学CBAM前建议先学会SEnet(因为本篇涉及SEnet的重合部分会略加带过)->传送门
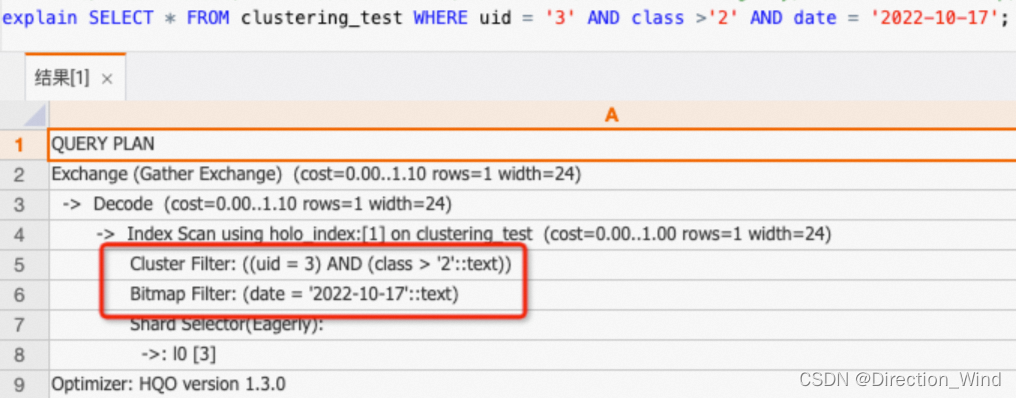
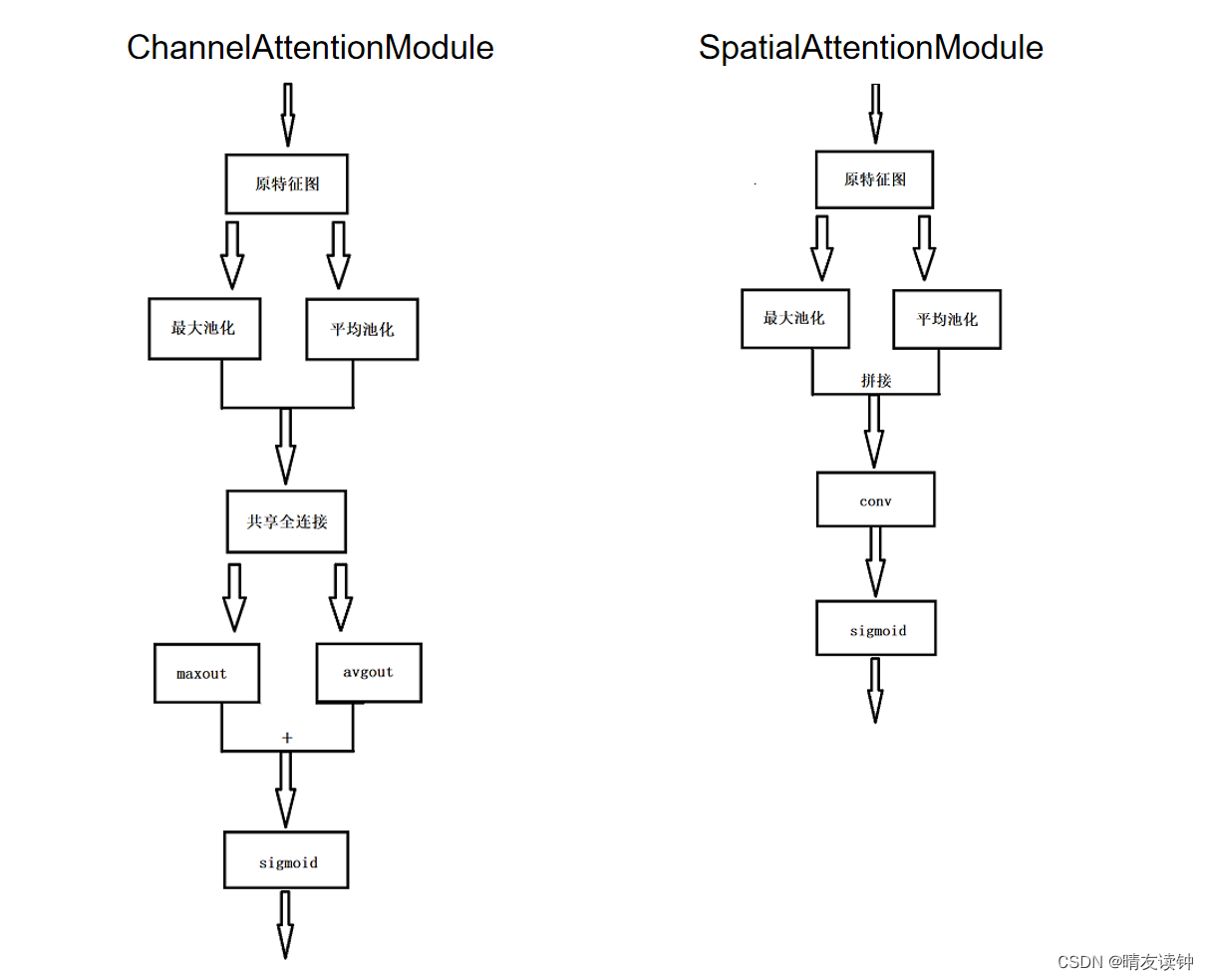
⒈结构图
下面这个是自绘的,有些许草率。。。
因为CBAM机制是由通道和空间两部分组成的,所以有这两个模块(左边是通道注意力机制,右边是空间注意力机制)
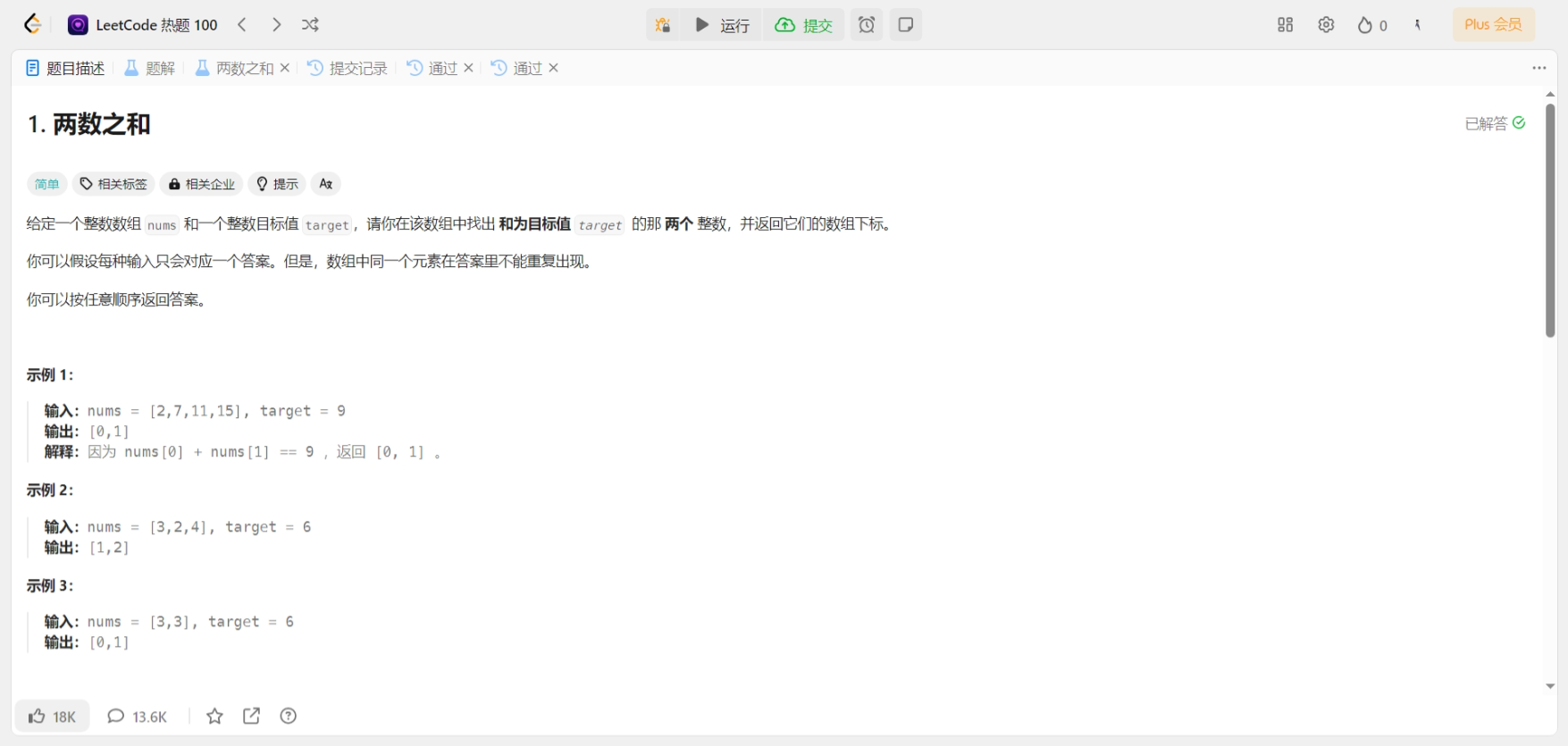
下面这两个是官方论文里的:


⒉机制流程讲解
SEnet只关注了通道注意力机制而忽略了空间上的一些简单特征,相比之下,CBAM将通道注意力机制和空间注意力机制进行一个结合,对输入进来的特征层,分别进行通道注意力机制的处理和空间注意力机制的处理,而是是先通道后空间,也就是第一张结构图表达的意思。
①首先是通道机制:
对于输入特征层,分别作全局最大池化和全局平均池化,输出结果分别送入一个共享全连接层(官方源码在这里和SEnet的全连接层一模一样),为什么叫共享全连接层?因为最大池化和平均池化的两条路线用的是这同一个全连接层。然后对两个结果(maxout和avgout)做加法,最后进行归一化操作,获得通道上的权重矩阵。
②然后是空间机制:
对于输入特征层,在每一个特征点的通道上取最大值和平均值,(这里和通道机制的最大池化和平均池化完全不同,通道机制里是在H、W两个维度求最大或平均,空间机制是在C一个维度上求最大和平均。)然后对两个结果(maxout和avgout)做拼接,也就是maxout的1*H*W与avgout的1*H*W进行拼接,得到2*H*W的张量,因此紧接着下一步就要进行一个7*7的卷积(conv)将通道压缩回1,最后还是进行归一化操作,获得空间上的权重矩阵。
③整体上:
对于输入特征层,输入特征层先乘上通道机制的输出权重(channel_out),然后再乘上空间上的输出权重(spatial_out)
⒊源码(pytorch框架实现)及逐行解释
import torch
from torch import nn
from torchsummary import summary
class ChannelModule(nn.Module):
