_data_list.append(row_value_dict)
return excel_data_list
if __name__ == '__main__':
current_path = os.path.dirname(__file__)
file_path = os.path.join(current_path, '../samples/test_data.xlsx')
excel_obj = ExcelFileUtils(file_path, 'Sheet1')
print(excel_obj.get_all_excel_data_list())
print(excel_obj.get_col_count())
![]()
测试执行结果:
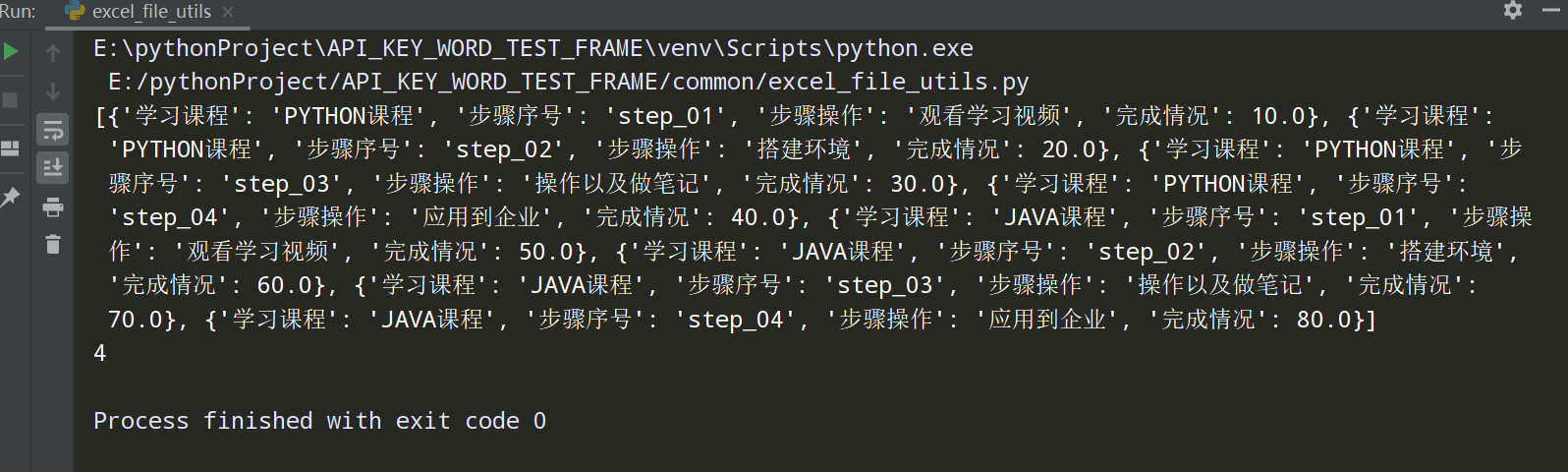
步骤6、在项目根目录下新建test_data普通文件夹,把测试用例文件放里面

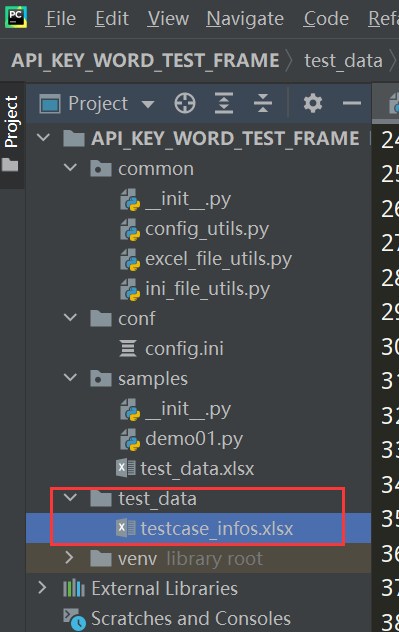
步骤7、在common下新建testcase_data_utils.py文件把测试用例的数据转换成框架需要用到的格式
