一、NLP 自然语言处理
NLP 是机器学习在语言学领域的研究,专注于理解与人类语言相关的一切。NLP 的目标不仅是要理解每个单独的单词含义,而且也要理解这些单词与之相关联的上下文之间的意思。
常见的NLP 任务列表:
- 对整句的分类:如获取评论的好坏、垃圾邮件的分类,如判断两个句子的逻辑相关性;
- 对句中单词的分类:如单词的语法构成(名词、动词、形容词)、单词的实体命名(人、地点、时间)
- 文本内容的生成:如文章续写、屏蔽词填充;
- 文本答案的提取:给定问题,根据上下文信息提前答案;
- 从提示文本生成新句子:如文本翻译、文本总结;
NLP 并不局限于书面文本,它也能解决语音识别、计算机视觉方方面的问题,如生成音频样本的转录、图像的描述等;
二、Transformer
Hugging Face Hub 社区是最大的Transformer开发者的交流地,里面分享了数万个预训练模型、数据集等,任何人都可以下载和使用。而Transformers 库提供了创建和使用这些共享模型、数据集的功能。
# # 安装
pip install transformers
# # 导入
import transformers
Transformers库的优势:
- 简单:Transformers只提供一个 API,只需两行代码即可下载、加载和使用 NLP 模型进行推理;
- 灵活:所有模型的核心都是 PyTorch 的nn.Module 类或 TensorFlow 的tf.keras.Model 类;
- 独立:模型之间相互独立,每个模型拥有的层都在一个模型文件内。这个是与其他 ML 库截然不同的,
2.1、Transformer 发展历史
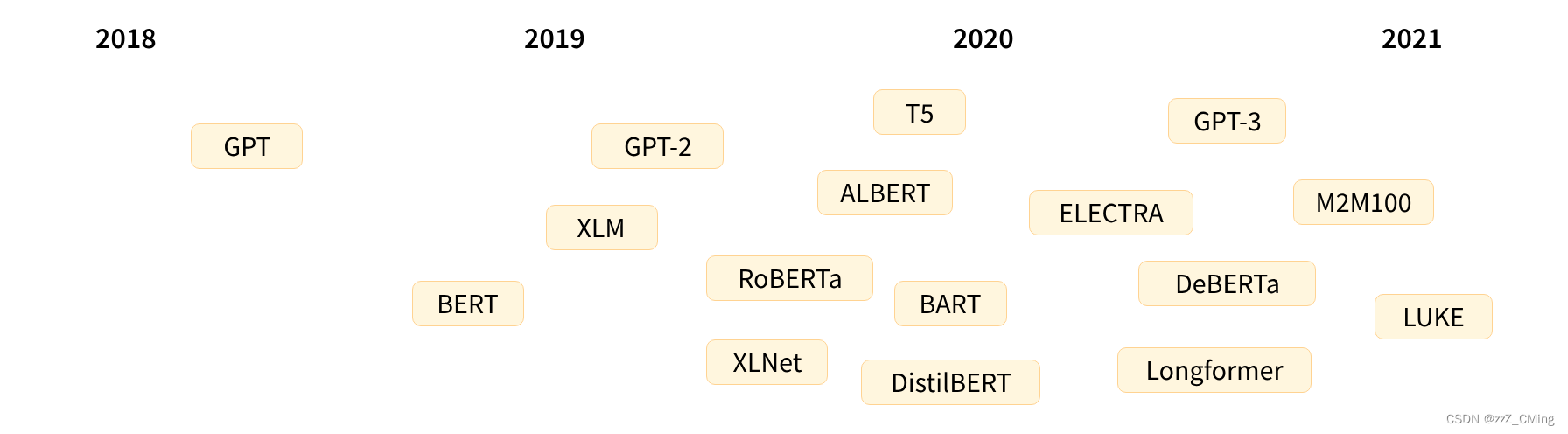
Transformer 架构于2017 年 6 月推出。最初的研究重点是翻译任务。随后推出了几个有影响力的模型,包括:
- 2018年6月:GPT,第一个预训练的Transformer模型,用于各种NLP任务的微调并获得了SOTA的结果;
- 2018 年10月:BERT,另一个大型预训练模型,旨在生成更好的句子摘要;
- 2019年2月:GPT-2,GPT 的改进(和更大)版本,由于道德问题没有立即公开发布;
- 2019年10月:DistilBERT,BERT 的精炼版,速度提高了 60%,内存减少了 40%,但仍然保留了 BERT 97% 的性能;
- 2019年10月:BART、T5,两个大型预训练模型,使用与原始 Transformer 模型相同的架构;
- 2020年5月:GPT-3,GPT-2的更大版本,能够在各种任务上表现良好,无需微调(称为zero-shot零样本学习)
上面提到的所有Transformer 模型(GPT、BERT、BART、T5 等)都是预训练语言模型(以自监督的方式接受了大量原始文本的训练),预训练模型只是对所训练语言进行的统计理解,对于特定的实际任务来说并不适用。正因如此,预训练模型还要经历一个迁移学习的过程,针对具体的任务以监督学习的方式进行微调。
预训练模型
- 从零开始训练,权重随机初始化,没有任何先验知识;
- 需要大量数据用于训练,训练时间也可能很久;
微调模型
- 是在预训练模型的基础上进行的训练;
- 要有具体任务的数据集,微调训练的时间不会很久;
- 微调模型的成本较低:时间、数据、财务、硬件等,更容易部署。
所以在实际应用中,应该始终尝试去寻找与实际任务接近的预训练模型,再使用具体任务的小样本数据集,以监督学习的方式来微调它。
2.2、Transformer 详细原理
Transformer 详细原理包括:
- 编码器Encoder部分
- 解码器Decoder部分
- Self-Attention 自注意力原理
- Multi-Head Attention 多头注意力机制
详细原理请看链接:Transformer模型原理
2.3、Transformer 能做什么
Transformers 库中最基本的对象是pipeline() 函数,它将必要的预处理和后处理连接起来,使我们能直接输入文本并获取对应需求的答案。目前可用的一些管道模型有:
- ner:实体命名识别
- fill-mask:掩码填充
- translation:翻译
- summarization:文章总结
- text-generation:文本生成
- question-answering:问题回答
- sentiment-analysis:情绪分析
- zero-shot-classification:零样本分类