def __init__(self, inputs, ratio=16):
super(ChannelModule, self).__init__()
_, c, _, _ = inputs.size()
self.maxpool = nn.AdaptiveMaxPool2d(1)
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.share_liner = nn.Sequential(
nn.Linear(c, c // ratio),
nn.ReLU(),
nn.Linear(c // ratio, c)
)
self.sigmoid = nn.Sigmoid()
def forward(self, inputs):
x = self.maxpool(inputs).view(inputs.size(0), -1)#nc
maxout = self.share_liner(x).unsqueeze(2).unsqueeze(3)#nchw
y = self.avgpool(inputs).view(inputs.size(0), -1)
avgout = self.share_liner(y).unsqueeze(2).unsqueeze(3)
return self.sigmoid(maxout + avgout)
class SpatialModule(nn.Module):
def __init__(self):
super(SpatialModule, self).__init__()
self.maxpool = torch.max
self.avgpool = torch.mean
self.concat = torch.cat
self.conv = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3)
self.sigmoid = nn.Sigmoid()
def forward(self, inputs):
maxout, _ = self.maxpool(inputs, dim=1, keepdim=True)#n1hw
avgout = self.avgpool(inputs, dim=1, keepdim=True)#n1hw
outs = self.concat([maxout, avgout], dim=1)#n2hw
outs = self.conv(outs)#n1hw
return self.sigmoid(outs)
class CBAM(nn.Module):
def __init__(self, inputs):
super(CBAM, self).__init__()
self.channel_out = ChannelModule(inputs)
self.spatial_out = SpatialModule()
def forward(self, inputs):
outs = self.channel_out(inputs) * inputs
return self.spatial_out(outs) * outs解释:
①依赖包和SEnet解释的一样。
②整体上看,将通道机制和空间机制分别封装成类,再封装一个CBAM类来对这两个机制调用,其中用到的__init__构造方法(python称魔术方法)和foward函数(前向传播过程),这些模板和上面介绍SEnet时是一模一样的。
先来看通道机制:
class ChannelModule(nn.Module):#继承nn模块的Module类
def __init__(self, inputs, ratio=16):#self必写,inputs接收输入特征张量,ratio是通道衰减因子
super(ChannelModule, self).__init__()#调用父类构造
_, c, _, _ = inputs.size()#获取通道数
self.maxpool = nn.AdaptiveMaxPool2d(1)#nn模块的自适应二维最大池化
self.avgpool = nn.AdaptiveAvgPool2d(1)#nn模块的自适应二维平均池化
self.share_liner = nn.Sequential(
nn.Linear(c, c // ratio),
nn.ReLU(),
nn.Linear(c // ratio, c)
)#这个共享全连接的3层和SEnet的一模一样,这里借助Sequential这个容器把这3个层整合在一起,方便forward函数去执行,直接调用share_liner(x)相当于直接执行了里面这3层