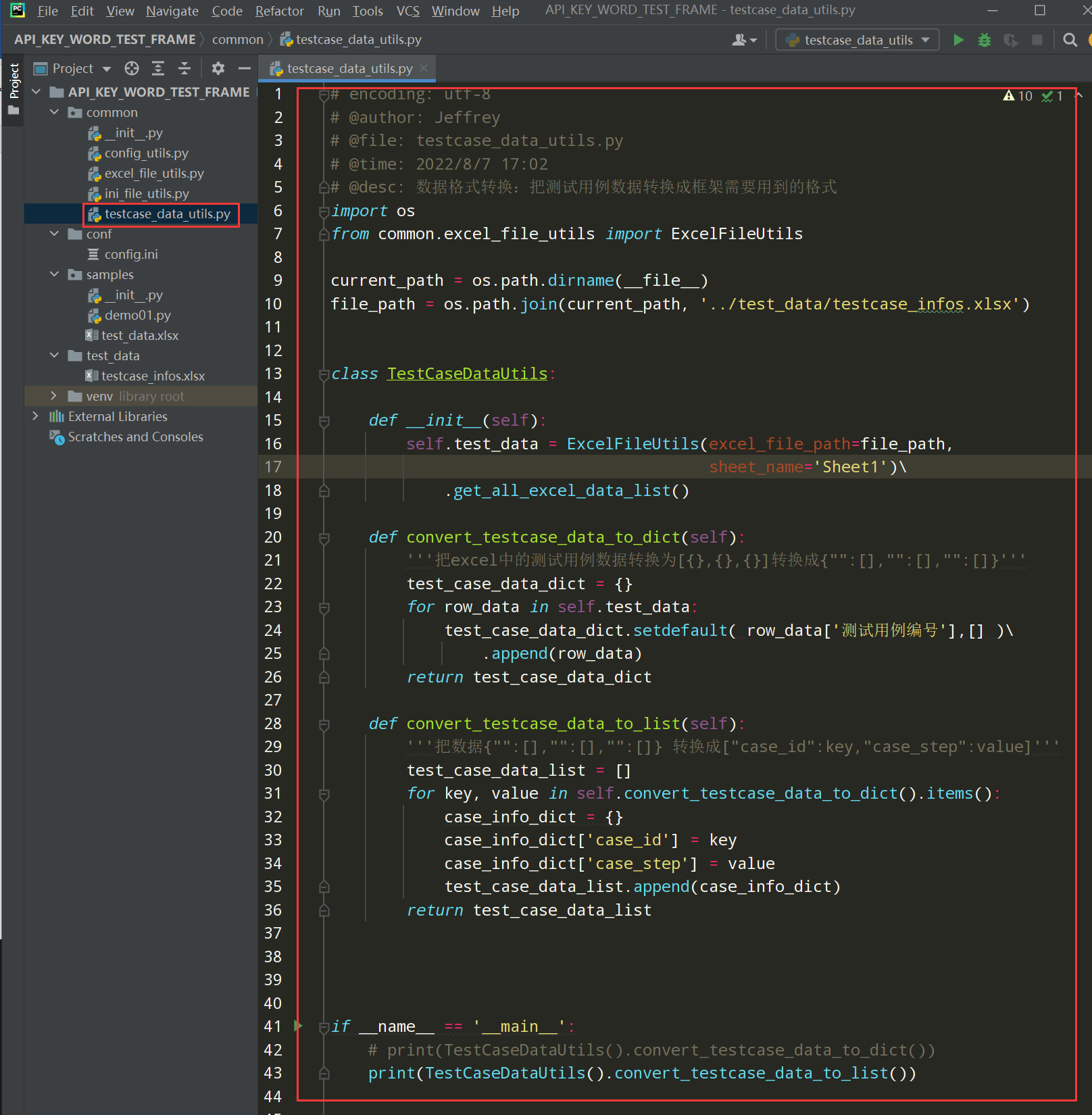
编写代码:
![]()
# encoding: utf-8
# @author: Jeffrey
# @file: testcase_data_utils.py
# @time: 2022/8/7 17:02
# @desc: 数据格式转换:把测试用例数据转换成框架需要用到的格式
import os
from common.excel_file_utils import ExcelFileUtils
current_path = os.path.dirname(__file__)
file_path = os.path.join(current_path, '../test_data/testcase_infos.xlsx')
class TestCaseDataUtils:
def __init__(self):
self.test_data = ExcelFileUtils(excel_file_path=file_path,
sheet_name='Sheet1')\