- feature-extraction:获取文本的向量表示
from transformers import pipeline
# # # 命名实体识别
# ner = pipeline("ner", grouped_entities=True)
# print(ner("My name is Sylvain and I work at Hugging Face in Brooklyn."))
# # # 掩码填充
# fill_mask = pipeline("fill-mask")
# print(fill_mask("The cat is <mask> on the mat."))
# # # 翻译
# translator = pipeline("translation", model="Helsinki-NLP/opus-mt-fr-en")
# print(translator("Ce cours est produit par Hugging Face."))
# # # 文章总结
# summarizer = pipeline("summarization")
# print(summarizer("xxxxxxxxxxxxxxxxxx"))
# # # 文本生成
# generator = pipeline("text-generation")
# print(generator("In this course, we will teach you how to"))
# # # 指定hugging face Hub网站中任意模型
# generator = pipeline("text-generation", model="distilgpt2")
# print(generator("In this course, we will teach you how to", max_length=30, num_return_sequences=2))
# # # 问题回答
# question_answerer = pipeline("question-answering")
# print(question_answerer(question="Where do I work?", context="My name is Sylvain and I work at Hugging Face in Brooklyn"))
# # 情绪分析
classifier = pipeline("sentiment-analysis") # # (该库只能输入英文。)
print(classifier(["I've been waiting for a HuggingFace course my whole life.", "I hate this so much!"]))
# # # 零样本分类zero-shot-classification
# classifier = pipeline("zero-shot-classification")
# print(classifier("This is a course about the Transformers library", candidate_labels=["education", "politics", "business"]))
# # # 获取文本的向量表示
# feature_extraction = pipeline("feature-extraction")
# print(feature_extraction("i am a studet"))
NLP 在处理问题使主要涉及三个步骤:
- 人类可理解的文本被预处理为模型可理解的数据格式;
- 将可理解的数据传递给模型,模型做出预测;
- 模型的预测再经过后处理,输出人类可理解的文本。
例如:
# # 情绪分析
classifier = pipeline("sentiment-analysis") # # (该库只能输入英文。)
print(classifier(["I've been waiting for a HuggingFace course my whole life.", "I hate this so much!"]))
# # 结果
# [{'label': 'POSITIVE', 'score': 0.9598047137260437},
# {'label': 'NEGATIVE', 'score': 0.9994558095932007}]