self.sigmoid = nn.Sigmoid()#nn模块的Sigmoid函数
def forward(self, inputs):
x = self.maxpool(inputs).view(inputs.size(0), -1)#对于输入特征张量,做完最大池化后再重塑形状,view的第一个参数inputs.size(0)表示第一维度,显然就是n;-1表示会自适应的调整剩余的维度,在这里就将原来的(n,c,1,1)调整为了(n,c*1*1),后面才能送入全连接层(fc层)
maxout = self.share_liner(x).unsqueeze(2).unsqueeze(3)#做完全连接后,再用unsqueeze解压缩,也就是还原指定维度,这里用了两次,分别还原2维度的h,和3维度的w
y = self.avgpool(inputs).view(inputs.size(0), -1)
avgout = self.share_liner(y).unsqueeze(2).unsqueeze(3)#y走的平均池化路线的代码和x是一样的解释
return self.sigmoid(maxout + avgout)#最后相加两个结果并作归一化再来看空间机制:(重复的模板就不再反复赘述了)
class SpatialModule(nn.Module):
def __init__(self):
super(SpatialModule, self).__init__()
self.maxpool = torch.max
self.avgpool = torch.mean
#和通道机制不一样!这里要进行的是在C这一个维度上求最大和平均,分别用的是torch库里的max方法和mean方法
self.concat = torch.cat#torch的cat方法,用于拼接两个张量
self.conv = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3)#nn模块的二维卷积,其中的参数分别是:输入通道(2),输出通道(1),卷积核大小(7*7),步长(1),灰度填充(3)
self.sigmoid = nn.Sigmoid()