.get_all_excel_data_list()
def convert_testcase_data_to_dict(self):
'''把excel中的测试用例数据转换为[{},{},{}]转换成{"":[],"":[],"":[]}'''
test_case_data_dict = {}
for row_data in self.test_data:
test_case_data_dict.setdefault( row_data['测试用例编号'],[] )\
.append(row_data)
return test_case_data_dict
def convert_testcase_data_to_list(self):
'''把数据{"":[],"":[],"":[]} 转换成["case_id":key,"case_step":value]'''
test_case_data_list = []
for key, value in self.convert_testcase_data_to_dict().items():
case_info_dict = {}
case_info_dict['case_id'] = key
case_info_dict['case_step'] = value
test_case_data_list.append(case_info_dict)
return test_case_data_list
if __name__ == '__main__':
# print(TestCaseDataUtils().convert_testcase_data_to_dict())
print(TestCaseDataUtils().convert_testcase_data_to_list())
![]()
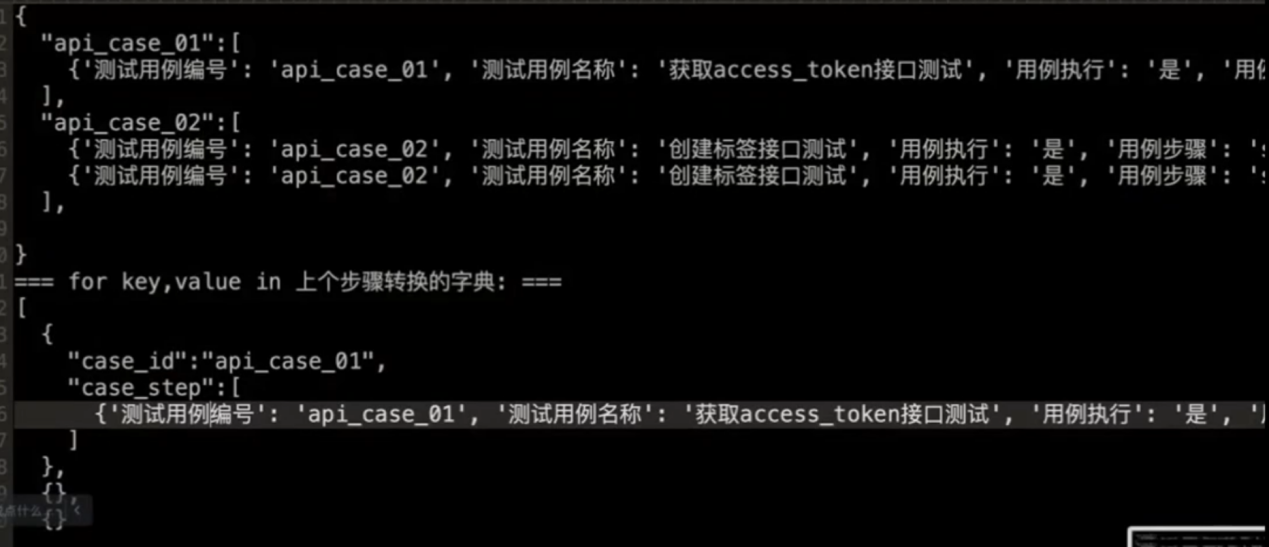
convert_testcase_data_to_dict()方法的目的是把用例数据以用例编号和用例数据分开
'''把excel中的测试用例数据转换为[{},{},{}]转换成{"":[],"":[],"":[]}'''
查看执行结果:

convert_testcase_data_to_list()方法的目的是以用例编号和用例步骤分开
'''把数据{"":[],"":[],"":[]} 转换成["case_id":key,"case_step":value]'''
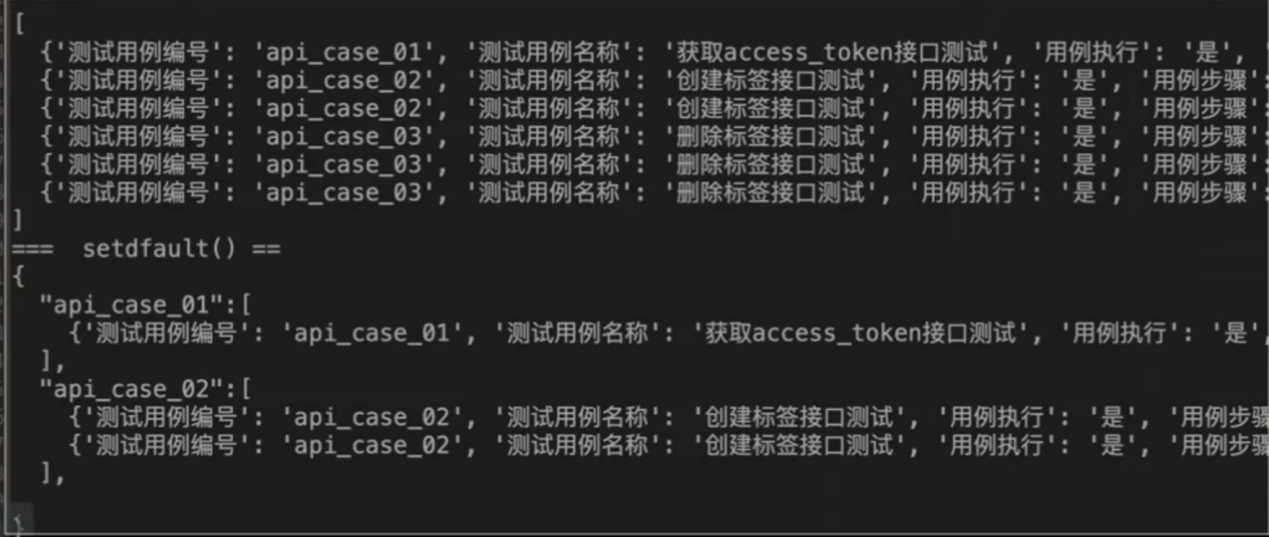
转换后数据
框架02,封装requests请求,在common下新建一个requests_utils.py文件
步骤1,封装get请求
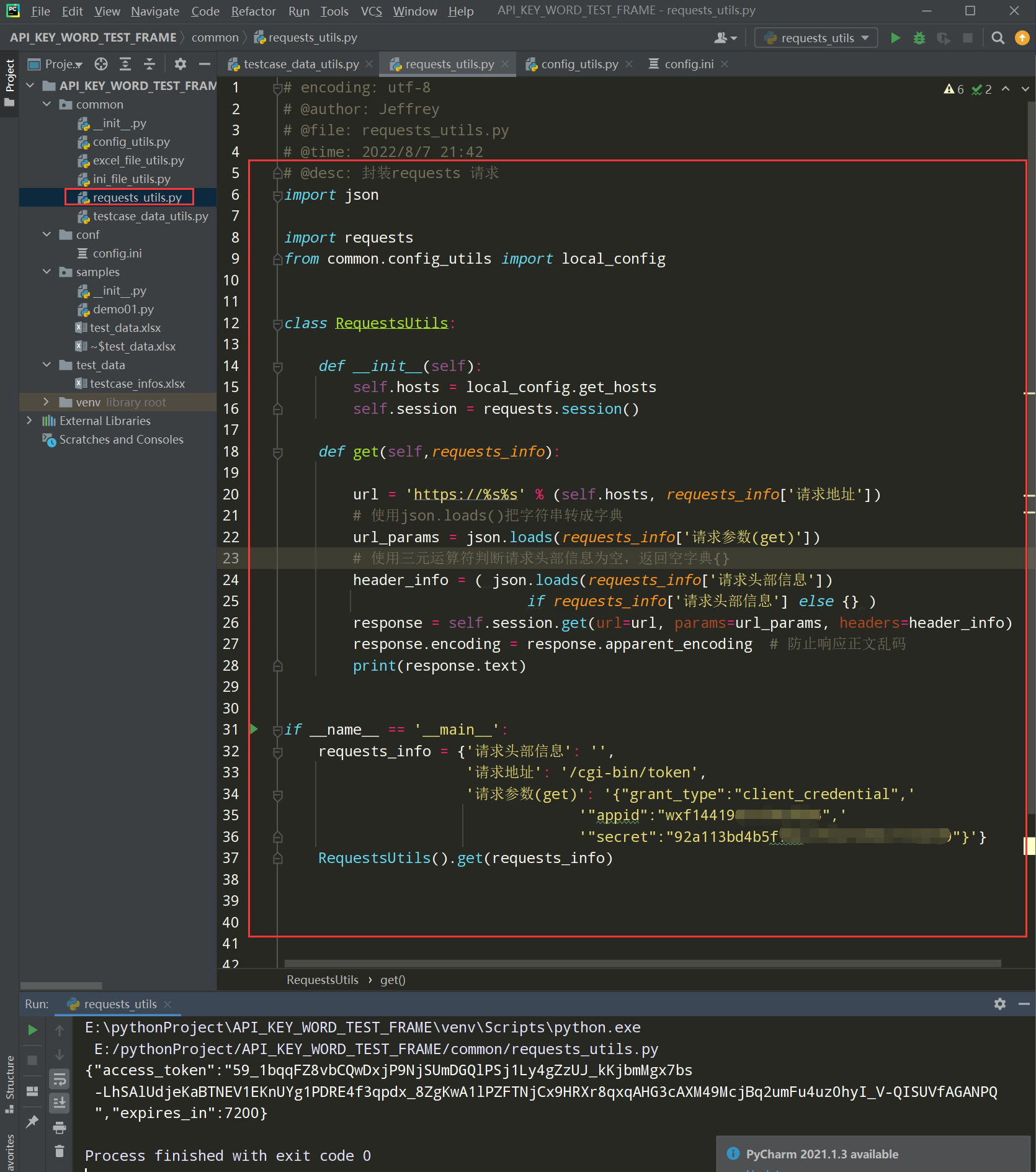
编写代码:
![]()
# encoding: utf-8
# @author: Jeffrey
# @file: requests_utils.py
# @time: 2022/8/7 21:42
# @desc: 封装requests 请求
import json
import requests
from common.config_utils import local_config
class RequestsUtils:
def __init__(self):
self.hosts = local_config.get_hosts
self.session = requests.session()