def forward(self, inputs):
maxout, _ = self.maxpool(inputs, dim=1, keepdim=True)#maxout接收特征点的最大值很好理解,为什么还要一个占位符?因为torch.max不仅返回张量最大值,还会返回索引,索引用不着所以直接忽略,dim=1表示在维度1(也就是nchw的c)上求最大值,keepdim=True表示要保持原来张量的形状
avgout = self.avgpool(inputs, dim=1, keepdim=True)#torch.mean则只返回张量的平均值,至于参数的解释和上面是一样的
outs = self.concat([maxout, avgout], dim=1)#torch.cat方法,传入一个列表,将列表中的张量在指定维度,这里是维度1(也就是nchw的c)拼接,即n*1*h*w拼接n*1*h*w得到n*2*h*w
outs = self.conv(outs)#卷积压缩上面的n*2*h*w,又得到n*1*h*w
return self.sigmoid(outs)最后看整体:
class CBAM(nn.Module):
def __init__(self, inputs):
super(CBAM, self).__init__()
self.channel_out = ChannelModule(inputs)#获得通道权重
self.spatial_out = SpatialModule()#获得空间权重
def forward(self, inputs):
outs = self.channel_out(inputs) * inputs #先乘上通道权重
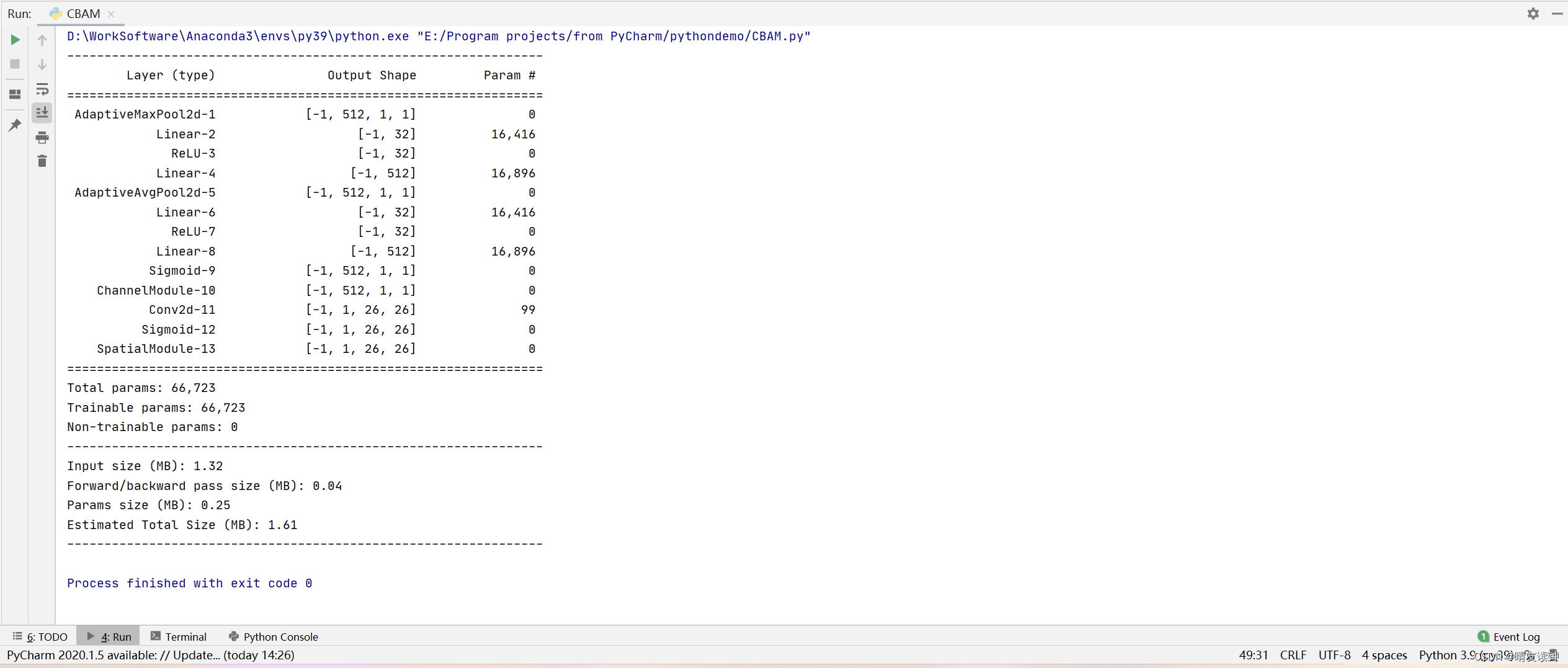
return self.spatial_out(outs) * outs #在乘完通道权重的基础上再乘上空间权重⒋测试结果
大问题没有,但还是少了一些关键层,尤其是空间机制那里的拼接maxout和avgout,通道变为2再用卷积压缩回1的过程都没体现。。。只能说summary确实不太好使,或者说我没用对?网络层简写导致的?(最不可能是这个原因,因为我拿官方的源码测试也是summary出这些结果)