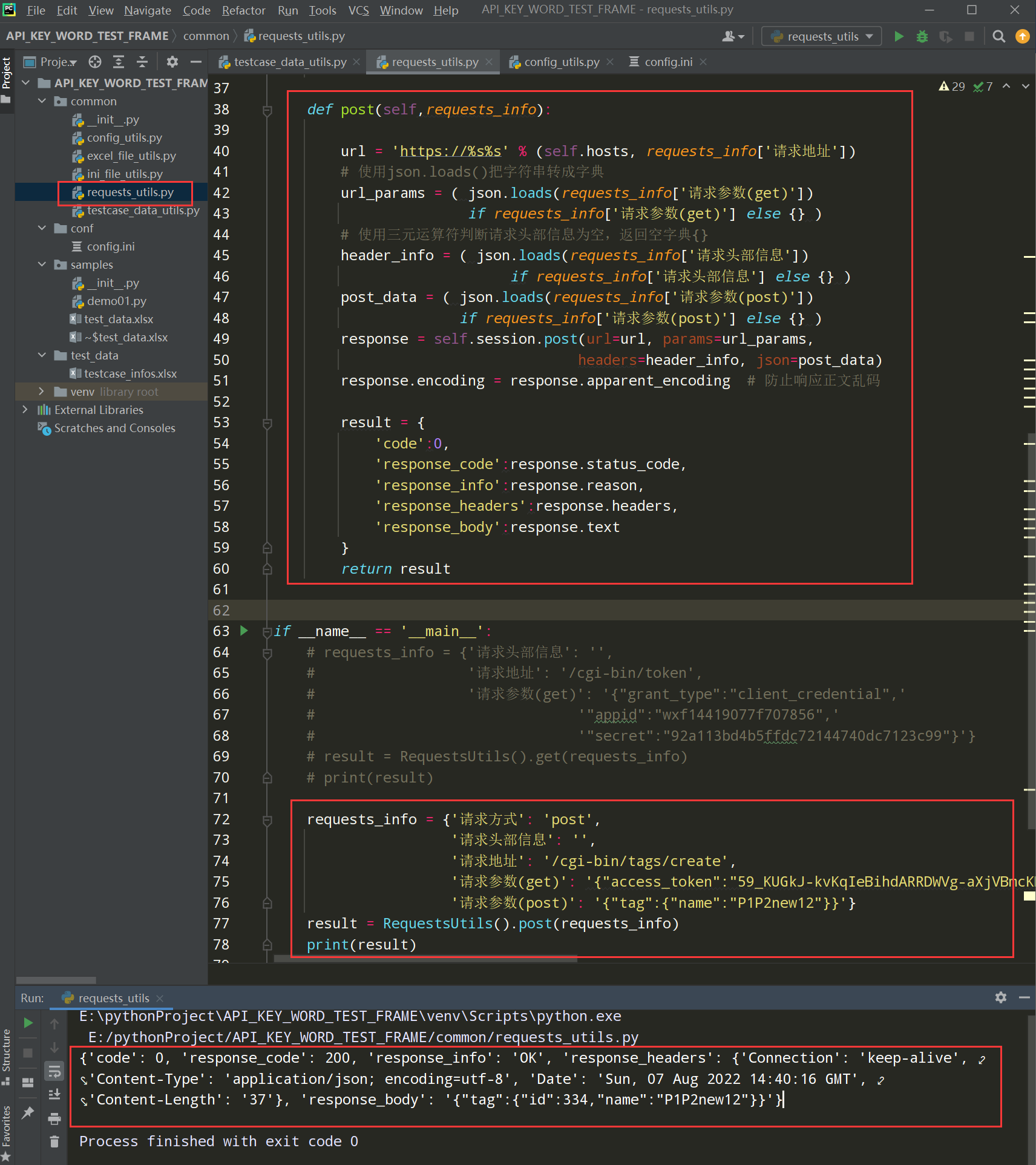
def get(self,requests_info):
url = 'https://%s%s' % (self.hosts, requests_info['请求地址'])
# 使用json.loads()把字符串转成字典
url_params = json.loads(requests_info['请求参数(get)'])
# 使用三元运算符判断请求头部信息为空,返回空字典{}
header_info = ( json.loads(requests_info['请求头部信息'])
if requests_info['请求头部信息'] else {} )
response = self.session.get(url=url, params=url_params, headers=header_info)
response.encoding = response.apparent_encoding # 防止响应正文乱码
print(response.text)
if __name__ == '__main__':
requests_info = {'请求头部信息': '',
'请求地址': '/cgi-bin/token',
'请求参数(get)': '{"grant_type":"client_credential",'
'"appid":"wxf1856",'
'"secret":"92a113bd423c99"}'}
result = RequestsUtils().get(requests_info)
print(result)
![]()
步骤2、把返回的所有响应信息,作为一个字典,且多一个code字段
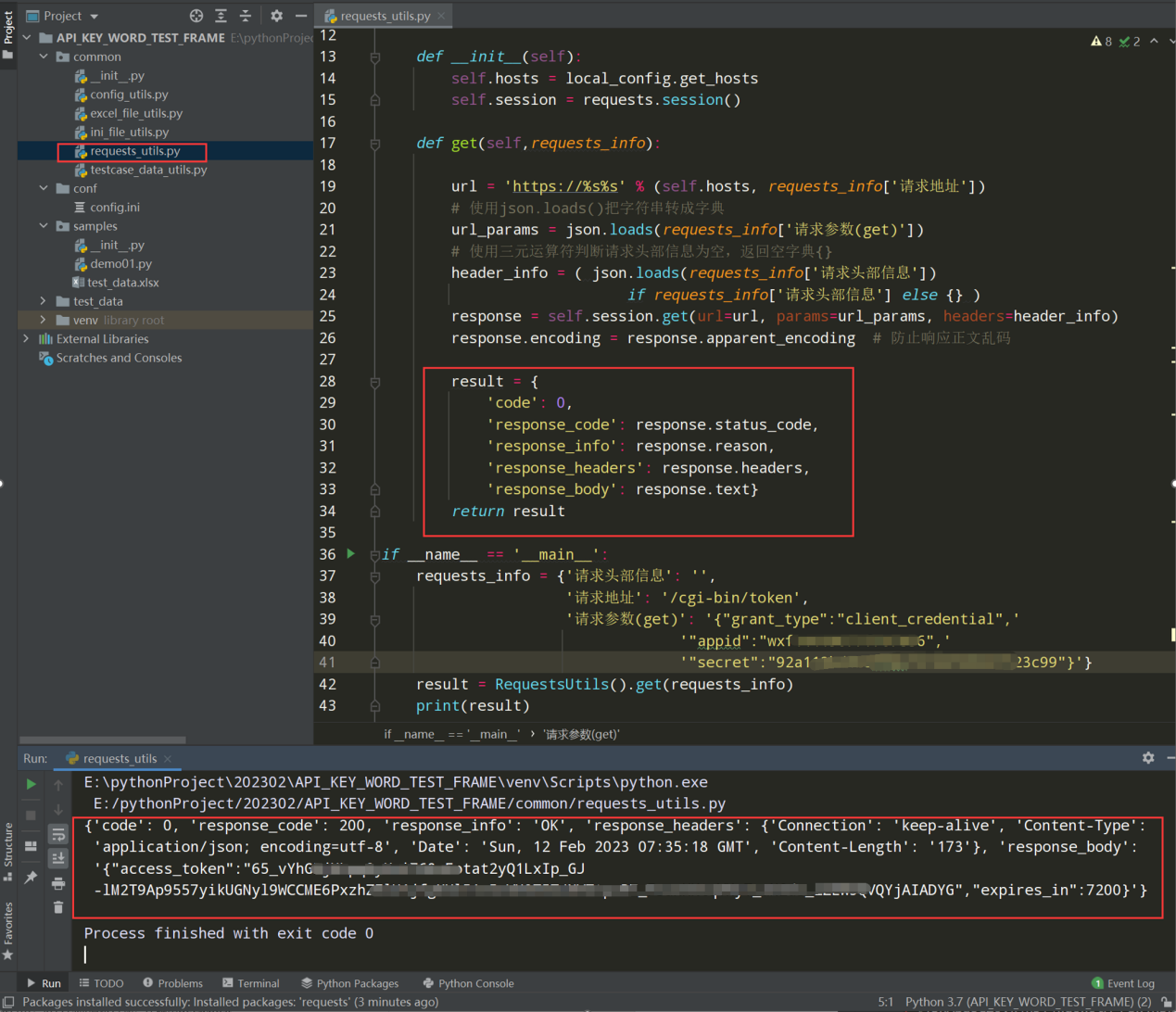
编写代码:
![]()
result = {
'code':0,
'response_code':response.status_code,
'response_info':response.reason,
'response_headers':response.headers,
'response_body':response.text }
![]()
步骤3、封装post请求